 统一的文本到结构生成框架——UIE
统一的文本到结构生成框架——UIE

引言:信息抽取终于走到了这一步:迈入大一统时代!
今天为大家介绍一篇好基友 @陆博士 的ACL22论文《Unified Structure Generation for Universal Information Extraction》,这也是中科院和百度联合发布的1篇信息抽取统一建模工作UIE。
UIE官方链接:https://universal-ie.github.io
本文的组织架构为:
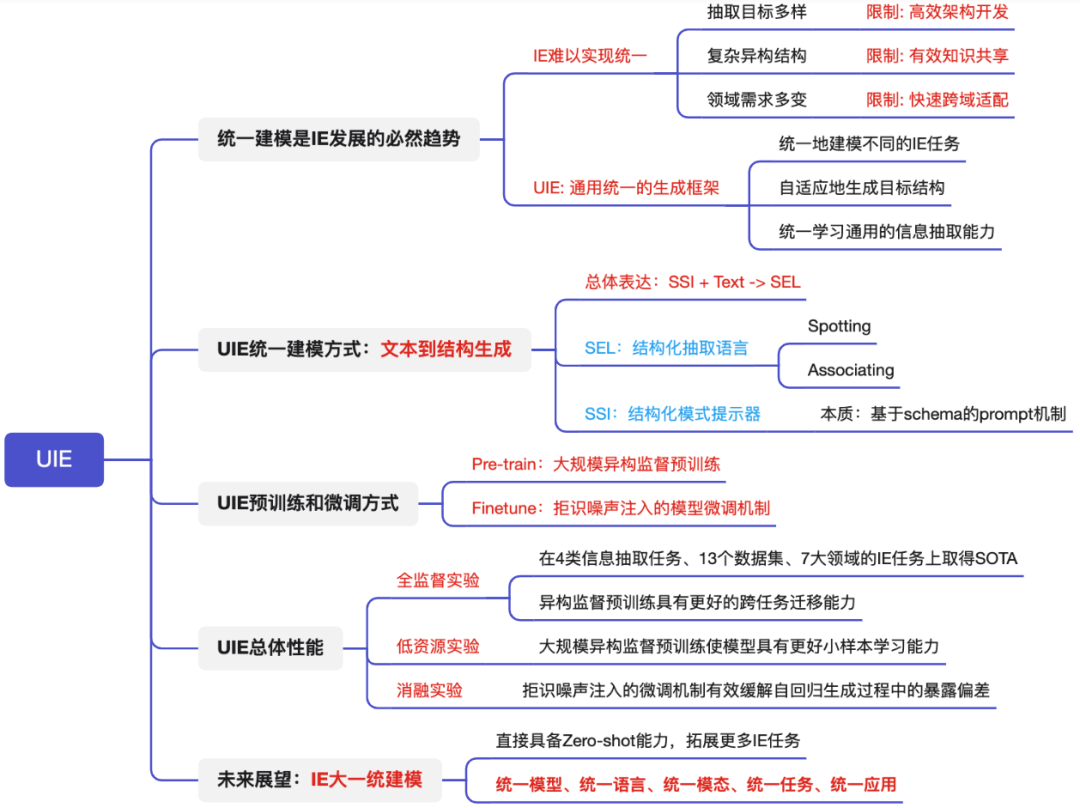
1.统一建模是IE发展的必然趋势
众所周知,信息抽取(IE)是一个从文本到结构的转换过程。常见的实体、关系、事件分别采取Span、Triplet、Record形式的异构结构。
曾几何时,当我们面对各种复杂多样的IE任务,我们总会造各式各样IE模型的轮子,来满足不同复杂任务的多变需求。

如上图所示:由于多样的抽取目标、相异的复杂结构、多变的领域需求时,导致信息抽取模型一直难以实现统一建模,极大限制了IE系统高效架构开发、有效知识共享、快速跨域适配。
比如,一个真实的情况是:针对不同任务设定,需要针对特定领域schema建模,不同IE模型被单个训练、不共享,一个公司可能需要管理众多IE模型。

当我们每次造不同IE轮子的时候,都要喝下不同的肥宅快乐水,撩以解忧(这不是个玩笑)
不过,在生成式统一建模各类NLP任务的今天,信息抽取统一建模也成为可能。
不久前,JayJay在《信息抽取的"第二范式"》一文中指出:生成式统一建模,或许是信息抽取领域正在发生的一场“深刻变革”。
因此:开发通用的IE结构是大有裨益的,可以统一建模不同的IE任务,从各种资源中自适应预测异构结构。总之:统一、通用的IE势不可挡!
这篇ACL2022论文,@陆博士提出了一个面向信息抽取的统一文本到结构生成框架UIE,它可以:
统一地建模不同的IE任务;
自适应地生成目标结构;
从不同的知识来源统一学习通用的信息抽取能力。
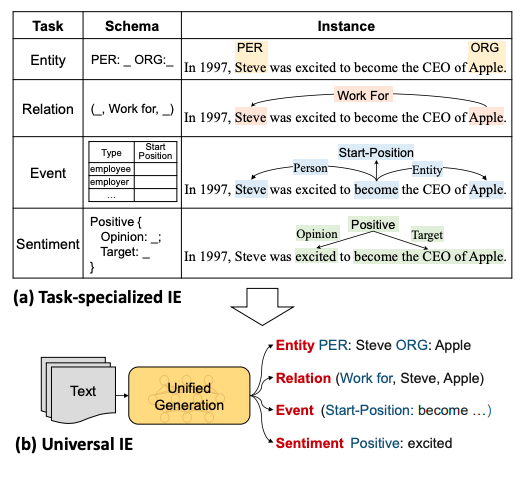
具体来说,UIE:
通过结构化抽取语言对不同的信息抽取目标结构进行统一编码;
通过结构化模式提示器自适应生成目标结构;
通过大规模结构化/非结构化数据进行模型预训练捕获常见的IE能力;
实验结果表明,本文提出的统一生成框架,基于T5模型进行了IE预训练,在实体、关系、事件和情感等4个信息抽取任务、13个数据集的全监督、低资源和少样本设置下均取得了SOTA性能。
接下来,我们将具体介绍UIE是如何统一建模的,以及具体是如何预训练的?
2. UIE统一建模方式:文本到结构生成
信息抽取任务可以表述为“文本到结构”的问题,不同的IE任务对应不同的结构。
UIE旨在通过单一框架统一建模不同IE任务的文本到结构的转换,也就是:不同的结构转换共享模型中相同的底层操作和不同的转换能力。
这里主要有两个挑战:
IE任务的多样性,需要提取许多不同的目标结构,如实体、关系、事件等;
IE任务是通常是使用不同模式定义的特定需求(不同schema),需要自适应地控制提取过程;
因此,针对上述挑战,需要:
设计结构化抽取语言(SEL,Structured Extraction Language)来统一编码异构提取结构,即编码实体、关系、事件统一表示。
构建结构化模式提示器(SSI,Structural Schema Instructor),一个基于schema的prompt机制,用于控制不同的生成需求。
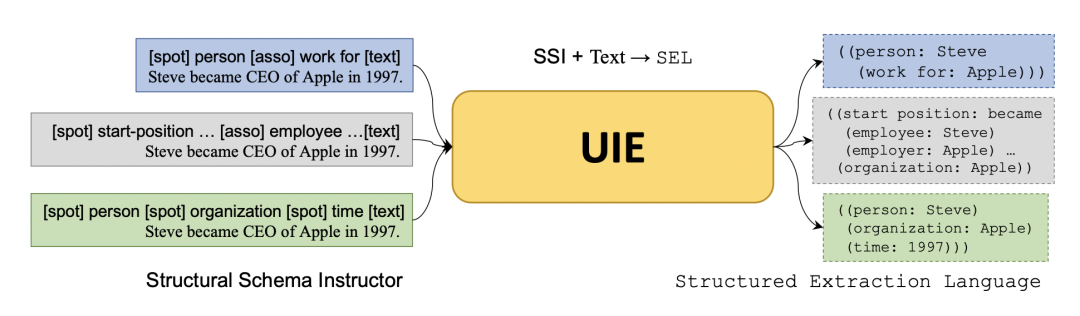
上图展示了UIE的整体框架,整体架构就是:SSI + Text -> SEL
一句话简单概括就是:SSI就是输入特定抽取任务的schema,SEL就是把不同任务的抽取结果统一用1种语言表示。
1)SEL:结构化抽取语言
不同的IE任务可以分解为2个原子操作:
Spotting:找出Spot Name对应的Info Span,如某个实体或Trigger触发词;
Associating:找出Asso Name对应的Info Span,链接Info Span片段间的关系:如两个实体pair的关系、论元和触发词间的关系;

如上图(a)所示:SEL语言可以统一用(Spot Name:Info Span(Asso Name:Info Span)(Asso Name:Info Span)...)形式表示,具体地:
Spot Name:Spotting操作的Info Span的类别信息,如实体类型;
Asso Name: Associating操作的Info Span的类别信息,如关系类型、关系类型;
Info Span:Spotting或Associating操作相关的文本Span;
如上图(b)所示:
蓝色部分代表关系任务:person为实体类型Spot Name,work for为关系类型Asso Name;
红色部分代表事件任务:start-position为事件类型Spot Name,employee为论元类型Asso Name;
黑色部分代表实体任务:organization和time为实体类型Spot Name;

上图给出一个中文case:考察事件 为事件类型Spot Name,主角/时间/地点 为论元类型Asso Name。
2)SSI:结构化模式提示器
SSI的本质一个基于schema的prompt机制,用于控制不同的生成需求:在Text前拼接上相应的Schema Prompt,输出相应的SEL结构语言。
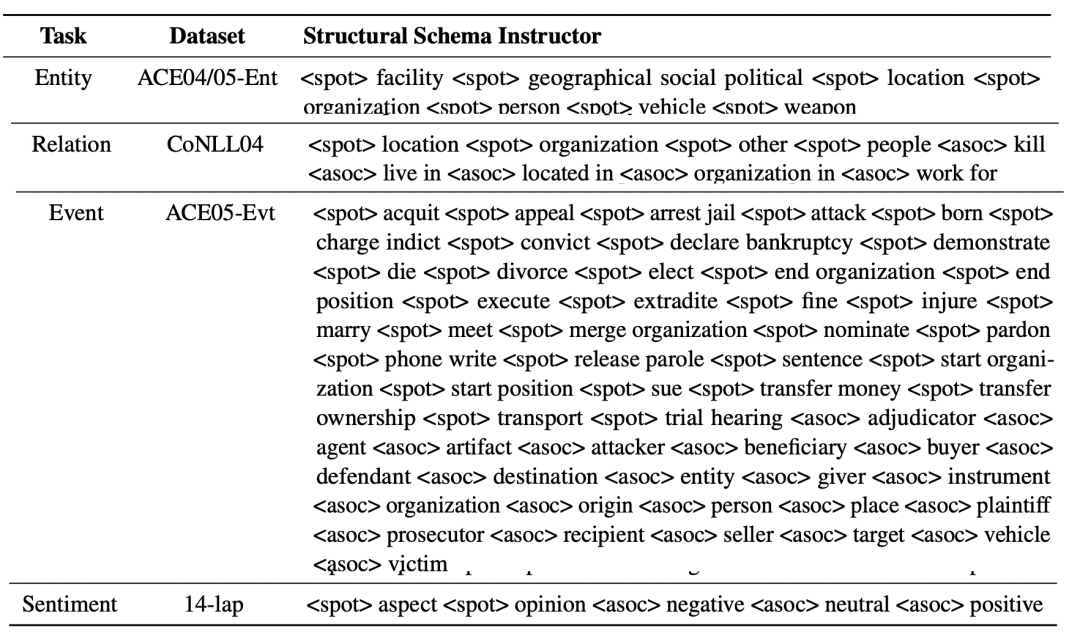
不同任务的的形式是:
实体抽取:[spot] 实体类别 [text]
关系抽取:[spot] 实体类别 [asso] 关系类别 [text]
事件抽取:[spot] 事件类别 [asso] 论元类别 [text]
观点抽取:[spot] 评价维度 [asso] 观点类别 [text]
下图给出了不同任务数据集的SSI形式:
3. UIE预训练和微调方式
本小节,我们将介绍:
1)Pre-train:如何预训练一个大规模的UIE模型,来捕获不同IE任务间的通用IE能力?
2)Finetune:如何通过快速的Finetune使UIE适应不同设置下的不同 IE 任务。
1)Pre-train:大规模异构监督预训练
UIE预训练语料主要来自Wikipedia、Wikidata和ConceptNet,构建了3种预训练数据:
D_pair: 通过Wikipedia对齐Wikidata,构建text-to-struct的平行语料:(SSI,Text,SEL)
D_record: 构造只包含SEL语法结构化record数据:(None,None,SEL)
D_text: 构造无结构的原始文本数据:(None,Text',Text'')
针对上述数据,分别构造3种预训练任务,将大规模异构数据整合到一起进行预训练:
Text-to-Structure Pre-training:为了构建基础的文本到结构的映射能力,对平行语料D_pair训练,同时构建负样本作为噪声训练(引入negative schema)。
Structure Generation Pre-training:为了具备SEL语言的结构化能力,对D_pair数据只训练 UIE 的 decoder 部分。
Retrofitting Semantic Representation:为了具备基础的语义编码能力,对D_text数据进行 span corruption训练。
最终的预训练目标,包含以上3部分;
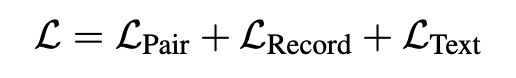
2)Finetune:拒识噪声注入的模型微调机制
为了解决自回归Teacher-forcing的暴露偏差,构建了拒识噪声注入的模型微调机制:随机采样SEL中不存在的SpotName类别和AssoName类别,即:(SPOTNAME, [NULL]) 和 (ASSONAME, [NULL]),学会拒绝生成错误结果的能力,如下图所示:
4. UIE主要实验结论
1)全监督实验
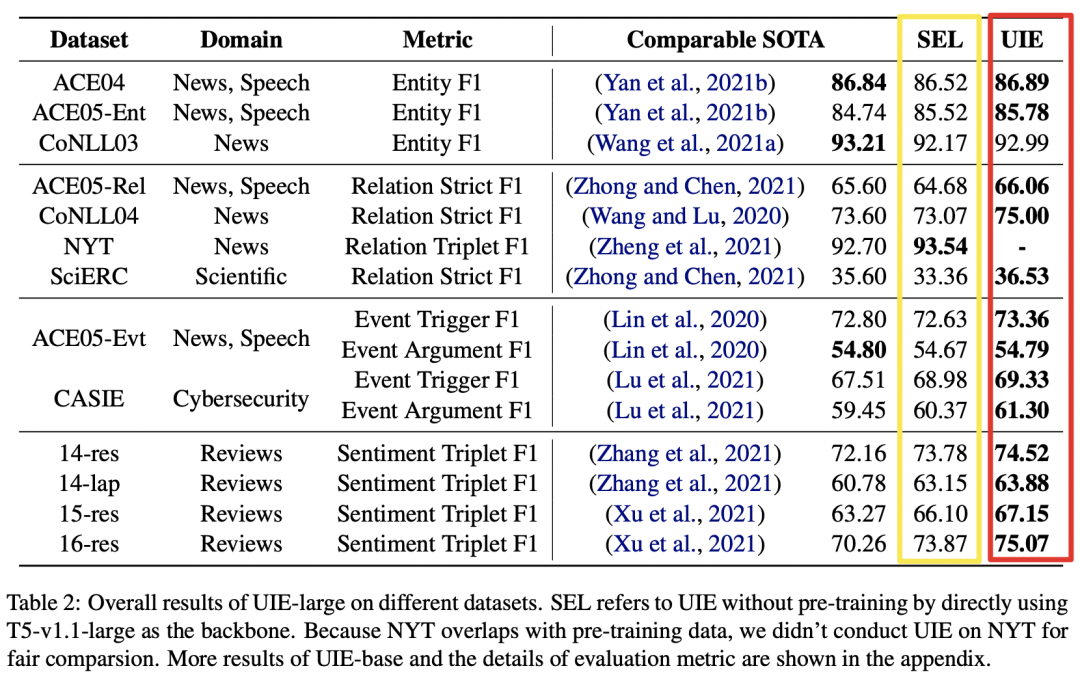
如上图所示,SEL代表未经预训练的UIE模型。可以看出:
1、在4类信息抽取任务、13个数据集、7大领域的IE任务上,UIE达到了SOTA性能;
2、对比SEL和UIE结果:异构监督预训练显著地提升了 UIE 的通用信息抽取能力,具有更好的跨任务迁移能力;
2)少样本实验
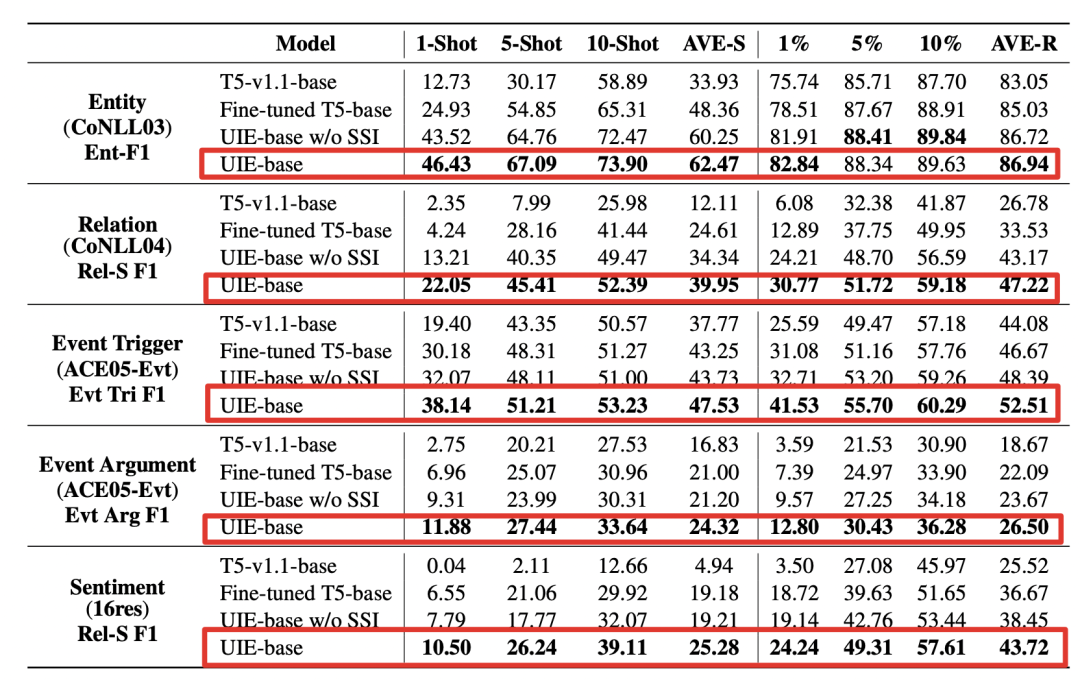
少样本实验可以发现:
1、大规模异构监督预训练可以学习通用的信息抽取能力,使模型具有更好小样本学习能力。
2、当去掉SSI结构化模式提示器后,发现指标下降,因此:结构化抽取指令具有更好的定向迁移的能力。
3)消融实验
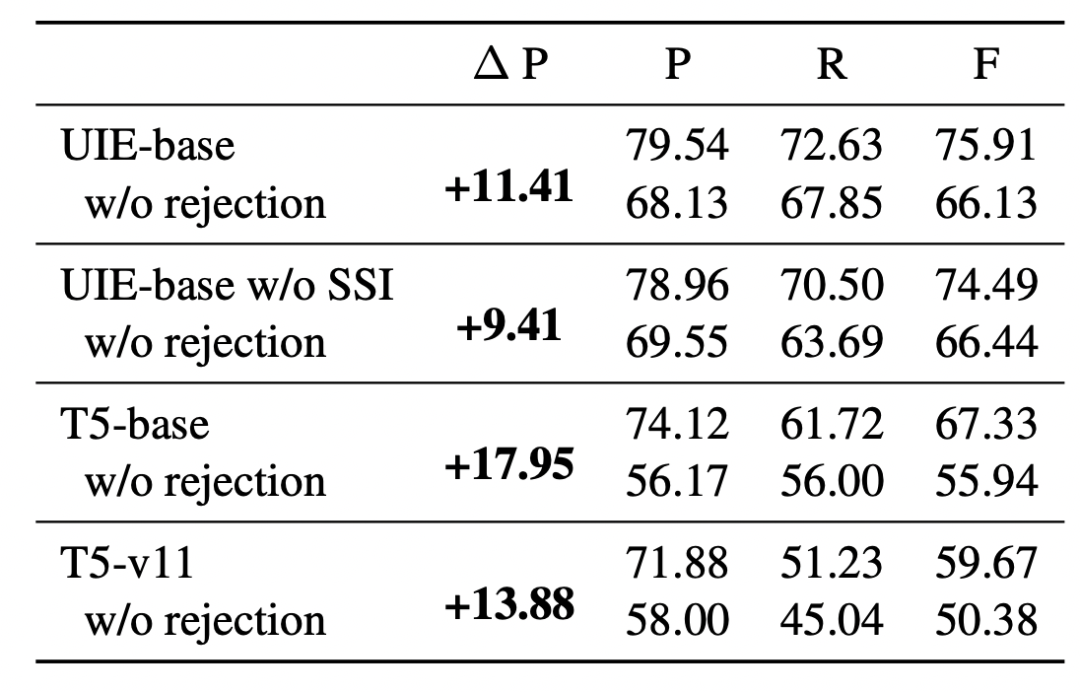
上述消融实验表明:基于拒识噪声注入的模型微调机制可以有效缓解自回归生成过程中的暴露偏差问题。
总结与展望
本文介绍了一个统一的文本到结构生成框架——UIE,可以通用建模不同的IE任务,自适应生成有针对性的结构,从不同的知识来源统一学习通用的信息抽取能力。
实验结果表明UIE实现了在监督和低资源下的SOTA性能,同时验证了其普遍性、有效性和可转移性。
审核编辑 :李倩
-
建模
+关注
关注
1文章
324浏览量
63493 -
文本
+关注
关注
0文章
120浏览量
17918
原文标题:信息抽取大一统:百度中科院发布通用抽取模型UIE,刷新13个IE数据集SOTA!
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
TomTom推出面向ADAS的统一限速数据服务
为什么国产MCU的工程生态很难统一?
京东零售广告创意:统一的布局生成和评估模型

重构电子系统抗扰设计的统一理论框架——从关联认知到正向设计

半导体封装框架的外部结构设计
万里红文本生成算法通过国家网信办备案
请问STM32如何移植Audio框架?
Copilot操作指南(一):使用图片生成原理图符号、PCB封装
一种基于扩散模型的视频生成框架RoboTransfer

关于鸿蒙App上架中“AI文本生成模块的资质证明文件”的情况说明
边缘生成式AI面临哪些工程挑战?




评论