 使用Memgraph和NVIDIA cuGraph算法运行大规模图形分析
使用Memgraph和NVIDIA cuGraph算法运行大规模图形分析

通过最新的 Memgraph 高级图形扩展( MAGE )版本,您现在可以在几秒钟内从 Memgraph 运行 GPU 支持的图形分析,同时使用 Python 。由 NVIDIA cuGraph 提供支持,以下图形算法现在将在 GPU 上执行:
PageRank (图形分析)
Louvain (社区检测)
平衡切割(聚类)
光谱聚类(聚类)
点击率(集线器与权威分析)
莱顿(社区检测)
Katz Centrality
中间性和中心性
本教程将向您展示如何使用 PageRank 图分析和 Louvain 社区检测来分析包含 130 万关系的 Facebook 数据集。
在本教程结束时,您将知道如何:
使用 Python 在 Memgraph 中导入数据
在大规模图形上运行分析并获得快速结果
从 Memgraph 在 NVIDIA GPU 上运行分析
教程先决条件
要学习本图形分析教程,您需要一个 NVIDIA GPU 、驱动程序和容器工具包。成功安装后 NVIDIA GPU 驱动程序 和容器工具包,您还必须安装以下四个工具:
码头工人 用于运行mage-cugraph映像
朱皮特 为了分析图形数据
炼金术 将 Memgraph 与 Python 连接
Memgraph 实验室 为了使图形可视化
下一节将指导您为本教程安装和设置这些工具。
码头工人
Docker 用于安装和运行mage-cugraph Docker 映像。设置和运行 Docker 映像涉及三个步骤:
下载 Docker
下载教程数据
运行 Docker 映像,使其能够访问教程数据
1.下载 Docker
您可以通过访问安装 Docker 网页,并按照操作系统的说明操作。
2.下载教程数据
在运行mage-cugraph Docker 映像之前,首先下载本教程中使用的数据。这允许您在运行时为 Docker 映像提供对教程数据集的访问权限。
要下载数据,请使用以下命令克隆 jupyter memgraph 教程 GitHub repo ,并将其移动到jupyter-memgraph-tutorials/cugraph-analytics文件夹:
Git clone https://github.com/memgraph/jupyter-memgraph-tutorials.git
Cd jupyter-memgraph-tutorials/cugraph-analytics
3.运行 Docker 镜像
现在,您可以使用以下命令运行 Docker 镜像并将车间数据装载到/samples文件夹:
docker run -it -p 7687:7687 -p 7444:7444 --volume /data/facebook_clean_data/:/samples mage-cugraph
运行 Docker 容器时,您应该会看到以下消息:
You are running Memgraph vX.X.X
To get started with Memgraph, visit https://memgr.ph/start
执行 mount 命令后,教程所需的CSV文件将位于 Docker 映像内的/samples文件夹中, Memgraph 将在需要时找到它们。
Jupyter 笔记本
现在 Memgraph 已经运行,请安装 Jupyter.本教程使用 JupyterLab,您可以使用以下命令安装它:
pip install jupyterlab
安装 JupyterLab 后,使用以下命令启动它:
jupyter lab
炼金术
使用 炼金术 ,一个对象图映射器( OGM ),用于连接到 Memgraph 并在 Python 中执行查询。您可以将 Cypher 视为图形数据库的 SQL 。它包含许多相同的语言结构,如创建、更新和删除。
下载 CMake 在您的系统上,然后您可以使用 pip 安装 GQLAlchemy :
pip install gqlalchemy
Memgraph 实验室
您需要安装的最后一个先决条件是: Memgraph 实验室 连接到 Memgraph 后,您将使用它创建数据可视化。学 如何安装 Memgraph 实验室 作为操作系统的桌面应用程序。
安装 Memgraph Lab 后,您现在应该 连接到 Memgraph 数据库 。
此时,您终于准备好:
使用 GQLAlchemy 连接到 Memgraph
导入数据集
在 Python 中运行图形分析
使用 GQLAlchemy 连接到 Memgraph
首先,将自己定位在 Jupyter 笔记本 。前三行代码将导入gqlalchemy,通过host:127.0.0.1和port:7687连接到 Memgraph 数据库实例,并清除数据库。一定要从头开始。
from gqlalchemy import Memgraph
memgraph = Memgraph("127.0.0.1", 7687)
memgraph.drop_database()
从 CSV 文件导入数据集。
接下来,您将执行以下操作: PageRank 以及使用 Python 的 Louvain 社区检测。
导入数据
这个 Facebook 数据集 由八个 CSV 文件组成,每个文件具有以下结构:
node_1,node_2
0,1794
0,3102
0,16645
每条记录表示连接两个节点的边。节点表示页面,它们之间的关系是相互的。
有八种不同类型的页面(例如,政府、运动员和电视节目)。页面已重新编制匿名索引,所有页面均已通过 Facebook 验证真实性。
由于 Memgraph 在数据具有索引时导入查询速度更快,因此在id属性上使用标签Page为所有节点创建查询。
memgraph.execute(
"""
CREATE INDEX ON :Page(id);
"""
)
Docker 已经拥有对本教程中使用的数据的容器访问权限,因此您可以通过./data/facebook_clean_data/文件夹中的本地文件进行列表。通过连接文件名和/samples/文件夹,可以确定它们的路径。使用连接的文件路径将数据加载到 Memgraph 中。
import os
from os import listdir
from os.path import isfile, join
csv_dir_path = os.path.abspath("./data/facebook_clean_data/")
csv_files = [f"/samples/{f}" for f in listdir(csv_dir_path) if isfile(join(csv_dir_path, f))]
使用以下查询加载所有 CSV 文件:
for csv_file_path in csv_files:
memgraph.execute(
f"""
LOAD CSV FROM "{csv_file_path}" WITH HEADER AS row
MERGE (p1:Page {{id: row.node_1}})
MERGE (p2:Page {{id: row.node_2}})
MERGE (p1)-[:LIKES]->(p2);
"""
)
接下来,将 PageRank 和 Louvain 社区检测算法与 Python 结合使用,以确定网络中哪些页面最重要,并找到网络中的所有社区。
PageRank 重要性分析
要识别 Facebook 数据集中的重要页面,您将执行 PageRank 。了解不同的 算法设置 这可以在调用 PageRank 时设置。
请注意,您还会发现MAGE中集成了其他算法。 Memgraph 应该有助于在大规模图形上运行图形分析。找到其他 Memgraph 教程 关于如何运行这些分析。
MAGE被集成以简化 PageRank 的执行。以下查询将首先执行算法,然后创建每个节点的rank属性,并将其设置为cugraph.pagerank算法返回的值。
然后,该属性的值将另存为变量rank。请注意,这项测试(以及本文介绍的所有测试)是在 NVIDIA GeForce GTX 1650 Ti 和 Intel Core i5-10300H CPU 上执行的,频率为 2.50GHz ,内存为 16GB ,并在大约四秒钟内返回结果。
memgraph.execute(
"""
CALL cugraph.pagerank.get() YIELD node,rank
SET node.rank = rank;
"""
)
接下来,使用以下 Python 调用检索列组:
results = memgraph.execute_and_fetch(
"""
MATCH (n)
RETURN n.id as node, n.rank as rank
ORDER BY rank DESC
LIMIT 10;
"""
)
for dict_result in results:
print(f"node id: {dict_result['node']}, rank: {dict_result['rank']}")
node id: 50493, rank: 0.0030278728385218327
node id: 31456, rank: 0.0027350282311318468
node id: 50150, rank: 0.0025153975342989345
node id: 48099, rank: 0.0023413620866201052
node id: 49956, rank: 0.0020696403564964
node id: 23866, rank: 0.001955167533390466
node id: 50442, rank: 0.0019417018181751462
node id: 49609, rank: 0.0018211204462452515
node id: 50272, rank: 0.0018123518843272954
node id: 49676, rank: 0.0014821440895415787
此代码返回具有最高秩分数的 10 个节点。结果以字典形式提供。
现在,是时候用可视化方法显示结果了Memgraph 实验室除了通过以下方式创建美丽的视觉效果外:D3.js和我们的图形样式脚本语言,您可以使用 Memgraph Lab 来:
- 查询图形数据库并用 Python 或 C ++甚至 Rust 编写图形算法
- 检查 Memgraph 数据库日志
- 可视化图形模式
Memgraph Lab 提供了各种预构建的数据集,帮助您入门。在 Memgraph Lab 中打开执行查询视图并运行以下查询:
MATCH (n)
WITH n
ORDER BY n.rank DESC
LIMIT 3
MATCH (n)<-[e]-(m)
RETURN *;
此查询的第一部分将MATCH所有节点。查询的第二部分将按rank的降序排列ORDER节点。
对于前三个节点,获取连接到它们的所有页面。我们需要WITH子句来连接查询的两个部分。
下一步是学习如何使用 Louvain 社区检测来查找图中存在的社区。
Louvain 的社区检测
Louvain 算法测量社区内节点的连接程度,与它们在随机网络中的连接程度进行比较。
它还递归地将社区合并到单个节点中,并在压缩图上执行模块化聚类。这是最流行的社区检测算法之一。
使用 Louvain ,您可以在图中找到社区的数量。首先执行 Louvain 并将 cluster_id保存为每个节点的属性:
memgraph.execute(
"""
CALL cugraph.louvain.get() YIELD cluster_id, node
SET node.cluster_id = cluster_id;
"""
)
要查找社区的数量,请运行以下代码:
results = memgraph.execute_and_fetch(
"""
MATCH (n)
WITH DISTINCT n.cluster_id as cluster_id
RETURN count(cluster_id ) as num_of_clusters;
"""
)
# we will get only 1 result
result = list(results)[0]
#don't forget that results are saved in a dict
print(f"Number of clusters: {result['num_of_clusters']}")
Number of clusters: 2664
接下来,仔细看看其中的一些社区。例如,您可能会发现属于一个社区的节点,但连接到另一个属于相反社区的节点。 Louvain 试图最小化此类节点的数量,因此您不应该看到很多节点。在 Memgraph Lab 中,执行以下查询:
MATCH (n2)<-[e1]-(n1)-[e]->(m1)
WHERE n1.cluster_id != m1.cluster_id AND n1.cluster_id = n2.cluster_id
RETURN *
LIMIT 1000;
此查询将显示MATCH节点n1及其与其他两个节点n2和m1的关系,分别包含以下部分:(n2)《-[e1]-(n1)和(n1)-[e]-》(m1)。然后,它将仅过滤出n1的那些节点WHERE、cluster_id,并且n2与节点cluster_id的m1不同。
为了简化可视化,使用LIMIT 1000仅显示 1000 个此类关系。
使用 图形样式脚本 在 Memgraph Lab 中,您可以设置图形的样式,例如,用不同的颜色表示不同的社区。
总结
现在,您可以使用 Memgraph 导入数百万个节点和关系,并使用 cuGraph PageRank 和 Louvain graph 分析算法进行分析。借助由 NVIDIA cuGraph 提供的 Memgraph 的 GPU 图形分析功能,您可以探索海量图形数据库并进行推理,而无需等待结果。
关于作者
Antonio Filipović 与 Memgraph 的解决方案团队合作。他拥有构建基于云的解决方案和开发基于流的图形分析算法的经验。作为一名学生,他帮助推出了 Memgraph Cloud 和 Memgraph 游乐场等产品。他还研究了基于流的图机器学习算法。安东尼奥最近获得了萨格勒布大学电气工程与计算学院的计算机科学硕士学位。
审核编辑:郭婷
-
NVIDIA
+关注
关注
14文章
5732浏览量
110338 -
gpu
+关注
关注
28文章
5337浏览量
136263 -
python
+关注
关注
59文章
4892浏览量
90460
发布评论请先 登录
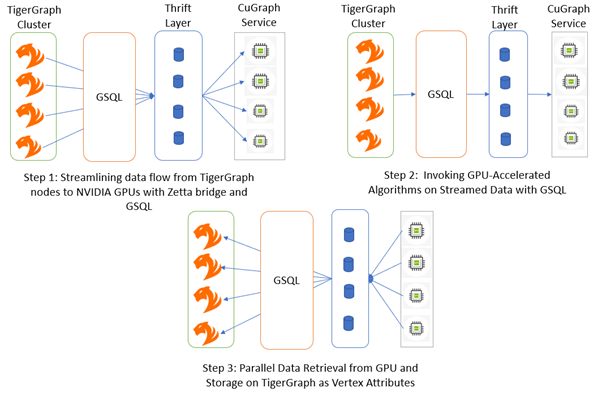
革命性的图形分析: NVIDIA cuGraph 加速的下一代架构
大规模特征构建实践总结
大规模MIMO的利弊
大规模MIMO的性能
基于MATLAB的大规模电路分析
对于大规模系统日志的日志模式提炼算法的优化
求解大规模问题的协同进化动态粒子群优化算法
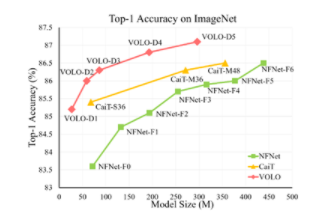
使用NVIDIA DGX SuperPOD训练SOTA大规模视觉模型



评论