 YOLOv6模型文件的输入与输出结构
YOLOv6模型文件的输入与输出结构

YOLOv6人脸检测模型
YOLOv6上次(应该是很久以前)发布了一个0.3.1版本,支持人脸检测与五点landmark调用,后来我就下载,想使用一下,发现居然没有文档,也没有例子。但是官方有个infer.py文件是可以调用的,说明这个模型文件应该没问题。下载打开模型文件的输入与输出结构如下:
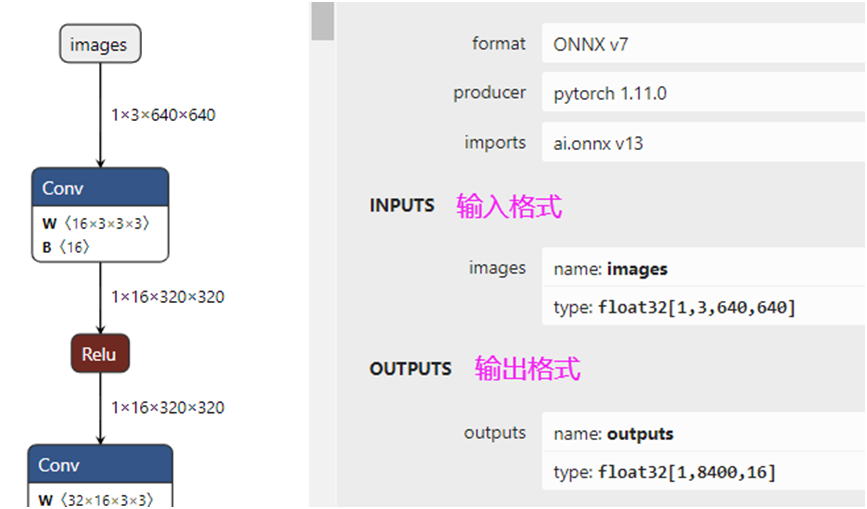
输出格式8400x16,其中16的输出表示为人脸框+landmark坐标信息。xyxy, conf, cls, lmdks,前面四个是Box信息、后面是置信度与分类得分、最后是10个值五点XY坐标
输出解析顺序
官方代码与参考文档给出的解析顺序,xyxy, conf, cls, lmdks,这部分还有官方的参考文件:
https://github.com/meituan/YOLOv6/blob/yolov6-face/yolov6/core/inferer.py

第110行就是这样说明的,于是我按上述格式一通解析,结果让我崩溃了,输入图像与解析结果如下:
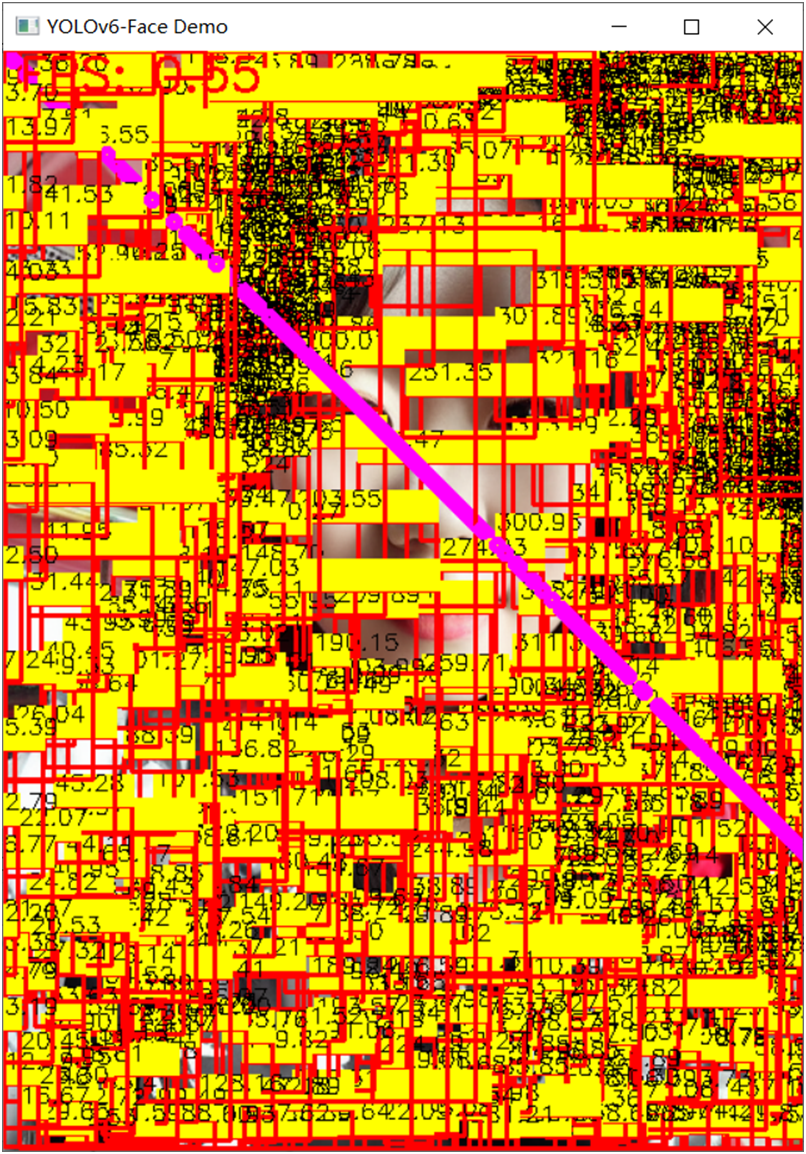
这个时候我才明白为什么这个发布了这么久,网上居然一篇文章关于YOLOv6人脸检测的文章都没有,网上的文章很多都是YOLOv5跟YOLOv7的人脸+Landmark检测,原因一切都是有原因的。 我debug一下,发现预测出来的16个值,只有最后两个值的结果是小于或者等于1的,所以我当时猜想16个顺序应该是:xyxy, lmdks, conf, cls,按照我猜测的顺序我又改下代码,然后直接运行测试,奇迹出现了:
这张图是AI生成的,如有雷同纯属巧合! 整个推理的流程跟YOLOv5、YOLOv6对象检测一样,就是后处理不同,所以附上后处理部分的代码:
defwrap_detection(self,input_image,out_data): confidences=[] boxes=[] kypts=[] rows=out_data.shape[0] image_width,image_height,_=input_image.shape x_factor=image_width/640.0 y_factor=image_height/640.0 sd=np.zeros((5,2),dtype=np.float32) sd[0:5]=(x_factor,y_factor) sd=np.squeeze(sd.reshape((-1,1)),1) #xyxy,lmdks,conf,cls, forrinrange(rows): row=out_data[r] conf=row[14] cls=row[15] if(conf>0.25andcls>0.25): confidences.append(conf) x,y,w,h=row[0].item(),row[1].item(),row[2].item(),row[3].item() left=int((x-0.5*w)*x_factor) top=int((y-0.5*h)*y_factor) width=int(w*x_factor) height=int(h*y_factor) box=np.array([left,top,width,height]) boxes.append(box) kypts.append(np.multiply(row[4:14],sd)) indexes=cv.dnn.NMSBoxes(boxes,confidences,0.25,0.25) result_confidences=[] result_boxes=[] result_kypts=[] foriinindexes: result_confidences.append(confidences[i]) result_boxes.append(boxes[i]) result_kypts.append(kypts[i]) returnresult_kypts,result_confidences,result_boxes
责任编辑:彭菁
-
模型
+关注
关注
1文章
3648浏览量
51711 -
代码
+关注
关注
30文章
4941浏览量
73145 -
人脸检测
+关注
关注
0文章
88浏览量
17171
原文标题:YOLOv6 人脸Landmark检测
文章出处:【微信号:CVSCHOOL,微信公众号:OpenCV学堂】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Yolov5算法解读

怎样使用PyTorch Hub去加载YOLOv5模型
YOLOv6中的用Channel-wise Distillation进行的量化感知训练
YOLOv5网络结构解析
yolov7 onnx模型在NPU上太慢了怎么解决?
YOLOv3的darknet模型先转为caffe模型后再转为fp32bmodel,模型输出和原始模型输出存在偏差是怎么回事?
一个YOLO系列的算法实现库YOLOU
关于YOLOU中模型的测试
YOLOv6在LabVIEW中的推理部署(含源码)

一文彻底搞懂YOLOv8【网络结构+代码+实操】
YOLOv8+OpenCV实现DM码定位检测与解析

深度学习YOLOv3 模型设计的基本思想


基于瑞芯微RK3576的 yolov5训练部署教程






 工商网监
工商网监
评论