 如何在推理引擎中脱颖而出
如何在推理引擎中脱颖而出

随着人工智能的爆炸式增长,人们越来越关注能够提供人工智能所需性能的新型专业推理引擎。因此,在过去六个月中,我们看到了一系列神经推理硬件公告,所有这些都承诺提供比市场上任何其他产品更好的加速。然而,挑战在于没有人真正知道如何衡量一个与另一个。这是一项新技术,就像任何新技术一样,我们需要指标,我们需要真正重要的指标。
一切都与吞吐量有关
当推理引擎的性能出现时,供应商会抛出诸如 TOPS(Tera-Operations/Second)性能和 TOPS/Watt 之类的基准。研究这些的系统/芯片设计人员很快意识到这些数字通常毫无意义。真正重要的是推理引擎可以为模型、图像大小、批量大小和过程以及 PVT(过程/电压/温度)条件提供多少吞吐量。这是衡量其性能表现的第一个衡量标准,但令人惊讶的是,很少有供应商提供它。
TOPS 的最大问题是,当一家公司说他们的引擎执行 X TOPS 时,他们通常会引用这一点而没有说明条件是什么。在不知道这些信息的情况下,他们错误地认为 X TOPS 意味着它可以执行 X 万亿次操作。实际上,报价 130 TOPS 的公司可能仅提供 27 TOPS 的可用吞吐量。
另一个正在使用但不太常用的基准是 ResNet-50。这个基准的问题是大多数引用它的公司都没有给出批量大小。如果他们不这样做,芯片设计人员可以假设这将是一个大批量,以最大限度地提高他们的硬件利用率。这使得 ResNet-50 作为基准不是很有帮助。相比之下,例如 YOLOv3 需要 100 倍以上的操作来处理 2 兆像素的图像。在“真实世界”模型中,硬件利用率将面临更大挑战。
如何正确测量神经推理引擎
在评估神经推理引擎时,需要注意几个关键事项。以下是最重要的考虑因素以及它们为何真正重要的原因。
定义什么是操作:一些供应商将乘法(通常为 INT 8 乘以 INT 8)计为一次操作,将累加(加法,通常为 INT 32)计为一次操作。因此,一次乘法累加等于 2 次操作。但是,一些供应商在其 TOPS 规范中包含其他类型的操作,因此必须在开始时进行澄清。
询问 操作条件是什么: 如果供应商提供 TOPS 而不提供条件,他们通常使用室温、标称电压和典型工艺。通常他们会提到他们所指的工艺节点,但不同供应商的运行速度不同,大多数工艺提供2、3或更多的标称电压。由于性能是频率的函数,而频率是电压的函数,因此芯片设计人员在 0.9V 时可以获得比在 0.6V 时高两倍以上的性能。频率因条件/假设而异。有关这方面的更多信息,请参阅此应用说明。
看看批量大小:即使供应商提供最坏情况的 TOPS,芯片设计人员也需要弄清楚所有这些操作是否真的有助于计算他们的神经网络模型。实际上,实际利用率可能非常低,因为没有推理引擎始终 100% 地使用所有 MAC。这就是批量大小很重要的原因。批处理是为给定层加载权重并同时处理多个数据集。这样做的原因是为了提高吞吐量,但放弃的是更长的延迟。ResNet-50 拥有超过 2000 万个权重;YOLOv3 拥有超过 6000 万个权重;并且必须为每个图像获取每个权重并将其加载到 MAC 结构中。权重太多,无法让它们都驻留在 MAC 结构中。
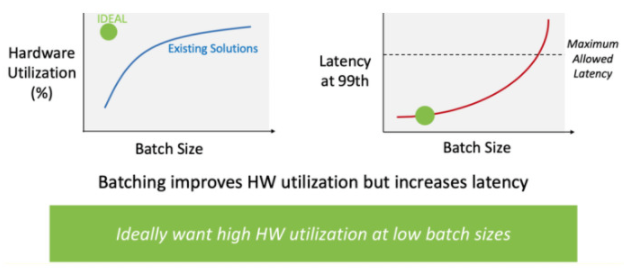
找出你的 MAC 利用率:并非所有神经网络的行为都相同。您需要以您需要的批量大小找出您想要部署的神经网络模型的神经推理引擎的实际 MAC 利用率。
深入TOPS
如果您是一名正在研究神经推理引擎的设计师,希望这篇文章能够阐明要寻找的内容。请记住——重要的是吞吐量。重要的是不要陷入诸如 TOPS 和 ResNet-50 之类的毫无意义的基准测试中,除非您知道围绕这些问题要问的问题。首先提出以下问题:在批量大小 = A 和 XYZ PVT 条件下,可以为特定模型(例如 YOLOv3)处理多少图像/秒。一旦您开始指定条件和假设,您将开始了解任何神经推理在现实世界中的表现如何。归根结底,这才是最重要的。
审核编辑:郭婷
-
芯片
+关注
关注
463文章
54484浏览量
469840 -
神经网络
+关注
关注
42文章
4844浏览量
108218 -
人工智能
+关注
关注
1821文章
50385浏览量
267120
发布评论请先 登录
思必驰斩获Interspeech 2026音频推理挑战赛智能体赛道亚军
最新光缆检测系统厂家排名:广州邮科凭什么脱颖而出?

温补晶振(TCXO)脱颖而出的核心优势

淘宝API揭秘:如何让你的店铺在海量商品中脱颖而出?

如何在NVIDIA Jetson AGX Thor上通过Docker高效部署vLLM推理服务

机械ERP:制造业智能升级核心引擎,如何选、用、赢?全面解析
利用NVIDIA DOCA GPUNetIO技术提升MoE模型推理性能
智能电子指路牌公司排名 TOP1:如何在叁仟智慧城市细分市场中脱颖而出
40个项目脱颖而出!2025英特尔人工智能大赛圆满收官,下一个AI应用浪潮开启

固态铝电解电容:如何凭借高纹波电流承载能力脱颖而出
请问如何在RK3588上使用npu,用onnx模型来推理
积算科技上线赤兔推理引擎服务,创新解锁FP8大模型算力
信而泰×DeepSeek:AI推理引擎驱动网络智能诊断迈向 “自愈”时代
BNC插座的独特优势,让它在众多线缆中脱颖而出

BNC连接线的独特优势,让它在众多线缆中脱颖而出



评论