 物件检测进行模型训练的详细步骤
物件检测进行模型训练的详细步骤

当前面的准备工作都已妥善之后,就可以进入模型训练的步骤,后面的工作就是计算设备的事情了。
4、 执行 TAO 模型训练:
TAO 工具提供提供 QAT (Quantize Aware Training) 量化感知的训练模式,不过目前 QAT 效果还在验证当中,倒也不急于使用,因此我们还是以标准模式来训练,就是将配置文件中 training_config 设置组的 “enable_qat” 参数设为 “false” 就行,然后直接执行指令块的命令,TAO 就会启动视觉类容器来执行模型训练任务。
这里提供两组执行训练所花费的时间参考数据:
-
NVIDIA Qudra RTX A4000/16GB 显存:48 秒/回合
-
NVIDIA RTX-2070/16GB 显存:67 秒/回合
-
两张卡一起训练:40秒/回合
为了更有效率地执行,我们可以在training_config设置组里添加 “checkpoint_interval: 10” 参数,这样每 10 回合生成一个中间文件,这样能节省大约 7GB 的空间。现在检查一下所生成的中间模型文件,如下图所示总共 8 个。
接下去我们看看这 8 个模型的训练效果如何,因为得挑一个精确度 (mAP) 最好的文件,进行后面的修剪任务。
通常越后面的模型 mAP 值越高,但这不是绝对的,最好是有明确的数据来做依据,才是比较科学的态度。在 experiment_dir_unpruned/ssd_training_log_resnet18.csv 提供这些记录,右键点击文件 -> Open With-> CSVTable 之后,就会看到如下图的内容。
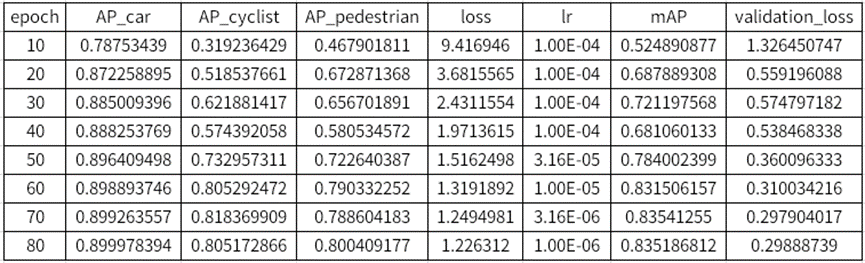
表中可以看到,越下面模型的 mAP 值越高,这样就能明确的选择 “epoch_080” 的模型来进行后续工作,记得在 “%set_env EPOCH=” 后面填入参数值,例如要选择第 80 回合的模型文件,就输入 “080”,然后继续往下进行。
5、评估模型好的训练:
这个步骤的目的是为了确认模型是否符合要求?有时候可能效果最好的模型,效果还未达到预期目标,如果是这样的话,就得回到第 4 步骤,以前面找到效果最好的模型,作为迁移选项的预训练模型,就是将配置文件的 training_config 设置组的 “pretrain_model_path” 改成 ssd_resnet18_epoch_080.tlt 的完整路径,然后再做 80 回合的训练。
执行评估效果的结构在本指令块输出的最下方,如下图所示。

比对一下这里显示的精准度,与前面 ssd_training_log_resnet18.csv 记录的结果是相同的,其实这个步骤是有点冗余,可以忽略!
6、修剪模型:
如果您的模型要放在计算资源充沛的设备上执行推理的话,其实后面的步骤是可以省略的,因此修剪模型的目的,是要在精确度维持水平的基础上将模型进行优化,这对 Jetson 这类计算资源吃紧的边缘设备来说就非常重要,因为这对推理性能有很大的影响,因此要看您所需要执行推理的设备是什么,再决定是否要进行修剪。
每个神经网络都有各自的修剪重点,必须找到对应的说明文件,例如这里对ssd进行修剪,请访问https://docs.nvidia.com/tao/tao-toolkit/text/object_detection/ssd.html,在里面的 “Pruning the Model” 有非常详细的参数说明。
TAO 提供以下 6 种模型修剪的方式,设定值的粗体字为预设值:
-
标准化器 (normalizer):使用参数 -n,设定值为 “max/L2”;
-
均衡器 (equalization_criterion):使用参数 -eq,设定值为 “union/ intersection/ arithmetic_mean/geometric_mean”;
-
修剪粒度 (pruning_granularity):使用参数 -pq,设定值为正整数,预设值为 8;
-
修剪阈值 (pruning threshold):使用参数 -pth,设定值为小于 1 的浮点数,预设值为 0.1;
-
最小数量过滤器 (min_num_filters):使用参数 -nf,设定值为正整数,预设值为 16;
-
排除层 (excluded_layers):使用参数 -el,设定值为正整数,预设值为空值(不排除)。
在大家还不熟悉这些参数用法时,最简单的方法就是调整阈值 (-pth) 的大小去找到平衡点,通常这个值越高就会损失较大的精度值,模型也会比较更小大。参数预设值为 0.1,差不多达0.3 已经是极限,再大可能就会让精准度低于一般要求。
这个步骤会用到 ssd_train_resnet18_kitti.txt 配置文件,修剪完的模型会存放在 -o参数所指定的目录,这里是“$USER_EXPERIMENT_DIR/experiment_dir_pruned”,输出的模型文件名为 “ssd_resnet18_pruned.tlt”,后面的“重新训练剪裁模型”步骤,就会以这个文件作为迁移学习的训练基础。
这个修剪过的模型文件还不能作为部署用途,还得经过下个步骤去重新训练之后,是我们最终所需要的版本。
7、重新训练修剪过的模型:
这个步骤与前面的模型训练几乎是一样的,唯一不同的地方就是前面以 NCG 下载的 resnet_18.hdf5 为基础导入迁移学习的功能,这里是以 ssd_resnet18_pruned.tlt 这个修剪过的文件为基础,同样用最前面的数据集进行训练。
以这个项目为例,未剪裁模型的大小为 101.7MB,用阈值为 0.1 所剪裁的重新训练模型大小只剩 22.5MB、阈值为 0.3 所剪裁的模型大小只剩 9.8MB。重新训练后同样会生成很多模型文件,同样查看 experiment_dir_retrain 目录下面的 ssd_training_log_resnet18.csv,挑出精度最好的一个准备下个评估环节。
8、评价重新训练的模型:
与前面的评估方式一样,找到效果最好的一个,然后将数值填入 “%set_envEPOCH=” 里,准备在训练设备上测试一下推理的效果。
如果修剪后重新训练的模型精度与未修剪的相差不多,这个模型就可以用来作为后面的推理测试,如果精度差距较大,就得回到第 6 步骤重新执行修剪工作与第 7 步骤重新训练,一直到获得满意精度的模型为止。
原文标题:NVIDIA Jetson Nano 2GB 系列文章(62):物件检测的模型训练与优化-2
文章出处:【微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
-
NVIDIA
+关注
关注
14文章
5496浏览量
109097 -
TAO
+关注
关注
0文章
10浏览量
7129 -
模型训练
+关注
关注
0文章
21浏览量
1523
原文标题:NVIDIA Jetson Nano 2GB 系列文章(62):物件检测的模型训练与优化-2
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
在Ubuntu20.04系统中训练神经网络模型的一些经验
请问嘉楠平台k230训练的跌倒检测模型里面的设置是怎么样的?
训练完模型后用cls_video.py在canmvIDE上运行,按着步骤操作但是摄像头没有识别到是什么情况?
请问如何在imx8mplus上部署和运行YOLOv5训练的模型?
使用OpenVINO™ 2021.4在CPU和MYRIAD上进行自定义对象检测,为什么结果差异巨大?
使用OpenVINO™训练扩展对水平文本检测模型进行微调,收到错误信息是怎么回事?
小白学大模型:训练大语言模型的深度指南






 工商网监
工商网监
评论