 解析yolov7采用的一项技术:模型结构重参化
解析yolov7采用的一项技术:模型结构重参化

Yolov7问世,刷新了目标检测内卷的新上限!小博此次携手博世AI大神Zlex做一次解析。今天,我们不准备解析yolov7,而是解析yolov7采用的一项技术:模型结构重参化。
首先,这要从古老的vgg说起,很久很久以前神经网络还没有很多花样的时候,他是一个以卷积为主串联的网络结构,如下图所示:
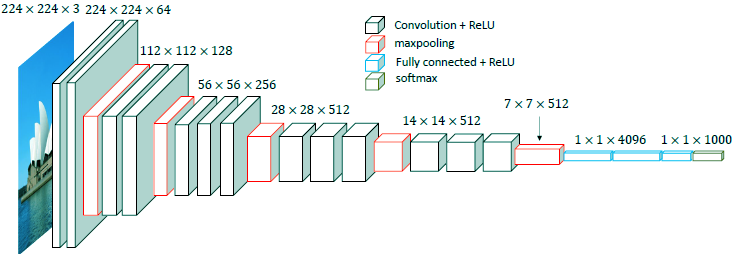

由于见证了神经网络的神奇效果,科学家工程师们前仆后继开发了resnet, inception net, 以及自学习产生的efficientnet等等以结构创新为主的系列,以及归一化系列(ln,bn,gn,in),激活函数系列, 卷积系列等各种新的计算层,还有各种损失函数层等等。
随着思维的展开,除了从计算方法(数学推理角度)和网络结构(实验性创新角度)层面创新,还有哪些脑洞可以打开呢?是否可以实现数学和网络结构方面的互相转化?答案是肯定的,数学推算和结构设计之间是可以相互转化的。
而模型结构重参化就是其中一种。
01
模型结构重参化
模型结构重参化是继承了深度学习的特性,并作为思考点而展开的,也就是训练(train)和推断(deploy)分别思考的策略,通常我们是可以忍受训练速度较慢,但是推理更加快速的部署方案。
基于这个现实的考虑,是否可能通过增加训练的复杂度但不增加推断运行的时间,从而达到模型能力的提升?
其实这一切都经不起科学家的推敲,这种思路的可行性答案也是肯定的,其实在很久之前的部署加速技巧—— Conv、BN、Relu 三个层融合(大部分情况是conv和bn融合)也是发现了——训练和部署可以在网络结构不同的情况下实现效果等价,这个数学公式等价变换思路。而tensorRT等部署加速方案也都融合了这项技术。
模型结构重参化(structural re-parameterization)是丁霄汉近年来提出的一种通用深度学习模型设计方法论。该方法论首先指出了构造一系列用于训练的结构,并将其结构等价转换为另一种用于测试的结构,也就是训练和测试的结构不再相同,但是效果等效。
该理论是假设在训练资源相对丰富的条件下,在不降低推理能力的前提下又能达到提速的目的。因此训练时的模型可以足够复杂,且具备优秀的性质。而转换得到的推理时模型可以简化,但能力不会减弱,也就是实现无损压缩。
为什么要以vgg为例,而不是以目前各种先进复杂的结构为例解析这一设计呢?其原因在于:模型结构复杂提升了精度,但不利于硬件的各种并行加速计算。但vgg这种单一的结构更容易做很多的变形和加速操作,Repvgg就是基于vgg网络的模型结构重参化。
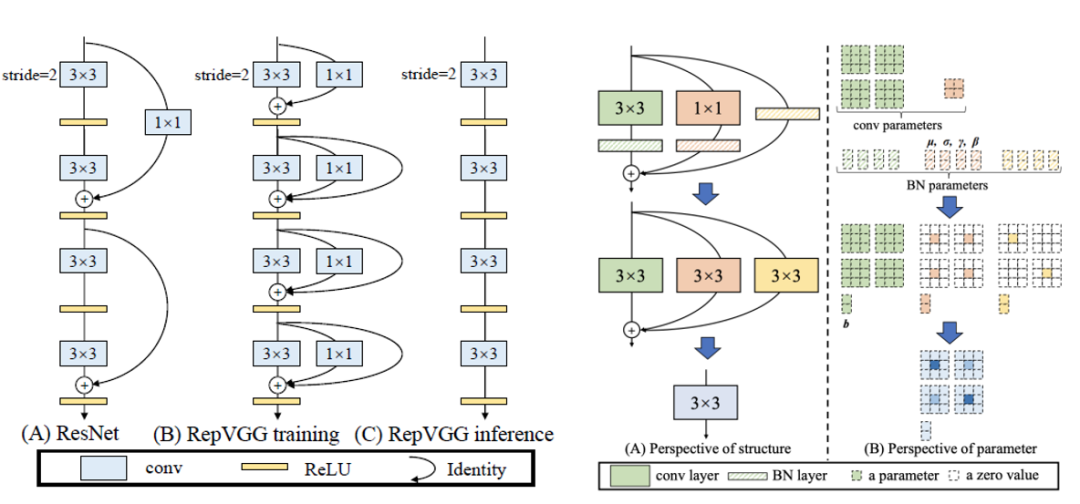
论文中对比了resnet的参差结构和rep结构的不同,以及训练和推理网络如何转化,如下图所示:
以上设计方法论基于的数学关系是:
(i+c+b)*w=i*w + c*w + b*w的等式理论。
该等式画成结构图是:
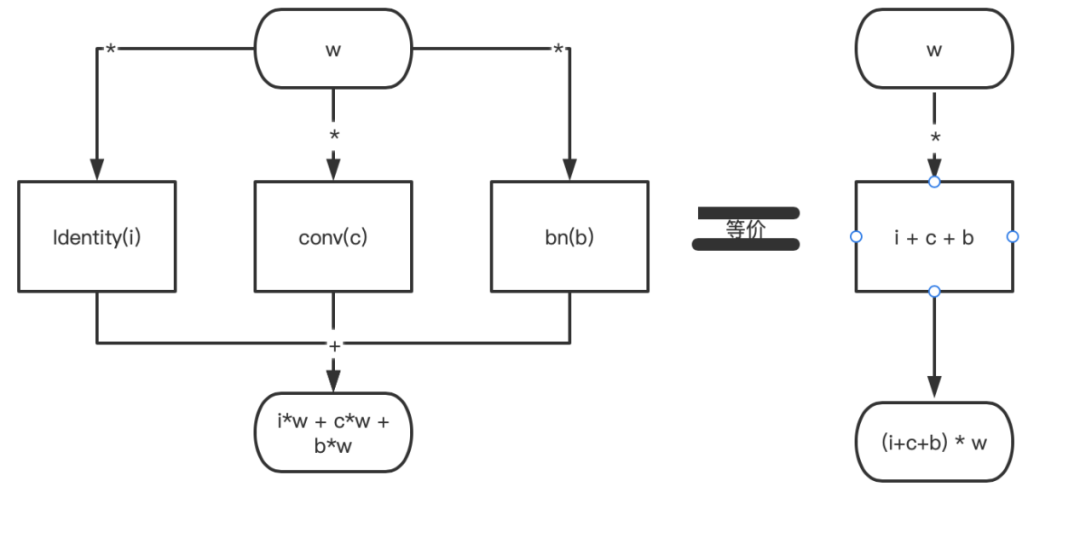
只不过在卷积的世界里,a和b表示的是一个n*n的核;而在一些设计里面,a和b的大小是不一致的。这个时候就需要把现在a和b的维度进行一致性转换,也就是repvgg作者采用的:把1*1的核通过pad的方法补0操作变成3*3的核,达到a、b维度一致。
identity的操作相当于是1*1的单位矩阵卷积pad后就可以转化为3*3的卷积核。还应该值得注意的是:每个卷积后面还跟着bn层,这是就用到了上述提到的conv和bn的融合计算方法。
02
Yolov7在这项技术上的发现和创新
Yolov7中的模型结构重参化做了哪些创新?
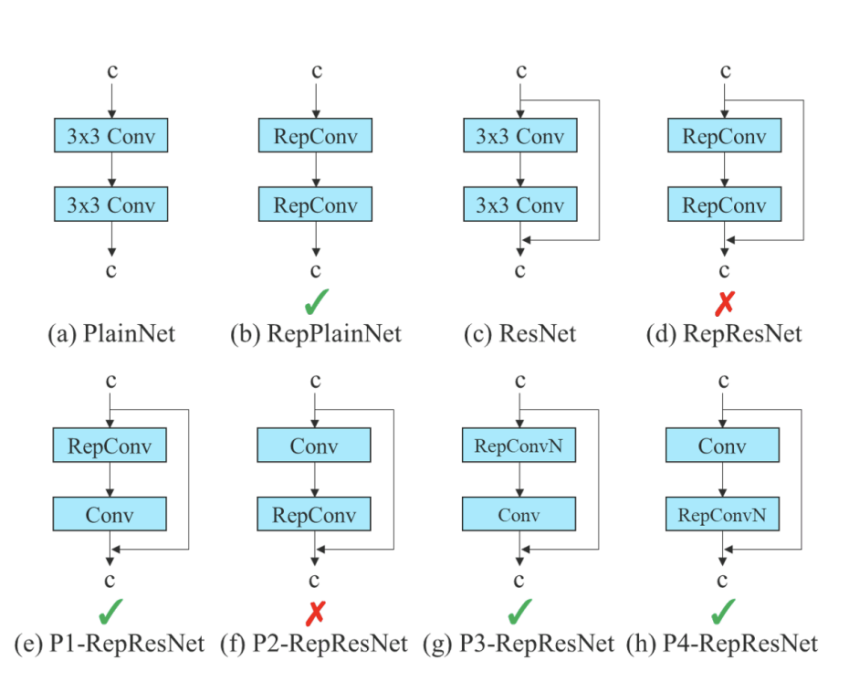
Zlex发现Rep的结构策略直接用到resnet等结构的网络中达不到预期效果,分析后发现identity层的使用破坏了resnet的参差结构和densenet的级联结构,因此去掉identity层,采用如下图(g和h)的结构方式有效。
03
Yolov7工业应用领域的改善空间
俗话说,极致的项目一般是“既要,也要,还要”的模式——既要推理速度快!也要推理精度高!还要训练速度也不能太慢!
Yolov7无疑是吸收了很多仙气修炼成的佳作,但也存在些许缺点,这些缺点也是该设计本质性的东西,Yolov7的训练速度经过Zlex亲测,比其他yolo系列慢了很多。对于资源有限型的AI爱好者也形成了一定的障碍,单元时间可以跑的实验次数少了很多,验证一些想法的节奏也慢了很多。
Yolov7给博世工业检测、自动驾驶、数字化等领域又注入了新的超能力,应用过程中也会发现这样或者那样的问题,比方说训练资源有限,速度跟不上项目的节奏,能力提升的trick不够适应自己的应用场景,小数据训练效果不佳,不同平台的移植工作量大等等,需要我们博世工程师在适配、融合和改进的路上坚定的前进。
审核编辑 :李倩
-
模型
+关注
关注
1文章
3882浏览量
52379 -
深度学习
+关注
关注
73文章
5614浏览量
124817
原文标题:博采众长 | 在提升深度学习模型能力方面的那些魔鬼细节:模型结构重参化
文章出处:【微信号:rbacinternalevents,微信公众号:博世苏州】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
瑞芯微(EASY EAI)RV1126B yolov8训练部署教程

瑞芯微(EASY EAI)RV1126B yolov5训练部署教程

零基础手写大模型资料2026
是德科技与联发科技联合完成一项工作原型验证
研华科技携手森云智能率先完成一项重要技术突破
openDACS 2025 开源EDA与芯片赛项 赛题七:基于大模型的生成式原理图设计
使用ROCm™优化并部署YOLOv8模型
单板挑战4路YOLOv8!米尔瑞芯微RK3576开发板性能实测
基于瑞芯微RK3576的 yolov5训练部署教程

在K230中,如何使用AI Demo中的object_detect_yolov8n,YOLOV8多目标检测模型?
请问yolov8训练模型如何写双线程?
yolov5训练部署全链路教程

如何提高yolov8模型在k230上运行的帧率?
AI技术加持,宏工科技锂电包装自动化装备新突破




评论