 Autopilot的识别堆栈内深挖细品
Autopilot的识别堆栈内深挖细品

在上期文章中,我们从Autopilot的感知堆栈的backbone网络开始分析,从raw data到RegNet,再到BiFPN,最后来到多头的Head结构,这就基本上给HydraNets的框架结构定了性。在Tesla AI Day结束之后,很多关心自动驾驶产业发展的人,观后感普遍是智商不够,看不懂。而实际上,如果读者不进入实际的研发领域,要理解Autopilot的工作机制、框架和基本脉络,实际上并没有那么困难。而对于Autopilot整体框架的理解,一旦有心得,对于自动驾驶行业的从业者、爱好者和政策关注者,其实都是大有裨益的。
而作为一个典型的跨学科产业,传统封闭知识结构的限制让很多初次涉足自动驾驶行业的新手来说,都会感到明显困难。一个突出的问题就是交叉学科概念实在太多太新了,往往名词都看不懂,就不要说深究了。所以,小编写这个系列文章的初衷就是尽可能拉低阅读门槛,让每个感兴趣的读者开卷有益。毕竟,Tesla这种具备开放心态的先锋企业,不是总能遇得到的。
所以关注这个系列的读者,在看系列中任何一篇文章的时候,都可以联系系列中的其它文章串起来看,各种新鲜的名词解释和上下文串讲会协助诸位和小编一起跑完这个理解的过程的。
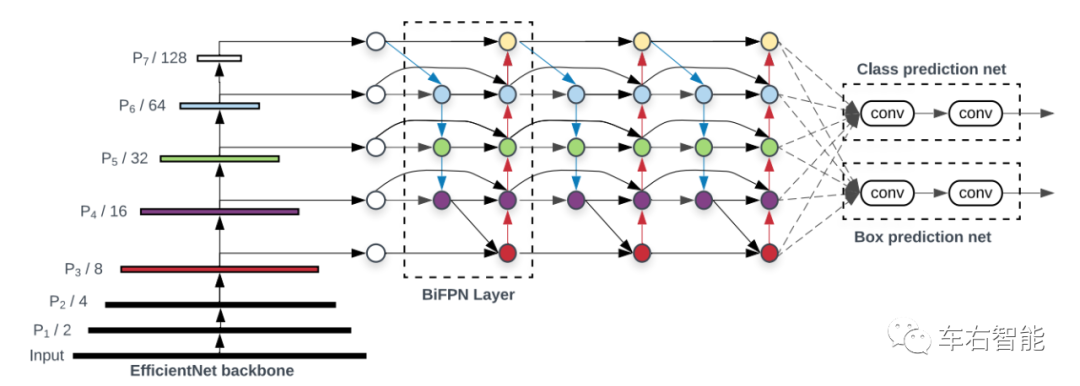
图一【Tesla transformer-33.png】来自论文《EfficientDet: Scalable and Efficient ObjectDetection》中的插图,获取URLhttps://arxiv.org/pdf/1911.09070.pdf;
这是上一篇文章中我们所讲的关键点BiFPN网络结构,其中BiFPN和其他上下游的网络结构交代得比较清楚,所以小编在这里再强调一次。上图左半部分为Google的EfficientNet,是一种典型的层次化的CNN Backbone结构,上图中显示为7层,每一层的分辨率逐渐降低,但是特征Feature map也是在这个过程中通过卷积计算来实现搜集的。重要的是,我们可以清晰地观察到,从第3层到第7层的Feature map数据被依次输入到BiFPN网络内,从而可以利用BiFPN的融合结构设计,将不同层次的feature按照预定义的规则融合到一起,制造更准确的识别结果。
上图(图一)的最右侧显示了这个整体模型中的Task Head,显示了优化后的backbone所提供的feature map最终被用于何种任务的实现。其中一个是分类任务Class,另一个是定位任务Box共两个任务。它们两个共享了EfficentNet backbone+BiFPN的特征识别结果,实现了算力的共享和高效利用。
在一个典型的CNN网络中(以下图为例是VGG16)另一个直观的案例,原始的Input image在后续的一些列卷积处理之后,最终按照任务的要求实现Output输出。通常讲,CNN被用于网络内容的识别,并在识别后按照识别结果的类别来报告输出。下图模型就是干这个的。
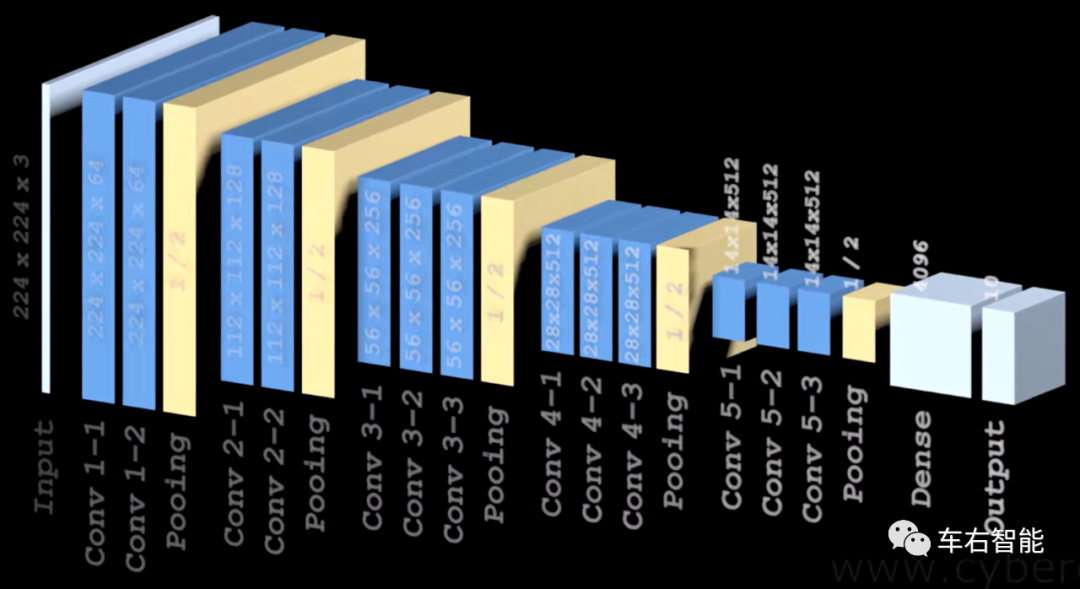
图二【Tesla transformer-34.png】来自youtube.com中账号@denisdmitriev的VGG16 Neural Networkvisualization视频的插图,获取URLhttps://www.youtube.com/watch?v=RNnKtNrsrmg;
如果将这个VGG16的卷积模型拉伸开来,就可以清晰地展示出每一个卷积层、池化层的输出直观计算(or感知)结果,如下:

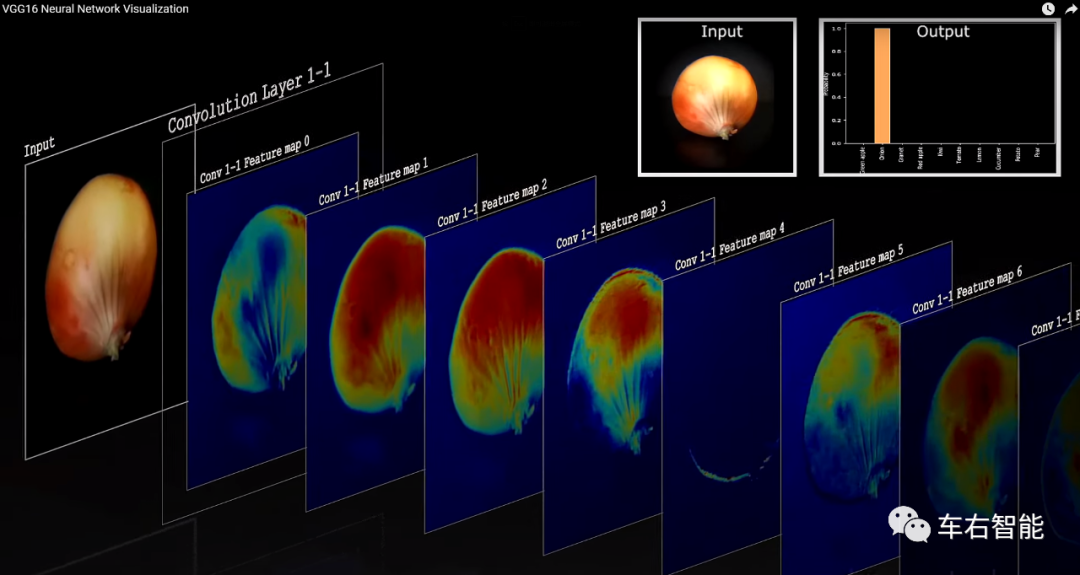
图三【Tesla transformer-35、36.png】来自youtube.com中账号@denis dmitriev的VGG16 Neural Network visualization视频的插图,获取URLhttps://www.youtube.com/watch?v=RNnKtNrsrmg;
由于不同卷积算子的卷积计算,原始图像中的苹果(或者洋葱),其不同的特征被捕捉出来,比如颜色、形状、表皮类型、根茎形状,甚至不同物种常常呈现的不同的凹凸不平的特点,都被CNN抓出来,并通过BiFPN类似的特征融合机制形成最终的认知,或者提供给后端Task Head有效的、良好的认知素材。从这个流程上看,CNN对于图像信息特征的捕捉方式,几乎和人类对于图像的感知方式一致了。当然,人类的感知能力除了视觉信息分析,我们还具备触觉、味觉和更一般的“世界知识体系”……这是AI暂时所做不到的。比如,两个在外观上完全一致的苹果和洋葱,人类视觉无法判断分类结果,自然会拿在手上掂量一下,甚至闻一下、尝一口,最终总是可以找到正确答案的。
之前在这个系列的第一篇文章里,我们谈到过AI技术演进的下一个方向,也有对于多模态信息的综合感知,那是因为Transformer体现出了一定的多模态数据处理能力。其实CNN技术本身也有同时被应用于图形和语言的信息处理领域,但显然自动驾驶领域内的感知问题,在当前阶段还是应该关注图形数据(视觉传感器)为核心,解决了视觉问题,大概99%的问题都被解决了。在此基础之上的更进一步感知多模态信息,才扎实。
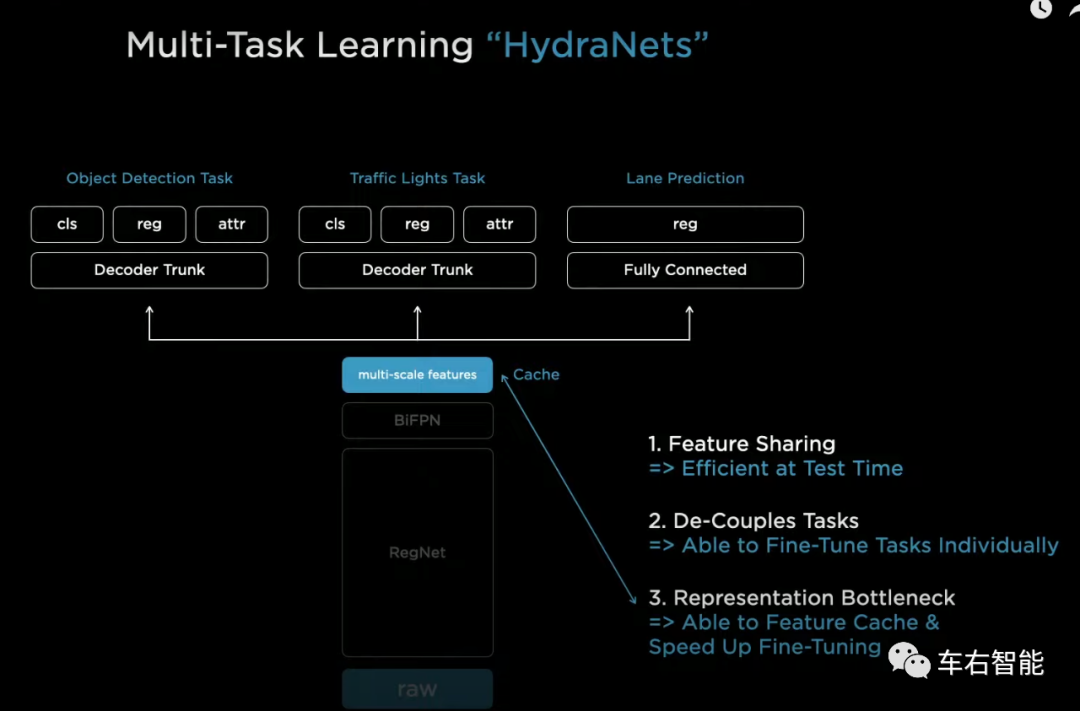
图四【Tesla transformer-37.png】来自Tesla AI day主题演讲视频截图,URLhttps://www.youtube.com/watch?v=j0z4FweCy4M&t=4115s;
Backbone+Task heads的整体架构如上图,这就是标准的多任务系统HydraNets。在这个多任务Heads框架中从左到右分别是Object Detection Task(应该包含静态和动态所有道路目标的识别)、Traffic Lights Task(交通灯和其它交通标识的识别)和Lane Prediction Task(车道线及可行驶区域识别)。实际上FSD beta现在这个阶段,使用到CNN backbone的任务一定不止以上三个。细分任务的原则是一个Head task无法处理和涵盖一个类别的任务,就需要拥有独立的Head Task。比如小编推测在Lan Prediction Task中,可能不仅仅是各种车道线的识别和预测,还有可能包含同样关键的马路边缘路缘石边界的识别。在这个具象的Task中,系统框图只给出了regression方法(reg),在对于车道线的识别这是一个普遍的方法,因为车道线基本上可以用一个固定的二次函数、三次函数既可以描述出车道线走势,所以机器学习里涉及的车道线识别方法,使用regression回归方法来预测车道线的多项式系数即可,这是个惯用的标准做法。但对于马路边缘路缘石构成的可行驶区域边界的识别,因为路缘石边界的不规则属性,可能无法服用regression方法。感兴趣的读者可以参考PolyLaneNet车道线识别的方法,互联网可查。
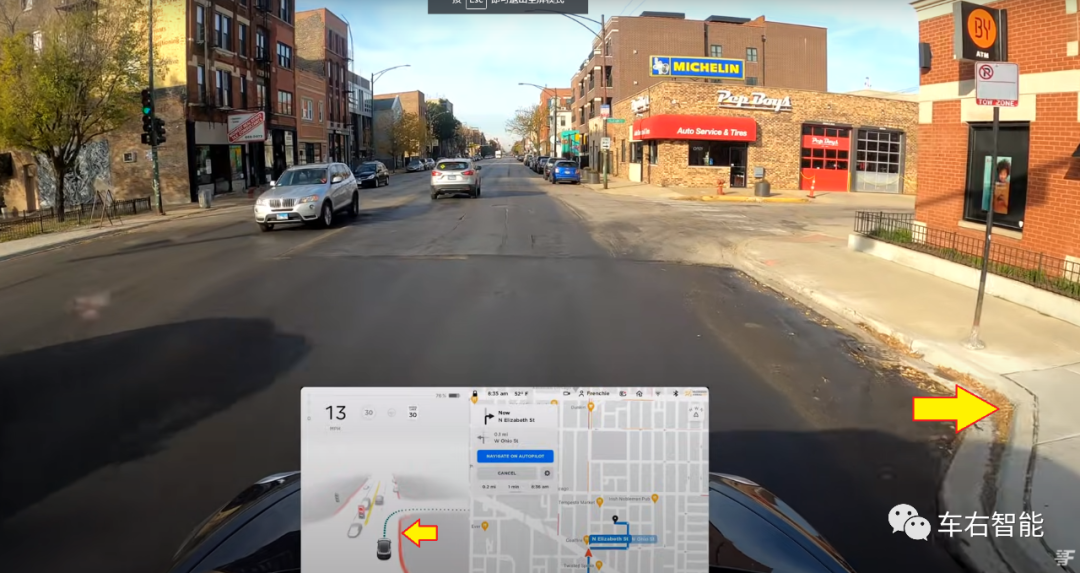
图五【Tesla transformer-38.png】来自Youtube站点博主@Frenchie的测试视频截图,URLhttps://www.youtube.com/watch?v=rfTpt8phxL4;
上图可以观察到FSD beta的中控屏幕显示的红色曲线为路缘石线条,由于基建处理路缘石的考量不仅仅是勾画车辆可行驶区域,相对地也要考虑行人道上的各种设备需求,因此它并不是一直和车道线保持并行,会有非规则曲线的场景出现。上图中这个场景下,显示的识别结果出现错误,且这个非规则的路缘石不可能用低次曲线拟合出来。
对于object和traffic light的预测分类(属性)和位置,则使用了classification、regression和attribution方法。类似的可以借鉴和查询的论文就更多了,YOLO系列就是一个完美的参考,互联网可查。
除了多头的任务本身,图四所显示的多任务架构还需要注意的是Tesla在Backbone和Head之间插入了一个叫做multi-scale features的cache环节。这个环节在模型的测试过程中扮演了关键角色。按照Karpathy的解释,训练过程如下:
1 首先进行的是end to end的联合训练,输入是视觉raw data,输出是所有任务的输出。监督所有子任务的准确度,并根据准确度进行干预(系统自动执行误差的反向传播)。这样的训练结果将会导致所有子任务的“集体最优结果”;
2 end to end的联合训练会导致子任务集体最优,但因为子任务之间不可能做到逻辑上的完全隔离,因此集体最优一定不是单个子任务的“个体最优结果”,因此需要以单个任务为核心进行调优fine tunning;
3 以单个子任务为核心的fine tunning的输入为经过联合调优后确立的backbone所输出的multi-scale features,从位于中部的那个cache里直接获取;输出则为各自子任务的输出,还是经过监督学习机制,最后将每个子任务收敛到各自的最优状态;
4 然后重复1的end to end联合训练……
上述这个迭代流程可以确保网络整体效能最优,且各个子任务的准确度最佳。横向看,这并非Tesla的专利(小编:尽管Tesla有训练多任务系统的一些专利,我们之前的文章有涉及过),业内处理自动驾驶系统内的多任务,大抵如此手法。但knowhow在于如何处理车载硬件的CPU算力——训练方法的有效性——最终模型输出的准确性,这三者之间的矛盾,达到和谐统一。这个Tesla当然不会细说,就比如这个cache内部的multi-scale feature,到底如何分配给不同的子任务可以协助子任务的预测水平实现最优?这就是Tesla的秘密了。
别的不好说,但是显然的是,谁的数据(有效数据)最多最丰富最极端corner,谁就最有把握接近最佳模型。Tesla虽然扔掉了所有的毫米波雷达回波数据,也不屑于Lidar的点云数据,但在视觉领域的积累应该还是有底气的。
截至目前,HydraNets架构已经可以支撑标准的L2自动驾驶业务了。对于Tesla来说,自从和Mobileye分手之后,HydraNets的框架就已经(也必须)开始部署了,无非是在框架内选择不同的具体技术进行性能更新而已。但实际上如果要往更高层级的自动驾驶自治迈进,对于HydraNets架构的扩展就势在必行了。

图六【Tesla transformer-39、40.png】来自Tesla AI day主题演讲视频截图,URLhttps://www.youtube.com/watch?v=j0z4FweCy4M&t=4115s;
以上两张图代表了两种不同级别的自动驾驶应用,想必各位读者已经耳熟能详了。前者是典型的单目摄像头所获取的信息,以及背后的多任务HydraNets NN架构的识别结果。从Mobileye开始普及典型的Level-2自动驾驶系统以来,Tesla Autopilot就一直是这个思路。唯一的变化就是2016年脱离和Mobileye的合作之后,Autopilot有一个阶段是采用了Camera+mm Radar的传感器组合,2021年上半年则转向Full vision。
上图前者的识别结果确实丰富,我们有过专门的公众号文章对Autopilot在这个阶段对于单目视觉信息的识别做了解读。但这个识别结果,哪怕融合了毫米波雷达的速度信息,支持更高等级的自动驾驶任务也是不够用的。所以才有了上图后者的需求,车辆哪怕是在封闭场地和低速的限制条件下,例如Smart summon(停车场智能召唤功能),也必须要掌握主车四周的全视角道路状态(可行驶区域),才有可能进行路径规划,并发现召唤者。注:上图中的九个视觉输出中有两个黑块,意味着车身一共8个摄像头,supper narrow遥距摄像头并在Smart summon中参与道路3D信息捕获和可行驶道路区域的识别。
对于Tesla Autopilot系统的识别堆栈谈到这里,读者应当注意这个主题的本质:花多少钱办多少事儿。迄今为止对于CNN Backbone和纯视觉的坚持,可以在大部分的Level-2任务上得到技术落地和回报,并在更大范畴的技术框架上一锤定音、不走回头路以适应越来越高的NN技术占比对于庞大有效的数据量的需求。只要这一步走对了,小编的角度看,Tesla就算成功了一半。自动驾驶系统在未来能走多远?走多快?这就不仅仅是一家公司的事情了,很多问题也还是基础科学、科学技术产业化的问题。举个非常简单的例子,纯视觉如何克服目标深度信息预测的准确度和时效性问题?神经网络算子新贵Transformer转战视觉信息处理的突破,是如何提供给Tesla一个良好的视觉场转化工具的?这里面有偶然,但更多是必然,我们相信只要走在正确的路上,困难就总是暂时的。
具体而言,当Tesla意识到前向单目摄像头所捕获的视觉信息,哪怕对其再精耕细作和堆砌大量数据训练出来的模型,这个能力进展也无法处理更高等级的自动驾驶技术需求的时候,并没有将现有识别堆栈推倒重来,而是继续向前选择了显性的C++人工代码试图提供车身四周完整的3D视角视觉信息……如下图:
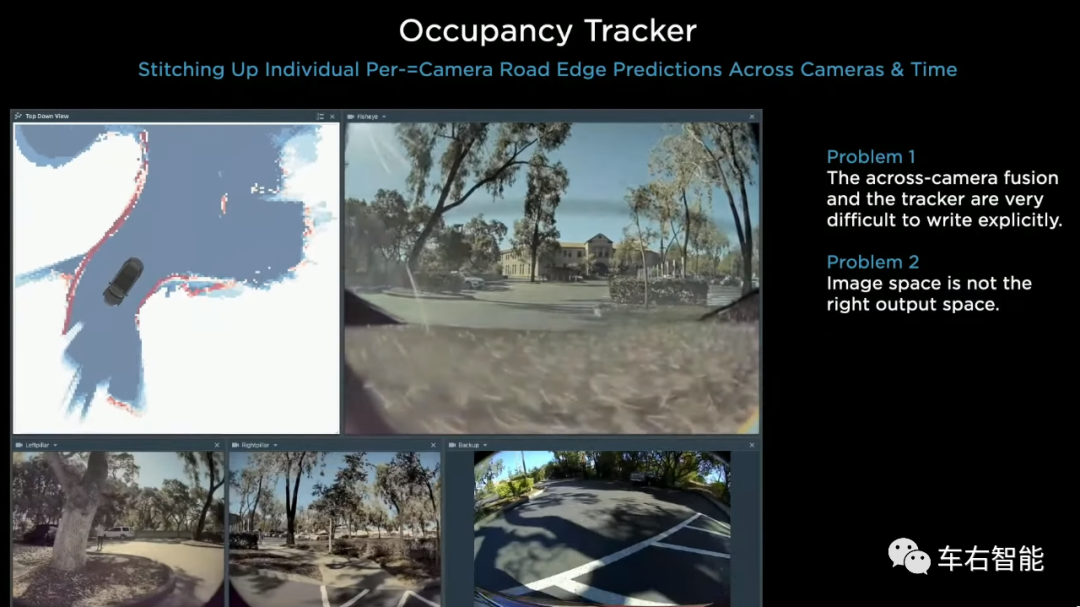
图七【Tesla transformer-41.png】来自Tesla AI day主题演讲视频截图,URLhttps://www.youtube.com/watch?v=j0z4FweCy4M&t=4115s;
这个被叫做“Occupancy Tracker”的人工代码被嵌入到Smart summon这个应用的Task head底部,完成从CNN backbone提取feature map后,需要参照车身摄像头的几何尺寸将其转换到路径规划所需要的Birds-view map。
360度的俯视图Birds-view map在大多数Level-2自动驾驶应用场景中,并非必要。但在更高等级的自动驾驶系统中,多传感器数据处理结果(小编:同构或者异构传感器都可以)终结在Birds-view map俯视图结构上,并提供给后端路径规划,还是最合适的。人类构建的公路系统是严格符合“连续平面”属性的,因此忽略高度信息的俯视图在规划中,比车载相机获取的或略深度信息的投影平面,更能表现出道路上各种物体的相对位置关系。但问题在于如果路面拓扑过于复杂,且视觉传感器会因为各种遮挡场景而只获取部分信息,在这个基础上,人工代码往往力不从心。
对于上图七的观察我们就可以看到,在CNN backbone上增加Birds-view map获取的“Occupancy Tracker”代码Head之后,可以实现从camera视觉信息到俯视图的转换,但问题同样明显:
1 Karpathy标识这段代码功能非常难以落地,具体表现为对于场景适应能力很差,可能在一部分场景下表现尚可,但一旦出现特殊的道路拓扑,就会失效;
2 精度问题。
上图七左上角是Birds-view map的输出结果,车辆左转弯之后,前方两侧都出现大面积的无法识别状态,右后侧出现识别精度大误差状态(红色线条重叠)。读者可以想象,一旦车速增加、出现大面积的路边遮挡物和道路拓扑剧烈改变等等,识别效果会进一步恶化。

图八【Tesla transformer-42.png】来自Tesla AI day主题演讲视频截图,URLhttps://www.youtube.com/watch?v=j0z4FweCy4M&t=4115s;
如果我们从smart summon应用再往前走一步,在所有道路条件下提供投影成像到Birds-view map的转换,再从路缘石边界(上图红色线条)扩展到对于车道线(上图蓝色箭头)的识别和转换视角,则之前的Occupancy tracker所面临的问题会被进一步放大。图八中,我们可以看到在camera投影视图中的路缘石边缘识别结果,因为天然在精度上的误差,经由精确的几何变换后,在俯视图上的误差得到进一步放大,甚至到会引发解读歧义的问题:认真看投影视图中的红色线条,是对路缘石的一种近似的拟合结果。CNN Backbone的各种CNN识别结果,在单目镜头的视觉投影信息中,只能依赖CNN的对于人类智能模拟之后的近似。Camera不可能提供和Lidar等同的测量精度,Camera+CNN更多意义上的操作本质是“预测”。因此,建立在预测结果上,对于近似的预测结果进行“硬桥硬马”的集合转换,结果就只能是这个水平。
图中的黄色和绿色箭头所指位置,投影成像的线条近似,被转换为以车辆摄像头为圆心的圆弧段,没错,Occupancy Tracker认为线段上的每一个点,到摄像头的距离都是一样的…….由此,更新Occupancy Tracker代码,使用同质的NN网络来模拟人类的预测行为,来完成这个视场转换任务,就是Autopilot识别堆栈的下一个核心重点了!
审核编辑 :李倩
-
堆栈
+关注
关注
0文章
183浏览量
20572 -
自动驾驶
+关注
关注
794文章
14979浏览量
181397 -
Autopilot
+关注
关注
0文章
44浏览量
7314
原文标题:Tesla Vision背后的变形金刚——系统需要的是测量还是预测?
文章出处:【微信号:阿宝1990,微信公众号:阿宝1990】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
芯片制造中的硅片表面细抛光与最终抛光加工工艺介绍

Hirose细间距高速线缆与线束设计实践与选型指南
在学单片机时在堆栈遇到的问题分享
I-PEX 细同轴线缆应用指南:高速摄像与高速接口的理想方案

单片机堆栈解析
堆栈的定义,堆栈的使用方法
极细同轴线束如何保障高速信号完整性?深度解析设计要点

如何精准驱动菜品识别模型--基于米尔瑞芯微RK3576边缘计算盒
米尔RK3576边缘计算盒精准驱动菜品识别模型性能强悍

空闲线程堆栈出现内存溢出的问题,怎么解决?
USB3.1传输能用极细同轴线吗?要注意哪些选型误区?

工程师如何为 MIPI 接口选择极细同轴线束?

极细同轴线束能做到多细?揭秘高速互连中的极限工艺




评论