 英特尔AVX-512VNNI技术解析
英特尔AVX-512VNNI技术解析

英特尔AVX-512VNNI技术解析
高级矢量扩展指令集(AdvancedVector ExtensionsAVX)是x86架构微处理器中的SIMD指令集。英特尔AVX-512顾名思义寄存器位宽是512b,可以支持16路32b单精度浮点数或64路8b整型数。
英特尔至强可扩展处理器通过英特尔深度学习加速(英特尔DLBoost)进一步提升了AI计算性能。英特尔深度学习加速包含英特尔AVX-512VNNI(VectorNeural Network Instructions),是对标准英特尔AVX-512指令集的扩展。
如何理解英特尔AVX-512技术,还要从SIMD指令集说起。SIMD是单指令流多数据流操作(SingleInstruction Stream, Multiple Data Stream)的缩写,相对应的是SISD单指令流单数据流(SingleInstruction Stream, Single Data Stream)。相较于传统的单指令单数据指令,SIMD指令使得一条指令可以完成多组数据的操作。单指令单数据流和单指令多数据流区别如下图所示:
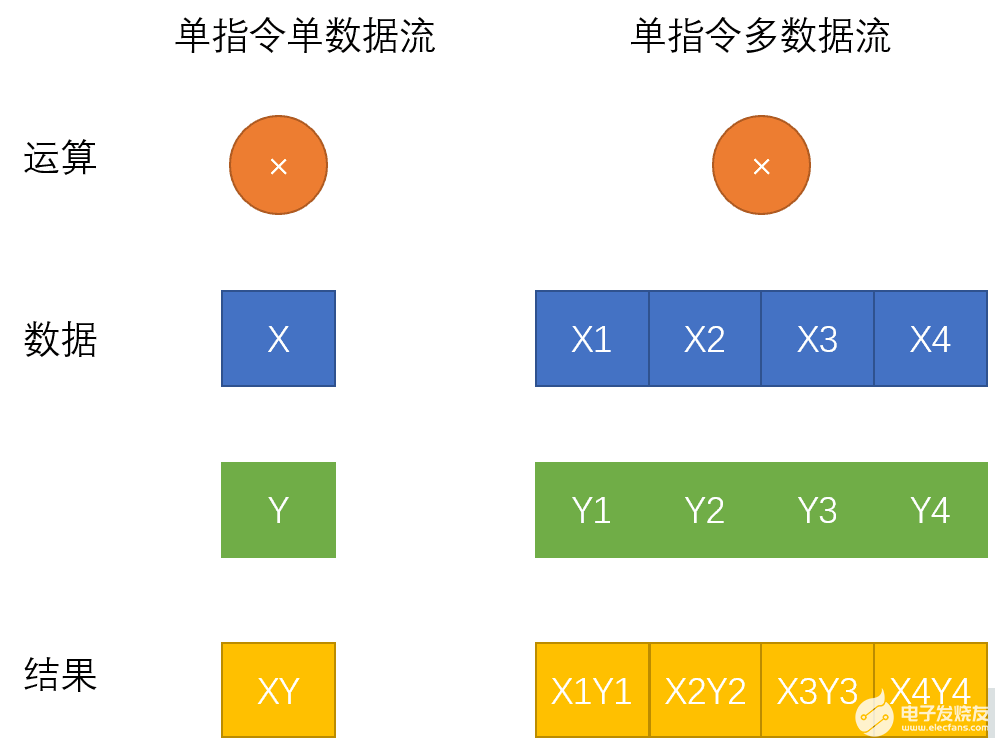
英特尔AVX指令集的前世今生
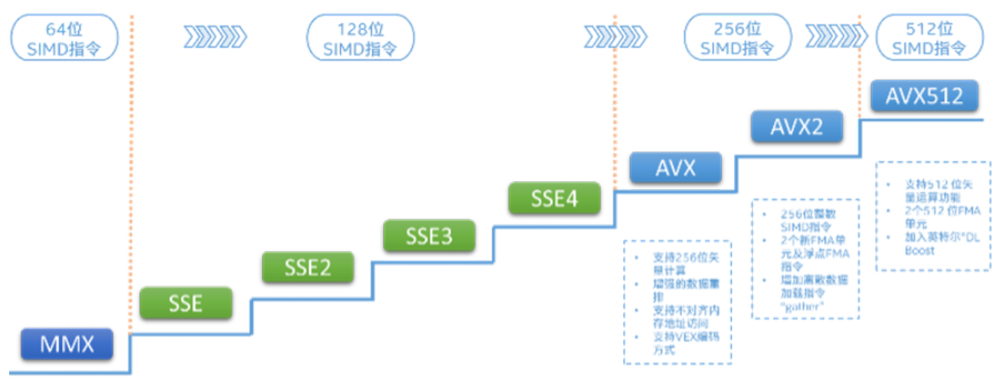
英特尔最早发布的SIMD指令集是MMX指令集:
1996年,英特尔发布了基于新版P55C架构的PentiumMMX系列处理器,其中引入了新的MMX指令集,开始支持SIMD。PentiumMMX系列处理器上新引入的MMX指令集开创了x86处理器支持SIMD操作的先河,该指令集定义了8个64-bit宽度的寄存器,每个寄存器的64-bit容量中可以放入八个8-bit长度的整数或四个16-bit长度整数或两个32-bit整数,CPU在识别到MMX指令集的新指令时会自动将寄存器中的数据进行分割计算,这样一来,单个指令就成功操作了多个数据,实现了SIMD。
英特尔AVX-512指令集实际上分成不同的扩展,用来实现不同的操作。具体的扩展如下:
AVX-512 Foundation
AVX-512 Conflict Detection Instructions (CD)
AVX-512 Exponential and Reciprocal Instructions (ER)
AVX-512 Prefetch Instructions (PF)
AVX-512 Vector Length Extensions (VL)
AVX-512 Byte and Word Instructions (BW)
AVX-512 Doubleword and Quadword Instructions (DQ)
AVX-512 Integer Fused Multiply Add (IFMA)
AVX-512 Vector Byte Manipulation Instructions (VBMI)
AVX-512 Vector Neural Network Instructions Word variable precision (4VNNIW)
AVX-512 Fused Multiply Accumulation Packed Single precision (4FMAPS)
VPOPCNTDQ
VPCLMULQDQ
AVX-512 Vector Neural Network Instructions (VNNI)
AVX-512 Galois Field New Instructions (GFNI)
AVX-512 Vector AES instructions (VAES)
AVX-512 Vector Byte Manipulation Instructions 2 (VBMI2)
AVX-512 Bit Algorithms (BITALG)
AVX-512 Bfloat16 Floating-Point Instructions (BF16)
AVX-512 Half-Precision Floating-Point Instructions (FP16)
通过以上这些指令集扩展,让英特尔至强可扩展处理器家族在音视频处理、游戏、科学计算、数据加密压缩以及深度学习等场景中拥有了出色的表现。
英特尔AVX-512VNNI(VectorNeural Network Instructions)
英特尔AVX-512VNNI(VectorNeural NetworkInstructions)是英特尔深度学习加速一项重要的内容,也是对标准英特尔AVX-512指令集的扩展。可以将三条指令合并成一条指令执行,更进一步的发挥新一代英特尔至强可扩展处理器的计算潜能,提升INT8模型的推理性能。目前第2代和第3代英特尔至强可扩展处理器均支持英特尔VNNI。
未使用VNNI的平台需要vpmaddubsw、vpmaddwd和vpaddd指令才能完成INT8卷积运算中的乘累加:

而拥有VNNI的平台上则可以使用一条指令vpdpbusd完成INT8卷积操作:
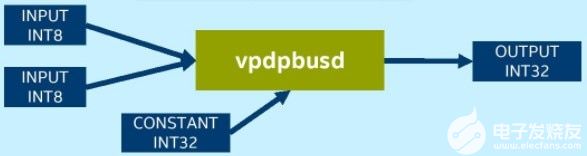
英特尔深度学习加速VNNI加速推荐系统中的矢量召回
下面介绍一个具体的使用场景:英特尔深度学习加速VNNI加速推荐系统中的矢量召回。
众所周知,推荐系统需要解决的问题是:如何为既定用户生成一个长度为K的推荐列表,并使该推荐列表尽量(高准确性)、尽快(低延迟)地满足用户的兴趣和需求?常规的推荐系统包含两部分:矢量召回(vectorrecall)和重排(ranking)。前者从庞大的推荐池里粗筛出当前用户最可能感兴趣的几百或几千条内容,并将结果交由后者的排序模块进一步排序,得到最终推荐结果。
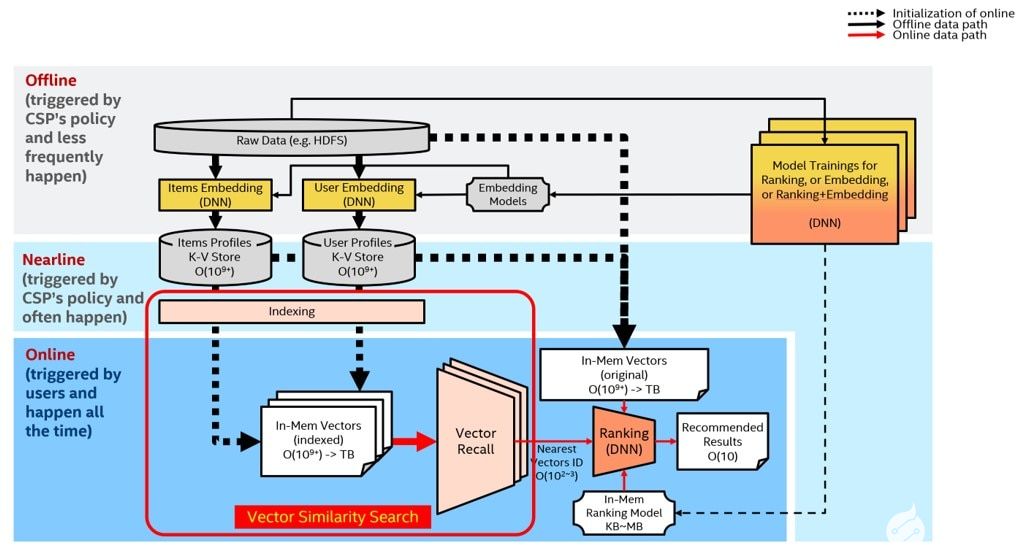
矢量召回可以转换成高纬度的矢量相似性搜索问题。HNSW(HierarchicalNavigable Small World)算法是基于图结构的ANN(ApproximateNearest Neighbor)矢量相似度搜索算法之一,也是速度最快精度最高的算法之一。
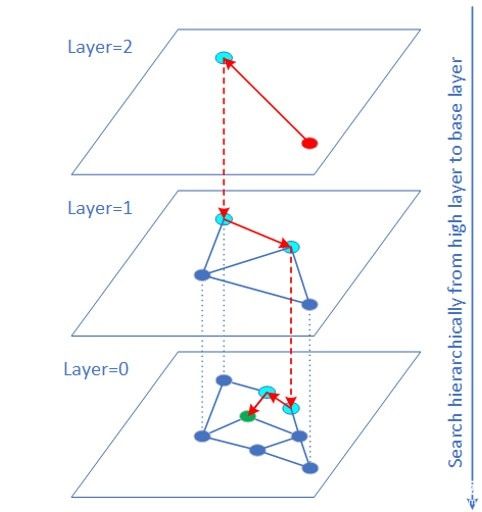
矢量原始数据的数据类型常常是FP32。对于很多业务(如图片检索),矢量数据是可以用INT8/INT16表示而且量化误差对最终搜集结果影响有限。这时可以使用VNNI intrinsic 指令实现矢量INT8/INT16 的内积计算。大量实验表明QPS性能有较大的提升,而且召回率几乎不变。QPS提升的原因一方面是 INT8/INT16访问带宽比 FP32少很多,另一方面距离计算部分由于使用 VNNI指令得以加速。
当数据集比较大时(如1亿到10亿数据量级范围),传统的做法是将数据集切片,变成几个较小的数据集,每个数据集单独获取topK,最后再合并。由于增加了多个机器之间的通信,增加延迟的同时降低了QPS。在大数据集上使用HNSW方案的最佳实践是:尽量不切片,在完整的数据集上建立索引和执行搜索,可获得最佳性能。当数据集过大,内存空间不够时,可以考虑使用英特尔傲腾持久内存解决。
Super-FusedBERT技术解析
BERT介绍
BERT(BidirectionalEncoder Representations fromTransformers,基于变换器的双向编码器表示技术)是2018年谷歌公司提出的NLP(Naturallanguageprocessing,自然语言处理)学科的新技术。谷歌正在利用BERT来更好地理解用户搜索语句的语义。2020年的一项文献调查得出结论:“在一年多一点的时间里,BERT已经成为NLP实验中无处不在的基线”,算上分析和改进模型的研究出版物超过150篇。
BERT的创新点在于它将双向Transformer用于语言模型,之前的模型是从左向右输入一个文本序列,或者将left-to-right和right-to-left的训练结合起来。实验的结果表明,双向训练的语言模型对语境的理解会比单向的语言模型更深刻,BERT使用了一种新技术叫做MaskedLM(MLM),在这个技术出现之前是无法进行双向语言模型训练的。
英特尔AVX-512技术加速新浪广告业务
通过使用英特尔AVX-512实现Super-FusedBert优化方案
一、利用Intel MKL高性能数学库
MKL是Intel发布的高性能数学库,适用于科学计算,工程和金融领域。经过多年的打磨,MKL已经是x86平台上性能最好的数学库之一。借助MKL可以最大限度的发挥出Xeon处理器的硬件性能,帮助加速Bert模型的推理。

图 MKL高性能数学库
深度学习模型中存在大量矩阵乘法(GEMM)这种计算密集操作,可以直接使用MKL的cblas_sgemm接口。
此外,MKL还提供了一种新的GEMM接口,叫PackedAPI。这种API可以对输入的矩阵进行预处理(Pack),进一步提高GEMM的效率。
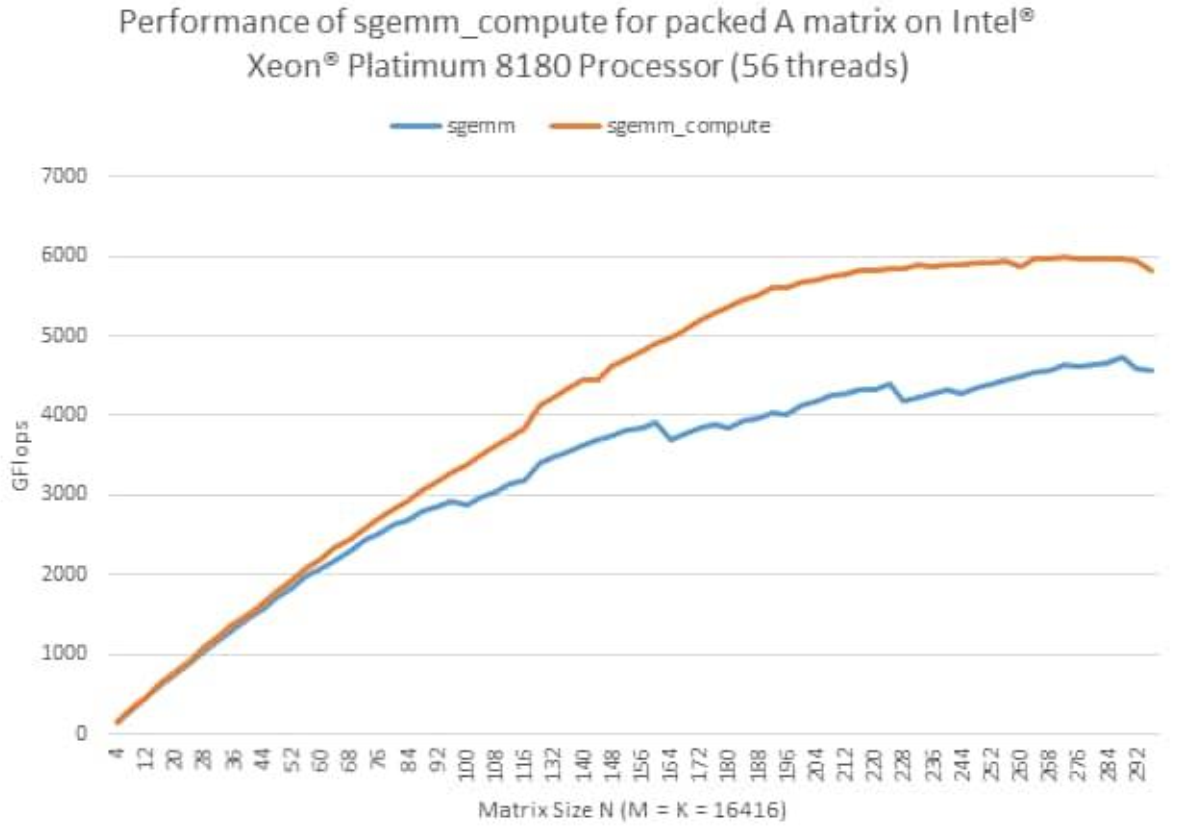
图 MKLPacked API性能曲线
对于Bert模型,在其推理时权重是固定的,因此可以对权重进行重排,使用MKL的PackedAPI进行模型推理加速。
二、利用Intel oneDNN开源深度学习加速库
oneDNN是Intel开源的深度学习加速库,同样可以支持不同的计算设备,如CPU,GPU等。oneDNN抽象了以下几个概念:
Primitive:一种DNN算子的底层原语,支持matmul,convolution等。
Memory:对Primitive使用的内存的抽象,存在多种布局,不同的内存布局也会影响
Primitive:的执行效率。
Engine:底层计算设备抽象,可支持 CPU, GPU。
Stream:Engine中Primitive的队列。
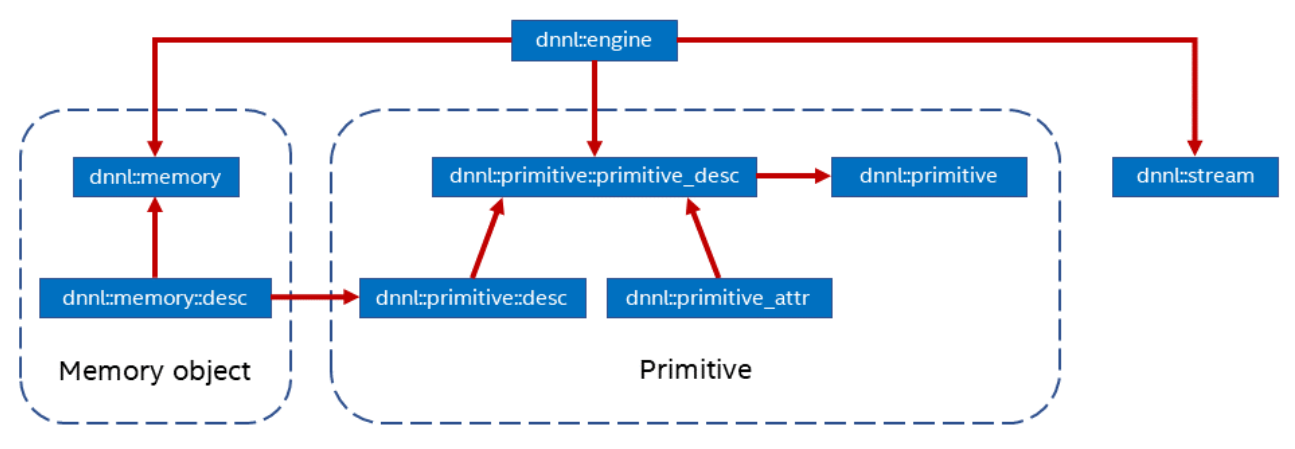
图 oneDNN结构
oneDNN中支持了大量常用的深度学习算子。Bert中使用的softmax,layernorm,gelu也都在oneDNN的Primitive中找到相应的实现。
三、使用AVX-512技术进行算子融合
在深度学习框架中,一个模型由多个算子组成,这些算子执行都服从深度学习中调度器的调度。冗余的算子会增加调度开销,进而影响执行效率。并且算子实现中可能还有很多不必要的访存和内存分配。因此在针对推理的优化中,减少算子数量非常必要。

图 算子融合示意图
除此之外,深度学习模型中,计算密集的算子(matmul,conv)后面会跟一个element-wise的操作(激活函数relu)。这些element-wise的操作可以在计算密集算子计算的过程中完成,而不必等到计算密集算子完全计算完后再进行。这种优化也叫算子融合。
在Bert模型中,matmul,biasadd,gelu的组合可以使用oneDNN的matmulprimitive算子结合追加post_op来完成。
oneDNN的matmulprimitive可以进行多维tensor的乘法操作,并附加融合bias加法。
四、访存优化
由于CPU架构的特点,越靠近CPU的存储越快,体积越小。因此高效利用缓存对程序性能非常重要。
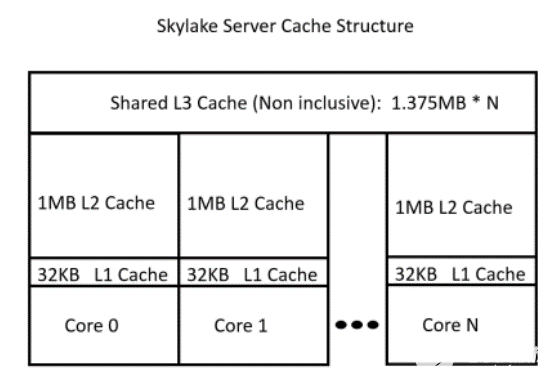
图 CPUcache结构示意图
这就要求算子在实现的过程中能够尽可能减少内存占用,进而减少cache的换出,提高cache利用率。
在Bert的self-attention中,对于q、k、v的计算中存在转置操作。通过下图可以清楚的看到,每一个q、k、v在经过一个线性层后,都会按照head进行split并转置。在self-attention最后和v进行点积后,还需要一个转置来摆放数据。
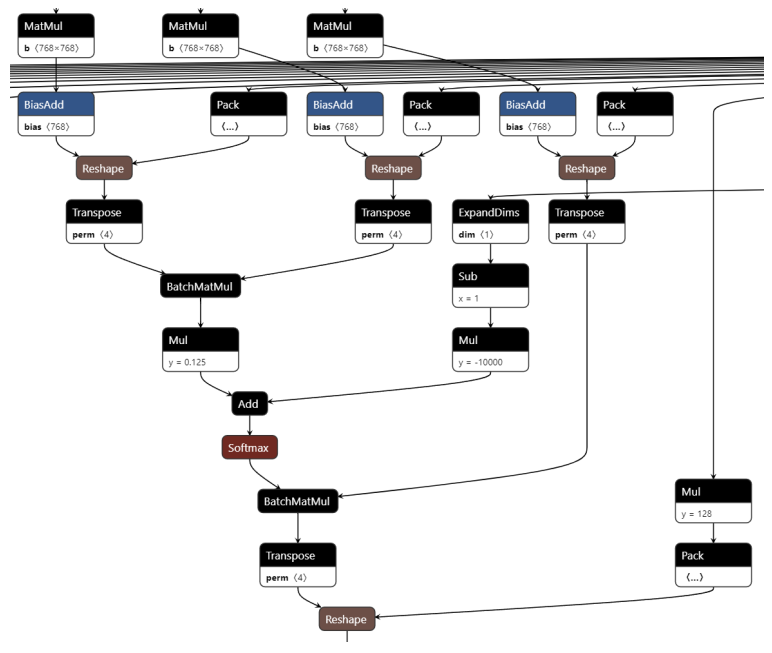
图self-attention图结构
其实通过分析图结构的计算流程,我们可以将上面的转置消除。如下图,原来的数据是按红色方框的方式存放,但是BatchMatmul需要用到的数据位于绿色方块中。因此我们可以使用MKL的batch_sgemm接口,将参数stride指定为64*12。这样就可以避免转置带来的内存占用和访存开销。
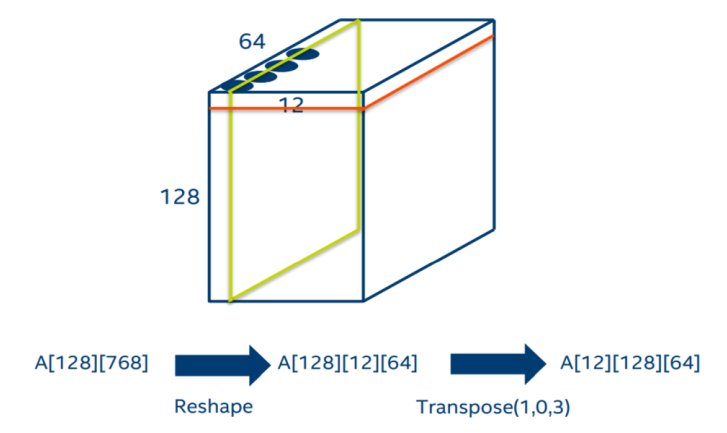
图消除self-attention转置
性能优化数据
在Intel第三代Xeon处理器IceLake8358P上,我们对Super-FusedBert进行了性能测试:
Bertbase model 参数:
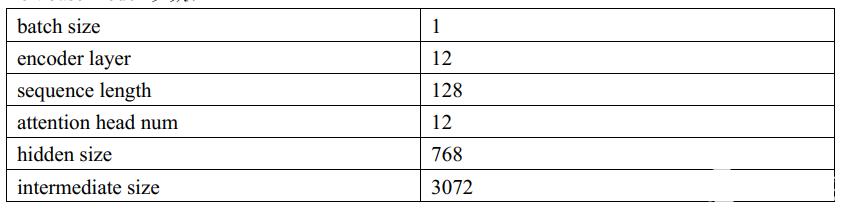
数据对比:
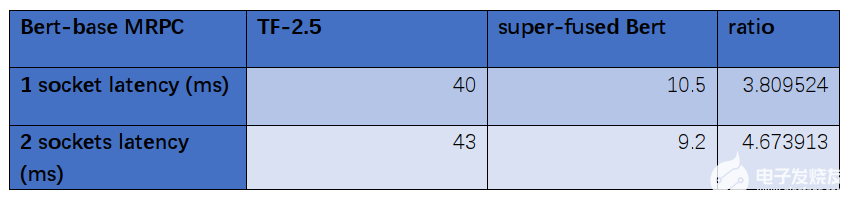
通过数据对比分析,经过优化后的Bert-base模型在第三代Xeon处理器IceLake8358P比优化前节省了大约四分之三的时长,分别从40ms优化到10.5ms、43ms优化到9.2ms。
这种优化对于满足实时在线服务推理的延迟要求有着十分显著的作用,有利于业务部门搭建基于Bert模型的业务,提高了集群中CPU利用率。
*实际性能受使用情况、配置和其他因素的差异影响。更多信息请见www.Intel.com/PerformanceIndex性能测试结果基于配置信息中显示的日期进行测试,且可能并未反映所有公开可用的更新。
详情请参阅配置信息披露。没有任何产品或组件是绝对安全的。
英特尔技术可能需要启用硬件、软件或激活服务。
具体成本和结果可能不同。
审核编辑:汤梓红
-
英特尔
+关注
关注
61文章
10320浏览量
181065 -
微处理器
+关注
关注
11文章
2440浏览量
86130 -
指令集
+关注
关注
0文章
229浏览量
24445
发布评论请先 登录
2026英特尔客户高峰论坛:杰和科技以深度协同收获技术跃迁

英特尔EN6310QA 1A PowerSoC:高效电源解决方案解析
英特尔Cyclone V器件数据手册解析
吉方工控亮相2025英特尔技术创新与产业生态大会
创芯赋能智能生态!汇顶科技亮相2025英特尔技术创新与产业生态大会

英特尔举办行业解决方案大会,共同打造机器人“芯”动脉

向新而生,同“芯”向上!2025英特尔技术创新与产业生态大会在重庆举行

科通技术获评英特尔首批尊享级合作伙伴

使用英特尔® NPU 插件C++运行应用程序时出现错误:“std::Runtime_error at memory location”怎么解决?
英特尔锐炫Pro B系列,边缘AI的“智能引擎”

英特尔先进封装,新突破
英特尔发布全新GPU,AI和工作站迎来新选择
英特尔持续推进核心制程和先进封装技术创新,分享最新进展
英特尔代工:明确重点广合作,服务客户铸信任



评论