 GPU网络中光互连的市场和产业趋势、策略和计划
GPU网络中光互连的市场和产业趋势、策略和计划

摘要
GPU加速的计算系统可为诸多科学应用提供强大的计算能力支撑,亦是业界推动人工智能革命的重要手段。为了满足大规模数据中心和高性能计算场景的带宽拓展需求,光通信和光互连技术正在迅速而广泛地渗入此类系统的各个网络或链路层级。作为系列文章的第三篇,本文针对GPU网络中光互连的市场和产业趋势、策略和计划做出分析。
在前两篇大略地介绍了GPU网络中光互连的历史趋势、短长期需求权衡、光通信技术手段之后,本篇将为读者简要分析其市场动向以及业界正在开展的进一步探索。
01
市场和产业动向:展望2025
与过去电信应用推进光互连的演变相类似,当前光互连的产业驱动力已经由数据通信应用(即数据中心)所主导。近几年,随着社交媒体、视频数据流、智能手机的用户数量不断增长,人们对数据中心内部更高的网络带宽需求愈发迫切。为了应对诸如5G、云服务、物联网、4K视频等新兴应用技术,全球数据中心的数量、占地面积、带宽容量均有显著增加。
上述现象在2016年最为明显。彼时,全球数据中心的传输链路迎来了由40 Gbit/s到100 Gbit/s的大规模链路升级。自此以降,受到新数据中心的扩张建设、已有数据中心的翻新改装、企业级数据中心的实际部署等因素的推动,光收发器的收益便以39%的复合年均增长率大幅增长[1]。而为了满足数据中心应用对100 Gbit/s光模组的大批量需求,光收发器供应商的制造能力也得到了大幅提升。
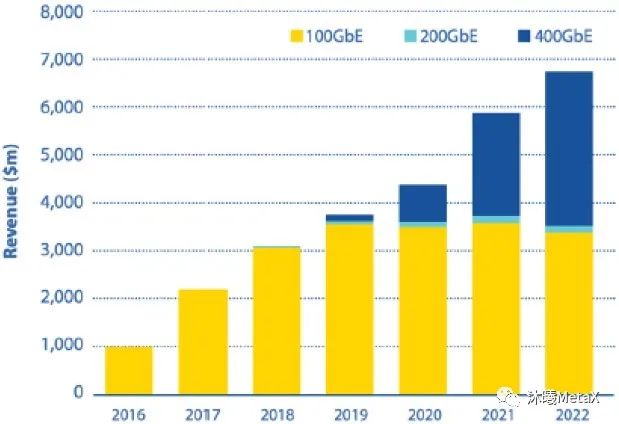
图1. 100 G,200 G,400 G光收发器的总收益
(来源于参考资料[1])
占据设备连接总数目的最大一部分便是数据中心内部的服务器互连,而带宽消耗的显著增长则使得人们需要更多地去考虑光互连的成本效益问题。为了适应近期PAM4的广泛使用和服务器速率由10 Gbit/s向着25 Gbit/s转化,网络的上行链路亦需增速。事实上,人们对容量提升的初始目标是引入400 Gbit/s的解决方案;而从成本和性能优化的角度考虑,业界在中途又加入了200 Gbit/s方案,以试图为后续400 Gbit/s方案寻求一个更加适宜的迁移路径。自2016年至2021年,光收发器总体(包括100 G,200 G,400 G)的复合年均增长率为63%;而仅就100 G光收发器而言,其复合年均增长率高达53%[2]。这主要是因为自2019年以来,200 G和400 G光收发器被商业化部署并开始小幅占据100 G光收发器的市场份额(见图1)。
对于数据中心内部的短距离光互连来说,多模光纤链路仍要比单模光纤链路占据更为主要的地位。与传统的串行传输有所不同,并行光路传输使用一个光模块接口,数据在多根光纤中同时得以发送和接收:40 GbE传输由4根光纤之上的单方向4×10 G实现;100 GbE传输由10根光纤之上的单方向10×10 G实现。这类标准引领了对高质量、低损耗的多模多路并行光学(Multi-Parallel Optics, MPO)接口的需求。
人们对数据中心带宽增长的不断需求继续驱动着业界的更多革新。以往,数据中心互连仅要求在多模或单模光纤中传输单个波长,而近期的技术驱动则聚焦在单模光纤中传输多个波长。2016年,与100 Gbit/s光收发器相符合的粗波分复用(Coarse Wavelength Division Multiplexing 4, CWDM4)技术已可以和并行单模(Parallel Single Mode 4, PSM4)在市场份额方面平分秋色。而随着200 Gbit/s和400 Gbit/s自2019年开始的实际部署,市场容量的增长已经由并行光路技术和多波长技术共同驱动。
在2016年早期,众多业界领军者在多源协议方面合作开发了一种高速的双密度四通道小型可插拔(Quad Small Form Factor Pluggable- Double Density, QSFP-DD)接口。作为可插拔收发器,QSFP-DD在保持占用空间以实现与标准QSFP的反向兼容之外,可为8通路的电接口附加提供的一排触点。QSFP-DD 8个通路中的任意一个都可以在25 Gbit/s NRZ调制或50 Gbit/s PAM4调制下工作,从而可以为200 Gbit/s或400 Gbit/s的聚合带宽提供支持;而QSFP-DD的反向兼容特点也可支撑新兴模块类型的使用、加速总体网络迁移。
当前,标准的QSFP收发器模块连接均已采用LC 双工连接器(尤其是在基于波分复用的双工模块情形下)。尽管LC双工连接器仍可在QSFP-DD收发器模块中使用,但是传输带宽还受限在单独的波分复用引擎设计上。该引擎使用一个1:4复用/解复用器来达到200 GbE,或是使用一个1:8复用/解复用器来达到400 GbE。这无疑增加了收发器的成本,并且提高了对收发器的冷却要求。

图2. CS连接器和LC双工连接器的比较
在保持连接器占用空间不变的前提下,人们期待能够实现一种可将连接器与QSFP-DD之间的连接性提升一倍的新型连接器类型。于是,作为一种双套管连接器,CS连接器应运而生。如图2所示,和LC双工连接器相比较,CS连接器的占用空间相对更小。于是,人们可在一个QSFP-DD模块的前接口部署两个CS连接器。这使得双波分复用引擎具有了较好的可行性:该双引擎可使用一个1:4复用/解复用器来达到2×100 GbE,或是在一个单独的QSFP-DD收发器上实现2×200 GbE。除了QSFP-DD收发器之外,CS连接器亦可与八通道小型可插拔模块和板中光学模块相适配。
在众多供应商采用QSDP-DD作为收发器接口的时候,网络交换面板密度也在成倍增加。自2012年以来,数据中心交换机的最大网络交换面板密度是128个单通道(信道)端口或32个4通道端口。近期,网络交换机ASIC供应商已能够将单个交换ASIC的信道数目提升到256个乃至512个。在保持单个机架单位交换机面板形状系数的同时,为了有效管理不断增长的带宽密度,人们在若干类多源协议(包括QSFP-DD,OSFP,SFP-DD)中采用了双倍密度的光收发器。由此,光纤数目也已经由4通道增长到了8通道、乃至于提升至8对光纤。而为了保持和已安装的光纤和网络交换机基础设备的兼容性,在上述收发器的实际部署中,人们可将8通道分开为2个独立的四路接口。当新型交换器得以实际部署时,数据中心的短期需求便是在同样物理空间之内的光纤对终端数量的增加。
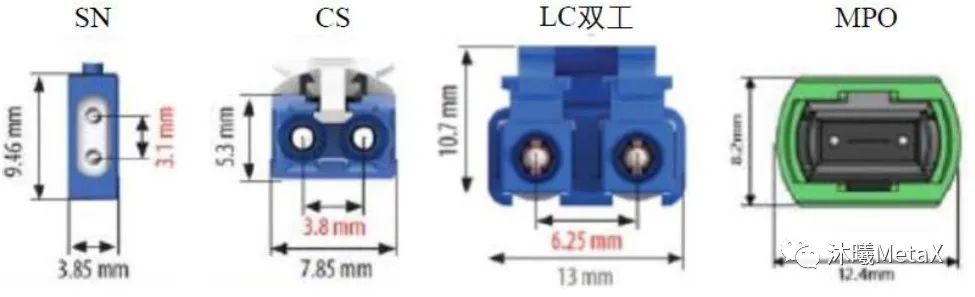
图3. SN、CS、LC双工和MPO的比较
上述需求又反过来促使业界人士去探寻进一步的革新:如图3所示,与CS连接器将LC连接器的密度增加一倍相类似,SN连接器又将CS连接器的密度增加了一倍。

图4. 在叶和脊结构中使用SN接口实现光纤分线
如图4所示,SN连接器是一种面向400 G数据中心优化方案的新型双工光纤连接器,其设计初衷是为四路方式收发器(QSFP,QSFP-DD,OSFP)提供独立的双工光纤分线。与MPO连接器相比较,SN连接器的效率和可靠性较高、成本较低。

图5. 未来光互连技术的演进
自2018年的Optical Fiber Communication Conference开始,市场分析师和技术专家便对将光互连部件移动到距离ASIC更近位置的必要性开展了广泛讨论。而早在2017年,the Consortium for On-Board Optics已针对板上光学发布了第一部工业指标规范[3]。这些技术布局的关键推动力就是高数据速率条件下铜线互连的固有限制。随着数据速率的上升,铜线的衰减大幅增加且其绝对传输限制被限定在100 Gbp/s/m[4]。而对高于这一限制的速率来说,使用光学信道便成了无法避免的技术手段。因此,光互连产业的演进并不仅限于板上光学,也包括了用于替代传统集成电路的光子集成光路(Photonic Integrated Circuits, PIC)。如图5所示,光互连下一步的演进既要满足前面板互连器件的需求,又要更多考虑PIC、板中和背板的互连器需求。
02
策略和计划:跨越成本和功耗之墙
在节点性能借助多芯片组件和GPU加速器等特殊计算单元来实现提升的同时,人们不仅对数据中心网络的带宽需求仍在持续,而且对人工智能和高性能计算的工作负载需求也呈现出激增态势。而通过增加单通道数据速率的传统方式已不再是获取效益的唯一办法。这是因为功效增益已有平缓化趋势,且低成本的电学链路已无法覆盖当前的互连传输距离。举例来说,在12.8 Tbit/s(2016)和102.4 Tbit/s(~2025)这两代交换芯片之间,光互连占据网络功率的比例将从约30%增长为超过50% [5];而对数据中心整体而言,光网络占比将会从10 Gbit/s以太网代际(2015)中的几个百分比增长为800 Gbit/s代际(~2025)中的20%以上[6]。此外,光学成本在不久的将来便会超越交换机端口的成本[5]。为了应对这不断逼近的成本和功耗之墙,人们需要从新型网络结构、共封装光学等角度来寻求一系列解决方案。在下文中,笔者将对这些方案逐一做出简短分析。
2.1
更加扁平化的网络
更加扁平化的网络意味着具备高通道数目的交换机得以使用,从而减少了交换层级。由此,人们可大幅减少交换机部件的数量并改进系统的总体吞吐量和延迟性能。而更高的端口数目可以通过使用尖端的单芯片交换机(已接近50 Tbit/s及以上)或者复合芯片配置实现。因为未来的交换芯片可具有超越单个机架所需的交换能力,所以拓扑结构应包括使用行间(End of Row)交换机来替代机架顶端(Top of Rack)交换机。
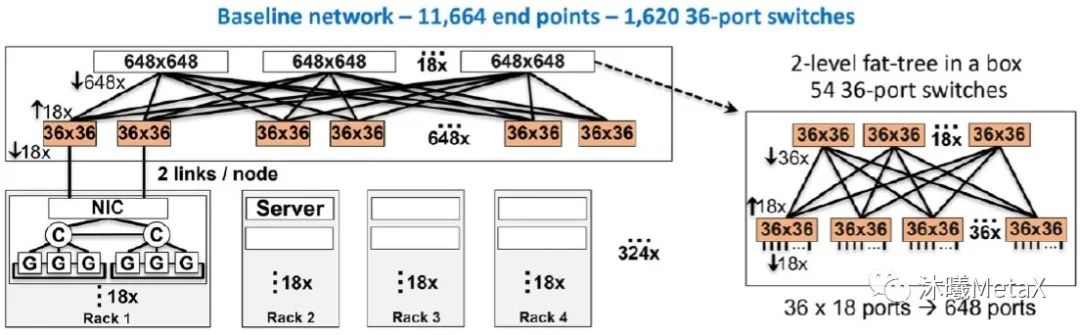
图6. 由36端口交换芯片所构成的基准网络
(来源于参考资料[7])
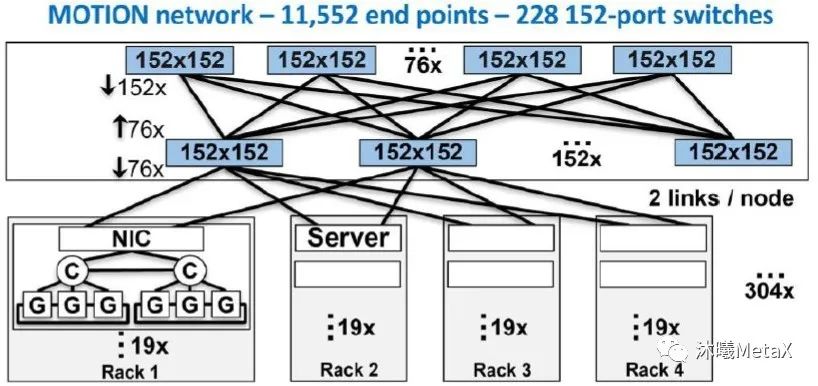
图7. 使用162端口交换芯片的扁平化网络
(来源于参考资料[7])
近期,IBM公司的P. Maniotis等[7]对使用高通道数目交换机(借助低功率的共封装光学)实现更加扁平化网络的优势做出了详细讨论。图6展示了一个由“当今的”36端口单芯片交换机所构成的高性能计算规模网络(包含11600个终端);而图7展示了一个由152端口交换芯片所构成的类似规模网络。相较而言,更加扁平化的网络可令交换芯片的数量减少85%,可大幅降低功耗和成本。
2.2
专门的硬件和网络
尽管多样化的工作负载可为数据中心定义一个更具通用性的网络和计算资源基础结构,但是在高性能计算领域,人们却一直对优化的网络拓扑结构(如用于科学计算的环形拓扑结构、用于图形分析的蜻蜓拓扑结构)颇感兴趣。
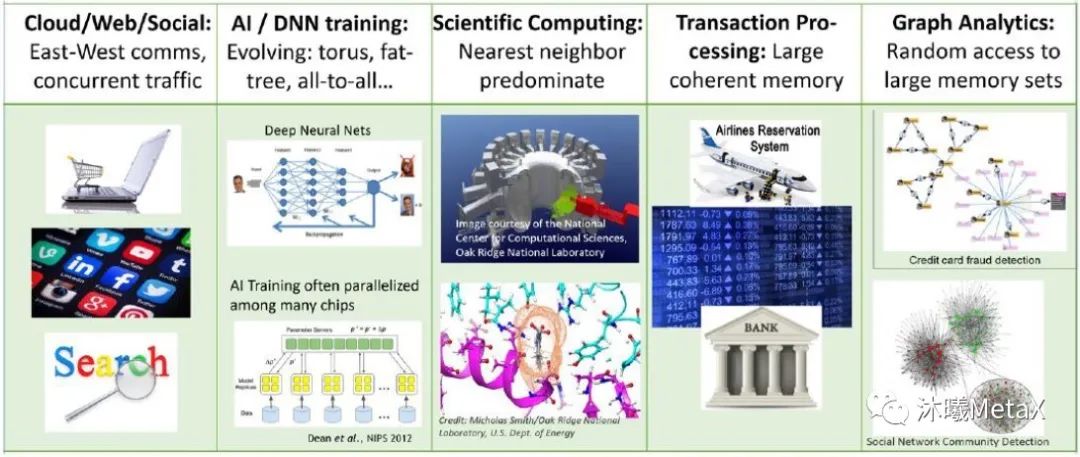
图8. 对网络工作负载需求的示例
(来源于参考资料[8])
图8展示了各式各样工作负载类型的需求范围。随着特定工作负载的重要性不断增加,针对特定任务(如人工智能训练)来制定专门的计算和网络设计将会是业界的一个关键考虑。
2.3
组合式/解聚式系统
针对特定的工作负载需求来构建资源是众多数据中心设计者梦寐以求的能力。组合式/解聚式系统意味着人们可以使用高性能结构来改进数据中心的总体效率。其潜在的优势包括:硬件可具备独立的恢复周期、用于特定工作负载的资源优化分派更具灵活性、更容易添加新的资源形态(如新型加速器)、有效降低运行成本和资本支出等。
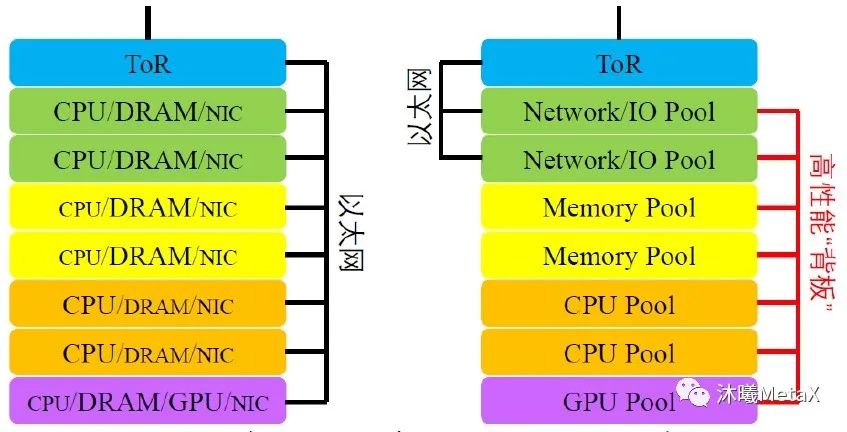
图9. 当今异构结构和未来组合式结构的概念示意图
图9为异构结构和组合式结构的概念示意图。其中,Compute Express Link[9]可为存储器和加速器解聚提供支持。在总线和接口标准(Peripheral Component Interface Express, PCIe)物理层以及给定的数据速率条件下,光互连(在跨越机架或多机架距离的高速场景中)的一个关键问题便是PCIe Gen 6中64 Gbit/s和大量以太网应用中53-56 Gbit/s 或106-112 Gbit/s之间的失配特性。
2.4
物理层效率和共封装光学
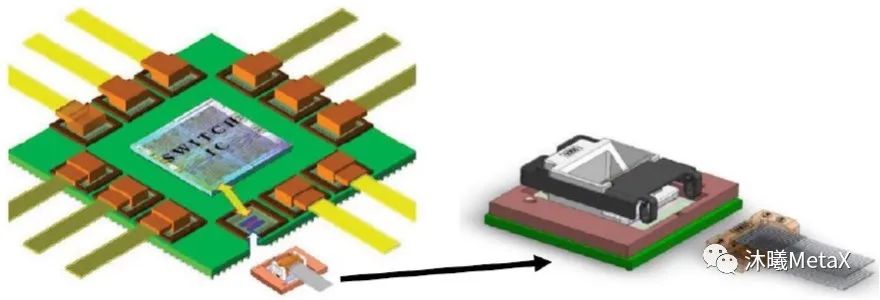
图10. 基于垂直腔面发射激光器的共封装光学概念
(来源于参考资料[7])
在持续的CMOS代际和改进的电路设计基础上,电学链路依旧能够在功率效率方面获得收效。然而,在更高的数据速率需求下,电学链路中不可避免的高信道衰减使得人们对利用光学链路满足传输距离的需求显著增多。共封装技术可使得电学链路的传输距离大幅减小,在功耗和信号一致性方面有着明显优势。它可为功耗低于5 pJ/bit的完整电-光-电链路(例如IBM公司正在开展的MOTIO2项目[10])提供潜在可能性。如图10所示,该项目基于垂直腔面发射激光器的共封装模块技术,旨在实现低成本、高性能(112 Gbit/s,< $0.25/Gbps)传输。
03
小结
基于新技术标准化的重要性,许多标准化组织、产业联盟和政府研究机构已开始着手制定未来光互连的各类技术规范。而为了跨越GPU网络光互连的成本和功耗之墙,业界也正在探索诸如更加有效的网络拓扑结构、针对特定工作负载的计算和网络结构、光电共封装等解决方案。以笔者观察,这些方案可为满足未来数据中心的高带宽需求提供有效帮助。
倘若读者对GPU网络的光互连这一领域有着独特兴趣,欢迎你关注、走近沐曦,让我们一起释放和安顿这份好奇心以及追根究底的脾气。
审核编辑 :李倩
-
gpu
+关注
关注
28文章
5272浏览量
136074 -
网络
+关注
关注
14文章
8336浏览量
95569 -
模组
+关注
关注
6文章
1797浏览量
32361
原文标题:【智算芯闻】面向GPU网络的光互连(3):凡是过去,皆为序章
文章出处:【微信号:沐曦MetaX,微信公众号:沐曦MetaX】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
如何正确选用Finisar AOC/DAC提升光互连性能

华为发布2026充电网络产业十大趋势
【「芯片设计基石——EDA产业全景与未来展望」阅读体验】+ 全书概览
从内存接口到PCIe/CXL、以太网及光互连,高速互连芯片市场分析
TE推出的AMPMODU互连系统有何特点?赫联电子怎么样?
汽车中的GPU是如何使用的?

华为智能光伏第四届全球安装商大会圆满落幕
怎样确定分布式光伏集群通信网络的负载均衡策略?

睿海光电以高效交付与广泛兼容助力AI数据中心800G光模块升级
2025年第二季度电子互连行业趋势全解析|来自Heilind的最新市场报告
中国首条"算力光轨"通车!国内首个分布式光互连光交换超节点发布

上海仪电联合曦智科技、壁仞科技、中兴通讯发布国内首个光互连光交换GPU超节点——光跃LightSphere X




评论