 如何在OpenVINO 开发套件中“无缝”部署PaddlePaddle BERT模型
如何在OpenVINO 开发套件中“无缝”部署PaddlePaddle BERT模型

任务背景
01
情感分析
(Sentiment Analysis)
情感分析旨在对带有情感色彩的主观性文本进行分析、处理、归纳和推理,其广泛应用于消费决策、舆情分析、个性化推荐等领域,具有很高的商业价值。例如:食行生鲜自动生成菜品评论标签辅助用户购买,并指导运营采购部门调整选品和促销策略;房天下向购房者和开发商直观展示楼盘的用户口碑情况,并对好评楼盘置顶推荐;国美搭建服务智能化评分系统,客服运营成本减少40%,负面反馈处理率100%。
02
自然语言处理(NLP)技术
自然语言处理(英语:Natural Language Process,简称NLP)是计算机科学、信息工程以及人工智能的子领域,专注于人机语言交互,探讨如何处理和运用自然语言。最近几年,随着深度学习以及相关技术的发展,NLP领域的研究取得一个又一个突破,研究者设计各种模型和方法,来解决NLP的各类问题,其中比较常见包括LSTM, BERT, GRU, Transformer, GPT等算法模型。
方案简介
本方案采用PaddleNLP工具套件进行模型训练,并基于OpenVINO 开发套件实现在Intel平台上的高效能部署。本文将主要分享如何在OpenVINO 开发套件中“无缝”部署PaddlePaddle BERT模型,并对输出结果做验证。
01
PaddleNLP
PaddleNLP是一款简单易用且功能强大的自然语言处理开发库。聚合业界优质预训练模型并提供开箱即用的开发体验,覆盖NLP多场景的模型库搭配产业实践范例可满足开发者灵活定制的需求。
02
OpenVINO 开发套件
OpenVINO 开发套件是Intel平台原生的深度学习推理框架,自2018年推出以来,Intel已经帮助数十万开发者大幅提升了AI推理性能,并将其应用从边缘计算扩展到企业和客户端。英特尔于2022年巴塞罗那世界移动通信大会前夕,推出了英特尔 发行版OpenVINO 开发套件的全新版本。其中的新功能主要根据开发者过去三年半的反馈而开发,包括更多的深度学习模型选择、更多的设备可移植性选择以及更高的推理性能和更少的代码更改。为了更好地对Paddle模型进行支持,新版OpenVINO 开发套件分别做了一下升级:
■直接支持Paddle格式模型
目前OpenVINO 开发套件2022.1发行版中已完成对PaddlePaddle模型的直接支持,OpenVINO 开发套件的Model Optimizer工具已经可以直接完成对Paddle模型的离线转化,同时runtime api接口也可以直接读取加载Paddle模型到指定的硬件设备,省去了离线转换的过程,大大提升了Paddle开发者在Intel平台上部署的效率。经过性能和准确性验证,在OpenVINO 开发套件2022.1发行版中,会有13个模型涵盖5大应用场景的Paddle模型将被直接支持,其中不乏像PPYolo和PPOCR这样非常受开发者欢迎的网络。
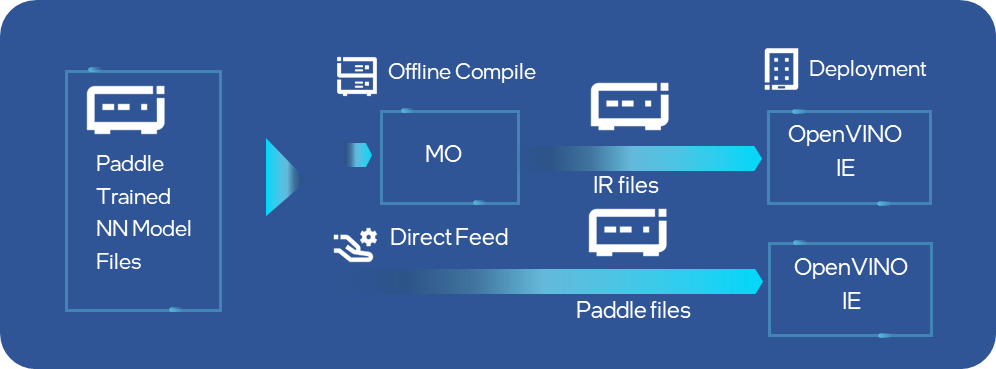
图:OpenVINO 开发套件的MO和IE可以直接支持Paddle模型输入
■ 全面引入动态输入支持
为了适配更广泛的模型种类,OpenVINO 2022.1版本的CPU Plugin已经支持了动态input shape,让开发者以更便捷的方式部署类似NLP或者OCR这样的网络,OpenVINO 开发套件用户可以在不需要对模型做reshape的前提下,任意送入不同shape的图片或者向量作为输入数据,OpenVINO 开发套件会自动在runtime过程中对模型结构与内存空间进行动态调整,进一步优化dynamic shape的推理性能。
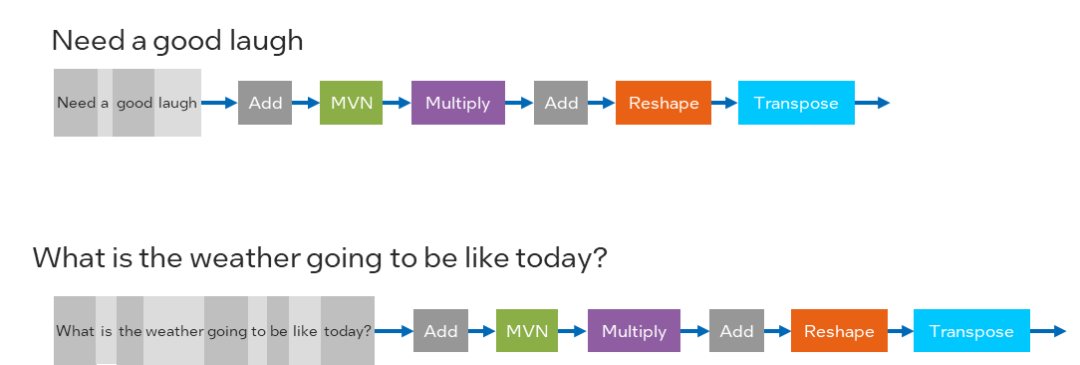
图:在NLP中的Dynamic Input Shape
详细介绍可以参考:https://docs.openvino.ai/latest/openvino_docs_OV_UG_DynamicShapes.html
BERT原理简介
01
BERT结构介绍
BERT (Bidirectional Encoder Representations from Transformers)以Transformer 编码器为网络基本组件,使用掩码语言模型(Masked Language Model)和邻接句子预测(Next Sentence Prediction)两个任务在大规模无标注文本语料上进行预训练(pre-train),得到融合了双向内容的通用语义表示模型。以预训练产生的通用语义表示模型为基础,结合任务适配的简单输出层,微调(fine-tune)后即可应用到下游的NLP任务,效果通常也较直接在下游的任务上训练的模型更优。此前BERT即在GLUE评测任务上取得了SOTA的结果。
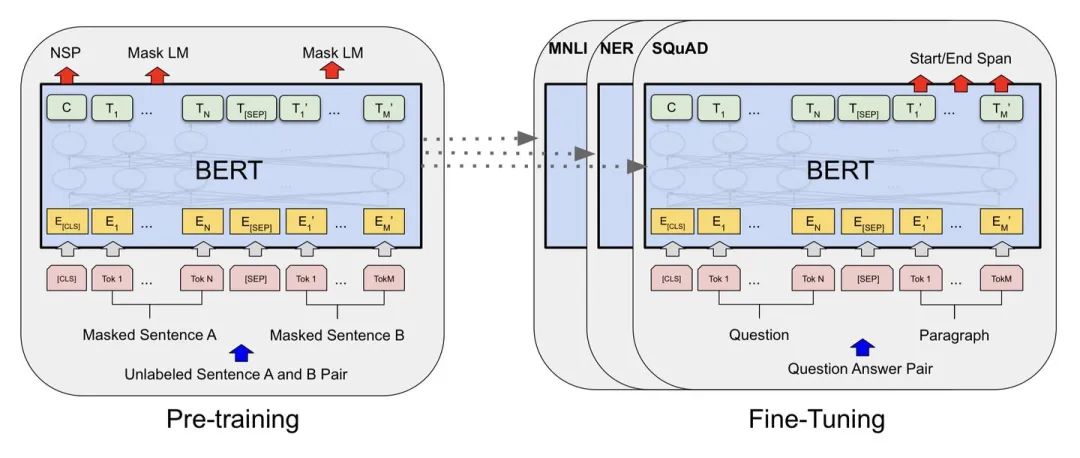
图:BERT的2阶段训练任务
不难发现,其模型结构是Transformer的Encoder层,只需要将特定任务的输入,输出插入到Bert中,利用Transformer强大的注意力机制就可以模拟很多下游任务。(句子对关系判断,单文本主题分类,问答任务(QA),单句贴标签(命名实体识别)),BERT的训练过程可以分成预训练和微调两部分组成。
02
预训练任务(Pre-training)
BERT是一个多任务模型,它的任务是由两个自监督任务组成,即MLM和NSP。
■Task #1:Masked Language Model
所谓MLM是指在训练的时候随即从输入预料上mask掉一些单词,然后通过的上下文预测该单词,该任务非常像我们在中学时期经常做的完形填空。正如传统的语言模型算法和RNN匹配那样,MLM的这个性质和Transformer的结构是非常匹配的。
■Task #2: Next Sentence Prediction
Next Sentence Prediction(NSP)的任务是判断句子B是否是句子A的下文。如果是的话输出’IsNext‘,否则输出’NotNext‘。训练数据的生成方式是从平行语料中随机抽取的连续两句话,其中50%保留抽取的两句话,它们符合IsNext关系,另外50%的第二句话是随机从预料中提取的,它们的关系是NotNext的。
微调任务 (Fine-tuning)
在海量单预料上训练完BERT之后,便可以将其应用到NLP的各个任务中了。以下展示了BERT在11个不同任务中的模型,它们只需要在BERT的基础上再添加一个输出层便可以完成对特定任务的微调。这些任务类似于我们做过的文科试卷,其中有选择题,简答题等等。微调的任务包括:
■基于句子对的分类任务
■基于单个句子的分类任务
■问答任务
■命名实体识别
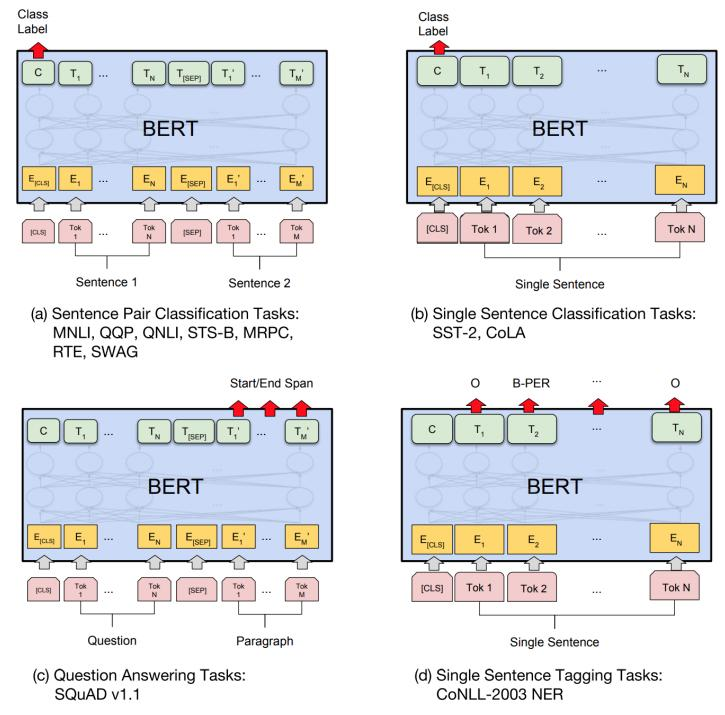
图:BERT的4大下游微调任务
训练与部署流程
本示例包含PaddleNLP训练和OpenVINO 开发套件部署两部分组成。
01
环境安装
打开命令行终端,分别输入以下命令,完成本地环境安装和配置。
1.1安装PaddlePaddle (AI studio环境中可以略过)
如果是CPU训练环境需要执行以下命令进行安装:
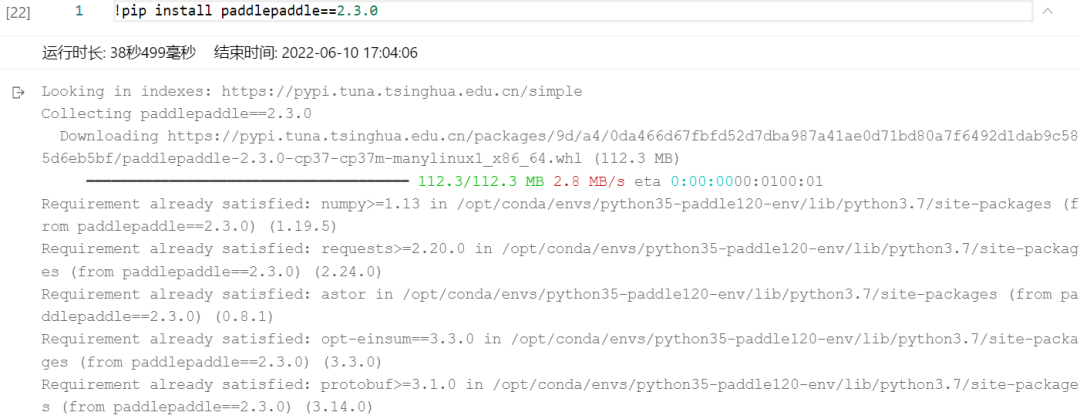
如果是GPU训练环境需要执行以下命令进行安装:
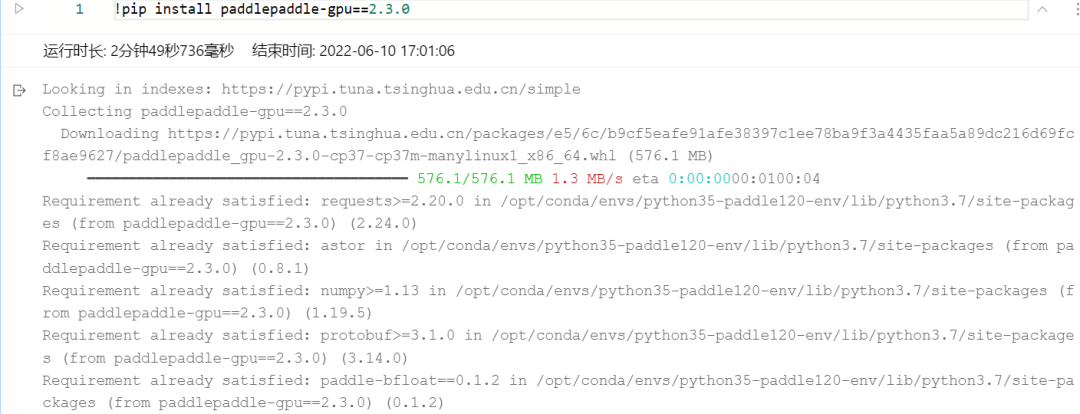
1.2安装PaddleNLP与相关依赖
下载PaddleNLP:
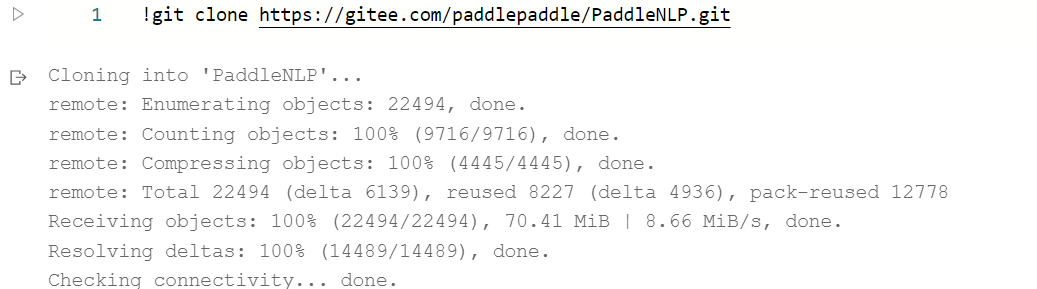
安装PaddleNLP相关依赖:
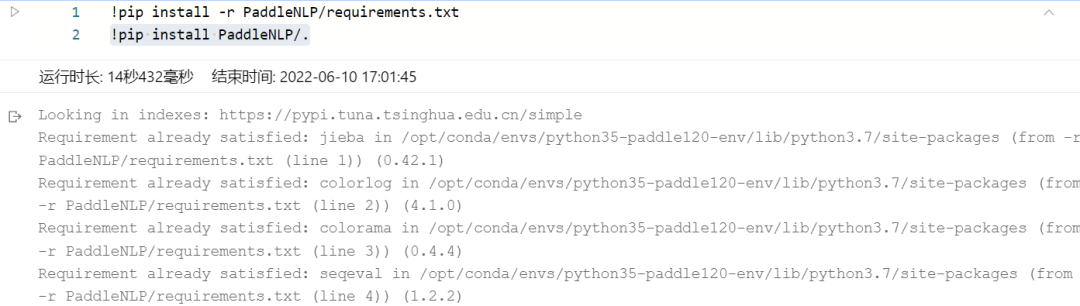
1.3安装OpenVINO 开发套件
02
训练部分
训练部分是BERT在 Paddle 2.0上的开源实现,可以分为数据准备,BERT Encoder预训练,SST2情感分类任务微调以及推理模型导出这四个步骤。
可以参考Paddle官方的案例说明,对以下过程做了简要汇总,地址:
https://github.com/PaddlePaddle/PaddleNLP/tree/develop/model_zoo/bert

图:Paddle BERT模型训练流程
除此之外,我们也可以借助Paddle AI studio直接运行训练脚本(无脑点击运行就可以了: )),链接如下:
https://aistudio.baidu.com/aistudio/projectdetail/4193790?contributionType=1
2.1步骤一:数据准备(可略过)
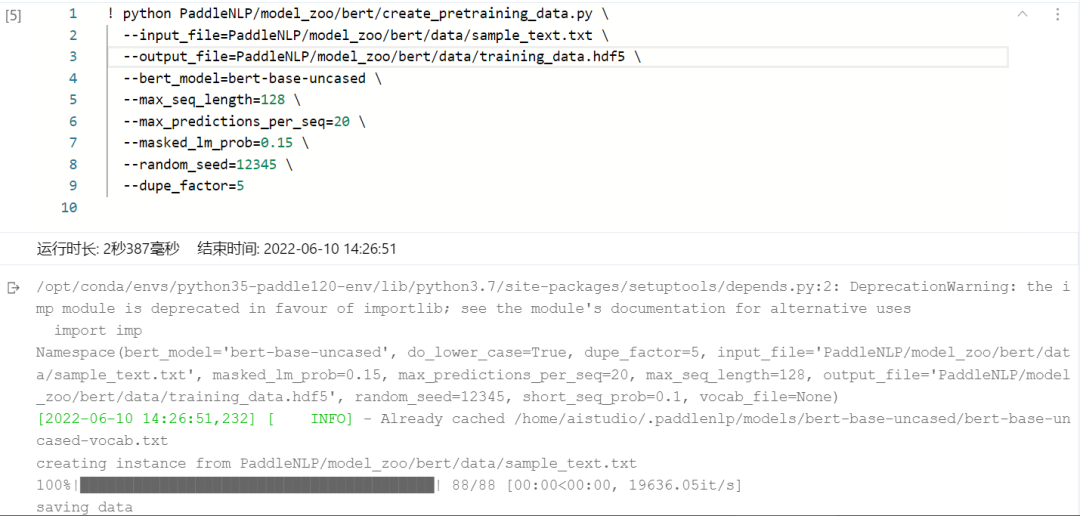
PaddleNLP中BERT任务下自带的create_pretraining_data.py 是创建预训练程序所需数据的脚本。其以文本文件(使用换行符换行和空白符分隔,data目录下提供了部分示例数据)为输入,经由BERT tokenizer进行tokenize后再做生成sentence pair正负样本、掩码token等处理,最后输出hdf5格式的数据文件。使用方式如下,在命令行输入:
2.2步骤二:GPU训练(可略过)
使用paddle.distributed.launch配置项运行run_pretrain.py训练脚本,可以在多卡GPU环境下启动BERT预训练任务。命令行指令如下:
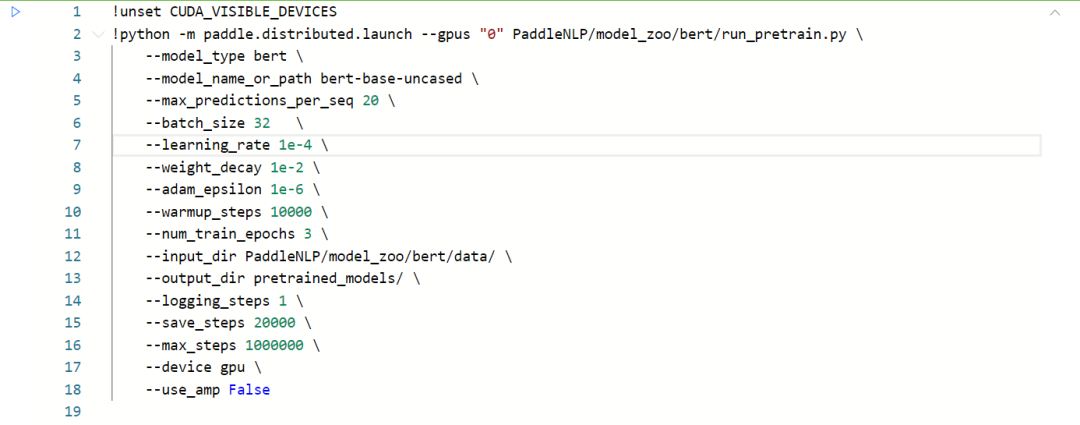
■model_type指示了模型类型,使用BERT模型时设置为bert即可。
■model_name_or_path指示了某种特定配置的模型,对应有其预训练模型和预训练时使用的 tokenizer。若模型相关内容保存在本地,这里也可以提供相应目录地址。
■input_dir表示输入数据的目录,该目录下所有文件名中包含training的文件将被作为训练数据。output_dir 表示模型的保存目录。

2.3步骤三:模型Fine-tunning
如果自己没有准备训练数据集的话,也可以跳过前面的步骤,直接使用huggingface提供的预训练模型进行Fine-tuning,以GLUE中的SST-2任务为例,该脚本会自动下载SST-2任务中所需要的英文数据集,启动Fine-tuning的方式如下:
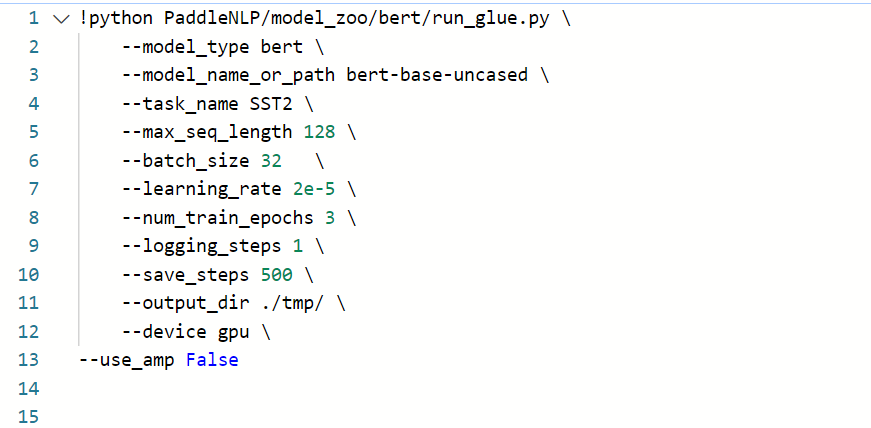
■model_name_or_path指示了某种特定配置的模型,对应有其预训练模型和预训练时使用的 tokenizer。若模型相关内容保存在本地,这里也可以提供相应目录地址。注:bert-base-uncased等对应使用的预训练模型转自huggingface/transformers
可以看到启动Fine-tuning任务以后,脚本会自动下载bert-base-uncased预训练模型,以及用于Fine-tuning的bert-base-uncased-vocab.txt数据集。
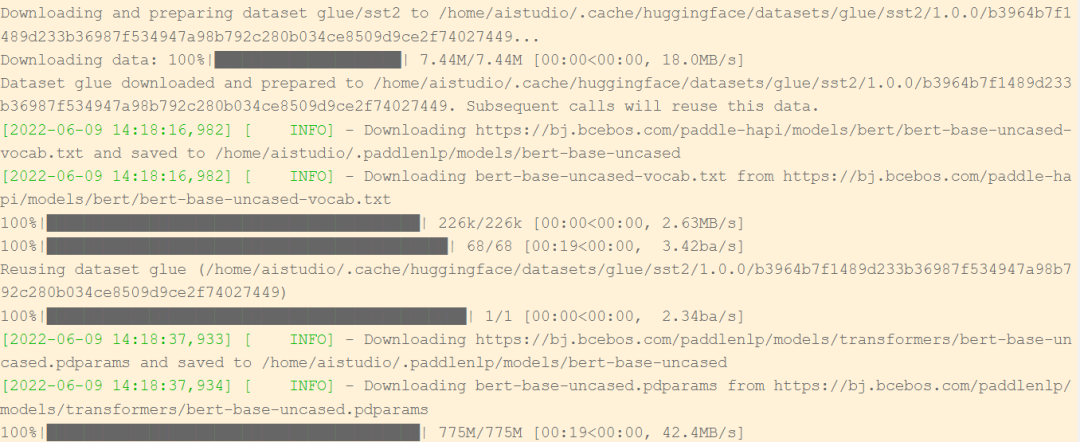
当训练任务到达预先设定的step轮数以后,便会停止训练,并且将.pdparam格式的模型权重保存在tmp目录下。
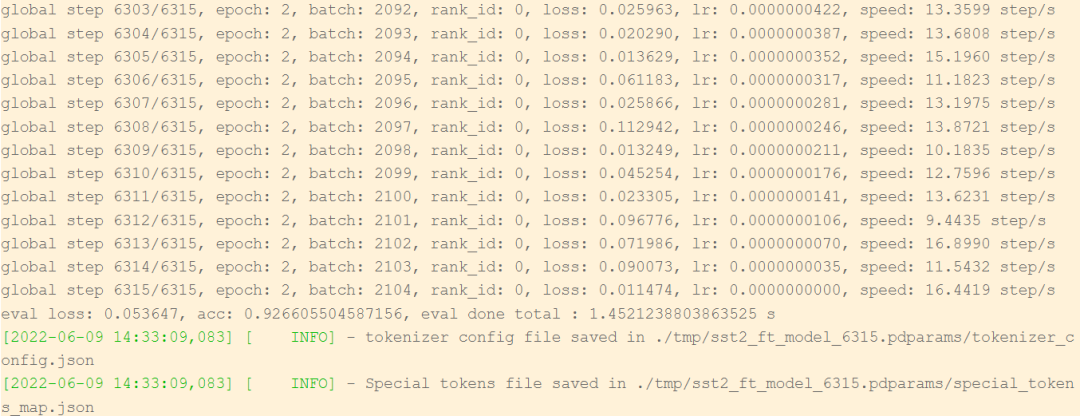
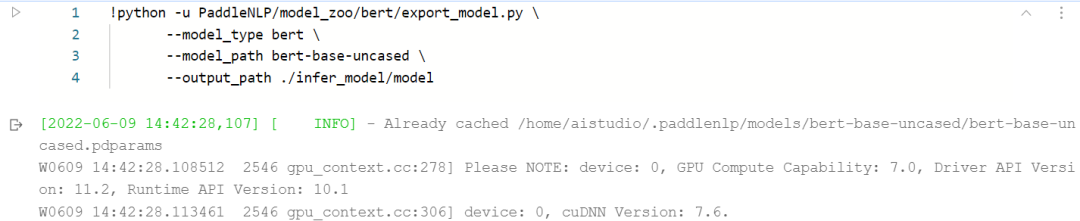
2.4步骤四:模型导出
在Fine-tuning完成后,我们可以使用如下方式导出希望用来预测的Paddle静态模型,并保存在infer_model路径下:
导出后的模型文件包含以下内容时,推理时需要保证这三个文件在同一个目录下:
model.pdmodel, model.pdiparams.info, model.pdiparams
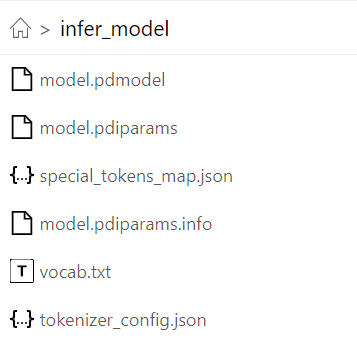
图:导出后的Paddle BERT静态模型文件
03
部署部分
该示例将基于OpenVINO 开发套件进行Paddle的静态模型部署,需要开发者提前准备好用于做部署的Intel平台硬件,可以是个人电脑,也可以是云服务器虚机。整体流程可以分为以下几个步骤:

图:BERT模型部署流程
对于情感分析任务,BERT网络的识别流程可以分成以下几个步骤:
■ 输入语句文本,并转为相应的Token ID
■ 为每一行Token ID添加Padding,使其保持长度一致
■ Token ID作为输入数据送入BERT模型进行推理 (模型内流程逻辑参考下图),通过Embedding Layer将一个词映射成为固定维度的稠密向量,降维后的向量会再通过Encoder提取Self-attentions后的向量间的关系特征,最后经过Classifier对情感分类任务做出判断。
■ 获取模型结果数据,通过后处理函数,计算分类标签与每一类标签的置信度
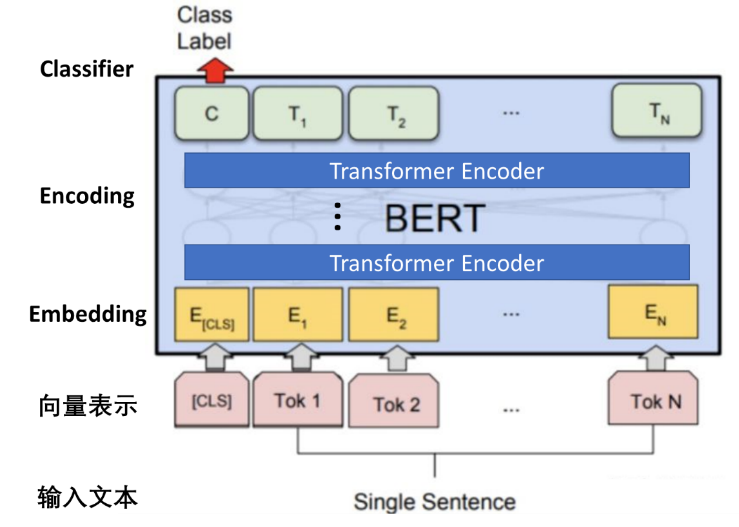
图:BERT for SST2模型内部逻辑
BERT for SST2的输入的编码向量(长度不固定)是2个嵌入特征的单位和,这2个词嵌入特征是:
■ input_ids:输入文本被转化为token后的单个字的id;
■ segment_ids:就是句子级别(上下句)的标签,用于区分两个句子,例如B是否是A的下文(对话场景,问答场景等)。由于在情感分析任务中没有下句,所以这里segment_ids为全部为0的向量。
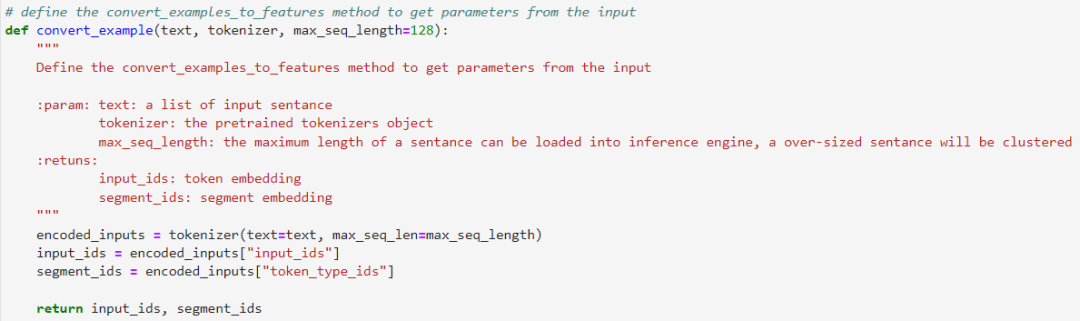
3.1步骤一:文本Token表示
定义数据转换模块,将原始的输入语句转化为input_ids与segment_ids,作为输入数据。这边我们将会使用PaddleNLP自带的tokenizer()方法进行转换。
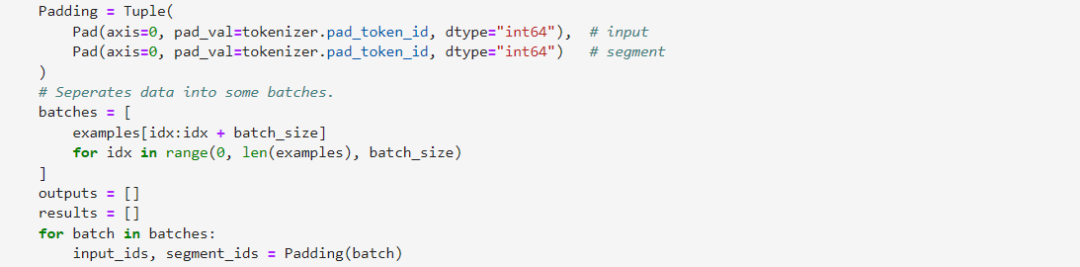
3.2步骤二:Padding
需要保证input_ids与segment_ids数组在axis0方向的长度一致,由于这边input_ids与segment_ids均为一维数组,所以也可以不进行该操作。
3.3步骤三:模型推理
部署代码里最核心的部分就是要定义基于OpenVINO 开发套件的预测器,这里使用CPU作为模型的部署平台,可以看到通过read_model这个函数接口我们可以直接读取原始的.pdmodel格式模型,省去了之前繁杂的离线转化过程。此外我们需要通过compile_model这个函数讲读取后的模型在指定的硬件平台进行加载和编译。最后创建infer_request推理请求进行推理任务部署。

由于输入语句的长度往往不一致,这也导致编码后的向量长度也不一致,这里OpenVINO 开发套件CPU Plugin的支持上已经全面引入了Dynamic Shape功能,无需再手动调整输入数据的长度,OpenVINO 开发套件会在runtime过程中自动匹配并动态申请一定的内存空间进行推理,优化性能表现。

由于新版OpenVINO 开发套件已经全面支持Intel 12代酷睿处理器,为了取得更佳的推理性能,我们建议使用最新的硬件平台进行测试。
3.4步骤四:结果后处理
此处得到的结果数据为两种不同评价的可能性,我们需要将其通过softmax函数还原成百分比形式,并且找到可能性最大的那个评价序号所对应的标签(Positive,Negative)。

最后我们找一组测试语句作为输入数据,将其封装成List以后,送入到识别器中进行识别,可以发现结果都是符合我们的先验预期的。
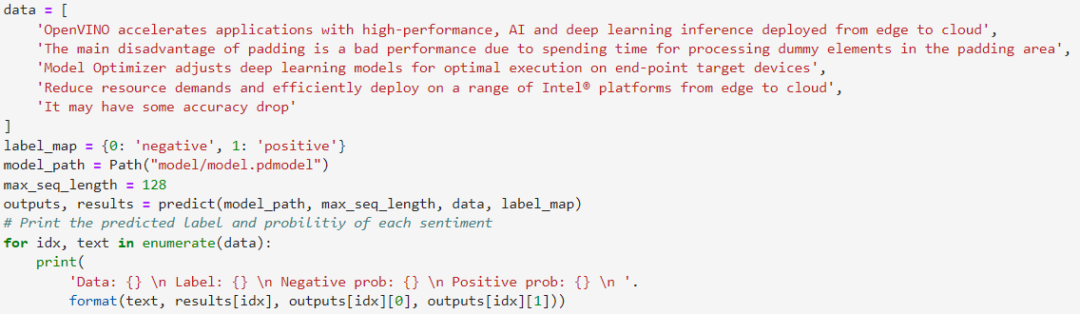
该示例程序可以可以准确按SST2情感二分类任务要求,输出每段输入语句的分类情感标签,并获得每种情感对应的参考置信度。

小结
作为发布至今近4年以来最大的一次更新,OpenVINO 2022.1版本为了更好地支持NLP与语音相关的模型,在CPU plugin中已全面支持了动态input shape,并通过与百度PaddlePaddle框架的深度集成,用更便捷的API接口,更丰富的模型支持,提升双方开发者在模型部署侧的使用体验,真正实现对PaddleNLP模型的“无缝”转化与部署。
通过本次的全流程示例,我们看到OpenVINO 开发套件对Paddle BERT模型已经做到了很好的适配,从而加速在Intel平台上的推理。以下github repository中已为大家提前准备好了OpenVINO 开发套件部署的参考实现与.pdmodel格式的BERT预训练模型。
https://github.com/OpenVINO-dev-contest/openvino_notebooks/tree/PaddleBert/notebooks/005-hello-paddle-nlp
除此之外,为了方便大家了解并快速掌握OpenVINO 开发套件的使用,我们还提供了一系列开源的Jupyter notebook demo。运行这些notebook,就能快速了解在不同场景下如何利用OpenVINO 开发套件实现一系列、包括OCR在内的、计算机视觉及自然语言处理任务。OpenVINO notebooks的资源可以在Github这里下载安装:
https://github.com/openvinotoolkit/openvino_notebooks
审核编辑 :李倩
-
自然语言处理
+关注
关注
1文章
629浏览量
14563 -
nlp
+关注
关注
1文章
491浏览量
23192
原文标题:基于OpenVINO™ “无缝”部署 PaddleNLP 模型 | 开发者实战
文章出处:【微信号:英特尔物联网,微信公众号:英特尔物联网】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
在V2板子上部署豆包模型调试指南
SC171开发套件V3 技术资料
AI端侧部署案例(SC171开发套件V3)
AI端侧部署开发(SC171开发套件V3)
如何在Ollama中使用OpenVINO后端
首创开源架构,天玑AI开发套件让端侧AI模型接入得心应手
如何部署OpenVINO™工具套件应用程序?
使用工具套件2020.2从ncappzoo运行模型和演示OpenVINO™报错怎么解决?
OpenVINO™工具套件插件对YOLOv5s模型和scatterUpate层的支持范围是什么?
如何修复IR版本与OpenVINO™工具套件版本不匹配问题?
C#集成OpenVINO™:简化AI模型部署

C#中使用OpenVINO™:轻松集成AI模型!





 工商网监
工商网监
评论