 NVIDIA Triton系列文章:开发资源说明
NVIDIA Triton系列文章:开发资源说明

大部分要学习 Triton 推理服务器的入门者,都会被搜索引擎或网上文章引导至官方的https://developer.nvidia.com/nvidia-triton-inference-server处(如下截图),然后从 “Get Started” 直接安装服务器与用户端软件、创建基础的模型仓、执行一些最基本的范例。

这条路径虽然能在很短时间内跑起 Triton 的应用,但在未掌握整个应用架构之前便贸然执行,反倒容易让初学者陷入迷失的状态,因此建议初学者最好先对 Triton 项目有比较更完整的了解之后,再执行前面的 “Get Started” 就会更容易掌握项目的精髓。
要获得比较完整的 Triton 技术资料,就得到项目开源仓里去寻找。与 NVIDIA 其他放在 https://github.com/NVIDIA或https://github.com/NVIDIA-AI-IOT的项目不同,Triton 项目有独立的开源仓,位置在https://github.com/triton-inference-server,进入开源仓后会看到如下截屏的内容:
下面列出四大部分的技术资源:
1. Getting Start(新手上路):
这里提供三个链接,比较重要的是 “Quick Start(快速启动)” 的部分,提供以下三个步骤就能轻松执行 Triton 的基础示范:
(1) Create a Model Repository(创建模型仓)
(2) Launch Triton(启动Triton服务器与用户端)
(3) Send an Inference Request(提交推理要求)
2. Production Documentation(生产文件):
这里最重要的是 “server documents on GitHub” 链接,点进去后会进入整个 Triton 项目中最完整的技术文件中心(如下图),除 Installation 与 Getting Started 属于入门范畴,其余 User Guide、API Guide、Additional Resources 与 Customization Guide 等四个部分,都是 Triton 推理服务器非常重要的技术内容。

因此这个部分可以算得上是学习 Triton 服务器的最重要资源。
例如点击 “User Guide” 之后,就会看到以下所条例的执行步骤:
Creating a Model Repository
Writing a Model Configuration
Buillding a Model Pipeline
Managing Model Availablity
Collecting Server Metrics
Supporting Custom Ops/layers
Using the Client API
Analyzing Performance
Deploying on edge (Jetson)
3. Examples(范例):
这里的范例,比较重要的是指向https://github.com/NVIDIA/DeepLearningExamples链接,列出针对 NVIDIA Tensor Core 计算单元的深度学习模型列表,包括计算机视觉、NLP 自然语言处理、推荐系统、语音转文字 / 文字转语音、图形神经网络、时间序列等各种神经网络模型细节,包括网络结构与相关参数的内容。
对于未来要在 Triton 服务器上,对于所使用的网络后端进行性能优化或者创建新的后端,会有很大的助益,但是对于初学者来说是相对艰涩的,因此现阶段先不做深入的说明与示范。
4. Feedback(反馈):
这里会链接到https://github.com/triton-inference-server/server/issues问题中心,是 Triton 项目中最重要的技术问题解决资源之一,后面执行过程中所遇到的问题,都可以先到这里来查看是否有人已经提出?如果没有的话,也可以在这里提交自己所遇到的问题,项目负责人会提供合适的回复。
以上第 2、4 两项资源,对初学者来说会有最大的帮助。接着看一下项目里 “钉住(Pinned)” 的 6 个仓(如下图),是比较重要的基础部分,涵盖了 Triton 架构图中的主要板块。
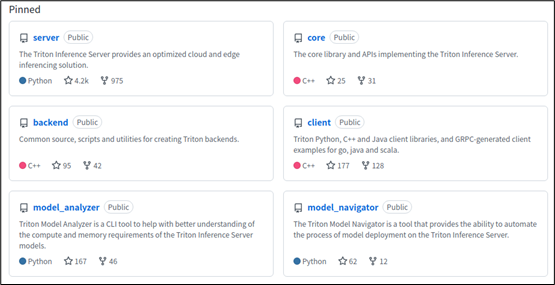
主要内容如下:
1. server 仓:
这里集成整个项目的主要内容,包括几部分:
(1)deploy(部署):提供在阿里巴巴、亚马逊等云资源的部署方式,以及基于 NVIDIA Fleet 指令集、GKE(Google kubernets Engine)、k8s、Helm 等应用平台的各种部署方法;
(2)docker(容器):修正一些创建容器脚本的错误;
(3)docs(使用说明):就是前面 “生产文件(Production Documentation)” 的内容,这里不重复赘述;
(4)qa(质量优化):由于 Triton 推理服务器有非常多优化的环节,在这个目录下提供上百个不同状况的优化测试脚本;
(5)src(源代码):目录下存放整个 Triton 推理服务器的开源代码(.cc)、头文件(.h)与编译脚本(CMakeLists.txt);
(6)其他代码与脚本
2. core 仓:
此存储库包含实现 Triton 核心功能的库的源代码和标头。核心库可以如下所述构建,并通过其 CAPI 直接使用。为了有用,核心库必须与一个或多个后端配对。您可以在后端回购中了解有关后端的更多信息。
3. backend 仓:
提供创建 Triton 服务器后端(backend)的源代码、脚本与工具。“后端” 是用来执行不同深度学习模型的管理模块,以深度学习框架进行封装,例如 PyTorch、Tensorflow、ONNX Runtime 与 TensorRT 等等,用户也可以为了性能目的,自行定义 C / C++ 封装方式。
4. client 仓:
提供 Triton 用户端的 C++ / Python / Java 开发接口、能生成适用于不同编程语言的 GRPC 开发接口的 protoc 编译器,以及对应的用户端范例;
5. model_analyzer 仓:
深度学习模型(model)是 Triton 推理服务器的最基础组成元件,因此对分析模型的计算与内存需求是服务器性能的一项关键功能。这个 model_analyzer 模型分析工具是一种 CLI 工具,这款新工具可以自动化地从数百种组合中为 AI 模型选择最佳配置,以实现最优性能,同时确保应用程序所需的服务质量,能帮助开发人员更好地了解不同配置中的权衡,并选择能够最大化 Triton 的性能配置;
6. model_navigator 仓:
这个 model_navigator 模型导航器是一种能够自动将模型从源移动到最佳格式和配置的工具,支持将模型从源导出为所有可能的格式,并应用 Triton 服务器的后端优化。使用模型分析器能找到最佳的模型配置,匹配提供的约束条件并优化性能。
以上是 Triton 开源项目里比较核心的 6 个仓,另外还有 20 多个代码仓,其中大约 15 个是项目提供的后端(backend)扩充应用,例如 tensorrt_backend、fil_backend、square_backend 等等,以及一些额外的管理工具,并且不断增加中。
本系列后面的内容都会基于这个 server 仓的 docs 目录下的内容为主,按部就班地带着读者循序渐进创建与调试 Triton 推理服务器的运作环境。
审核编辑 :李倩
-
NVIDIA
+关注
关注
14文章
5696浏览量
110121 -
服务器
+关注
关注
14文章
10366浏览量
91763
原文标题:NVIDIA Triton 系列文章(3):开发资源说明
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
芯科科技发布Simplicity SDK for Zephyr开发资源
借助NVIDIA CUDA Tile IR后端推进OpenAI Triton的GPU编程
NVIDIA全新开放物理AI模型和框架加速人形机器人开发
NVIDIA 推出 Alpamayo 系列开源 AI 模型与工具,加速安全可靠的推理型辅助驾驶汽车开发

NVIDIA Jetson系列开发者套件助力打造面向未来的智能机器人
利用NVIDIA Cosmos开放世界基础模型加速物理AI开发
面向科学仿真的开放模型系列NVIDIA Apollo正式发布
NVIDIA DRIVE AGX Thor开发者套件重磅发布
NVIDIA Omniverse Extension开发秘籍
芯科科技Arduino开发资源重大更新
NVIDIA桌面GPU系列扩展新产品
方寸之间构筑系统级可靠性,纳芯微发布国产首款高性能 2 线制霍尔开关 MT72xx系列
使用NVIDIA Triton和TensorRT-LLM部署TTS应用的最佳实践

NVIDIA Isaac Sim与NVIDIA Isaac Lab的更新
芯科科技助力蓝牙Mesh设备开发




评论