 使用Merlin分层参数服务器扩展推荐系统推理
使用Merlin分层参数服务器扩展推荐系统推理

如今,推荐系统被广泛用于个性化用户体验,并在电子商务、社交媒体和新闻源等各种环境中提高客户参与度。因此,以低延迟和高精度服务用户请求对于维持用户参与至关重要。
这包括在使用最新更新无缝刷新模型的同时执行高速查找和计算,这对于模型大小超过 GPU 内存的大规模推荐者来说尤其具有挑战性。
NVIDIA Merlin HugeCTR ,一个开源框架,旨在优化 NVIDIA GPU 上的大规模推荐,最近发布 分层参数服务器( HPS )体系结构 以专门解决工业级推理系统的需求。实验表明,该方法能够在流行的基准数据集上以低延迟进行可拓展部署。
大规模推荐推理的挑战
大型嵌入表 :典型深度推荐模型的输入可以是数字(例如用户年龄或商品价格)或分类特征(例如用户 ID 或商品 ID )。与数字特征不同,分类特征需要转换为数字向量,以输入多层感知器( MLP )层进行密集计算。嵌入表学习从类别到数字特征空间的映射(“嵌入”),这有助于实现这一点。
因此,嵌入表是模型参数的一部分,并且可能是内存密集型的,对于现代推荐系统,可以达到 TB 级。这远远超出了现代 GPU 的板载存储容量。因此,大多数现有的解决方案都退回到在 CPU 内存中托管嵌入表,这没有利用高带宽 GPU 内存,从而导致更高的端到端延迟。
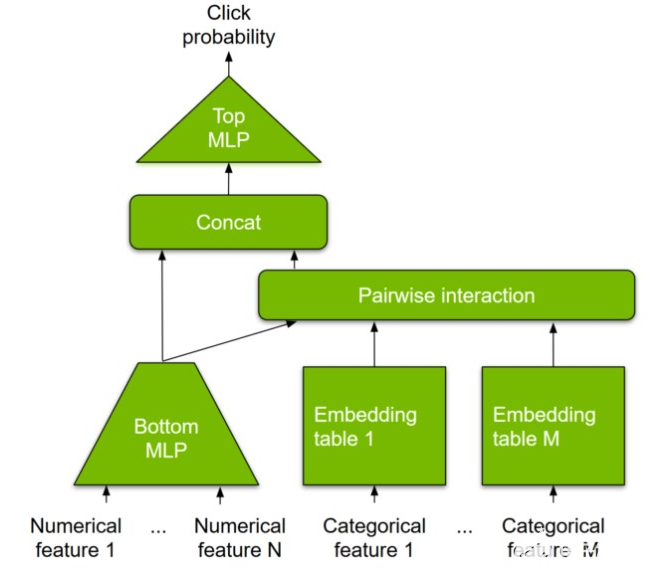
图 1.典型深度学习推荐模型示例。显示的架构是 个性化和推荐系统的深度学习推荐模型 。
可扩展性 :在用户行为的驱动下,许多客户应用程序被构建为服务于峰值使用,并且需要根据预期和实际负载扩展或扩展 AI 推理引擎的灵活性。
对不同框架和模型的高兼容性 :人工智能推理引擎必须能够服务于两种深度学习模型 ( 例如 DeepFM, DCN, DLRM, MMOE, DIN, 和 DIEN),由 TensorFlow 或 PyTorch 等框架以及简单的机器学习( ML )模型训练。此外,客户希望混合部署多个不同的模型架构和单个模型的多个实例。模型还必须部署在从云到边缘的各种硬件平台上。
部署新模型和在线培训更新 :客户希望能够根据市场趋势和新用户数据频繁更新其模型。模型更新应无缝应用于推理部署。
容错和高可用性 :客户需要保持相同级别的 SLA ,对于任务关键型应用程序,最好是五个 9 或以上。
下一节提供了更多有关 NVIDIA Merlin HugeCTR 如何使用 HPS 解决这些挑战的详细信息,以实现对建议的大规模推断。
分层参数服务器概述
分层参数服务器支持使用多级自适应存储解决方案部署大型推荐推理工作负载。为了存储大规模嵌入,它使用GPU 存储器作为第一级高速缓存,CPU 存储器作为二级缓存(如用于本地部署的 HashMap 和用于分布式的 Redis ),以及用于扩展存储容量(如 RocksDB )的 SSD 。
CPU 内存和 SSD 均可根据用户需求灵活配置。请注意,与嵌入相比,致密层( MLP )的尺寸要小得多。因此,密集层以数据并行的方式在各种 GPU 工作者之间复制。
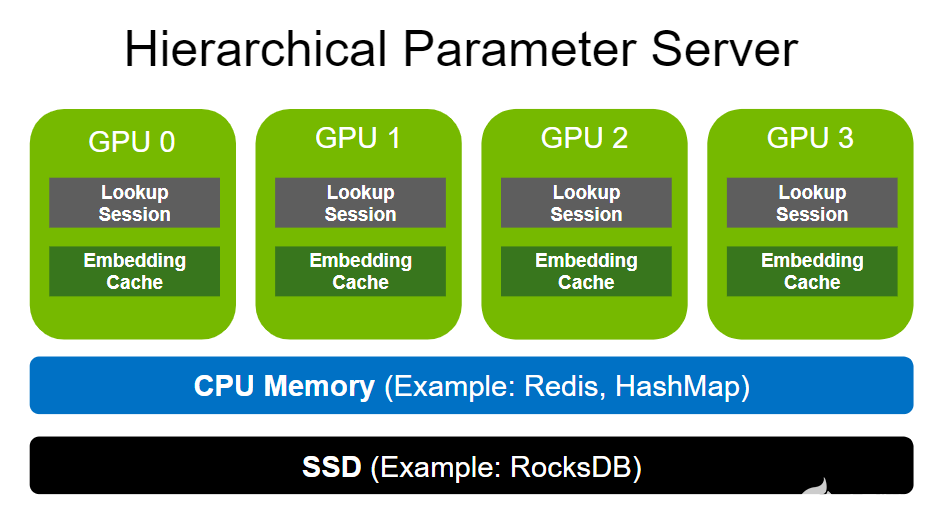
图 2. NVIDIA Merlin HugeCTR 分层参数服务器架构
GPU 嵌入缓存
GPU 的内存带宽比大多数 CPU 的内存宽度高一个数量级。例如, NVIDIA A100-80 GB 提供超过 2 TB / s 的 HBM2 带宽。 GPU 嵌入缓存通过将内存密集型嵌入查找移动到 GPU 中,更接近计算发生的位置,从而利用了如此高的内存带宽。
为了设计一个有效利用现代 GPU 提供的优势的系统,重要的是要注意一个关键观察:在现实世界的推荐数据集中,一些特征类别通常比其他特征类别出现得更频繁。例如 标准 1 TB 点击日志数据集 ,也是一个流行的基准数据集 用于 MLPerf 总共 188 米中的 305K 个类别(仅占 0.16% )被 95.9% 的样本引用。
这意味着某些嵌入的访问频率远远高于其他嵌入。嵌入键访问大致遵循幂律分布。因此,在 GPU 内存中缓存这些最频繁访问的参数将使推荐系统能够利用高 GPU 内存带宽。单个嵌入查找是独立的,这使得 GPU 成为向量查找处理的理想平台,因为它们能够同时运行数千个线程。
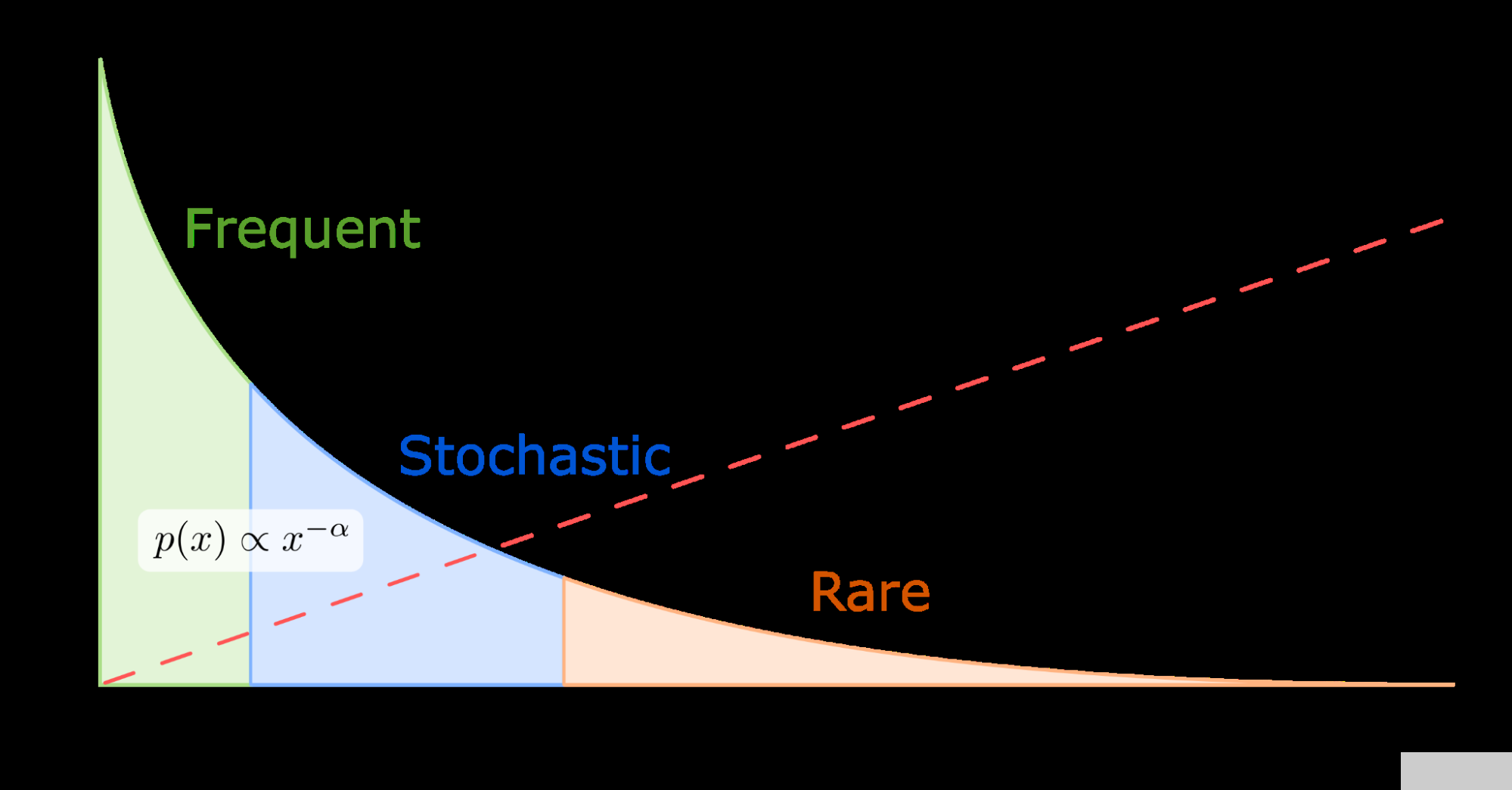
图 3.幂律分布的可视化
这些特性激发了 HPS GPU 嵌入缓存的设计,该缓存将热嵌入保留在[Z1K11]内存中,通过减少额外的或重复的参数在较慢的 CPU- GPU 总线上的移动来提高查找性能。它由保留所有嵌入表的完整副本的辅助存储器支持。下文将对此进行更全面的探讨。对于与 GPU 上托管的每个模型相关联的每个嵌入表,存在唯一的 GPU 嵌入缓存。
嵌入键插入机制
当在推理过程中 GPU 缓存中缺少查找到的嵌入键时,将触发键插入以从层次结构的较低级别获取相关数据。 HPS 实现了同步和异步键插入机制,以及用户定义的[VZX1 8],以在两个选项之间进行选择,以平衡准确性和延迟。
Synchronous insertion: 如果实际命中率低于命中率阈值,则在等待将丢失的键插入 GPU 缓存时,会阻止推理请求。这通常发生在模型刚加载时、预热期间或进行重要模型更新后。
Asynchronous insertion: 如果实际命中率高于命中率阈值,则立即返回预配置的默认向量,以允许查询管道继续执行,而不会延迟。“惰性”插入本身发生在后台。当已达到所需精度且主要关注点是保持低延迟时,使用该方法。在实际的行业场景中,即使缓存了完整模型,推理也可能仍然缺少功能,因为在推理中可能会出现从未出现在训练数据集中的新项目和用户。
GPU 嵌入缓存性能
图 4 显示了使用 标准 1 TB 点击日志数据集 和 90GB 个性化和推荐系统的深度学习推荐模型 NVIDIA T4 ( 16 GB 内存)、 A30 ( 24 GB 内存)和 A100 GPU ( 80 GB 内存)上的( DLRM )型号,缓存了型号大小的 10% 。命中率阈值设置为 1.0 ,以便所有键插入都是同步的。在稳定阶段进行测量。
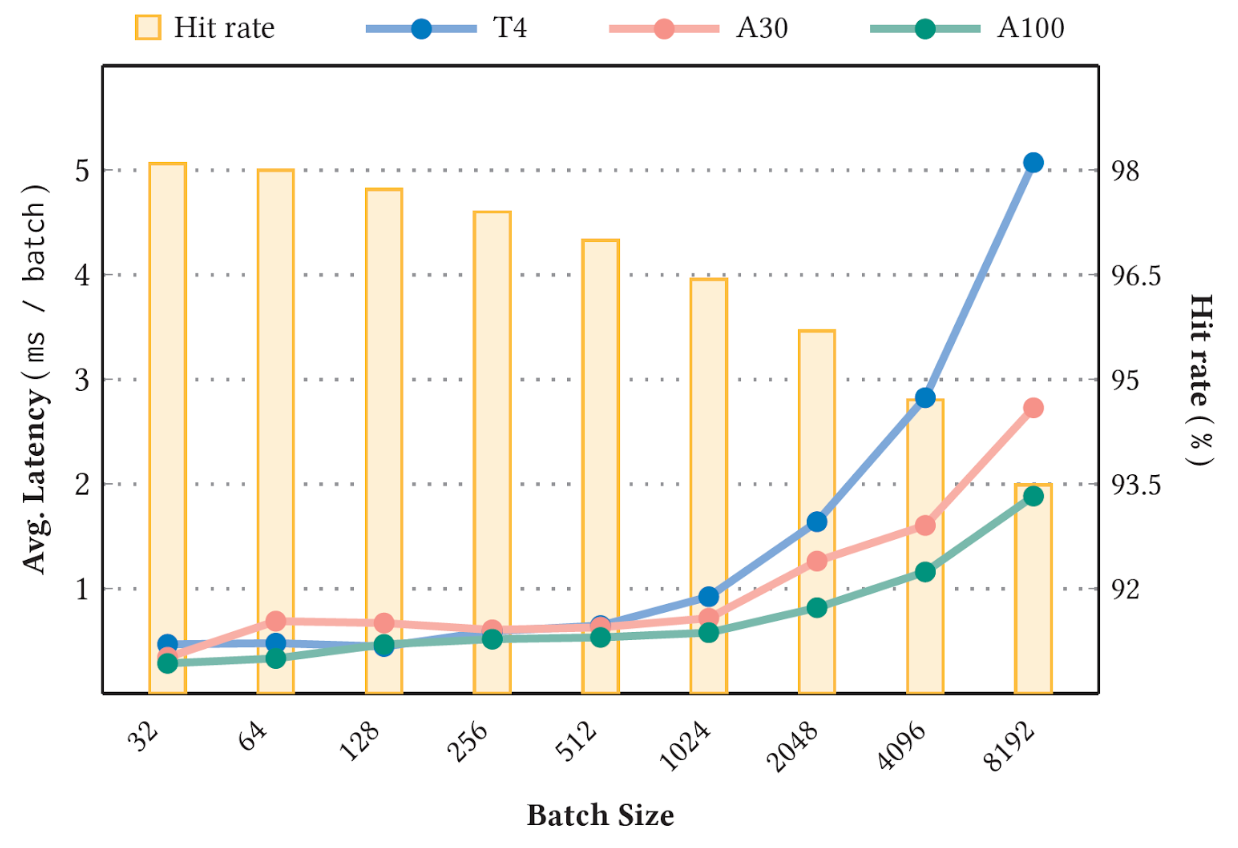
图 4.不同批量大小的平均延迟和 GPU 嵌入缓存命中率
可以预期,较高的稳定缓存命中率(图 4 中的条形图)对应于较低的平均延迟(图 4 的折线图)。此外,由于键丢失的可能性越来越大,更大的批大小也会导致命中率降低和延迟增加。有关基准的更多详细信息,请参阅 用于大规模深度推荐模型的 GPU 专用推理参数服务器 。
HPS 包括两个额外的层,通过利用CPU 存储器和 SSD 。这些层高度可配置,以支持各种后端实现。以下各节将更详细地介绍这些。
CPU 缓存
第二级存储是 CPU 缓存,通过 CPU- GPU 总线访问,并以较低的成本作为[Z1K11]嵌入缓存的扩展存储。如果 GPU 嵌入缓存中缺少嵌入键, HPS 接下来将查询 CPU 缓存。
如果找到键(缓存命中),则返回结果并记录访问时间。这些最后访问的时间戳用于以后的键逐出。
如果键丢失, HPS 将转到下一层获取嵌入,同时还调度将丢失的嵌入向量插入 CPU 缓存。
“ CPU 缓存”层支持各种数据库后端。 HugeCTR HPS 提供 易失性数据库示例 具有基于哈希映射的本地 CPU 内存数据库实现,以及 Redis 集群 – 基于后端,利用分布式集群实例进行可扩展部署。
固态硬盘
缓存层次结构的最低层以更低的成本在 SSD 、硬盘或网络存储卷上存储每个嵌入表的完整副本。对于表现出极端长尾分布的数据集(大量类别,其中许多类别不经常被引用),保持高精度对于手头的任务至关重要,这一点尤其有效。这个 HugeCTR HPS 参考配置 将嵌入表映射到 RocksDB 本地 SSD 上的数据库。
整个模型通过设计保存在每个推理节点中。这种资源隔离策略增强了系统可用性。即使在灾难性事件后只有一个节点是活动的,也可以恢复模型参数和推理服务。
增量训练更新
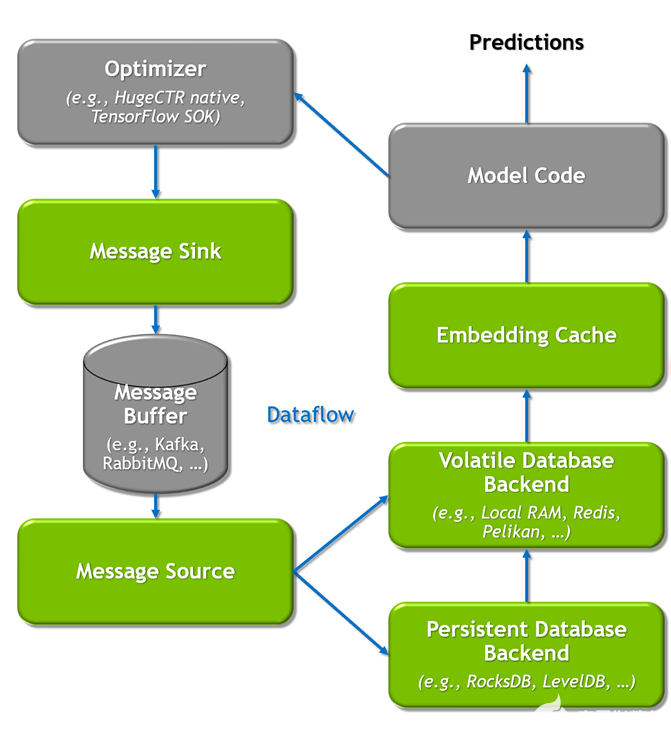
推荐模型有两种培训模式:离线和在线。在线培训将新的模型更新部署到实时生产中,对于推荐的有效性至关重要。 HPS 雇佣 无缝更新机制 通过 Apache Kafka – 基于消息缓冲区连接训练和推理节点,如图 5 所示。
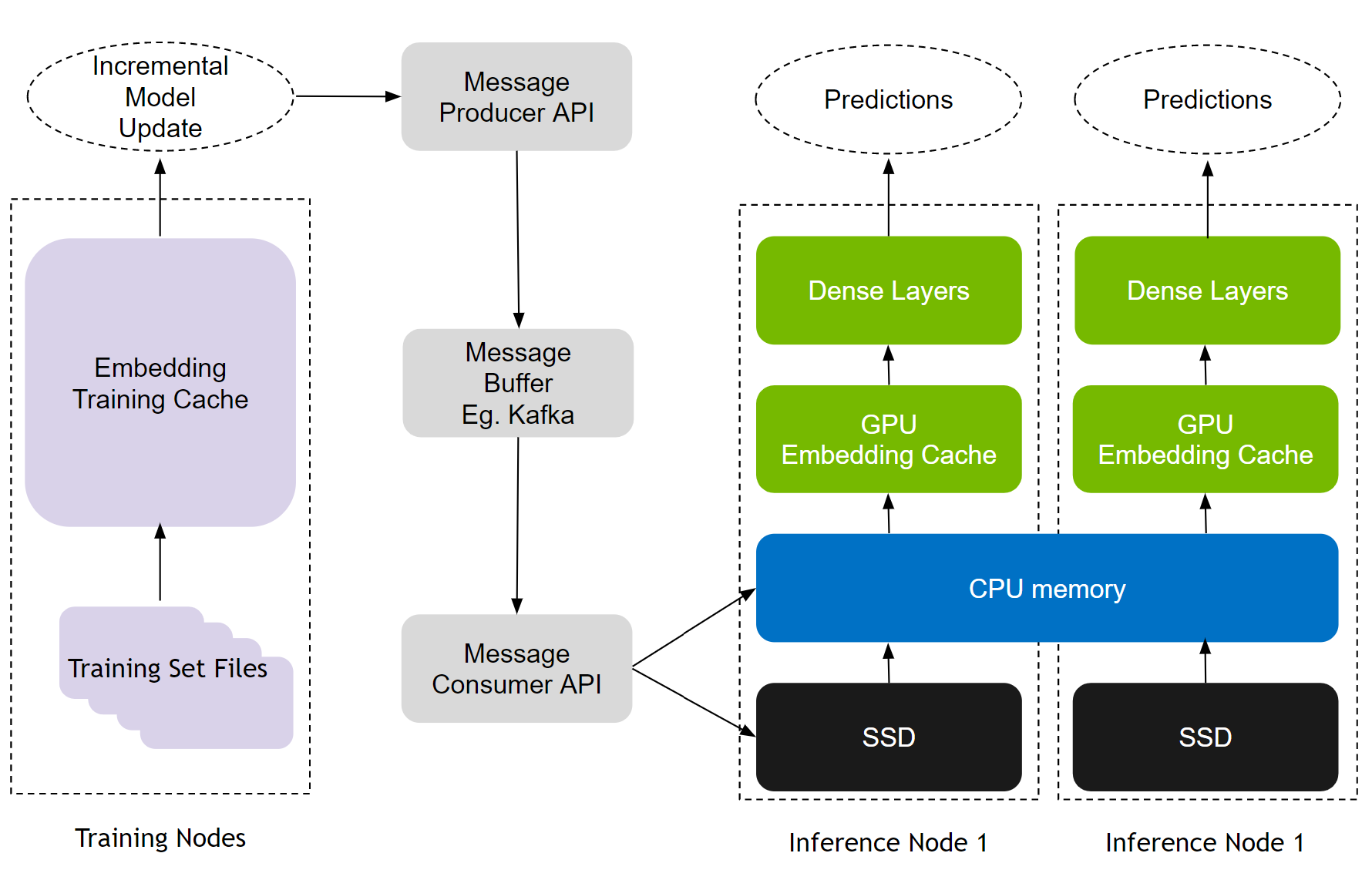
图 5. HugeCTR 推理在线更新机制
更新机制有助于 MLOps 工作流,支持在线/频繁以及离线/再培训更新,无需停机。它还通过设计赋予了容错能力,因为即使推理服务器关闭,训练更新也会继续在 Kafka 消息缓冲区中排队。通过方便易用的 Python API ,开发人员可以使用所有这些功能。
HPS 性能基准
为了证明 HugeCTR HPS 的优势,我们评估了其在 DLRM 模型上的端到端推理性能,并 标准 1 TB 点击日志数据集 ,并将其与仅在 GPU 上运行密集层计算和仅 CPU 解决方案的场景进行了比较。
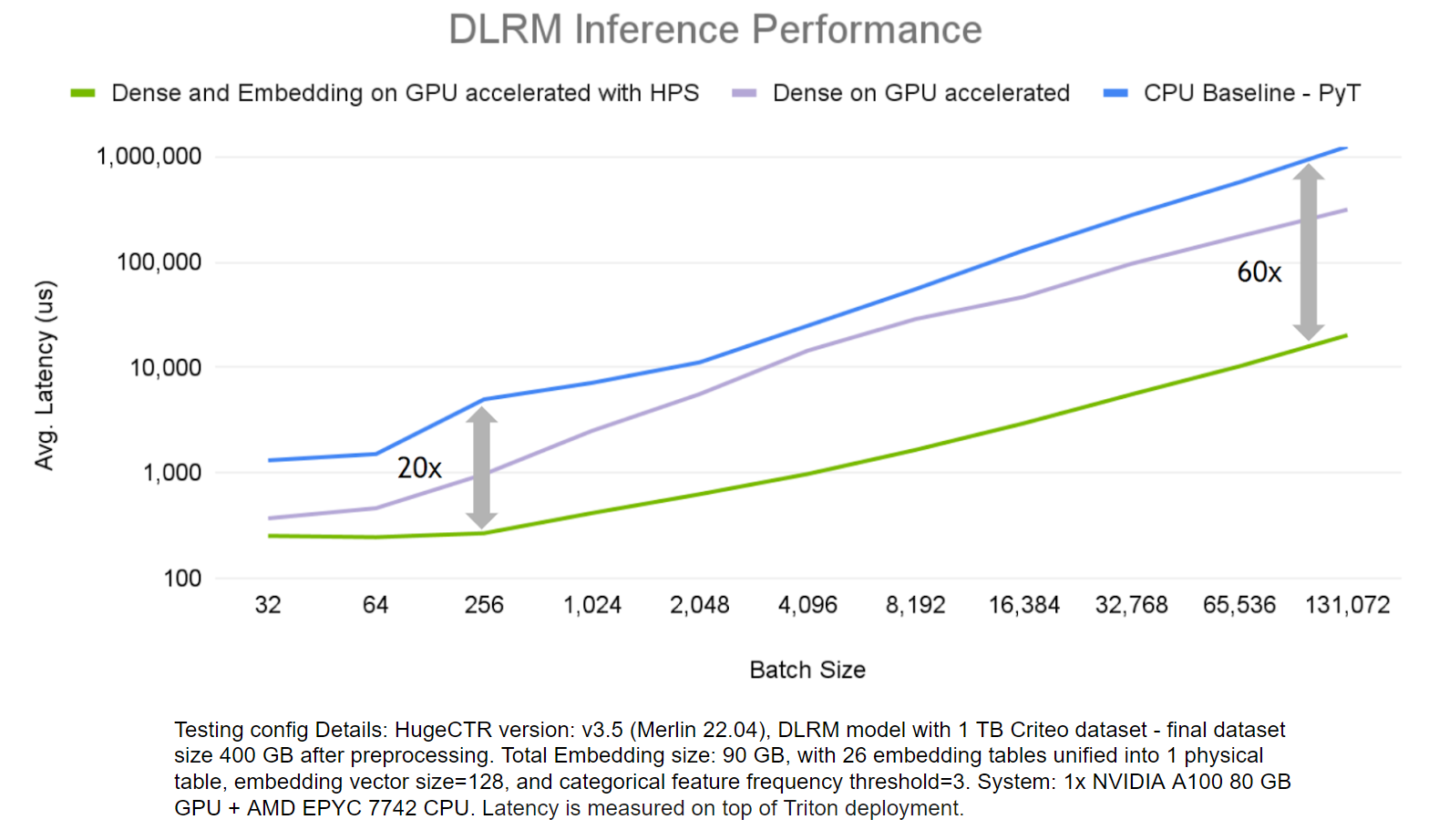
图 6.推理性能比较
HPS 解决方案加快了嵌入和密集层的速度,远远优于仅使用 CPU 的解决方案,在更大批量的情况下,其速度高达 60 倍。
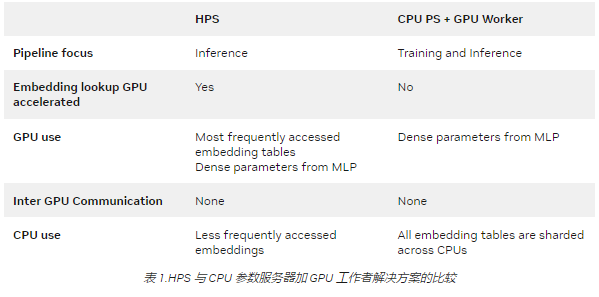
HPS 与 CPU PS 加 GPU 工作解决方案的区别
您可能熟悉 CPU 参数服务器( PS )和 GPU 工作解决方案。表 1 显示了 HPS 与大多数 PS plus worker 解决方案的不同之处。
总结
本文介绍了 Merlin HugeCTR HPS ,其中 GPU 嵌入缓存作为一种工具,用于加速 NVIDIA GPU 上大规模嵌入的推理。 HPS 方便易用 配置 ,包括 例子 让你开始。还将有一个 TensorFlow 插件 这使得能够在现有 TF 推理管道中使用 HPS 。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
5731浏览量
110329 -
gpu
+关注
关注
28文章
5335浏览量
136251 -
服务器
+关注
关注
14文章
10459浏览量
91875
发布评论请先 登录
服务器特点
云服务器与物理服务器的区别是什么?
服务器配置参数主要有哪些
基于SNMP Agent扩展的服务器监
Merlin HugeCTR分级参数服务器:缓存和在线更新设计
使用MIG和Kubernetes部署Triton推理服务器
NVIDIA Triton推理服务器的功能与架构简介
AI服务器与传统服务器的区别是什么?
使用NVIDIA Triton推理服务器来加速AI预测
国产推理服务器如何选择?深度解析选型指南与华颉科技实战案例

AI 推理服务器都有什么?2025年服务器品牌排行TOP10与选购技巧




评论