 一窥AMR图谱在自然语言处理中的应用
一窥AMR图谱在自然语言处理中的应用

引言
TreeBank 作为自然语言语法的结构化表示可谓广为人知,其实在语义层面也有一种类似的结构化方法——抽象语义表示(Abstract Meaning Representation,AMR)。它能记录自然语言文本中最重要的语义信息,但并不限制实际表达时的语法结构。本次分享我们将向读者介绍 ACL 2022 中与 AMR 有关的三篇论文,一窥 AMR 图谱在自然语言处理中的应用。
文章概览
Graph Pre-training for AMR Parsing and Generation
AMR 既不会自动从文本中展现出来,也无法自行表达一个句子。因此对于 AMR 而言,最重要的任务就是从文本中构建 AMR,以及根据 AMR 生成文本。目前的主流模型均以预训练语言模型作为基础,然而本文作者指出,传统的预训练方法面向文本,存在任务形式错配的问题。因此,本文首次提出将直接针对 AMR 的图预训练任务应用至预训练语言模型中,并取得了不错的效果。
Variational Graph Autoencoding as Cheap Supervision for AMR Coreference Resolution
理论上我们可以利用 AMR 图谱分析多个句子甚至一篇文章的语义,但必须通过指代消融将多个指代相同实体的节点合并。目前的模型一方面需要大量的图谱数据用于训练,另一方面却对数据噪声较为敏感。本文作者通过将变分图自编码器引入既有的 AMR 指代消融模型,成功将存在一定错误的自动标注 AMR 图谱数据纳入训练数据中,使模型性能得到了显著提高。
AMR-DA: Data Augmentation by Abstract Meaning Representation
AMR 图谱可以助力多种自然语言处理任务,不过本文探讨的却是一个比较另类的应用——自然语言数据增强。面向文本的数据增强方法或者容易导致病句,或者难以提供足够的数据多样性;相反,面向 AMR 的数据增强可以在轻微改变甚至不改变语义的前提下,生成通顺而多变的文本。基于上述观察,本文在两个主流任务上比较了传统方法与 AMR 数据增强的效果,并分析了 AMR 方法的优势所在。
论文细节

研究动机
人工标注 AMR 图谱往往费时费力,因此设计能相互转换文本与 AMR 的自动模型就显得非常重要。其中,从文本构建 AMR 称为 AMR 解析(parsing),而根据 AMR 生成文本则称为 AMR 生成(generation)。目前主流的方法是将 AMR 图谱按照一定的节点顺序(如 DFS 序列)表示为一个字符串,然后应用序列到序列(seq2seq)模型;然而,通常的序列到序列模型是基于文本设计的,并不能很好地学习 AMR 特有的图结构。
为了实现能更好地利用图结构的模型,本文作者探究了以下三个问题:能否设计完全基于图的预训练任务(即图到图任务)作为文本预训练的补充?怎样有效结合这两类形式不同的训练任务?能否引入其它模型自动标注的 AMR(存在一定噪声)?本文即沿着上述三个问题,分别在 AMR 解析与生成两个任务上进行了实验与分析。
图训练任务
为了与既有的模型结果对齐,本文依然沿用了基于文本的 BART 模型,输入或输出序列化的 AMR 图谱。BART 的预训练任务是文本去噪,即从添加了噪声的文本中重建原始内容,其中噪声包括语段的增删、调换、掩码(MASK)覆盖等。显然如果直接对序列化 AMR 图谱应用这些操作,很可能会破坏图谱表示,导致模型难以利用结构信息恢复原始图谱。
为此,作者巧妙地设计了两类能够表示为文本去噪的图预训练任务——节点/边重建和子图重建。其中,节点/边重建任务随机选取原始 AMR 图谱中部分节点和边,并用掩码标签覆盖,要求模型恢复这些节点和边的原始标签;子图重建任务则进一步将一个完整的随机子图替换为掩码节点,要求模型恢复整个子图。这些基于图谱的变换既可以分别应用于不同的输入,也可以同时使用。
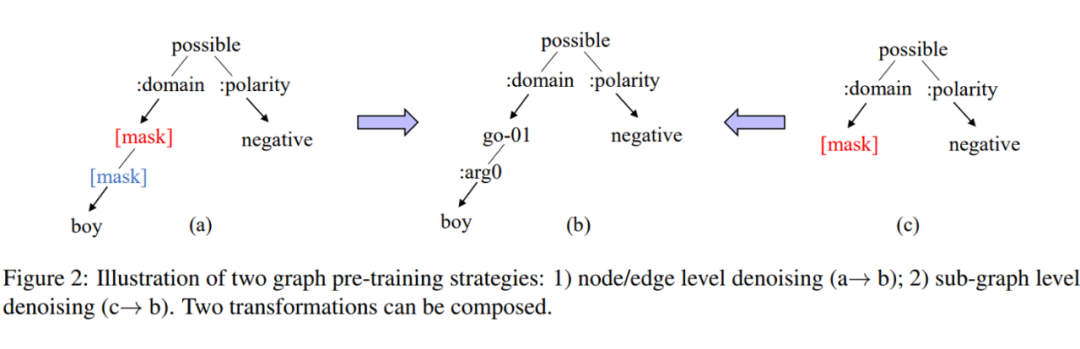
通过加入一些限制条件,上述两个任务都能以文本掩码、语段交换等形式套用既有的 BART 预训练流程。这样一方面可以在不改动既有模型架构的前提下进行图训练任务,另一方面可以增强模型对比结果的说服力。
联合训练框架
解决了任务设计的问题,还需要考虑如何统一图训练与文本训练。本文作者注意到,这两类预训练任务和下游任务(AMR 解析与生成)都可以表示为如下形式:输入一段文本或一个 AMR 图谱,输出另一段文本或另一个 AMR 图谱;然而不难发现,预训练任务的输入与输出有相同的形式,但下游任务却并非如此——两类任务的形式错配了。
作者认为,这一错配是目前序列到序列模型性能瓶颈的来源之一:模型在预训练阶段难以学习文本与图谱信息交互的部分,然而无论是 AMR 解析还是生成任务都高度依赖这些交互信息。因此,他们进一步提出了文本-图谱联合预训练框架,即模型同时输入文本与图谱信息,输出期望的文本或图谱。如此一来,上述各种任务无非是将其中一个输入源置空而已。
在这样一个统一的框架下,本文提出了将文本与图谱结合起来的预训练任务——其中一类是同时输入文本与图谱,但向其中某个输入添加噪声,并要求模型复原;另一类是同时向两个输入添加噪声,并要求模型恢复其中一个。各个任务的损失函数与通常的去噪任务无异,均为交叉熵损失,且训练期间可以同时加入所有任务,目标损失函数即为所有任务的损失函数之和。

与单纯的文本或图训练任务相比,模型能同时利用文本与图谱的信息,就有机会强化模型理解双方交互的水平。此外,根据预训练样本量的不同,训练样本的噪声水平会逐渐提高(即掩码出现的频率),使模型能渐进地学习。
实验设计
利用以上提到的图训练与联合训练任务,本文选取 AMR 2.0 与 AMR 3.0 两个人工标注数据集作为训练集和主要测试集,并额外在 New3、小王子(LP)以及 Bio AMR 等小型数据集上测试模型的跨领域性能。此外为了回答第三个问题——能否利用自动标注数据,作者又从 Gigaword 语料库(两个主数据集的语料来源)随机抽取部分句子,并采用 SPRING 模型生成自动标注的 AMR 图谱,作为预训练专用的附加数据集。
AMR 解析与 AMR 生成两个任务均采用原版 BART 作为核心模型,并通过验证集指标选取最优模型。AMR 解析任务采用目前主流的 Smatch 分数及其子项作为评价指标,AMR 生成任务则选取 BLEU、CHRF++ 和 METEOR 等文本生成评价指标。
结果及分析
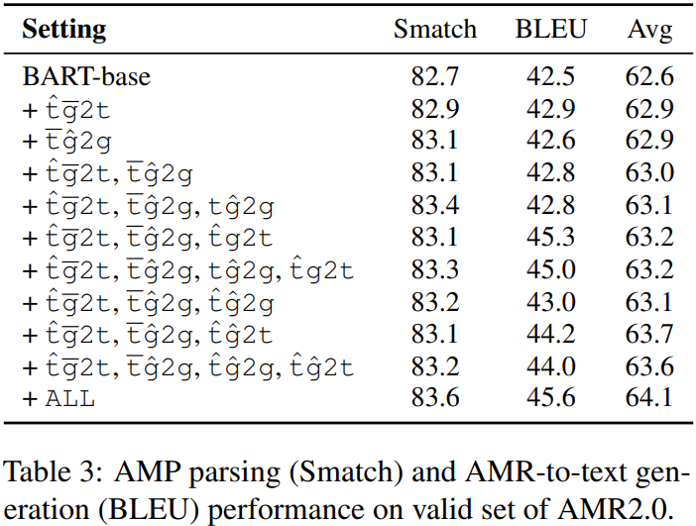
下图展示了在验证集上各种预训练任务组合的效果,可见当模型是针对图谱去噪预训练时,解析任务的性能提升更明显,生成任务的性能提升更明显,且组合所有任务的效果是最好的。另外作者进一步发现,两种图预训练形式都能提供一定程度的帮助,且子图重建的贡献更大一些。
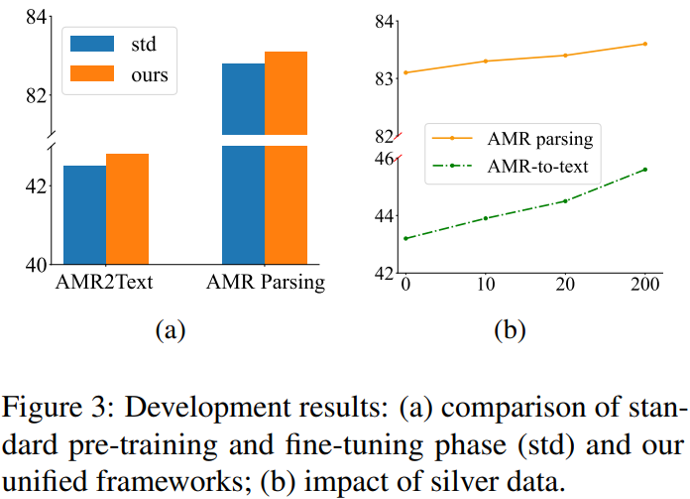
下图列出了一些验证集上的其它实验结果。其中,左图比较了两种训练范式下的模型性能,显示通过联合训练框架预训练的模型在两个任务上都优于采用传统任务预训练的模型;右图则统计了添加自带噪声的自动标注数据参加预训练后的指标变化,表明在本文提出的训练范式下,即使是自动标注数据也可以有效改善模型的性能。
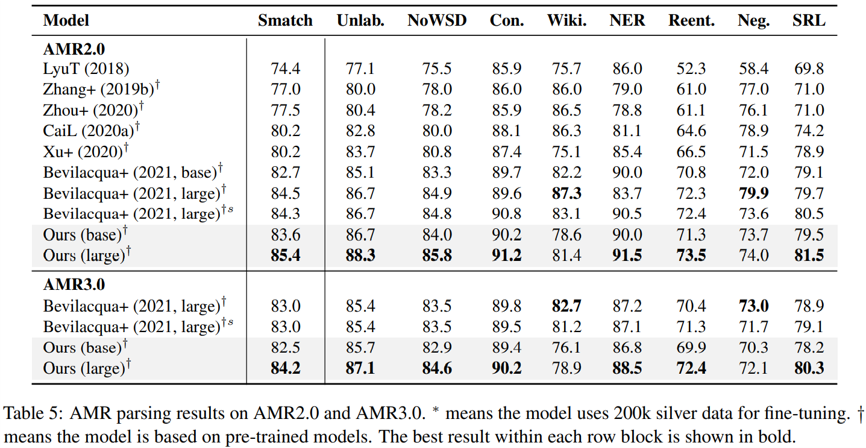
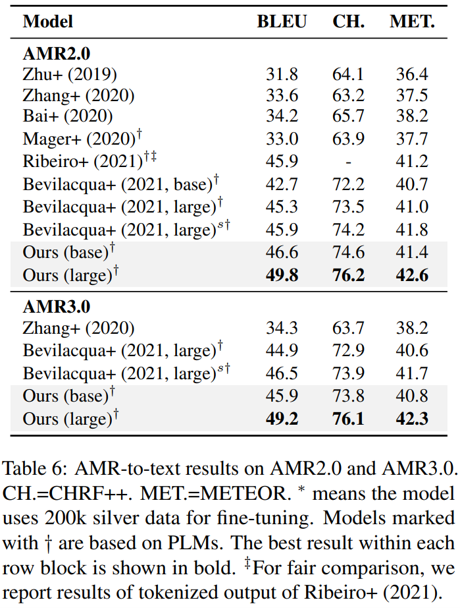
主数据集上的测试结果如下图所示,包括 AMR 解析与 AMR 生成任务,可见本文提出的模型与其它主流模型相比,在各项指标上几乎都实现了突破,甚至在生成任务上用较小的 bart-base 达到或超过了用 bart-large 作为核心的其它模型。值得注意的是,在这些模型中,本文提出的模型在利用自动标注数据时的表现是最好的——作者指出这是因为去噪预训练任务可以更好地容忍一定的数据噪声。
此外,模型在跨领域数据集上的表性能也显著优于参与比较的其它模型,显示模型有更强的领域适应能力,作者认为是由于新的预训练任务减轻了模型在精调阶段的灾难遗忘现象。
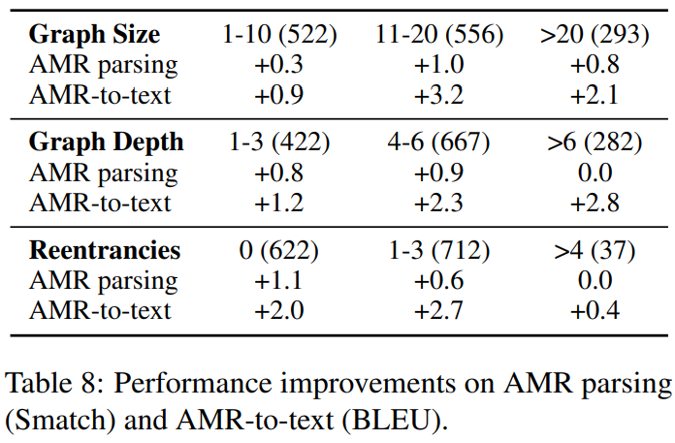
最后,本文作者还讨论了应对复杂程度不同的 AMR 图谱时,模型在两个任务上的表现。从下图的结果可以看到,模型的性能改进(特别是 AMR 生成)在更大、更深的图上更加明显,并且对有不同平均入度的图也都有性能提升。

研究动机
虽然 AMR 是针对句子标注的,但从定义来看,它并不限制语义表达的规模,因此对一篇文章中每个句子生成 AMR 图谱并整体处理是完全可行的。但在许多文章中,多个句子往往会涉及同一个实体,因此有必要将表达相同实体的 AMR 节点合并为一个聚类节点——这就是 AMR 上的指代消融任务。
早期的 AMR 指代消融主要有两种方式,其一是人工设计匹配规则,其二是通过对齐 AMR 与文本,将面向文本的指代消融结果套用至 AMR 上。最近的研究开始聚焦于直接将基于神经网络的文本指代消融模型改造为专用于 AMR 图谱的模型,取得了不错的成果;但正如上文所述,这类方法依然需要面对标注数据不足的困境。为了帮助模型走出这一困境,本文作者同样试图挖掘自动标注数据的潜力,使神经网络模型也能很好地应用于 AMR 指代消融任务中。
模型结构
本文研究的基准模型称为 AMRCoref,是一个直接在 AMR 图谱上计算指代聚类的模型。整个模型由节点编码、图谱编码、概念识别与指代聚类四个阶段组成,其中概念识别需要确定 AMR 中各个节点的类别(功能词、实体、动词等),而指代聚类就专注于判断节点之间有无指代关联——模型正是基于后面这两个阶段的损失函数训练的。
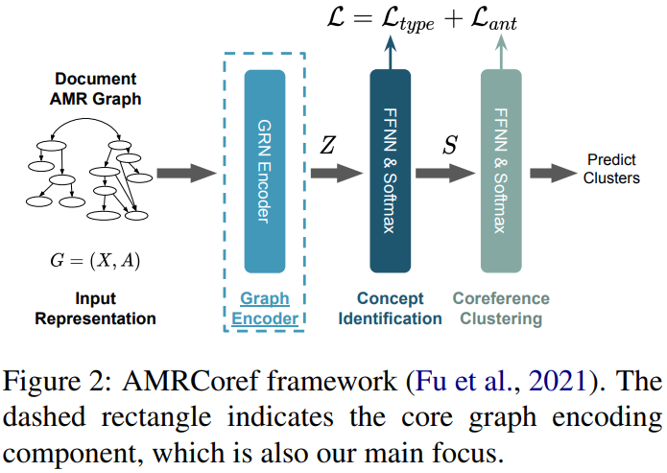
为了让模型能学习带有噪声的自动标注数据,本文将 AMRCoref 中图谱编码采用的 GRN 替换为变分图自编码器(VGAE)。VGAE 由一个局部图编码器和一个局部图解码器组成,其中前者与 AMRCoref 的图谱编码阶段作用相同,利用 GCN、GAT 或 GRN 将各个节点的编码相互融合;后者则通过点积等运算试图重建 AMR 的边集——解码器的目标正是要让边集重建损失以及变分限制惩罚之和最小。
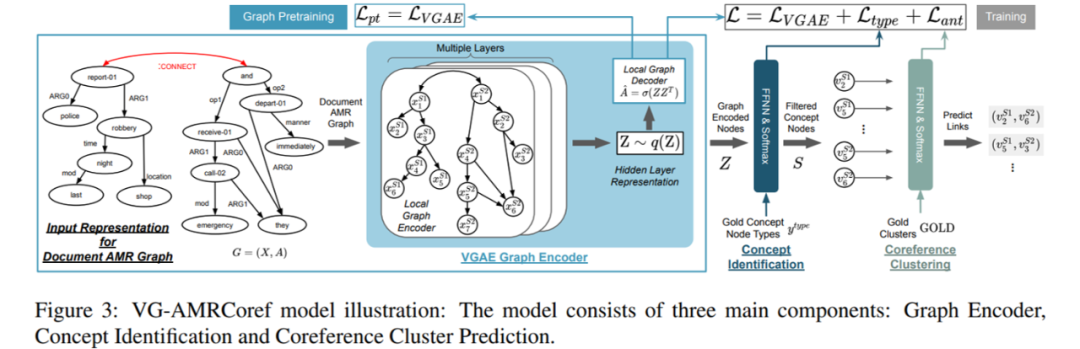
新的 VGAE-AMRCoref 模型有两种训练方式:直接训练和图编码预训练。直接训练法与原始的 AMRCoref 基本相同,只是额外增加了 VGAE 的解码器损失;图编码预训练则只考虑解码器损失,预训练完毕后再针对下游任务精调。
实验设计
本文选择了 MS-AMR 基准测试作为训练集和主测试集,并在小王子(LP)数据集上测试了跨领域性能;图编码预训练采用 AMR 3.0(下文称 AMR-gold)数据集。为了检验模型利用自动标注数据的能力,作者额外为 AMR-gold 的每个句子自动生成了 AMR 图谱,组成同样用于预训练的 AMR-silver 数据集。指代消融的评测指标由 MUC、B3 和 CEAF-phi4 的 F-1 分数组成。
根据验证集上的实验结果,VGAE-AMRCoref 模型采用 GAT 作为图编码器。参与比较的模型包括一个基于节点字符串匹配的规则模型、一个结合文本指代消融与 AMR 对齐的模型和 AMRCoref;此外,AMRCoref 和 VGAE-AMRCoref 的节点编码均考虑包含 BERT 编码与不包含两个版本。所有实验结果均取 5 个随机种子下的平均值。
结果及分析
下图展示了各个模型在两个不同的测试集上的指代消融性能。即使是未经过预训练阶段的 VGAE-AMRCoref,其性能也与 AMRCoref 相当;而加入预训练任务后,模型性能得到了显著提升,特别是在跨领域数据集上表现突出。另外,在节点编码中引入 BERT 编码可以让模型略有改进,但并不明显。
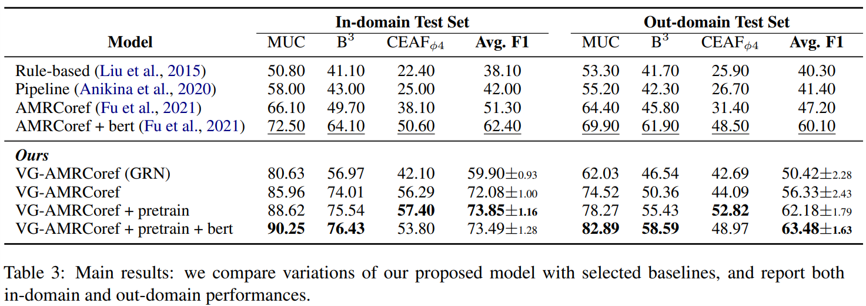
此外,本文作者还进行了若干消融实验。下图显示了采用不同版本解码器损失的实验结果,可见无论是边集重建损失亦或变分限制惩罚都能改进模型性能,且后者的效果更好一些。
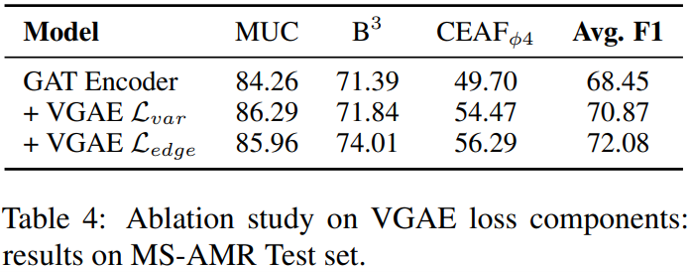
图编码器层数与模型性能的关系如下图所示,不难发现图神经网络中常见的过平滑现象依然存在——当编码器超过 3 层时,模型性能开始下降——这与 AMRCoref 的实验结果一致。
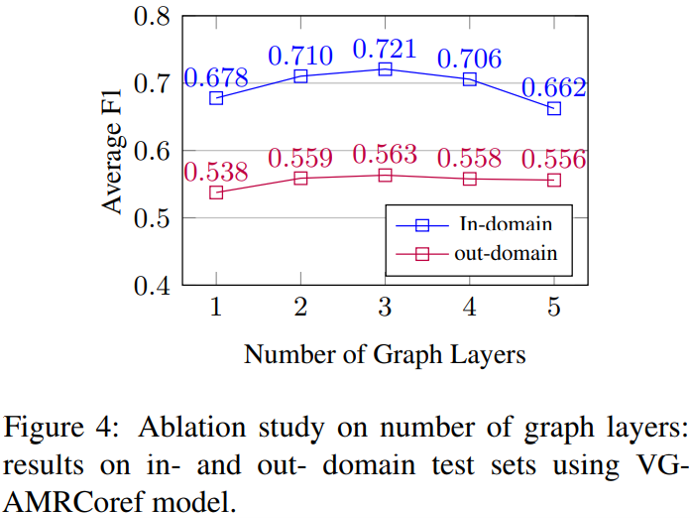
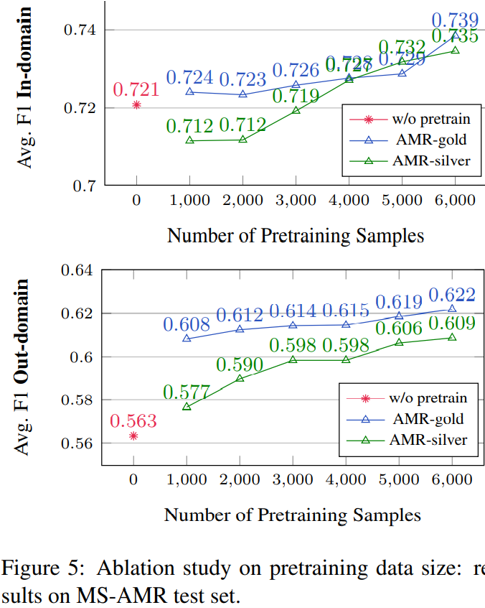
最后,下图比较了将不同规模的 AMR-gold 与 AMR-silver 作为预训练数据集时模型的效果。总体而言,越多的预训练数据能带来越高的分数,对两个数据集而言都是如此。尽管自动标注的 AMR-silver 在小数据量时会稍微降低模型性能,但只要数据量达到一定水平,自动标注数据依然能带来可观的提升。作者在此也提出,如果能用更大规模的语料库与更好的 AMR 解析模型,那么采用自动标注数据预训练的 VGAE-AMRCoref 仍然存在提升空间。

研究动机
长期以来,数据增强技术(Data Augmentation,DA)在自然语言处理领域的应用都不算多。一方面,易于存储的文本数据确实能以语料库的形式提供大量样本;但另一方面,目前的方法大部分难以在合理性与多样性之间达到平衡——基于单词的数据增强(如增删调换)很容易造出病句或矛盾句,而基于句子的数据增强(如往复翻译)则难以创造多变的句式,容易导致过拟合。
为了找到兼顾合理性与多样性的数据增强方法,本文作者将目光转向了 AMR。AMR 不限制语法的设定使得单个 AMR 图谱能够生成多种句式不同的句子,而且在一定范围内修改 AMR 并不会显著影响其语义。这些特性就使得 AMR 成为了自然语言数据增强的有力中介。
AMR 数据增强
AMR 数据增强(AMR-DA)包括三个阶段:首先需要将文本语料解析为 AMR 图谱,然后根据需求在 AMR 图谱上作少量修改,最后从修改后的 AMR 图谱生成新的文本。其中,AMR 解析模型选择上文提到的 SPRING 模型,而 AMR 生成模型则采用了基于 T5 的预训练文本生成模型。
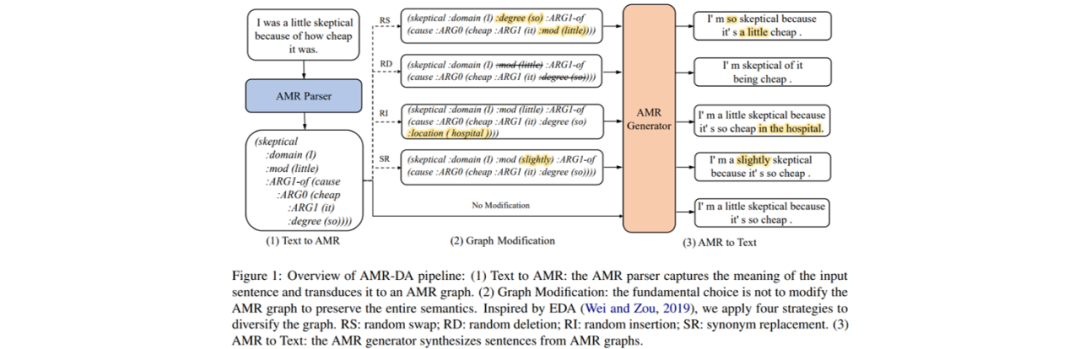
需要特别介绍的是 AMR 图谱的修改操作,包括不修改(Ori)、随机调换(RS)、随机删除(RD)、随机插入(RI)和同义词替换(SR)五种操作。
不修改操作即保持原有的 AMR 图谱不变,单纯利用生成模型实现文本改写;
随机调换每次将两个概念节点连同其连边交换,重复若干次;
随机删除每次删除一个叶子节点及其连边,重复若干次;
随机插入每次从一个节点对库中挑选一对连边节点对插入,重复若干次,节点对库是从 AMR 2.0 中提取并筛去不合适的连边节点对组成的;
同义词替换每次选择一个概念节点,并用 PPDB 同义词库中的某个同义词替换,重复若干次。
语义相似度实验
本文作者首先在语义相似度(Semantic Textual Similarity,STS)任务上进行实验。STS 要求计算句子对的语义相似度,在矛盾学习(一种无监督句级表示学习方法)中有重要应用;在这个任务中,自然语言数据增强可以提供相似度高的正例。为了检验各种数据增强方法在 STS 上的效果,本文选取了无监督的 ConSERT 和 SimCSE 两个 STS 模型用于比较,并将原始模型采用的数据增强替换为 AMR-DA。所有模型都采用维基百科语料训练,并在 7 个不同的 STS 基准数据集上测试。
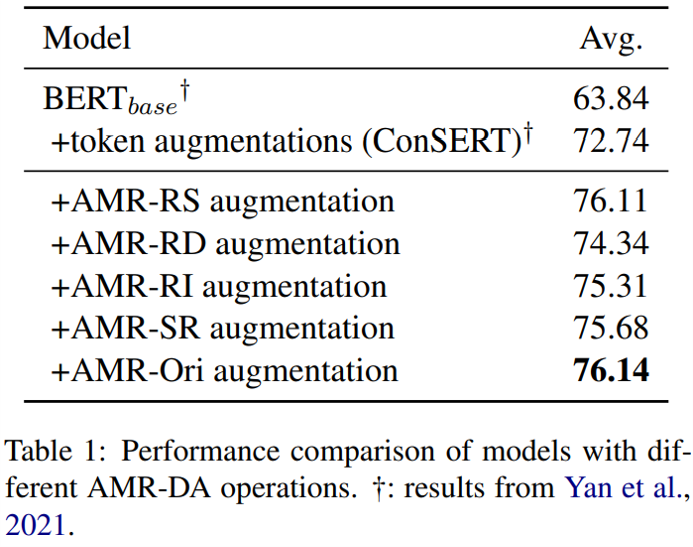
以下是各种修改操作的实验结果,可见所有操作单独应用时都能超过原版 ConSERT 采用的单词级 DA。其中,不修改的提升效果最明显,后续实验表明这是由于这一操作可以生成相似度更高的句子对。值得留意的是,上述实验显示同义词替换可以带来最大的词法多样性,但这一方法同样可以有效改进模型训练。
下图进一步比较了各种模型的测试性能,可以看到采用 AMR-DA 后,模型性能有了明显提升,基本达到了领先水平。需要指出的是,ESimCSE 模型不仅有正例增强,还采用了负例增强,而 AMR-DA 虽然只能提供正例增强,但依然可以与之匹敌。

文本分类实验
相比于语义相似度,文本分类(Text Classification,TC)的应用要广泛得多,因此本文作者同样在若干文本分类任务上测试了各种数据增强技术在 CNN、RNN、BERT 等神经网络模型上的效果。针对同一种 DA 的所有实验均采用相同的配置,且只应用于训练集的一个子集上。此外,实验分别测试了每个样本应用一处和五处修改时模型的性能。
下图展示了 TC 任务上的实验结果,其中 EDA 直接在文本上应用类似 AMR-DA 的修改,而 AEDA 是 EDA 的一种改进版本。结果显示,无论何种网络、何种任务,AMR-DA 都取得了比其它 DA 更高的分数,并且同时采用五种修改方式的提升比单独采用一种更大。
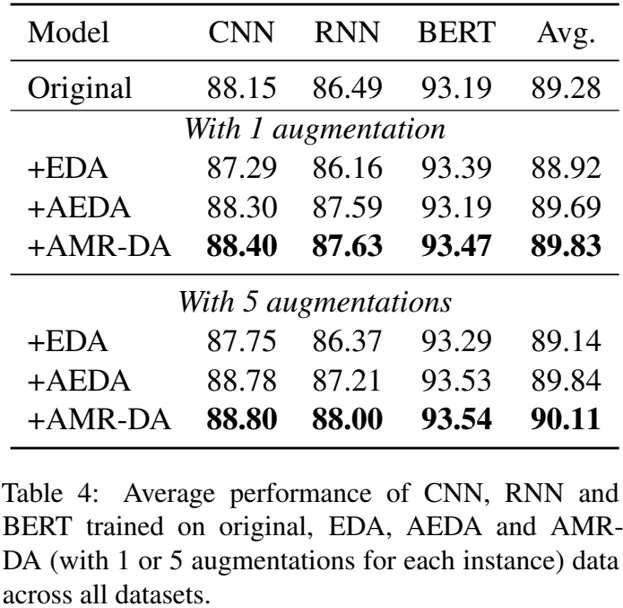
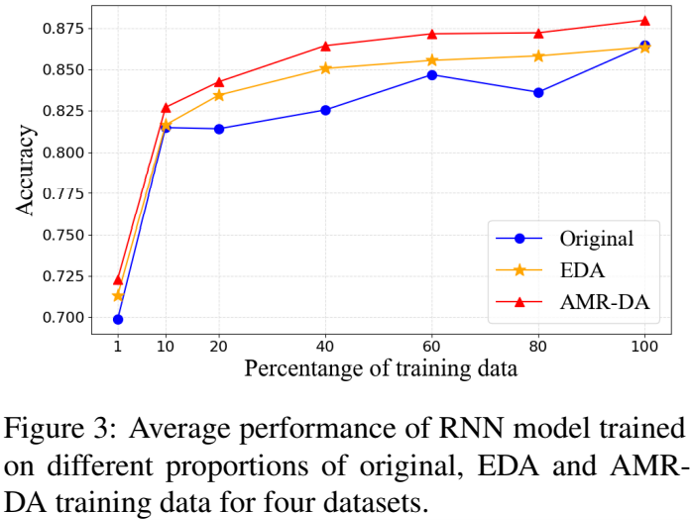
当限制模型训练集大小时,模型性能的变化如下图所示,可见 AMR-DA 在各种训练集大小下都超过了 EDA,并且与原始训练集相比有显著改进。
机理分析
在上述两个任务上实验之后,本文作者尝试从多个角度分析 AMR-DA 的优势。下图列出了不做任何 AMR 修改时 AMR-DA(以下称为 AMR-Ori)的效果,即只考虑了 AMR 图谱带来的句式多样性。可以看到,仅仅是通过解析-生成的方式改写句子,AMR-Ori 就已经表现良好,并且不同生成模型对结果影响并不算大。

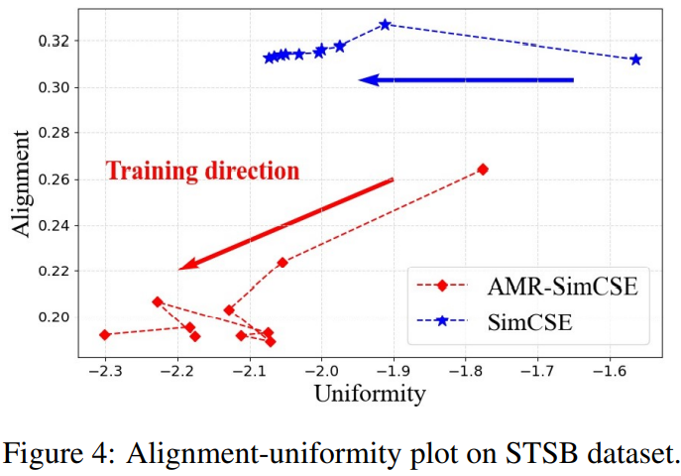
为了进一步考察 AMR-DA 带来的变化,下图展示了 STS 任务中 SimCSE 编码在不断学习的过程中对齐性(正例的相似程度)与统一性(随机样本的分散程度)的发展,其中两个指标的值越低,编码效果越好。对原版 SimCSE 而言,学习过程中虽然统一性指标确实在不断下降,但对齐性指标未能进一步改进;而采用 AMR-DA 后,模型在两个指标上都优于原版模型,且随着新数据的学习均有下降。
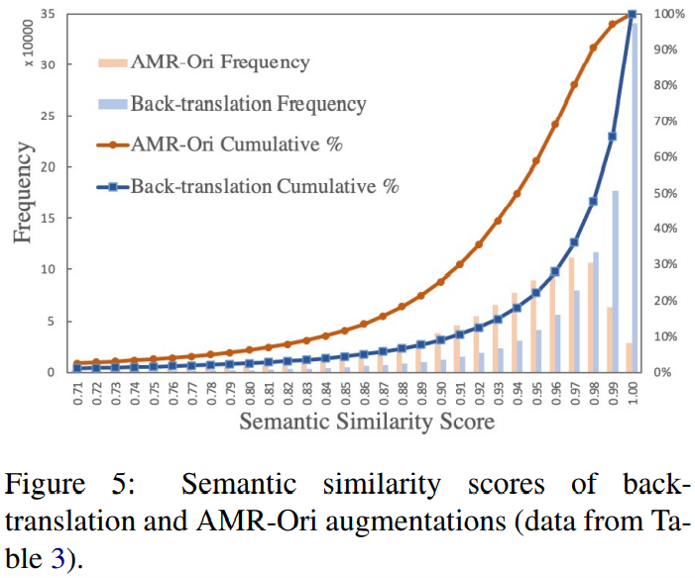
最后,下图比较了 AMR-Ori 和往复翻译生成句子对的相似度分布。两种方法都可以视为对原文的改写,但 AMR-Ori 的句子多样性要显著高于往复翻译。这也解释了为什么在 STS 任务中,往复翻译效果糟糕,但 AMR-Ori 却表现良好。
审核编辑:刘清
-
编码器
+关注
关注
45文章
3903浏览量
141442 -
AMR
+关注
关注
3文章
476浏览量
31925 -
ACL
+关注
关注
0文章
61浏览量
12755 -
自然语言处理
+关注
关注
1文章
629浏览量
14563
原文标题:ACL2022 | 抽象语义表示——建构、处理与应用的新进展
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
云知声论文入选自然语言处理顶会EMNLP 2025

HarmonyOSAI编程自然语言代码生成
北斗生态环境监测站:读懂自然的 “语言”

【HZ-T536开发板免费体验】5- 无需死记 Linux 命令!用 CangjieMagic 在 HZ-T536 开发板上搭建 MCP 服务器,自然语言轻松控板
高德与阿里云一起,开启智慧出行新范式
人工智能浪潮下,制造企业如何借力DeepSeek实现数字化转型?
云知声四篇论文入选自然语言处理顶会ACL 2025

一文全面解析AMR(磁力)传感器

自然语言处理的发展历程和应用场景
自然语言提示原型在英特尔Vision大会上首次亮相
VLM(视觉语言模型)详细解析

一种基于正交与缩放变换的大模型量化方法

大语言模型的解码策略与关键优化总结

微软重磅推出《GraphRAG实践应用白皮书》
深度学习工作负载中GPU与LPU的主要差异






 工商网监
工商网监
评论