 ERNIE-Search模型结构
ERNIE-Search模型结构
说来惭愧,之前写了一篇对向量召回的总结(前沿重器[28] | 前沿的向量召回都是怎么做的),万万没想到现在就来写新文章了,而且上面的总结还没提到,大家当做扩展和补充吧。
众所周知,在语义相似度上,交互式方案总会比非交互方案更容易获得较好的效果,然而在召回上,非交互式方案(也就是表征式)具有得天独厚的优势,我们最终使用的,又不得不是非交互的方案,因此我们会尝试进一步优化非交互方案。
最近开始发现一些从交互式蒸馏到交互的方案,例如21年年末美团提出的VIRT(VIRT: Improving Representation-based Models for Text Matching through Virtual Interaction),今天我们来聊的是百度在22年5月份提出的方案,我认为这篇论文是这个领域内目前比较有代表性的,主要有这几个原因:
整理了一些比较好的蒸馏思路和方向。
对这些蒸馏方案做了一些消融实验。
试验了一些前处理的方案,甚至包括一些furture pretrain。
论文和有关资料放这里:
原论文:ERNIE-Search: Bridging Cross-Encoder with Dual-Encoder via Self On-the-fly Distillation for Dense Passage Retrieval
文章讲解:
https://zhuanlan.zhihu.com/p/522301876
https://blog.csdn.net/moxibingdao/article/details/125713542
https://zhuanlan.zhihu.com/p/518577648
表征式能逼近交互式吗
之所以想先聊这个,是因为想说一下这两者之间存在的可能性,即表征式是否可以达到交互式的效果,从苏神有关这块的推理来看(https://spaces.ac.cn/archives/8860),其实是可行的,虽然这块的推理并不算严格,但是这个推理已经相对可靠了,换言之,我们可能可以找到更好的学习方法,找到这样一组参数,使表征式能达到交互式效果的这个理论高度。
ERNIE-Search模型结构
模型结构,我比较想从损失函数开始讲,其实从损失函数看就能看出本文很大部分的贡献:
这个损失的内容非常多,我把他分为两个部分,一个是独立训练的部分(不带箭头的),另一个是蒸馏部分(带箭头的)。首先是独立训练的部分,这部分主要是直接针对标签进行训练的,无论是teacher模型还是student模型,其实都是需要这个部分的。
:cross-encoder,交互式的方案,在这篇论文里,使用的是ERNIE2.0(4.1.3中提到)。
:late-interaction,延迟交互方案,这里是指介于交互式和表征式之间的方案,开头是双塔,后续的交互式并非cos而是更复杂的交互方式,如ColBERT(ColBERT: Efficient and Effective Passage Search via Contextualized Late Interaction over BERT)。
:Dual-encoder,表征式方案,就是常说的双塔,本文用的是同样是ERNIE2.0(4.1.3中提到)。
另一部分则是蒸馏部分,这里的蒸馏部分作者是做了很多的心血进行分析的,构造了好几个损失函数,分别是这些,这里的几个蒸馏损失函数用的都是KL散度:
:交互方案蒸馏到延迟交互方案。
:延迟交互方案蒸馏到表征式方案(和共同形成级联蒸馏)。
:交互方案蒸馏到表征式方案。
:最特别的一个。实质上是一个token级别的交互损失,旨在希望延迟交互得到的attn矩阵和交互式的attn矩阵尽可能接近。
回到损失函数本身,其实会发现这个损失函数是由多个损失函数组合起来的,敏锐的我们可以发现,这里的几个损失之间的权重是完全一样的,估计调整下可能还有些空间吧,不过也考虑到损失函数实在够多了,调起来真的不容易。
说起效果,这点作者是做了消融实验的:
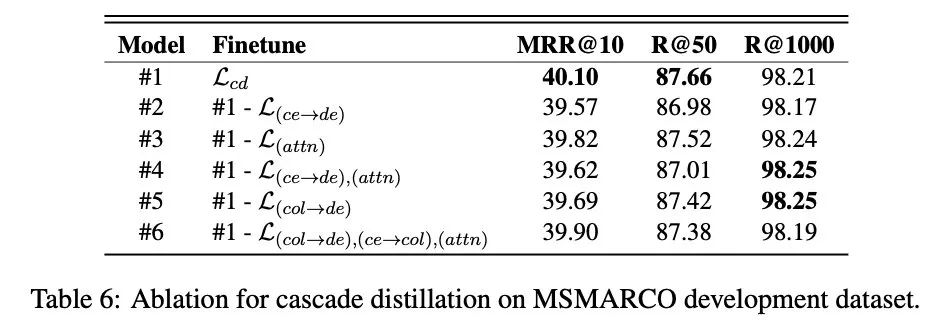
损失函数消融实验
从实验结果来看,其中贡献最大的是,也就是交互方案蒸馏到延迟交互方案,其二是(我感觉就是),这个也挺符合直觉的吧,但是比较神奇的是去掉了比较多以后,就是#6的实验,好像最终对结果的损失反而会变少,这个有些神奇,有待进一步实验和探索吧,当然,我感觉这里可能和权重也有关。
训练策略
还需要提一个关键点就是文章在4.1.3中提到的训练策略,这个特别的训练策略为最终的结果贡献度不少(可以参考消融实验),因此展开说一下:
使用对应语料对预训练模型(应该就是ERNIR2.0)进行继续预训练,这个阶段在文中也被称为post-train。
对QA任务,使用交互式蒸馏到表征式的方案,训练表征式模型。
对QA任务,再使用上面的级联蒸馏方案,训练表征式模型,和上一条被联合称为finetune阶段。
另外,在3.4中,有提到一个训练策略叫Dual Regularization(DualReg),其实我感觉这个和r-dropout很相似(前沿重器[15] | R-Dropout——一次不行就两次),用两个不同随机种子的dropout对表征式进行前向训推理,得到两个表征结果,用KL散度进行学习,而因为双塔,实际上要对q1和q2都这么做一次,所以实际上会多两个损失函数。

训练策略消融实验
这些训练策略的效果,在4.3.1中有进行消融实验,如上图所示,直观地,从这个表其实可以发现几个信息:
ID'(也就是交互式蒸馏)具有一定的优势,尤其是在Finetuning阶段,但是在Post-train中的收益似乎不那么明显。
DualReg似乎是有些效果的,但是不清楚为什么要把CB(RocketQA中的提到的跨batch负采样策略)也放一起,就感觉这个东西和本文的创新点没啥关系,让我们并不知道是CB的贡献,还是DualReg的贡献了。
但是感觉做的有一些马虎,主要是为了证明这个ID'(也就是交互式整流)的方案比较厉害,但是从这个表来看收效没有想象的大额,不过有一说一,前面的继续预训练还是非常值得我们学习和尝试的,这点我在(前沿重器[26] | 预训练模型的领域适配问题)中有提到过。
小结
总结下来,这篇文章最大的特点是把“通过学习交互式,来让表征式效果进一步提升”这个思路发挥很极致,让我们知道了这个方案的潜力,这个是有些实验和落地价值的。
除此之外,这篇文章在初读的时候,其实发现了不少新的概念(可能也是我有些匮乏吧),所以挖了不少坑,论文里的下面这张表其实都值得我好好读一下,当然也包括introduction里面的。
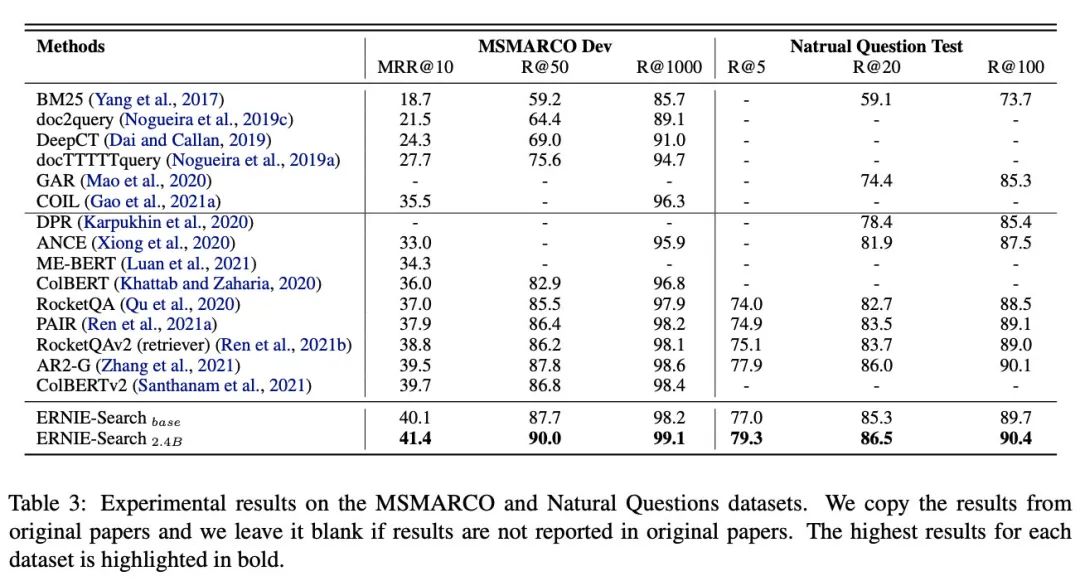
对比实验
审核编辑 :李倩
-
函数
+关注
关注
3文章
3868浏览量
61308 -
模型
+关注
关注
1文章
2704浏览量
47681
原文标题:ERNIE-Search:向交互式学习的表征式语义匹配代表作
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
百度智能云推出全新轻量级大模型
百度智能云发布三款轻量级大模型和两款特定场景大模型
Stage 模型深入解读

protues添加通过component search engine 下载的电子元件模型后闪退
jvm内存模型和内存结构
晶闸管的结构和功能模型
网络模型的七层结构和五层结构
OpenHarmony ArkTS工程目录结构(Stage模型)
卷积神经网络模型原理 卷积神经网络模型结构
用于快速模型的模型调试器11.20版用户指南
用于快速模型的模型调试器11.21版用户指南
ai大模型和小模型的区别
适用于快速模型的模型调试器用户指南
ARM®设计仿真模型(DSM)用户指南
YOLOv6模型文件的输入与输出结构






 工商网监
工商网监
评论