 使用NVIDIA Clara Parabricks 3.8加速基因组分析
使用NVIDIA Clara Parabricks 3.8加速基因组分析

生物信息学家一直在寻找新的工具来简化和增强基因组分析管道。 NVIDIA Clara Parabricks 拥有 60 多种工具,能够在研究和临床环境中为种系和体细胞工作流程提供准确、快速的基因组分析。
NVIDIA Clara Parabricks 3.8 ,特点:
快速变体注释工具。
肿瘤只需要临床癌症工作流程。
安培的额外支持 GPU 。
序列数据的快速增长要求更快的变体调用格式( VCF )读写速度。 Clara Parabricks 3.8 扩展了快速变量注释、变量后调用、使用 snpswift 支持自定义数据库注释以及使用 bcftools 调用变量结果。在 Clara Parabricks 上, snpswift 提供了快速准确的 VCF 数据库注释,并利用了广泛的数据库。
测序技术的进步扩大了基因组学在临床肿瘤学中的作用。 NVIDIA Clara Parabricks 现在为临床癌症工作流程提供了仅限肿瘤的体细胞呼叫者 LoFreq 和 Mutect2 呼叫。肿瘤正常呼叫可通过 LoFreq 、 Mutect2 、 Strelka2 、 SomaticSniper 、 Muse 在 Parabricks 上进行。
基因组科学家可以通过使用更广泛的 GPU 体系结构运行 Clara Parabricks ,进一步加快基因组分析工作流程,包括 A6000 、 A100 、 A10 、 A30 、 A40 、 V100 和 T4 。这也支持客户使用由特定 NVIDIA GPU 驱动的下一代测序仪器进行基址调用,这些客户希望使用相同的 GPU 对 Clara Pararicks 进行二次分析。
扩展的快速变体注释
在 1 月份发布的 Clara Parabricks 3.7 ,添加了一个新的变体注释工具,有助于为下游基因组分析提供变体的功能信息。这一点很重要,因为正确的变体注释有助于基因组研究和临床诊断的最终结论。
Pararicks 的变体注释工具 snpswift 提供了快速而准确的 VCF 数据库注释,与其他社区变体注释解决方案(如 vcfanno )相比,它可以在更短的运行时内提供结果。 Snpswift 带来了更多的功能和加速,同时保留了 VCF 文件的精确等位基因数据库注释的基本功能。新的 snpswift 工具还支持用 ENSEMBL 中的基因名称数据注释 VCF 文件,有助于理解编码变体。
支持的数据库包括 dbSNP 、 gnomAD 、 COSMIC 、 ClinVar 和 1000 个基因组。 Snpswift 可以对这些变量进行联合注释,为筛选 VCF 变量和解释其重要性提供重要信息。此外, snpswift 能够使用来自 ENSEMBL GTF 的信息注释 VCF ,以添加详细信息并利用该领域中其他广泛使用的数据库。
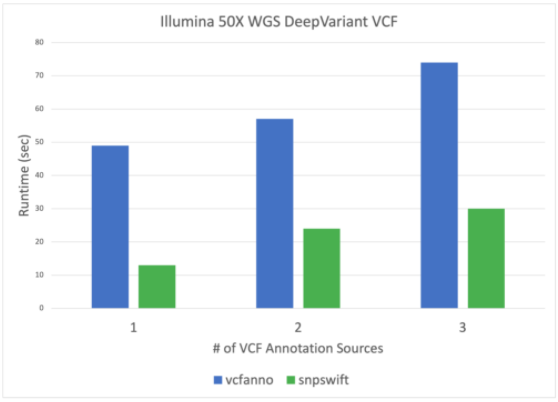
图 1 Clara Pararicks 的变体注释工具 snpswift 比其他社区变体注释工具(如 vcfanno )提供更快、更准确的 VCF 数据库注释
除了这些广泛使用的数据库外,许多研究机构和公司都有自己丰富的内部数据集,这些数据集可以为每个变体提供有价值的特定领域信息。
Clara Parabricks 3.8 中的 Snpswift 现在使用多个自定义 TSV 数据库对 VCF 进行注释。 Snpswift 还能够在 30 秒内用包含 500K 变体的自定义 TSV 注释 600 万变体 HG002 VCF 。用户可以使用 VCF 、 GTF 和 TSV 数据库联合注释 VCF ,所有这些都只需一个命令,只需一次运行。
最后, Clara Parabricks 3.8 包含了后果预测。预测变异的功能结果是对遗传变异进行分类和排序注释的关键步骤。 Parabricks 3.8 提供了一个 bcftoolscsq 命令,该命令封装了众所周知且速度极快的 bcftools csq 工具 ,提供了单体型感知的结果预测。这导致 VCF 文件中的变体分阶段,以避免变体影响相同密码子时出现常见错误。
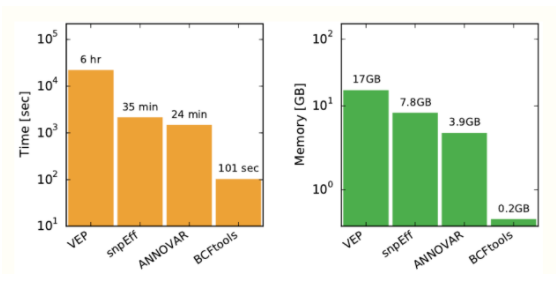
图 2 这张图片拍摄于 调用 GitHub 链接的结果。 BCFtools / csq 与三个常用结果调用程序的性能比较,使用一个带有 450 万个站点的 VCF 示例
与基于CPU的环境相比,最先进的生物信息学工具的速度提高了60倍。全基因组工作流程的端到端分析只需22分钟,外显子组工作流程只需4分钟。大规模测序项目和其他全基因组研究能够在一台DGX服务器上每天分析60多个基因组,同时降低相关成本,产生比以往任何时候都有用的见解。
关于作者
Vanessa Braunstein 在 NVIDIA 的医疗团队从事产品营销工作。此前,她在基因组学、医学成像、制药、化学和诊断公司从事产品开发和营销。她学习分子和细胞生物学、公共卫生和商业。
Camir Ricketts是 NVIDIA ( NVIDIA )的一位生物信息学科学家,他正在开发新方法,以加速基因组分析并利用人工智能进行医疗保健。他在康奈尔大学威尔·康奈尔医学院完成博士学位,专注于结构变异表征和肿瘤系统发育推断的方法开发。
审核编辑:郭婷
-
cpu
+关注
关注
68文章
11331浏览量
225904 -
NVIDIA
+关注
关注
14文章
5694浏览量
110119 -
服务器
+关注
关注
14文章
10364浏览量
91761
发布评论请先 登录
Oracle和NVIDIA合作加速向量搜索和企业数据处理
NVIDIA携手微软加速机器人和物理AI的发展
NVIDIA携手全球工业软件巨头构建AI智能体加速设计与工程开发流程
NVIDIA加速计算平台助力从地球到太空的AI应用
利用NVIDIA Cosmos开放世界基础模型加速物理AI开发
第十二届全国功能基因组学高峰论坛在京举办:聚焦人工智能与多组学融合发展

序祯达生物利用NVIDIA Parabricks技术加速多组学分析
0.4 至 3.8 GHz SPDT 开关 skyworksinc

今日看点丨我国团队研制出系列牛用基因芯片;Littelfuse推出紧凑型PTS647轻触开关系列




评论