 MCM应用于GPU还需要多久
MCM应用于GPU还需要多久

消费用户市场,普通用户都能用上16核甚至64核处理器的PC。这可不是单纯堆核心就完事儿的。以当前CPU核心的规模,和可接受的成本,消费电子设备上一颗芯片就达到这种数量的核心数目,与chiplet的应用是分不开的。
Chiplet是这两年业界的香饽饽。前不久的ISSCC会议上,chiplet也是今年的热门议题。AMD从Zen架构开始,Ryzen系列处理器就全面应用了chiplet技术。Chiplet并不是什么新技术,更早提的MCM(multi-chip module)就是应用了chiplet的一种芯片方案。
简单来说,MCM通常是指将多个die(多个IC或chips)封装到一起的多芯片模组。构成MCM的一个个die,或者功能电路模块,即是chiplet。多个chiplet之间能够协作,构成更大的芯片,也就是MCM(有时,MCM/Multi-chip Package又被当做某一类封装方式)。
不过本文探讨的MCM/chiplet可能有一定程度的窄化,这里不探讨类似Intel Kaby Lake G那一类方案,即便它算是典型的chiplet应用(以及像很多近代Intel处理器那样只将处理器die和PCH die分开的那类chiplet,以及HBM存储chiplet)。可能单纯称其为MCM会更合理。
以AMD的Ryzen 3000系列处理器为例,每4个核心(外加cache)组成一个CCX,两个CCX就组成一个CCD——也就是一个die或chiplet。一颗处理器芯片上就会有多个这样的CCD。另外还有个I/O die作为通讯中心(cIOD),连接各个die,如上图所示。
值得一提的是,Ryzen 3000处理器的CCD部分制造采用7nm工艺,而cIOD则选择了12nm工艺,这就很能体现chiplet在制造上物尽其用、节约成本的优越性了。
如果说处理器的chiplet/MCM商用已经全面落地,那么die size更大的GPU能不能也采用MCM的方案?这是本文要探讨的话题,MCM应用于GPU还需要多久?借此也能窥见chiplet作为此类高算力芯片的技术方向时,半导体制造已经走到了哪里。
当GPU的die尺寸大到吓人的程度时
如果只看消费市场,骨灰级玩家对GPU算力的追求是无止尽的。只怕算力不够,不怕价格、功耗有多夸张。图形算力的饥渴从未停止过:1998年3dfx引入SLI技术,即2个或者更多的显卡一起上,实现更大规模的图形并行计算。
SLI同类技术(包括AMD的CrossFire)并未大规模普适,主要是因为这样的技术不仅有硬件级别的支持要求,而且对游戏开发者也有要求。在很多不支持多GPU并行计算的游戏中,此类方案甚至会令游戏体验变差。不过多GPU扩展的方案,在当代数据中心还是比较常见的。
基于这个思路,如果将多GPU的层级下沉到多die——也就是一个GPU之上,有多个chiplet,堆砌更多的图形计算单元,好像也是完全行得通的方案。只不过多GPU(或多芯显卡)需要跨系统或者跨板级,而多die则是基于同一个基板的封装级方案,延迟和带宽理论上也比跨PCB板更有优势才对。
那么为什么不直接将现在的GPU做得更大,在一颗die上堆更多的计算资源呢(也就是所谓的monolithic)?如果摩尔定律恒定持续,同面积内容纳更多晶体管,则这种方案是可持续的。但在摩尔定律放缓的情况下,要在一颗die上塞下更多的图形计算核心,尺寸和成本都是无法接受的。
目前的显卡主流产品,AMD Radeon RX 6900XT的单die尺寸达到了519mm²,英伟达Geforce RTX 3090则达到628mm²。这种die尺寸也算是不惜血本的代表了,逐渐逼近光刻机可处理的最大尺寸(rectile limit, 858mm²)。未来再给GPU加计算核心,单die方案会有极大难度。这是GPU考虑MCM/chiplet方案的先决条件。
从成本来看,这个问题大概会更明朗。即便不考虑切割大面积晶圆可能造成良率低下的问题,更小die也能带来更高的成本效益。300mm的wafer满打满算造114片22x22mm(接近Vega 64尺寸)片单die;如果切分成更小的11x11mm,即原有每片die可获得4片更小的die,则很大程度减少了晶圆切割边缘浪费,就能造488片die——如果这些die在理想情况下每4片组成一颗MCM芯片,则产量就高了大约8%。
当然这其中并未考虑wafer不同形状的优化方案,也没有考虑制造缺陷之类的问题,而且MCM芯片还需要耗费更多的die来做专门的通讯(比如前文提到Ryzen处理器的I/O die)。但chiplet/MCM能够实现的成本节约仍然是显著的。
EE Times专栏作者Don Scansen前不久撰文提到,“AMD计算出,以Chiplet方法制作EPYC处理器时,会需要比单一芯片多出10%的硅晶圆面积做为裸晶对裸晶(die-to-die)的通讯功能区块、冗余逻辑(redundant logic)以及其他附加功能,但最后整个chiplet形式处理器的芯片成本,比单芯片处理器节省了41%。”
总结一句话,chiplet/MCM本质上是在摩尔定律止步不前的当下,为进一步提高芯片算力,采用的一种控制成本的方案。这里的成本控制实际上还表现在IP的复用和弹性,chiplet有时可以“复制粘贴”的模块化方式,灵活地存在于芯片之上。AMD如今的Ryzen处理器能够如此便捷地堆核心,并且在多线程性能表现出对Intel的碾压优势,和chiplet是分不开的。
GPU应用chiplet的阻碍
不过GPU要应用chiplet却并不是一件简单的事,就好像显卡SLI(或双芯显卡)经过了这么多年,都并未普及开一样。Raja Koduri此前还在AMD的时候提过,GPU可能会采用Infinity Fabric方案(AMD Ryzen处理器的一种互联方案);这在当时被认为是MCM型GPU提出的依据。不过众所周知Raja Koduri后来就离开了AMD,此间规划的延续性是未知的。
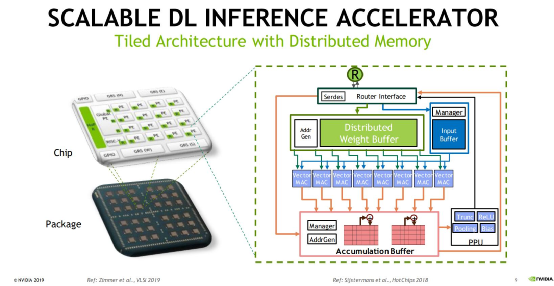
2019年英伟达宣布实验室打造一款名为RC18的AI处理器。这颗处理器采用16nm工艺,更重要的是选择了多die解决方案。芯片整体包含36个小型模块,每个模块主要由16个PE(Processing Elements)构成,外加RISC-V核及对应的缓存,另外还有英伟达的GRS(Ground-Referenced Signaling)互联。当时英伟达提到,RC18的存在表明很多技术的可行性,包括可扩展的深度学习架构,以及高效的die-to-die方案。
这颗芯片对于未来的chiplet型GPU而言可能是个重要模板。不过对于图形计算的GPU而言,在同一颗芯片上渲染画面帧,要分配到不同chiplet之上,难度还是会比这类AI芯片更大的。2018年AMD RTG团队高级副总裁David Wang在接受PCGamesN采访时,曾经提到过MCM GPU要实现起来并不简单。“我们在看MCM型的实现方法,但目前尚无法定论,传统游戏图形计算会应用类似技术。”
“从某种角度来看,其实这也就是在单一封装上去做CrossFire(AMD版的SLI方案)。其挑战在于,我们需要能够做到在硬件层面对开发者不可见,否则其发展就不会顺利。”而且,“GPU在NUMA(非一致性内存访问)架构以及一些特性方面有着一定的限制……”,尤其相比CPU,图形计算负载的这种设定会更有难度。
这话的意思是指,第一,如果MCM GPU需要游戏开发者去花额外的时间做开发上的调整,或者增加开发难度,则成为推广MCM GPU的阻碍。第二,不同die之间互联效率、数据一致性问题:包括在chiplet之间切分图形计算管线,以及彼此之间存储访问的差异性,都会给设计带来更高的复杂度。
SLI——即以前的多GPU(或板级多芯片GPU)方案实际上是这两个问题的放大版本。面向开发者时开发难度大;不同GPU之间的工作部署有难度。(而且多GPU方案非常依赖于多层级的系统互联,这个过程中的数据迁移、同步带来的功耗问题也比较大;所以最终互联,达成的有效带宽和每比特消耗的能量都不尽人意)
其中后一个问题也是chiplet技术演进探讨的热门议题,即便已经商用的chiplet CPU产品,依旧在互联方面有着持续改进的空间。
Chiplet即将应用于GPU的几个先兆
MCM GPU真正在这两年呼声特别高也不是没有原因的。其中有几件标志性事件可能表明MCM GPU离我们并不遥远了——即便最早一批MCM GPU可能会是面向数据中心的,并在后续才逐渐下放到游戏和图形计算市场。
首先是Intel这边,Raja Koduri(没错,就是之前AMD的那位)今年一月份在Twitter上发布了一条推文,展示Intel即将推向市场的Xe HPC,如上图所示——有关Xe GPU,此前介绍十一代酷睿的核显文章曾大致谈到过。Xe面向HPC高性能计算时,作为独立GPU形态存在。
这枚代号为Ponte Vecchio的芯片看起来还是蔚为壮观的。就这张图片来看,这颗GPU计算核心可能主要由上下两个chiplet构成,围绕四周的应该是HBM存储,还有I/O或者其他属于Xe特性的组成部分。Chiplet之间可能采用Intel的EMIB(Embedded Multi-die Interconnect Bridge)连接。此前Intel也提过Ponte Vecchio之上应用了Foveros 3D堆叠技术,具体情况未知。不过chiplet在GPU上的应用,或者说真正的MCM GPU,在此也是初见端倪的。
除此之外,2019年底Twitter传出一则泄露消息,称英伟达新一代Hopper架构(Ampere后续架构)GPU将以MCM的形态问世。
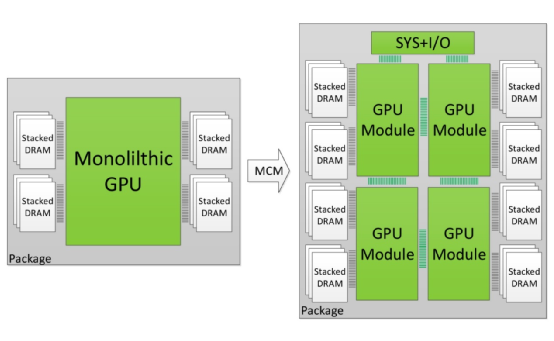
来源:MCM-GPU: Multi-Chip-Module GPUs for Continued Performance Scalability, Nvidia
事实上,英伟达在2017年的ISCA上就发表过一篇题为MCM-GPU: Multi-Chip-Module GPUs for Continued Performance Scalability的paper。虽然这篇paper中提到的方法,只是在英伟达实验室里以模拟的方式将MCM GPU,与单die GPU和多GPU方案进行比较,不过表明英伟达的确是有在探讨其可行性的。
这篇paper有具体探讨不同层级的多芯片方案,比如SLI那样的多显卡方案,以及板级多芯方案、同封装下的多die方案、单die方案等,互联带宽和开销问题;并且认定当代技术储备,比如说substrate尺寸、die之间信号通讯技术(如英伟达的GRS)都正走向成熟,给MCM GPU的实现开创了技术条件。

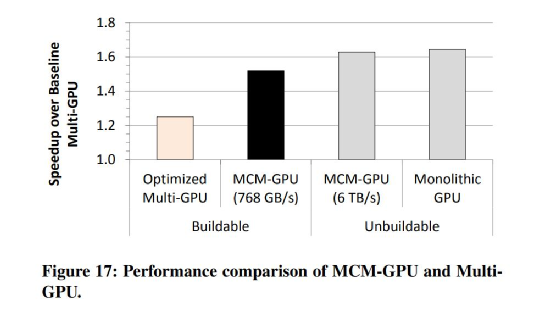
此外这篇paper提到了几个优化方案,包括引入L1.5 cache,不同chiplet之间线程调度和数据划分方案。从这套方案的结果来看(如上图),虽然某些测试项有不尽人意之处,但整体上MCM GPU能够实现在性能上比多GPU方案的显著领先(且功耗遥遥领先,0.5 pJ/bit vs 10 pJ/bit),而且性能较同计算硬件资源的单die方案,并没有太大损失(而且需要注意,这种单die方案现实中是造不出来的)。而相比目前能够制造的最大单die方案(128 SM单元),英伟达预设中的这套方案有45.5%的性能优势。
文中提及将这样的方案应用在HPC大规模集群中,能够极大提升性能密度,系统层级减少机柜数量,以及对应的系统级网络、通讯规模变小。最终实现通讯、供电、制冷系统的耗电量极大节约。只不过这篇paper,整体上更多仍停留于纸面和模拟。
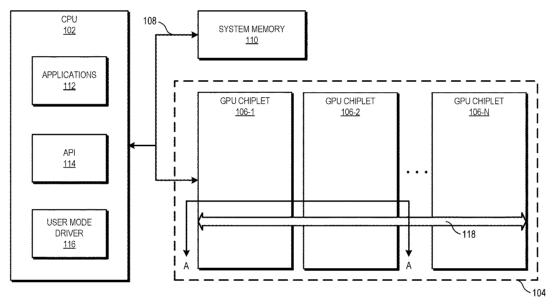
最后AMD作为已经在CPU之上推开chiplet的市场玩家,今年年初浮现一则其2019年申请的专利,名为”GPU Chiplets using High Bandwidth Crosslinks”。这项专利的很大一部分,旨在解决MCM GPU在开发层面困难的问题。
这项专利提到系统中包含一个CPU。它在通讯上与GPU chiplet阵列的第一颗chiplet连接。CPU和这颗GPU chiplet通过一条总线连接;而这颗GPU chiplet和后面的chiplet则通过一种passive crosslink连接。这里的passive crosslink实际上是个被动interposer die,专门用于chiplet之间的通讯,以及负责将SoC功能切分成更小的chiplet。(如上图所示)
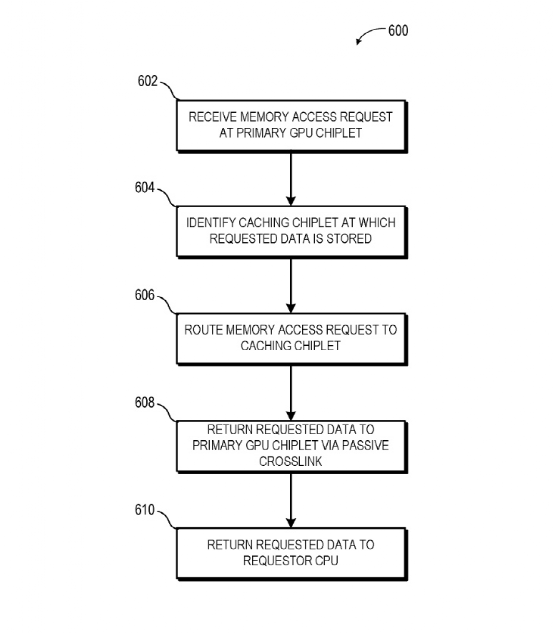
针对存储一致性问题,每颗GPU chiplet都会有其各自的LLC(last-level cache),也就是L3 cache。LLC跨所有的chiplet实现一致性,也是实现跨chiplet存储一致性乃至提升MCM GPU效率的关键。
这套系统中,仅第一颗GPU chiplet接收来自CPU的请求,这样一来对CPU而言,GPU就好像是传统的单die方案一样,对图形计算开发也就比较友好了。未知AMD是否已将这项专利付诸实现,GPU本身内部的通讯延迟理论上可能会更高。
不过如前所述,MCM GPU最早应用的理论上可能还是数据中心、HPC这些领域。毕竟如英伟达在paper中所述,这样的设计对于数据中心具备了更天然的替代优势。而在技术逐步准备就绪之际,MCM GPU的出现的确只是时间问题,包括下放到游戏市场。Intel、AMD和英伟达,哪家将率先踏出这一步,也是值得拭目以待的。
-
处理器
+关注
关注
68文章
20332浏览量
254924 -
gpu
+关注
关注
28文章
5271浏览量
136069 -
MCM
+关注
关注
1文章
70浏览量
22939
原文标题:GPU越做越大,快到极限了怎么办?
文章出处:【微信号:zhuyandz,微信公众号:FPGA之家】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
自动驾驶占用网络还需要数据标注吗?

如何在 VisionFive v2 上使用外部 GPU?
二进制 GPU 驱动程序需要什么才能启动?
单片机中有FLASH为啥还需要EEROM?


电子产品有CE认证还需要做RoHS吗?2026年合规答疑

技术资讯 I 一文速通 MCM 封装



请问riscv中断还需要软件保存上下文和恢复吗?

FU6866应用于风机出现电流波动
GPU架构深度解析





评论