 面向ARM异构多核系统的性能分析与效能优化
面向ARM异构多核系统的性能分析与效能优化

01背景介绍
性能和能耗之间的平衡是设计新处理器的核心问题之一,因为超过90%的处理器最终用于嵌入式能源受限设备,例如智能手机和物联网传感器。异构系统,结合不同的处理器类型,为不同类型的工作负载提供高能效处理。第一个异构系统将处理器与不同的指令集架构(ISA)相结合。最近,单ISA非对称多核处理器(AMP)开始流行。它们的优势是显而易见的——因为处理器共享相同的架构,操作系统线程调度程序可以在运行时做出关于将哪个任务/线程映射到哪个处理器/内核的决定,这不仅取决于工作负载的特征,还取决于通过单个处理器/内核的运行时负载。另一方面,这为调度问题引入了额外的自由度,使其更加复杂。
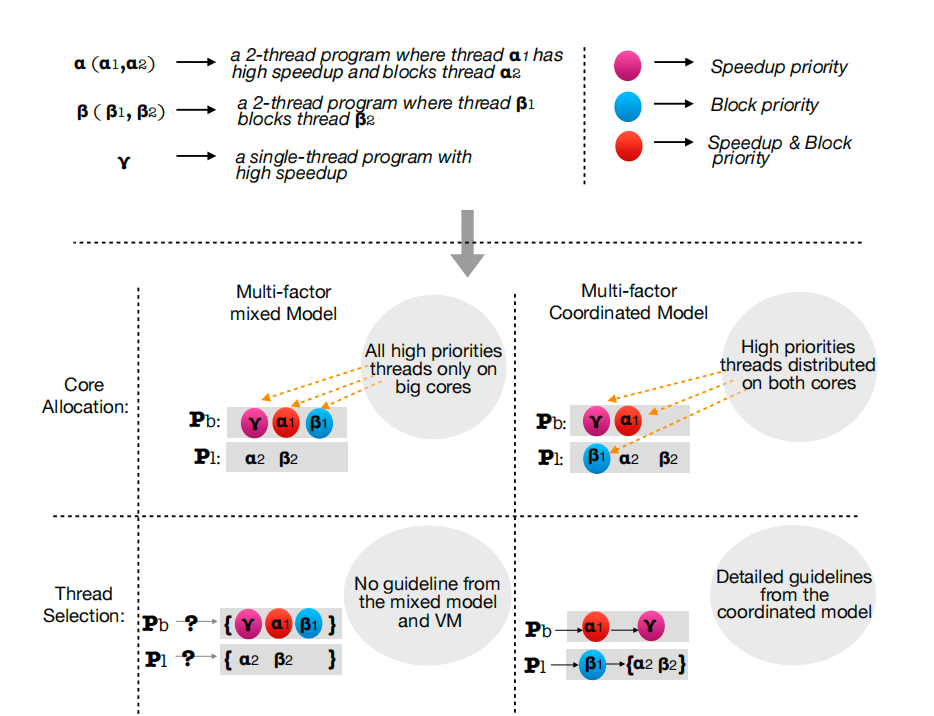
非对称多核处理器上的多线程多道程序工作负载,具有一个大核和一个小核。仅控制CPU核心亲和性会导致次优运行时优化决策。工作负载,这些应用程序具有潜在的不平衡线程,并且线程总数可能高于内核数。虽然向前迈出了重要一步,但WASH仅控制核心亲和力,并且以有限的方式这样做。前者意味着我们无法以整体方式处理核心分配和线程调度来加速最关键的线程。后者意味着WASH只真正控制每个线程的调度域,即允许线程使用的内核组。每个线程的实际核心由底层LinuxCFS调度程序选择,其启发式忽略异构性和线程关键性。
02COLAB方案概览
COLAB是一种用于非对称多核处理器的运行时优化策略,它能够针对线程调度中的所有三个主要因素-核心敏感度、线程关键性和公平性做出协调决策。
1.核心敏感度:每种类型的核心都旨在处理不同类型的工作负载。例如,在ARM big.LITTLE系统中,大内核主要用于性能关键型工作负载或具有指令级并行(ILP)的工作负载。在它们上执行其他类型的工作负载不会显著提高性能,但会显著增加能耗。为了构建高效的AMP调度程序,我们需要预测哪些线程适合哪种内核。
2.线程关键性:更快地执行工作负载的单个线程并不总是转化为整个工作负载的更好性能。如果应用程序的线程不平衡或以不同的速度执行,例如因为不同的线程在不同类型的内核上运行,则应用程序将仅以其最慢或最关键的线程(阻塞大部分其他线程的线程)运行线程)。一个好的AMP调度程序会尽可能地加速这些线程,而不管核心敏感度如何。
3.负载均衡:在多道程序工作负载中,单独加速单个应用程序是不够的,如果它会惩罚其他应用程序。理想情况下,我们需要负载均衡来平衡所有应用程序中资源共享的负面影响。在同构系统中,这很容易通过以循环方式在CPU上为每个应用程序提供固定大小的时间片来实现。AMP使这个简单的解决方案变得不可行。由于每个内核的性能不同,不同内核类型上相同的CPU时间会导致执行的工作量完全不同。
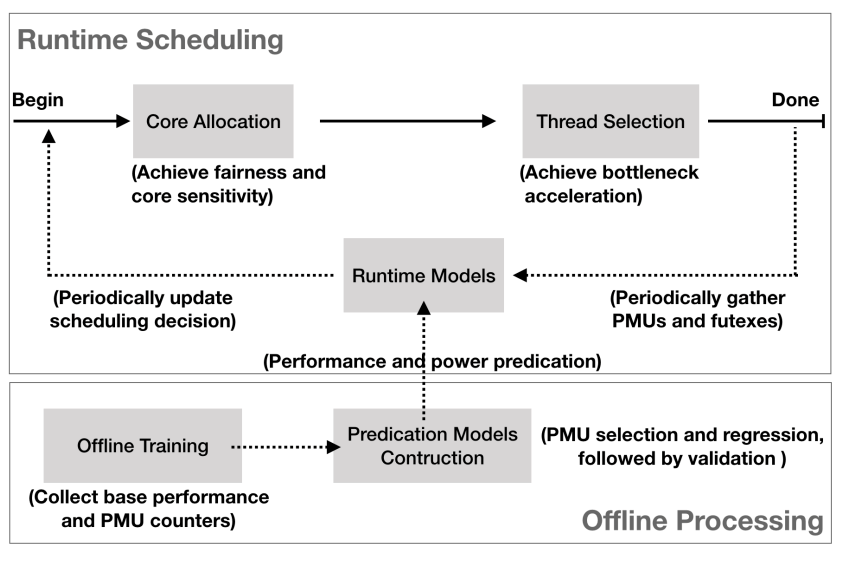
系统分为运行时调度过程和离线建模过程。运行时调度器内置在OS内核中,由
i)一个核心分配器组成,用于处理公平性和核心敏感性;
ii)实现瓶颈加速的线程选择器;
iii)基于机器学习的运行时模型,它预测异构内核上线程的加速和功耗。离线建模处理用于通过离线训练构建运行时模型。
COLAB调度程序的主要新颖之处在于它可以以协作的方式处理多个运行时因素(核心敏感性、瓶颈加速和公平性),以实现高系统性能和能源效率。
运行时分析
核心分配器:支持AMP的核心分配器主要受线程的核心敏感度因素指导,它量化了将线程从小核心迁移到大核心带来的性能优势。将high-speedupthread(在大核心上享有较大的加速)从小核心迁移到大核心通常比迁移low-speedupthread 提供更多好处。然而,考虑到瓶颈因素,它量化了线程阻塞其他线程的程度,揭示了这种启发式在多道程序工作负载上的问题。以前的方法只是将预测的瓶颈加速和加速结合在一起。这可能会导致次优的调度决策,其中瓶颈线程和高速加速线程都累积在大核心的运行队列中,更好的核心分配策略将避免瓶颈加速和加速的简单组合,而是专注于协作环境,其中大核心专注于高速瓶颈线程,小核心处理低加速瓶颈线程而无需额外迁移。此外,核心分配器试图通过有效地共享异构硬件并尽可能避免让资源闲置来实现AMP的相对公平。简单地将就绪线程均匀地映射到不同类型的内核上并不能实现真正的公平性,因为不同类型的内核最终具有不同数量的线程优先级。因此,应采用分层分配来保证整体公平性,从而避免频繁将线程迁移到空运行队列的需要。
线程选择器:线程选择器决定接下来将执行每个内核的运行队列中的哪个线程。线程选择器通常会优先考虑瓶颈线程,以避免线程被阻塞太久而导致性能损失。在多线程多程序环境中,可能需要同时加速来自不同程序的多个瓶颈线程。不像之前的瓶颈加速调度程序那样简单地检测瓶颈线程并将它们全部分配给大核,线程选择器需要做出协作决策——理想情况下,大核和小核核心将同时运行瓶颈线程。核心敏感性通常对线程选择器并不重要,它做出的决定完全由瓶颈加速来指导。一个例外是大核心的运行队列为空并且调用线程选择器时。只有在这种情况下,才应考虑就绪线程的核心敏感性的加速因素。必要时,大核甚至可以抢占小核上的线程执行。最后,线程选择器还关注公平性。通过更新线程选择器的时间间隔来缩放线程的时间片已被证明可以保证线程的相等进度并实现多线程单程序工作负载的公平性。然而,仅仅确保所有线程的平等进程是不够的,不足以保证跨程序的公平性。线程选择器应确保每个单独的程序都能平等地进行使用大核和小核来加速瓶颈为此提供了机会。线程选择器试图通过尽快加速所有程序的瓶颈线程来确保程序之间的公平性。
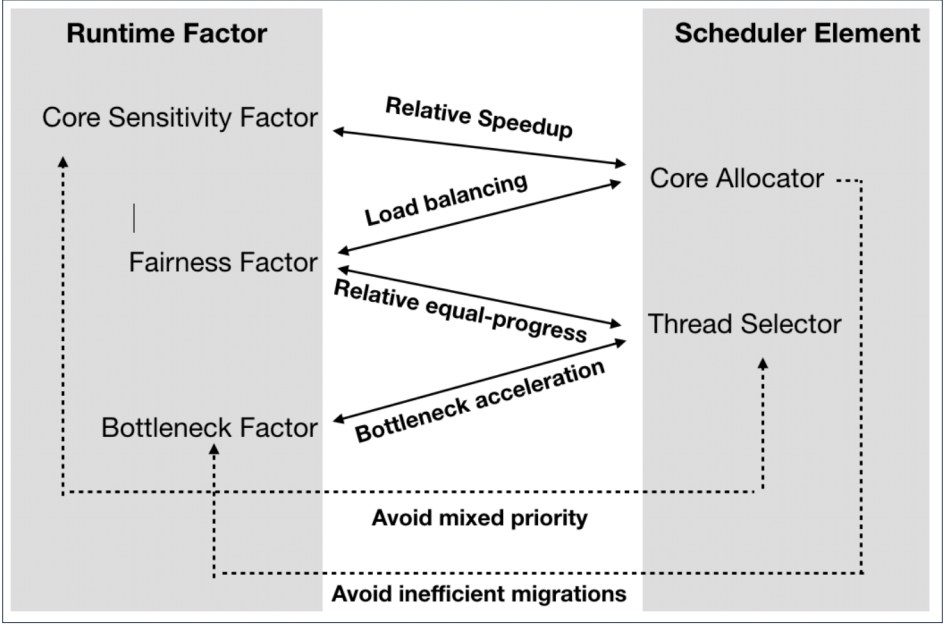
运行时协作
核心分配器和线程选择器协作以实现性能和能耗之间的良好折衷,同时确保公平。模型的流程图如下图所示。
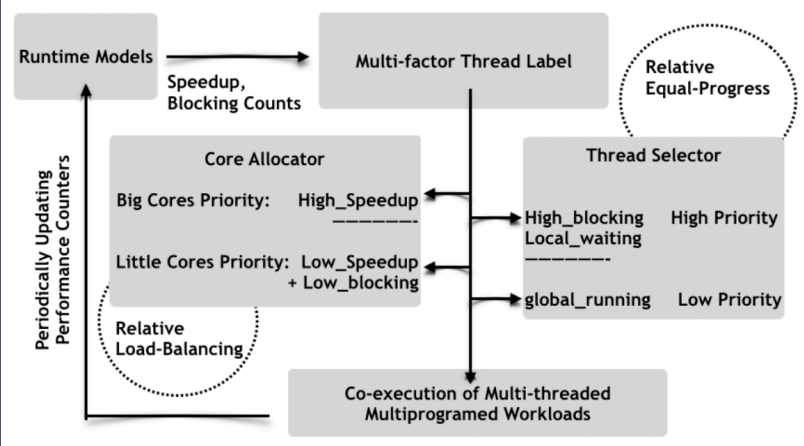
基于加速预测和瓶颈识别的运行时模型,通过定期将就绪线程分类(使用标签)分为两个不同的类别来促进协作。
核心分配标签:在大核心上具有高预测加速的线程将被标记为大核心上的高优先级。具有低预测加速和阻塞级别的线程,即非关键线程,将在小核心上获得高优先级(在大核心上获得低优先级)。剩余线程在大核或小核上获得相同的优先级——然后可以自由分配这些线程以平衡核的负载。
线程选择标签:具有高阻塞级别的线程将被标记为本地线程选择的高优先级。无论它们是在大核还是小核上执行,都将给予这些线程相同的优先级。该标签仍然记录了当前核心的类型——如果存在具有空运行队列的相同类型的核心,线程总是优先被相同类型的核心选择。在小核心上运行的线程也被标记,因为它们可能会在合适的时候被抢占在大核心上迁移和执行,但运行线程永远不会优先于等待就绪线程。
标签后处理:在标记过程之后,公平性、核心敏感性和瓶颈加速由线程上的标签表示,并且可以由核心分配器、线程选择器或两者一起处理。基于这种协调模型,核心分配器和线程选择器从就绪线程集中处理不同的优先级队列——它们的决策不会像WASH这样的混合多因素直接排名。相反,他们提供了一个基于时间片的协作方案。
协同多因素模型处理的另一个重要问题是确保线程的平等进展,我们不会干扰线程选择的优先级和决策,而是根据在大内核上运行的线程的预测加速值,通过按比例缩放的时间片方法在线程中实现相等的进展。大核上的线程片比小核上的相对短。线程选择功能更频繁地被触发以交换大核上的执行线程,这保证了在所有核上执行的线程的相对等进度。运行时模型会定期提取性能计数器,该计数器代表AMP上多线程多程序工作负载的当前执行环境。模型计算更新的运行时因素包括预测的加速值和阻塞计数。此信息附加到线程并报告回多因素贴标机以供下一轮使用。
03总结
本期报告着重介绍了COLAB运行时优化框架,该框架针对非对称多核处理器(AMP)上的多线程多道程序工作负载。AMP在当今处理器市场尤其是嵌入式系统中占据重要部分。COLAB是第一个通用调度程序,通过对核心敏感性、线程关键性和调度公平性做出协作决策,优化了影响AMP调度的所有这三个因素-核心亲和力、线程关键性和调度公平性。COLAB调度程序在性能方面分别比最先进的WASH、ARMGTS 和LinuxCFS调度程序高出21%、20%和25%,平均系统吞吐量高了6%、2%和15%,与WASH和ARMGTS相比,COLAB实现了平均5%的节能。
审核编辑 :李倩
-
ARM
+关注
关注
135文章
9624浏览量
394866 -
多核处理器
+关注
关注
0文章
110浏览量
20869 -
线程
+关注
关注
0文章
511浏览量
20912
原文标题:面向ARM异构多核系统的运行时性能分析与效能优化
文章出处:【微信号:算力基建,微信公众号:算力基建】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录

详解Arm Performix性能分析工具套件的实际使用方法

Arm宣布推出Performix性能分析工具套件
Arm 推出Performix:开创AI智能体性能优化新纪元

VirtualLab:光栅的优化与分析
【玩转多核异构】T153核心板RISC-V核的实时性应用解析

深入解析面向不同市场的多样化Arm计算子系统

Linux系统性能优化技巧
【飞凌T527N开发板试用】异构RISC-V核心使用体验
【老法师】多核异构处理器中M核程序的启动、编写和仿真

PCIe协议分析仪能测试哪些设备?
如何释放异构计算的潜能?Imagination与Baya Systems的系统架构实践启示




评论