 在Azure机器学习上提高人工智能模型推理性能
在Azure机器学习上提高人工智能模型推理性能

每个 AI 应用程序都需要强大的推理引擎。无论您是部署图像识别服务、智能虚拟助理还是欺诈检测应用程序,可靠的推理服务器都能提供快速、准确和可扩展的预测,具有低延迟(对单个查询的响应时间较短)和高吞吐量(在给定时间间隔内处理大量查询)。然而,检查所有这些方框可能很难实现,而且成本高昂。
团队需要考虑部署可以利用以下功能的应用程序:
具有独立执行后端的多种框架( ONNX 运行时、 TensorFlow 、 PyTorch )
不同的推理类型(实时、批量、流式)
用于混合基础设施( CPU 、 GPU )的不同推理服务解决方案
可以显著影响推理性能的不同模型配置设置(动态批处理、模型并发)
这些要求使人工智能推理成为一项极具挑战性的任务,可以通过 NVIDIA Triton 推理服务器 。
这篇文章提供了一个逐步提高 AI 推理性能的教程 Azure 机器学习 使用 NVIDIA Triton 模型分析仪和 ONNX 运行时橄榄 ,如图 1 所示。
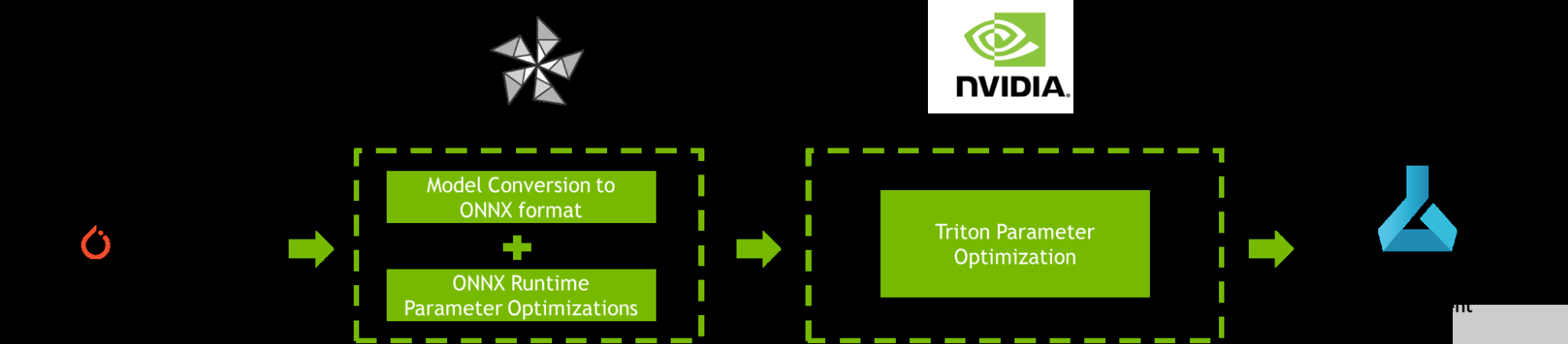
图 1.使用 ONNX 运行时、 OLive 、 Triton 模型分析器和 Azure 机器学习优化 PyTorch 模型的工作流
工作流优化的机器学习模型
为了提高 AI 推理性能, ONNX Runtime OLive 和 Triton 模型分析器在模型部署之前自动执行参数优化步骤。这些参数定义了底层推理引擎将如何执行。您可以使用这些工具来优化 ONNX 运行时参数 (执行提供程序、会话选项和精度参数),以及 Triton 参数 (动态批处理和模型并发参数)。
阶段 1 : ONNX 运行时橄榄优化
如果 Azure 机器学习是您部署 AI 应用程序的地方,那么您可能熟悉 ONNX 运行时。 ONNX Runtime 是微软的高性能推理引擎,用于跨平台运行 AI 模型。它可以跨多种配置设置部署模型,目前 Triton ®声波风廓线仪支持。微调这些配置设置需要专门的时间和领域专业知识。
OLive ( ONNX Runtime Go Live )是一个 Python 包,通过使用 ONNX 运行时自动化加速模型的工作来加速此过程。它提供了两种功能:将模型转换为 ONNX 格式和自动调整 ONNX 运行时参数,以最大化推理性能。运行 OLive 将隔离并推荐 ONNX 运行时配置设置,以获得最佳核心 AI 推理结果。
您可以使用以下 ONNX 运行时参数使用 OLive 优化 ONNX Runtime BERT 小队模型:
执行提供程序:ONNX Runtime 通过其可扩展执行提供程序( EP )框架与不同的硬件加速库协作,以在硬件平台上优化运行 ONNX 模型,该框架可以利用平台的计算能力优化执行。 OLive 探索了以下执行提供程序的优化:针对 CPU 的 MLA (默认 CPU EP )、英特尔 DNNL 和 OpenVino 、针对 GPU 的 NVIDIA CUDA 和 TensorRT 。
会话选项:OLive 浏览 ONNX 运行时会话选项,以找到线程控制的最佳配置,包括 inter_op_num_threads、intra_op_num_threads、execution_mode和graph_optimization_level。
精度:OLive 以不同的精度级别评估性能,包括float32和float16,并返回最佳精度配置。
在运行了优化之后,您仍然可能会在应用程序级别上留下一些性能。使用 Triton 模型分析器可以进一步提高端到端吞吐量和延迟,该分析器能够支持优化的 ONNX 运行时模型。
第 2 阶段: Triton 模型分析器优化
NVIDIA Triton 推理服务器 是一款开源推理服务软件,有助于标准化模型部署和执行,并在生产中提供快速、可扩展的人工智能推理。图 2 显示了 Triton 推理服务器在与客户端应用程序和多个 AI 模型集成时如何管理客户端请求。
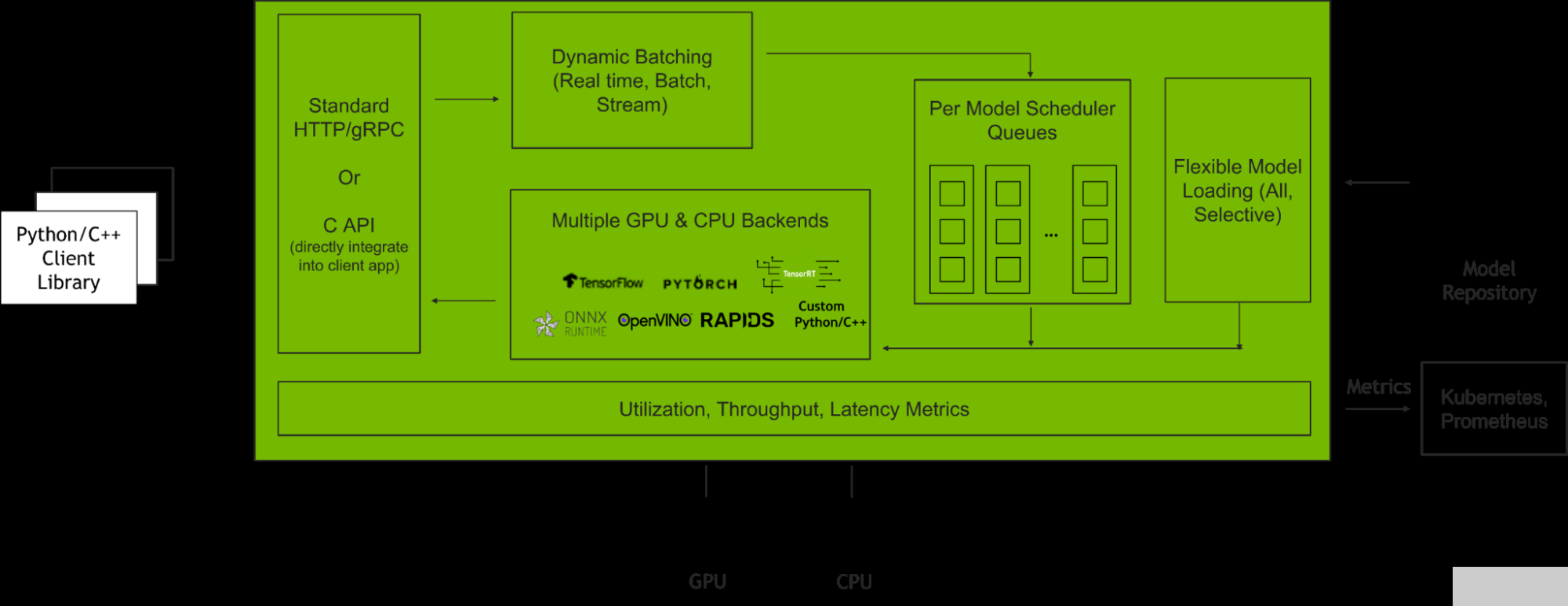
图 2. Triton 推理服务器如何管理客户端请求
这篇文章将着重于使用 Triton 模型分析器优化两个主要的 Parabricks 特性:
动态配料:Triton 允许服务器组合推理请求,以便动态创建批处理。这导致在固定延迟预算内增加吞吐量。
并发模型:Triton 允许同一模型的多个模型或实例在同一系统上并行执行。这导致吞吐量增加。
当以最佳级别部署时,这些功能非常强大。当以次优配置部署时,性能会受到影响,使终端应用程序容易受到当前苛刻的服务质量标准(延迟、吞吐量和内存要求)的影响。
因此,基于预期用户流量优化批量大小和模型并发级别对于充分挖掘 Triton 的潜力至关重要。这些优化 模型配置设置 将在严格的延迟约束下提高吞吐量,在部署应用程序时提高 GPU 利用率。该过程可以使用 Triton 模型分析仪实现自动化。
给定一组约束,包括延迟、吞吐量目标或内存占用, Triton 模型分析器根据批量大小、模型并发性或其他[ZGK22]模型配置设置的不同级别,搜索并选择最大化推理性能的最佳模型配置。部署和优化这些功能后,您将看到令人难以置信的结果。
教程:开始优化推理性能
在 Azure 机器学习上使用 ONNX Runtime OLive 和 Triton 模型分析器部署优化的机器学习模型需要四个步骤:
发射 Azure 虚拟机 使用 NVIDIA GPU 优化的虚拟机映像( VMI )
在模型上执行 ONNX 、 Runtime 、 OLive 和 Triton 模型分析器参数优化
分析和自定义结果
将优化的 Triton ONNX 运行时模型部署到 Azure 机器学习端点上
要完成本教程,请确保您有一个 Azure 帐户,可以访问 NVIDIA GPU 支持的虚拟机。例如,使用 Azure ND A100 v4 系列 虚拟机 NVIDIA A100 GPU , NCasT4 v3 系列 对于 NVIDIA T4 GPU 或 NCv3 系列 适用于 NVIDIA V100 GPU 。虽然建议使用 ND A100 v4 系列以获得最大规模的性能,但本教程使用标准的 NC6s _ v3 虚拟机,使用单个 NVIDIA V100 GPU 。
步骤 1 :使用 NVIDIA 的 GPU 优化 VMI 启动 Azure 虚拟机
本教程使用 NVIDIA GPU 优化 VMI 在 Azure 市场上可用。它预先配置了 NVIDIA GPU 驱动程序、 CUDA 、 Docker 工具包、运行时和其他依赖项。此外,它还为开发人员构建 AI 应用程序提供了一个标准化堆栈。
为了最大限度地提高性能, NVIDIA 每季度对该 VMI 进行验证和更新,并提供最新的驱动程序、安全补丁和对最新 GPU 的支持。
有关如何在 Azure VM 上启动和连接 NVIDIA GPU 优化 VMI 的详细信息,请参阅 Azure 虚拟机上的 NGC 文档 。
第 2 步:执行 ONNX Runtime OLive 和 Triton 模型分析器优化
使用 SSH 连接到 Azure 虚拟机并加载 NVIDIA GPU 优化的 VMI 后,即可开始执行 ONNX Runtime OLive 和 Triton 模型分析器优化。
首先,克隆 GitHub 存储库并通过运行以下命令导航到内容根目录:git clone https://github.com/microsoft/OLive.git
接下来,加载Triton 服务器容器请注意,本教程使用版本号 22.06 。
docker run --gpus=1 --rm -it -v “$(pwd)”:/models nvcr.io/nvidia/tritonserver:22.06-py3 /bin/bash
加载后,导航到安装 GitHub 材料的/models文件夹:
cd /models
下载 OLive 和 ONNX 运行时包,以及要优化的模型。然后,通过设置以下环境变量,指定要优化的模型的位置:
导出模型_位置= https://olivewheels.blob.core.windows.net/models/bert-base-cased-squad.pth
导出模型_文件名= bert-base-cased-squad.pth
您可以使用您选择的模型调整上面提供的位置和文件名。为了获得最佳性能,请直接从 NGC 目录 这些模型被训练到高精度,并且具有高级证书和代码样本。
接下来,运行以下脚本:
bash download.sh $model_location $export model_filename
脚本将下载三个文件到您的机器上:
-
橄榄包装:
onnxruntime_olive-0.3.0-py3-none-any.whl -
ONNX 运行时包:
onnxruntime_gpu_tensorrt-1.9.0-cp38-cp38-linux_x86_64.whl -
PyTorch Model:
bert-base-cased-squad.pth
在运行图 1 中的管道之前,首先通过设置环境变量指定其输入参数:
-
出口
model_name=bertsquad -
出口
model_type=pytorch -
出口
in_names=input_names,input_mask,segment_ids -
出口
in_shapes=[[-1,256],[-1,256],[-1,256]] -
出口
in_types=int64,int64,int64 -
出口
out_names=start,end
参数in_names、in_shapes和in_types指模型预期输入的名称、形状和类型。在这种情况下,输入是长度为 256 的序列,但它们被指定为[-1256],以允许对输入进行批处理。您可以更改与模型及其预期输入和输出相对应的参数值。
现在,您可以通过执行以下命令来运行管道:
bash optimize.sh $model_filename $model_name $model_type $in_names $in_shapes $in_types $out_names
该命令首先安装所有必要的库和依赖项,并调用 OLive 将原始模型转换为 ONNX 格式。
接下来,调用 Triton 模型分析器,自动生成带有模型元数据的模型配置文件。然后将配置文件传递回 OLive ,以通过前面讨论的 ONNX 运行时参数(执行提供程序、会话选项和精度)进行优化。
为了进一步提高吞吐量和延迟,然后将 ONNX 运行时优化的模型配置文件传递到 Triton 模型库中,供 Parabricks 模型分析器工具使用。 Triton 模型分析器然后运行profile命令,它设置优化搜索空间,并使用.yaml配置文件指定 Triton 模型存储库的位置(见图 3 )。
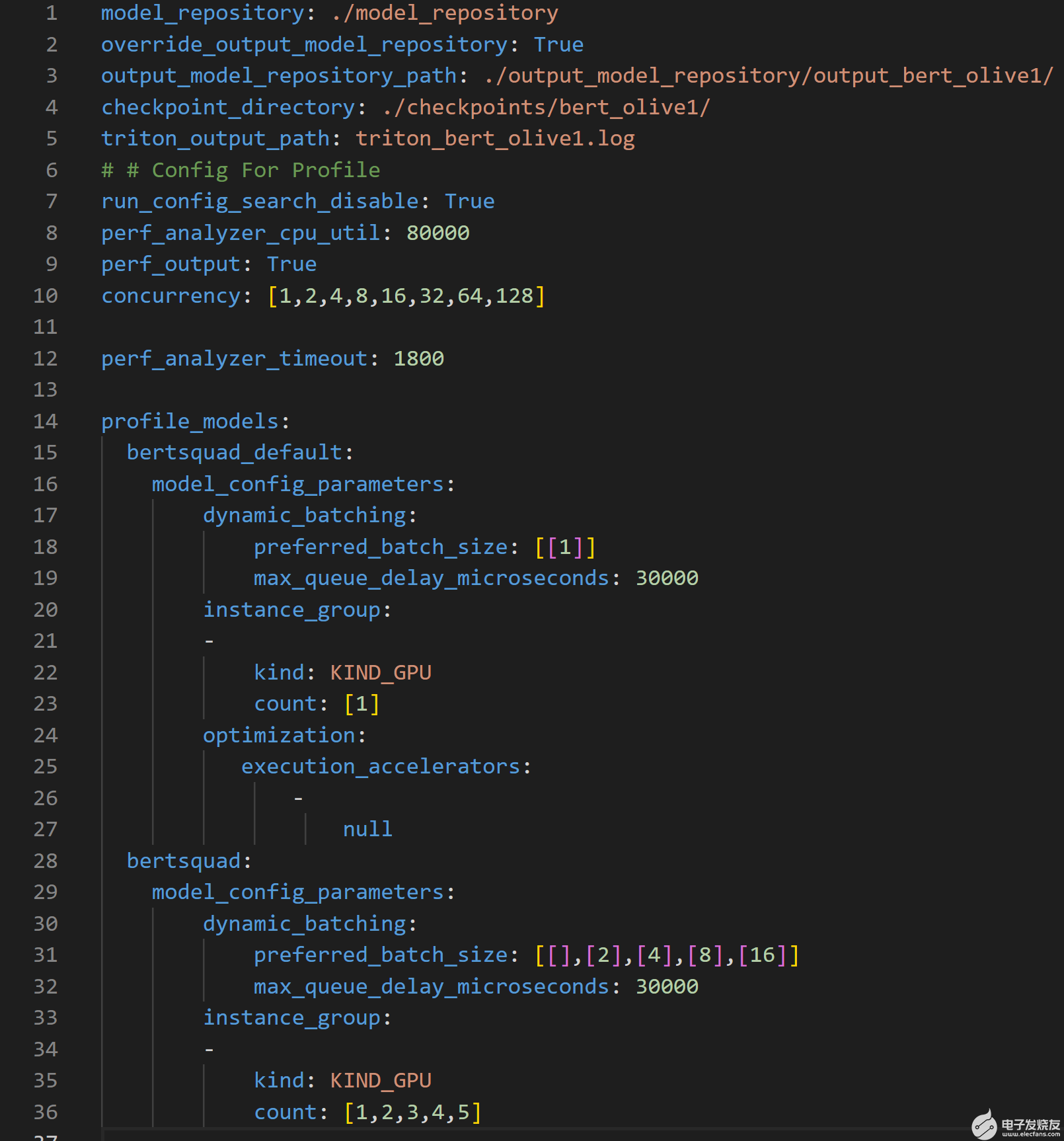
图 3.概要配置文件概述了 Triton 模型分析器搜索空间,以优化推理性能
上述配置文件可用于以多种方式自定义 Triton 模型分析器的搜索空间。该文件需要模型存储库的位置、要优化的参数及其范围,以创建 Triton 模型分析器用于查找最佳配置设置的搜索空间。
第 1-5 行指定了重要的路径,例如优化模型所在的输出模型存储库的位置。
第 10 行指定了参数 concurrency ,该参数指定了要由性能分析器,它模拟用户流量。
第 15 行指定了bert_default 模型,其对应于从 PyTorch 到 ONNX 转换获得的默认模型。该模型是基线模型,因此使用了动态批处理(第 17 行)和模型并发(第 20 行)的非优化值
第 19 行和第 32 行显示了在优化过程中必须满足的 30ms 延迟约束。
第 28 行指定了bertsquad 模型,其对应于橄榄优化模型。此模型与bert_default模型不同,因为此处的动态批处理参数搜索空间设置为 1 、 2 、 4 、 8 和 16 ,模型并发参数搜索空间设为 1 、 3 、 4 和 5 。
profile命令记录每个并发推理请求级别的结果,并且对于每个并行推理请求级别,记录 25 个不同参数的结果,因为动态批处理和模型并发参数的搜索空间分别具有五个唯一值,总计等于 25 个不同的参数。请注意,运行此操作所需的时间将随着图 3 中概要文件配置文件中搜索空间中提供的配置数量的增加而增加。
脚本然后运行Triton 模型分析仪分析命令使用图 4 所示的附加配置文件来处理结果。该文件指定了输出模型存储库的位置,其中通过profile命令生成结果,以及将记录性能结果的 CSV 文件的名称。
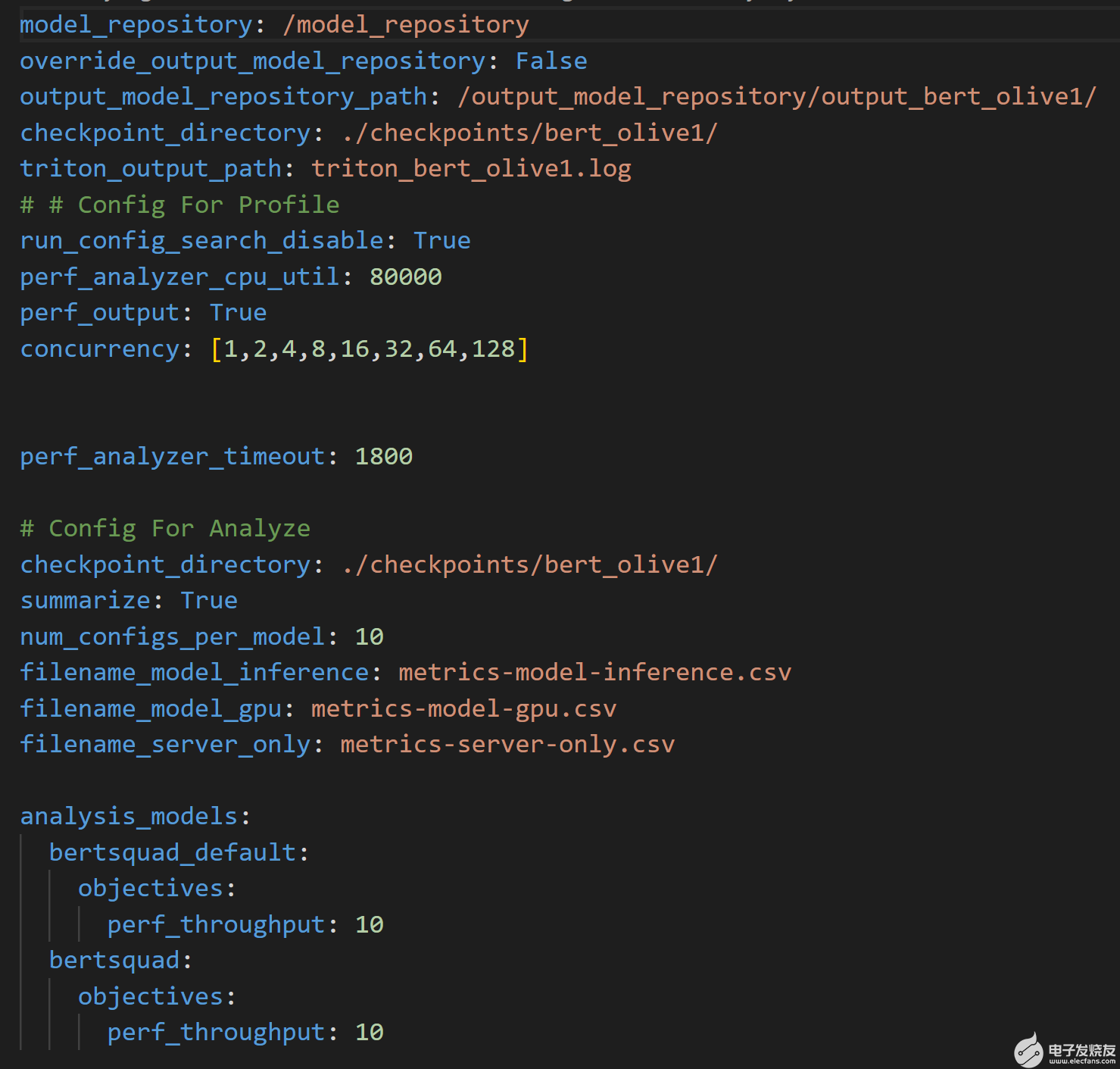
图 4.分析用于运行analyze命令的配置文件,并处理profile命令的结果
虽然profile和analyze命令可能需要几个小时才能运行,但优化的模型配置设置将确保部署的模型具有强大的长期推理性能。对于较短的运行时间,调整模型配置文件(图 3 ),在希望优化的参数上使用较小的搜索空间。
演示运行完成后,将生成两个文件: optim _ Results 。 png ,如图 5 所示,以及 Optimal _ ConfigFile _ Location 。 txt ,表示要部署在 Azure 机器学习上的最佳配置文件的位置。建立非优化基线(蓝线)。通过 OLive 优化实现的性能提升如图所示(浅绿线),以及 OLive + Triton 模型分析器优化(深绿线)。
步骤 3 :分析性能结果
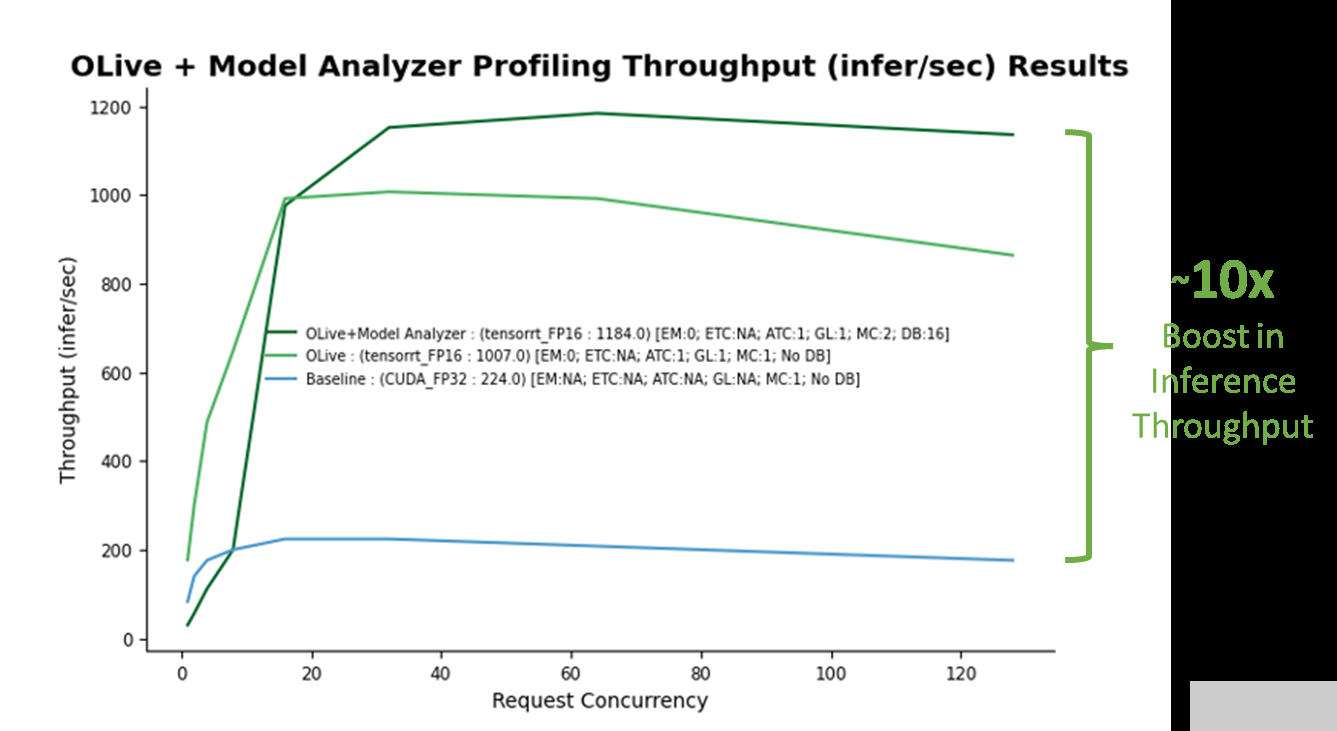
图 5.在使用单个 V100 NVIDIA GPU 的 Azure 虚拟机( Standard _ NC6s _ v3 )上应用 OLive plus Triton Model Analyzer 优化配置设置时,推理吞吐量提高了 10 倍。(注意:这不是官方基准。)
基线对应于具有非优化 ONNX 运行时参数( CUDA 后端,具有全精度)和非优化 Triton 参数(无动态批处理和模型并发)的模型。随着基线的建立,很明显,从 OLive 和 Triton 模型分析器在各种推理请求并发级别( x 轴)上的优化中获得的推理吞吐量性能( y 轴)有了很大提升,仿真结果如下:Triton 性能分析仪,一种通过生成推理请求来模拟用户流量的工具。
OLive 优化通过以混合精度将执行提供程序调整为 TensorRT 以及其他 ONNX 运行时参数,提高了模型性能(浅绿线)。然而,这显示了没有 Triton 动态批处理或模型并发的性能。因此,可以使用 Triton 模型分析器进一步优化该模型。
Triton 模型分析器在优化模型并发性和动态批处理后,进一步将推理性能提高了 20% (深绿线)。 Triton 模型分析器选择的最终最佳值是两个模型并发性(两个 BERT 模型副本将保存在 GPU 上)和 16 个最大动态批处理级别(一次最多 16 个推理请求将一起批处理)。
总体而言,使用优化参数的推理性能增益超过 10 倍。
此外,如果您希望应用程序具有特定级别的推理请求,则可以通过配置Triton perf_analyzer.您还可以调整模型配置文件,以包括:要优化的其他参数例如延迟分批。
您现在可以使用 Azure 机器学习部署优化模型了。
步骤 4 :将优化模型部署到 Azure 机器学习端点
部署优化的人工智能模型,以便在使用 Triton 的 Azure 机器学习涉及使用托管在线端点和Azure 机器学习工作室没有代码接口。
托管在线端点帮助您以交钥匙方式部署 ML 模型。它负责服务、扩展、保护和监控您的模型,将您从设置和管理底层基础设施的开销中解放出来。
要继续,请确保已下载Azure CLI,并且手头有图 6 所示的 YAML 文件。
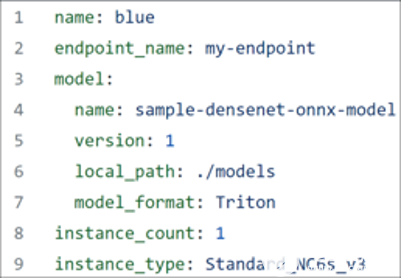
图 6.优化 BERT 模型的 YAML 文件
第一注册您的模型使用上述 YAML 文件以 Triton 格式。您注册的模型应该类似于图 7 ,如模型所示 Azure 机器学习工作室的页面。
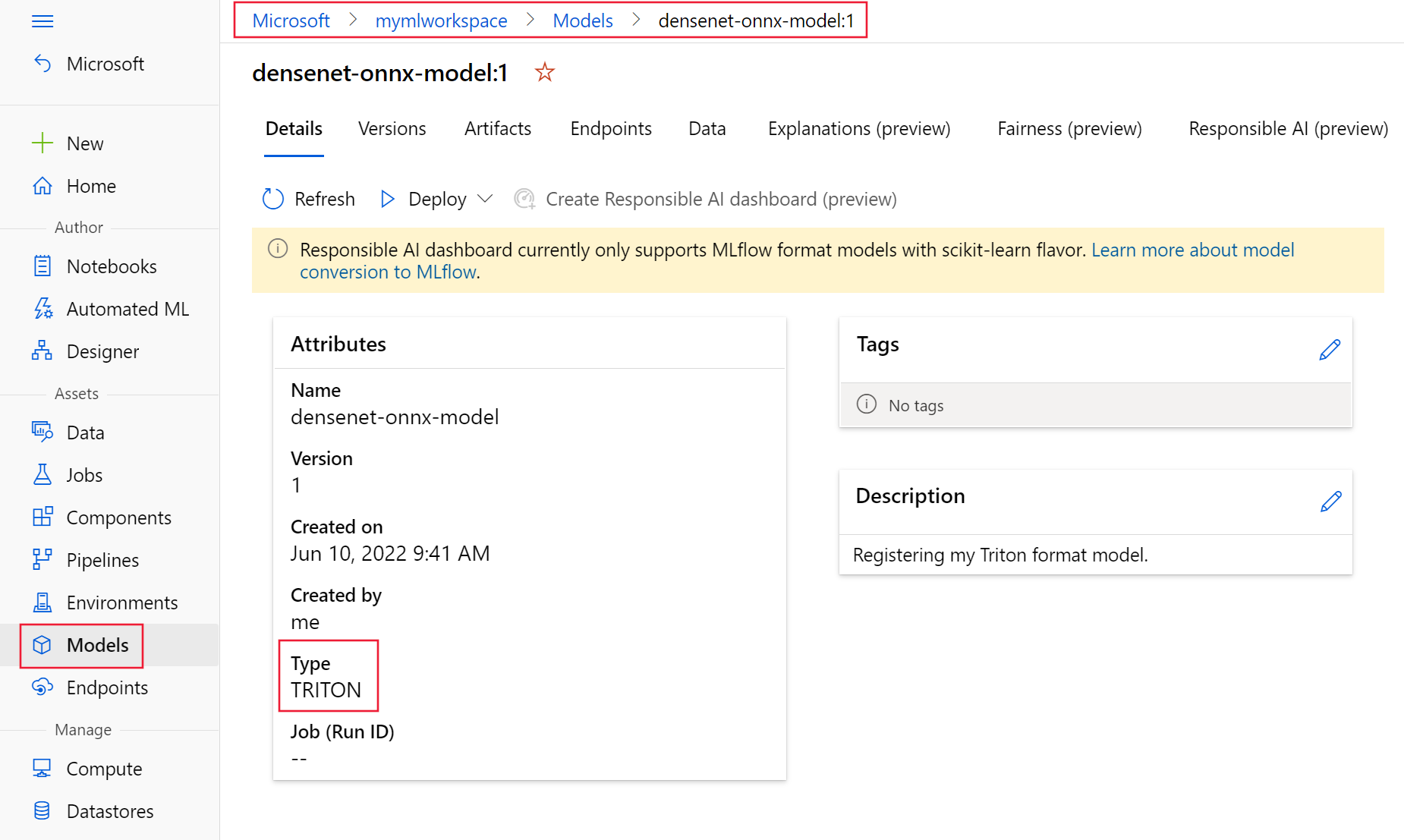
图 7.Azure 机器学习工作室注册的优化模型
接下来,选择 Triton 模型,选择“部署”,然后选择“部署到实时端点”继续通过向导将 ONNX 运行时和 Triton 优化模型部署到端点。请注意,将 Triton 模型部署到 Azure 机器学习管理端点时,不需要评分脚本。
祝贺现在,您已经在 Azure 机器学习上部署了一个 BERT 小队模型,该模型使用 ONNX 运行时和 Triton 参数优化了推理性能。通过优化这些参数,相对于未优化的基线 BERT 小队模型,您的性能提高了 10 倍。
关于作者
Manuel J.Reyes Gomez 是一位经验丰富的数据科学和机器学习实践者。他还是微软公司的 NVIDIA 开发者关系经理,负责监督两家公司之间的协作 AI 和 ML 项目。
Emma Ning 是微软人工智能框架团队的主要项目经理,专注于人工智能模型的操作和加速,以及开放和可互操作人工智能的 ONNX / ONNX 运行时。她在利用机器学习技术的搜索引擎领域拥有超过五年的产品经验,并花了六年多的时间探索人工智能在各种企业中的应用。她热衷于引入人工智能解决方案来解决业务问题,并提高产品体验。
Lei Qiao 是微软人工智能框架团队的软件工程师,专注于深度学习模型推理加速。她在将这些加速技术集成到不同的机器学习平台方面也很有经验。
Rohil Bhargava 是 NVIDIA 的产品营销经理,专注于在特定 CSP 平台上部署 NVIDIA 应用程序框架和 SDK 。在加入 NVIDIA 之前,罗希尔曾担任金融服务行业的顾问和产品经理。他的工作加速了人工智能在银行遗留决策过程中的采用和分析工作流。他目前在卡内基梅隆大学攻读技术战略 MBA ,并拥有西北大学工业工程和经济学学士学位。
审核编辑:郭婷
-
服务器
+关注
关注
13文章
10093浏览量
90895 -
人工智能
+关注
关注
1813文章
49741浏览量
261575 -
机器学习
+关注
关注
66文章
8541浏览量
136236
发布评论请先 登录
使用OpenVINO将PP-OCRv5模型部署在Intel显卡上
利用超微型 Neuton ML 模型解锁 SoC 边缘人工智能
挖到宝了!人工智能综合实验箱,高校新工科的宝藏神器
挖到宝了!比邻星人工智能综合实验箱,高校新工科的宝藏神器!
超小型Neuton机器学习模型, 在任何系统级芯片(SoC)上解锁边缘人工智能应用.
信而泰×DeepSeek:AI推理引擎驱动网络智能诊断迈向 “自愈”时代
最新人工智能硬件培训AI 基础入门学习课程参考2025版(大模型篇)
C#集成OpenVINO™:简化AI模型部署

借助ExecuTorch和KleidiAI提高大语言模型推理性能

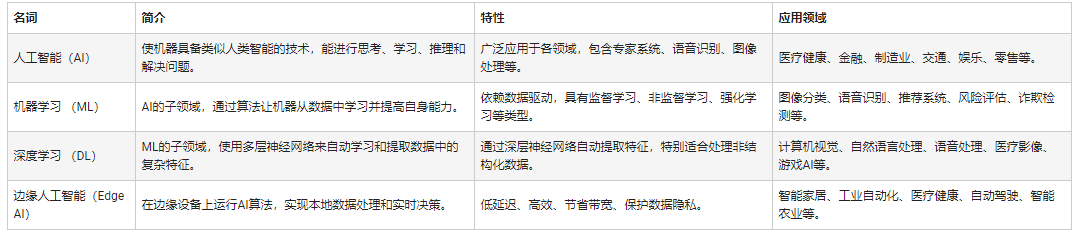
人工智能和机器学习以及Edge AI的概念与应用





 工商网监
工商网监
评论