 Transformers研究方向
Transformers研究方向

BERT 通过改变 NLP 模型的训练方式迎来了 NLP 领域的 ImageNet 时刻。自此之后的预训练模型分别尝试从mask 范围,多语言,下文预测,模型轻量化,预训练方式,模型大小,多任务等方向谋求新突破,有的效果明显,有的只是大成本小收益。
自 2018 年 BERT 提出之后,各种预训练模型层出不穷,模型背后的着眼点也各有不同,难免让人迷糊。本文旨在从以下几个方面探讨系列 Transformers 研究方向:
扩大遮罩范围(MaskedLM)
其他预训练方式
轻量化
多语言
越大越好?
多任务
要说 BERT 为什么性能卓越,主要是它改变了 NLP 模型的训练方式。先在大规模语料上训练出一个语言模型,然后将这个模型用在阅读理解/情感分析/命名实体识别等下游任务上
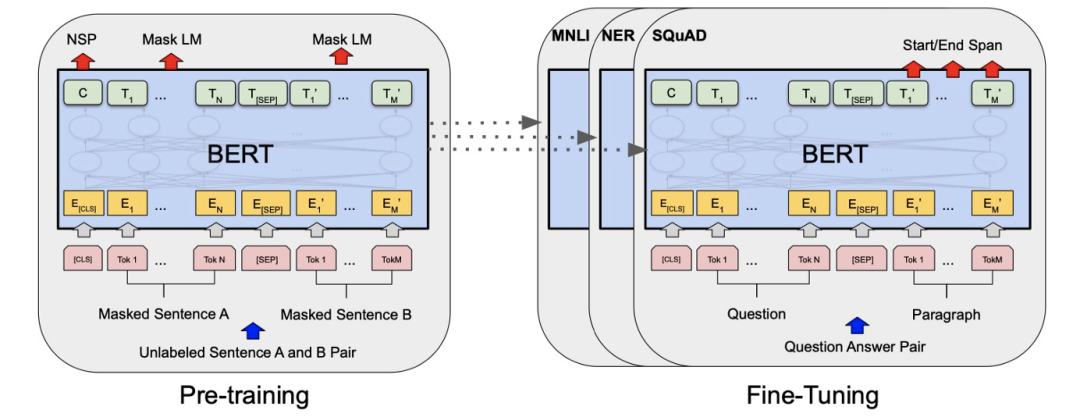
Yann LeCun 将 BERT 的学习方式称为“自监督学习”,强调模型从输入内容中学习,又对其中部分内容进行预测的特点。而 BERT 本身实际算是是基于 Transformer 编码器部分改进而来的多任务模型,会同时执行遮罩语言模型学习以及下文预测任务,以此习得潜藏语义。
扩大遮罩范围改进 MaskedLM
遮罩语言模型里的“遮罩”,通常是分词后一小段连续的 MASK 标记

相比于从上下文中猜整个词,给出 ##eni 和 ##zation 猜到 tok 显然更容易些。
也正因单词自身标识间的联系和词与词间的联系不同,所以 BERT 可能学不到词语词间的相关关系。而只是预测出词的一部分也没什么意义,预测出整个词才能学到更多语义内容。所以拓展遮罩范围就显得十分重要了:
字词级遮罩——WWM
短语级遮罩——ERNIE
缩放到特定长度——N-gram 遮罩/ Span 遮罩
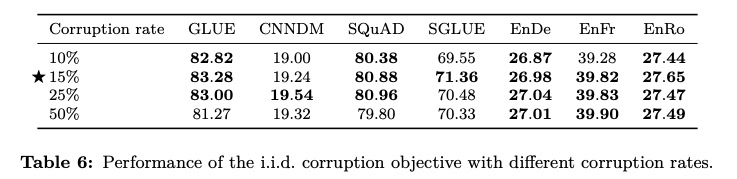
短语级遮罩使用时得额外提供短语列表,但加上这样的人工信息可能会干扰模型导致偏差。T5 尝试了不同跨度的遮罩,似乎长一些的会好点
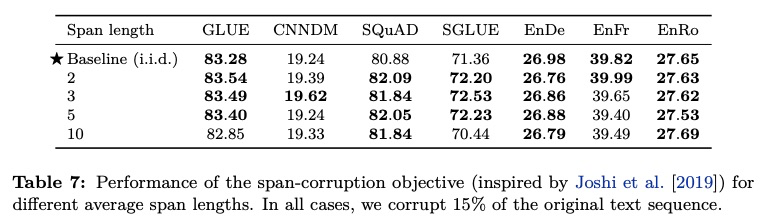
可以看到初期扩大跨度是有效的,但不是越长越好。SpanBERT 有一个更好的解决方案,通过概率采样降低对过长遮罩的采纳数量。
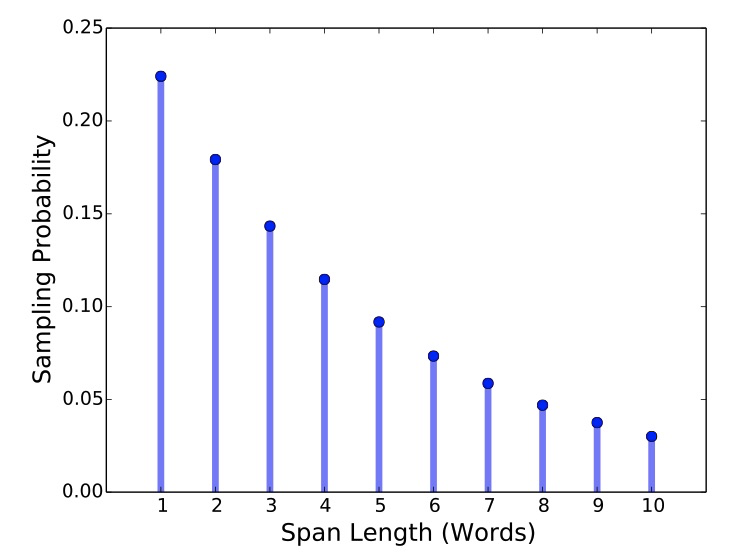
从 SpanBERT 的实验结果来看随机跨度效果不错
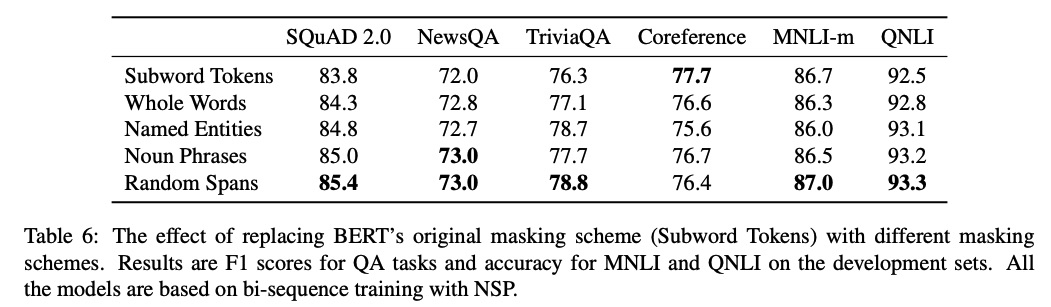
此外,也有模型尝试改进遮罩比例。Google 的 T5 尝试了不同的遮罩比例,意外的是替代项都不如原始设置表现好
下文预测
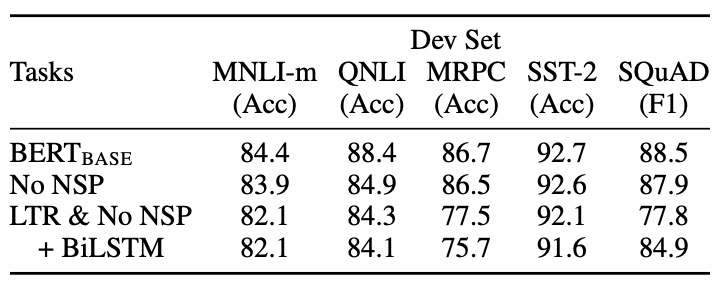
准确地讲应该是下一句预测(NextSentencePrediction,NSP),通过判断两个句子间是否是上下文相关的来学习句子级知识。从实验结果来看,BERT 并没有带来明显改进
BERT 的欠佳表现给了后来者机会,几乎成了兵家必争之地。XLNET / RoBERTa / ALBERT 等模型都在这方面进行了尝试
RoBERTa
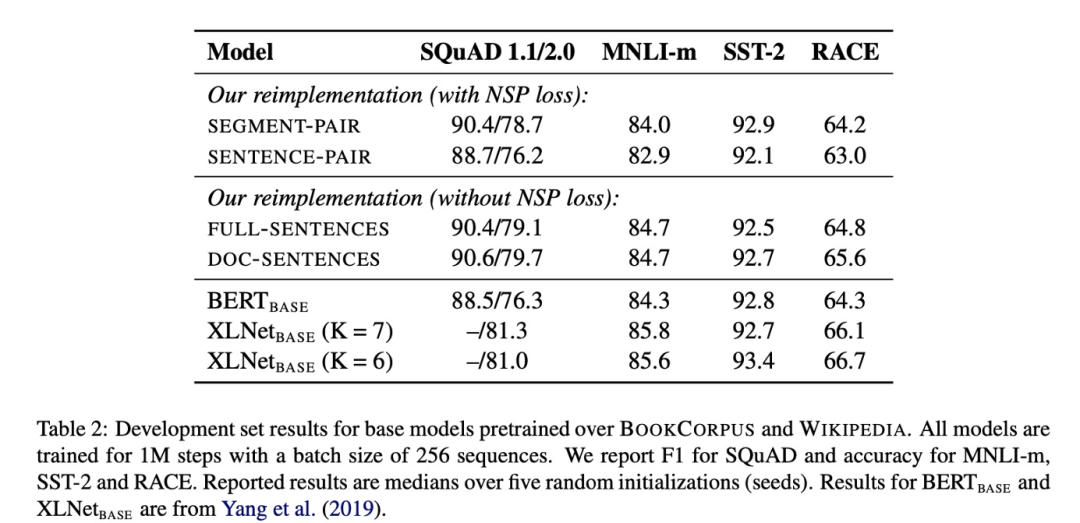
ALBERT
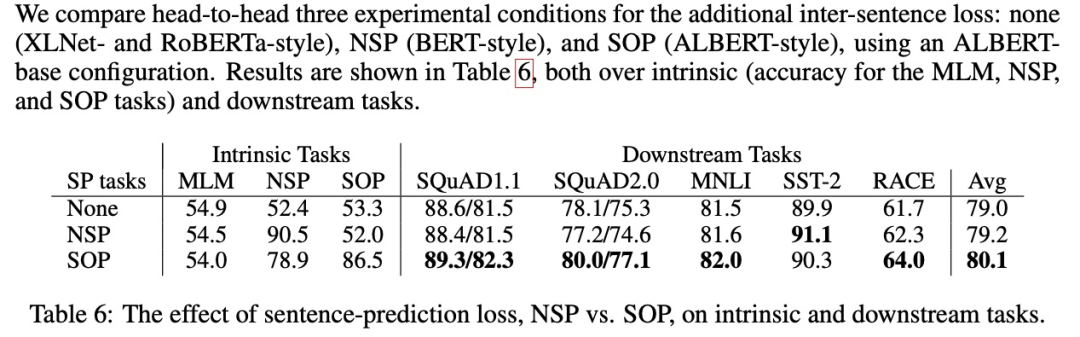
XLNet
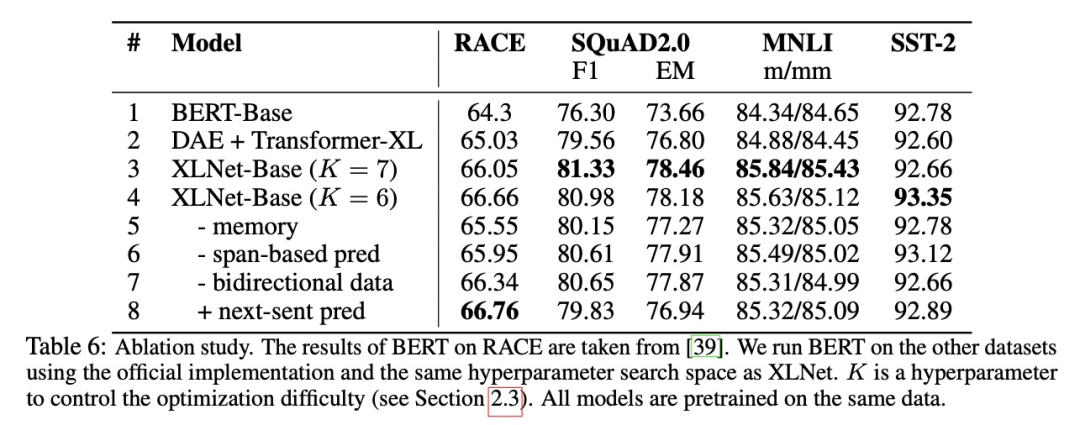
可以看出 NSP 带来的更多的是消极影响。这可能是 NSP 任务设计不合理导致的——负样本是从容易辨析的其他文档中抽出来的,这导致不仅没学到知识反而引入了噪声。同时,NSP 将输入分成两个不同的句子,缺少长语句样本则导致 BERT 在长句子上表现不好。
其他预训练方式
NSP 表现不够好,是不是有更好的预训练方式呢?各家都进行了各种各样的尝试,私以为对多种预训练任务总结的最好的是 Google 的 T5 和 FaceBook 的 BART
T5 的尝试

BART 的尝试
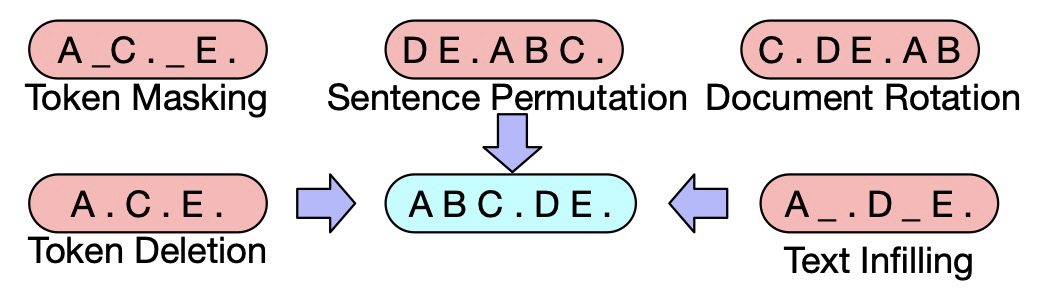
各家一般都选语言模型作为基线,而主要的尝试方向有
挡住部分标识,预测遮挡内容
打乱句子顺序,预测正确顺序
删掉部分标识,预测哪里被删除了
随机挑选些标识,之后将所有内容前置,预测哪里是正确的开头
加上一些标识,预测哪里要删
替换掉一些标识,预测哪里是被替换过的
试验结果如下
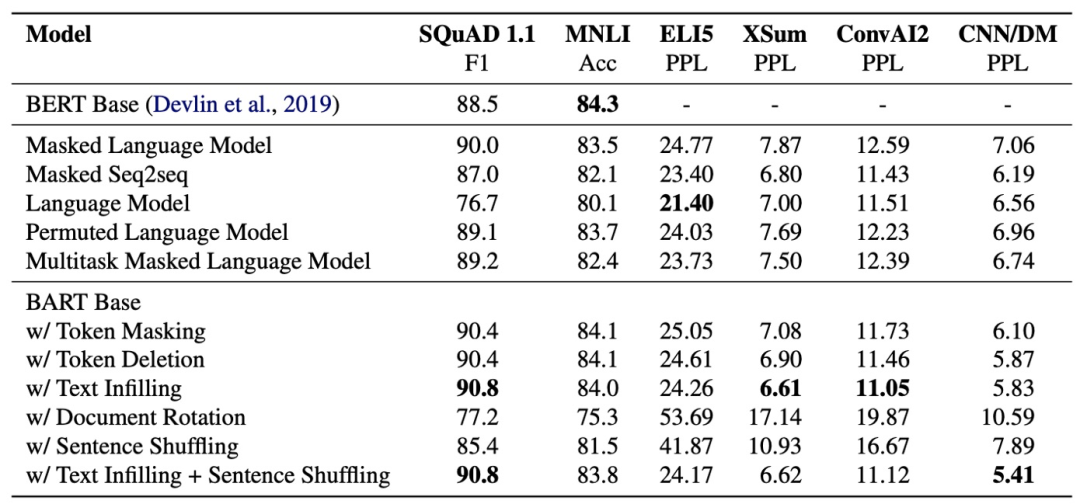
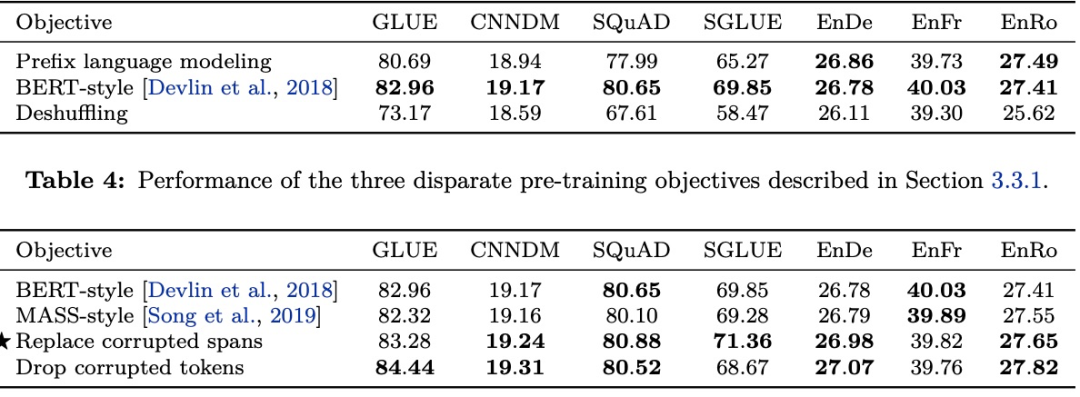
实验表明遮罩模型就是最好的预训练方法。要想效果更好点,更长的遮罩和更长的输入语句似乎是个不错的选择。而为了避免泄露具体挡住了多少个词,每次只能标记一个遮罩,对一个或多个词做预测
轻量化
BERT 模型本身非常大,所以为了运行更快,模型轻量化也是一大研究方向。一网打尽所有 BERT 压缩方法[1]对此有细致描述,主要分几个方向:
修剪——删除部分模型,删掉一些层 / heads 等
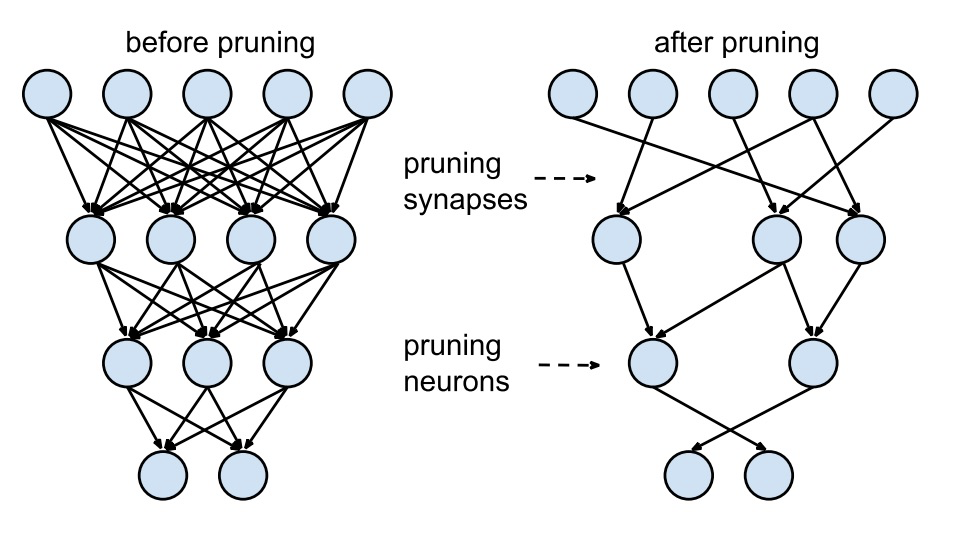
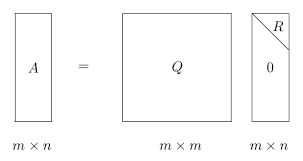
矩阵分解——对词表 / 参数矩阵进行分解
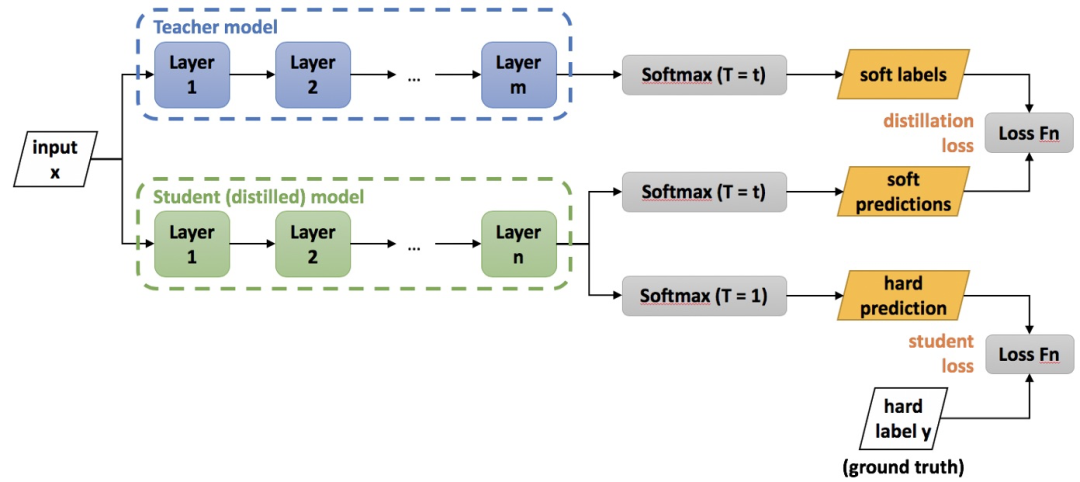
知识蒸馏——师生结构,在其他小模型上学习
参数共享——层与层间共享权重
多语言
数据集在不同语言间分布的非常不均匀,通常是英语数据集很多,其他语言的相对少些,繁体中文的话问题就更严重了。而 BERT 的预训练方法并没有语言限制,所以就有许多研究试图喂给预训练模型更多语言数据,期望能在下游任务上取得更好的成绩。
谷歌的 BERT-Multilingual 就是一例,在不添加中文数据的情况下,该模型在下游任务上的表现已经接近中文模型

有研究[2]对多语言版 BERT 在 SQuAD(英语阅读理解任务)和 DRCD(中文阅读理解任务)上进行了测试。最终证明可以取得接近 QANet 的效果,同时多语言模型不用将数据翻译成统一语言,这当然要比多一步翻译过程的版本要好。
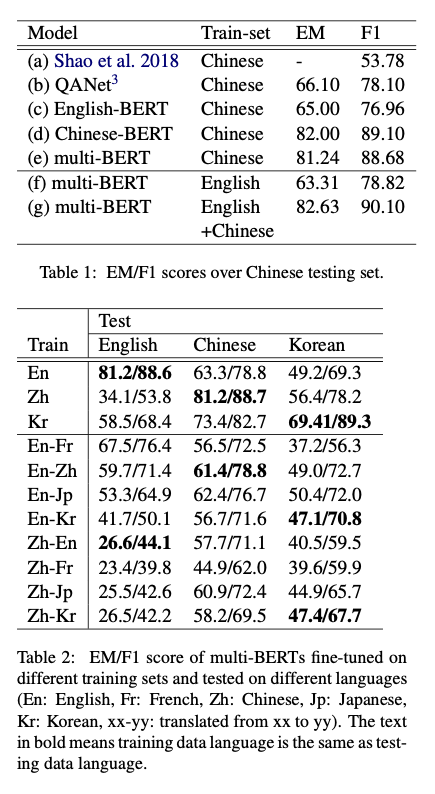
从上面的结果可以看出无论是用 Embedding 还是 Transformer 编码器,BERT 都学到了不同语言间的内在联系。另有研究[3]专门针对 BERT 联通不同语言的方式进行了分析。
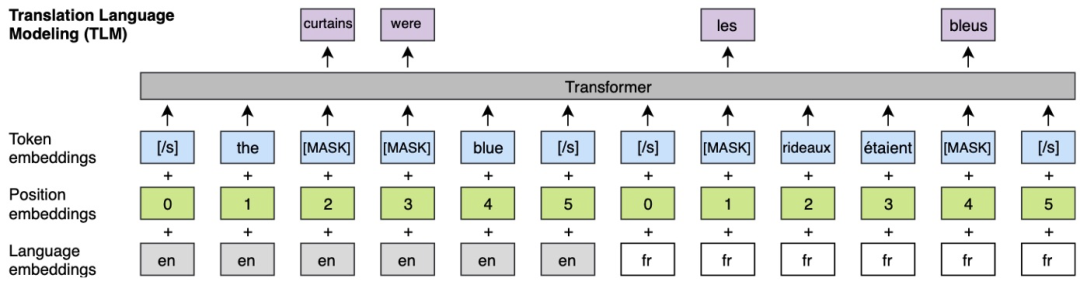
首先,在相同的 TLM 预训练模型中对不同语言建立关联
然后,通过控制是否共享组件来分析哪个部分对结果影响最大
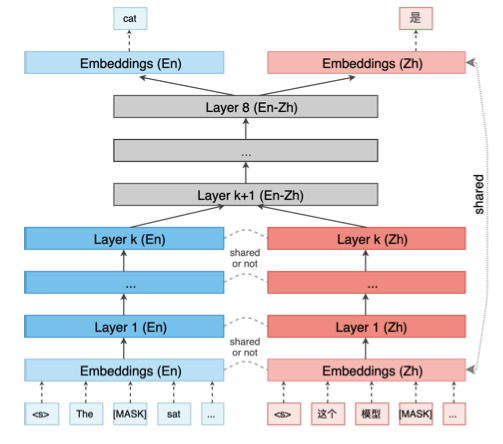
结果是模型间共享参数是关键
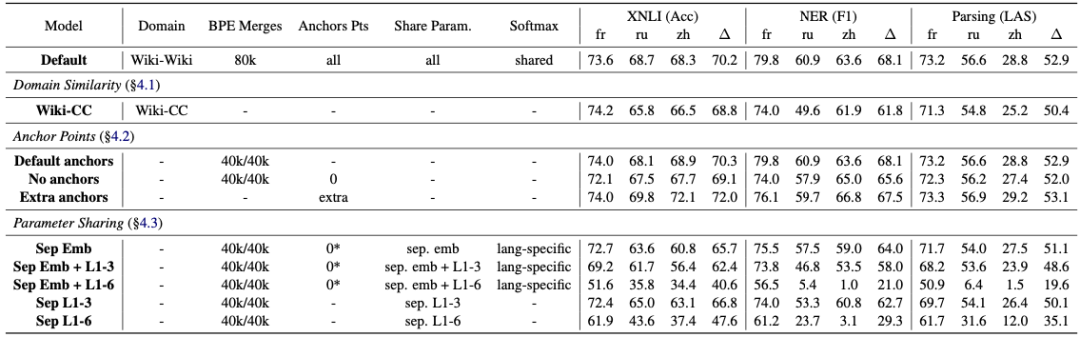
这是因为 BERT 是在学习词和相应上下文环境的分布,不同语言间含义相同的词,其上下文分布应该很接近

而 BERT 的参数就是在学习期间的分布,所以也就不难理解模型在多语言间迁移时的惊人表现了
越大越好?
尽管 BERT 采用了大模型,但直觉上数据越多,模型越大,效果也就应该更好。所以很多模型以此为改进方向
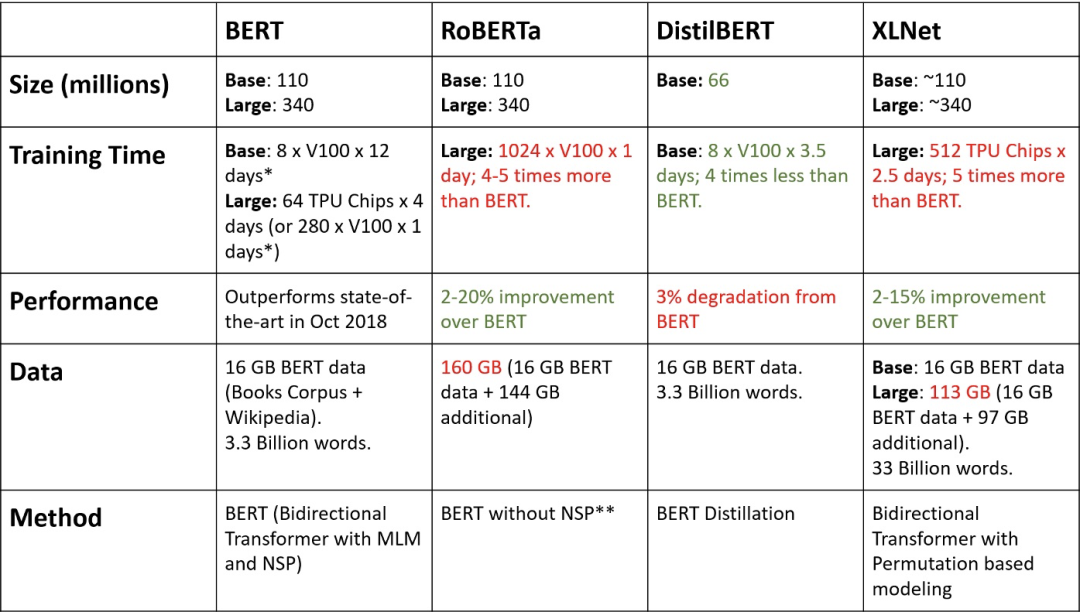
T5 更是凭借 TPU 和金钱的魔力攀上顶峰

然而更大的模型似乎并没有带来太多的回报
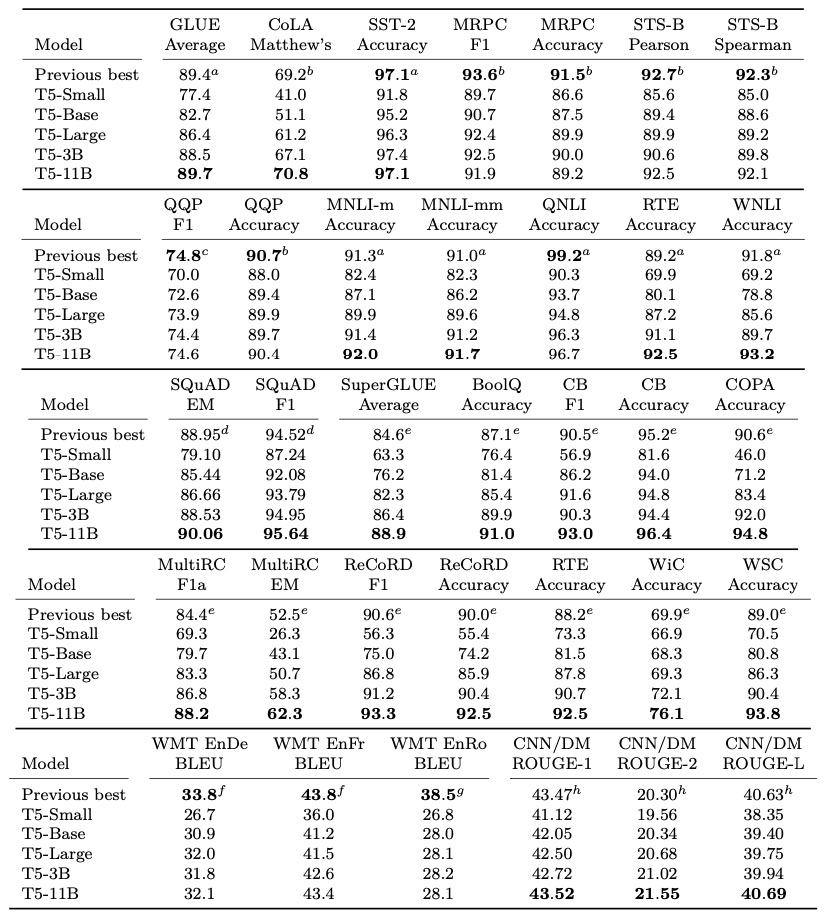
所以,简单增大模型规模并不是最高效的方法。
此外,选用不同的训练方法和目标也是一条出路。比如,ELECTRA 采用新型训练方法保证每个词都能参与其中,从而使得模型能更有效地学习表示(representation)
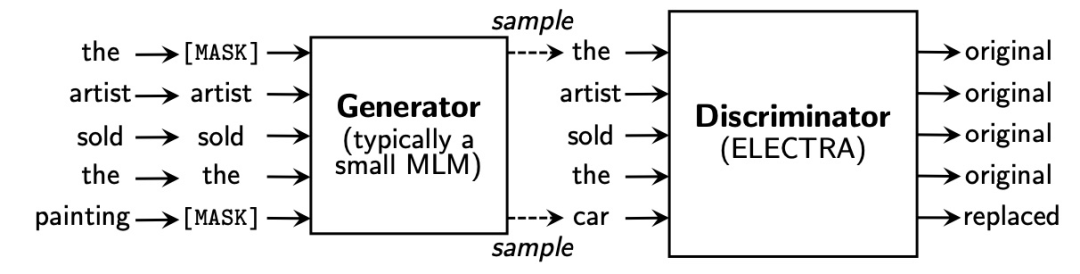
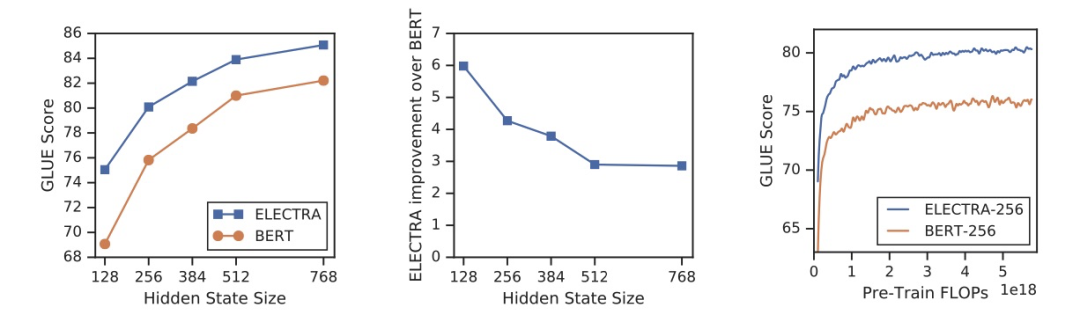
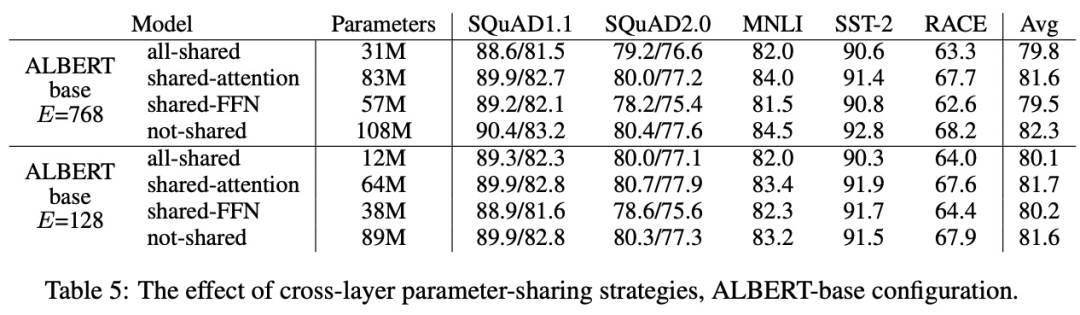
ALBERT 使用参数共享降低参数量,但对性能没有显著影响
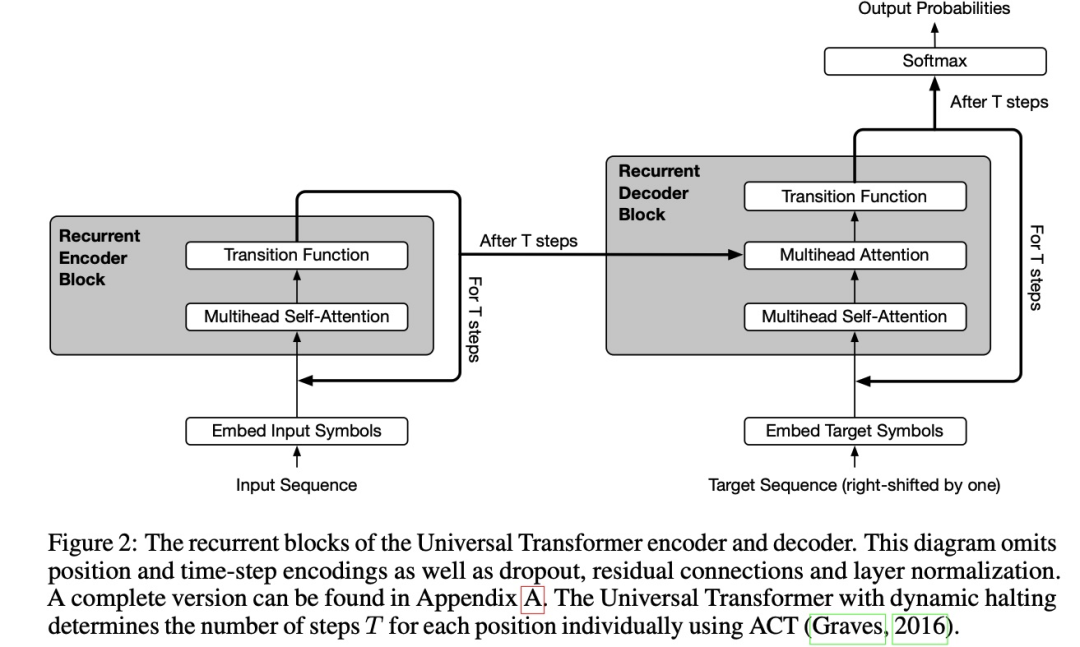
多任务
BERT 是在预训练时使用多任务,我们同样可以在微调时使用多任务。微软的用于自然语言理解的多任务深度神经网络[4](MTDNN)就是这么做的
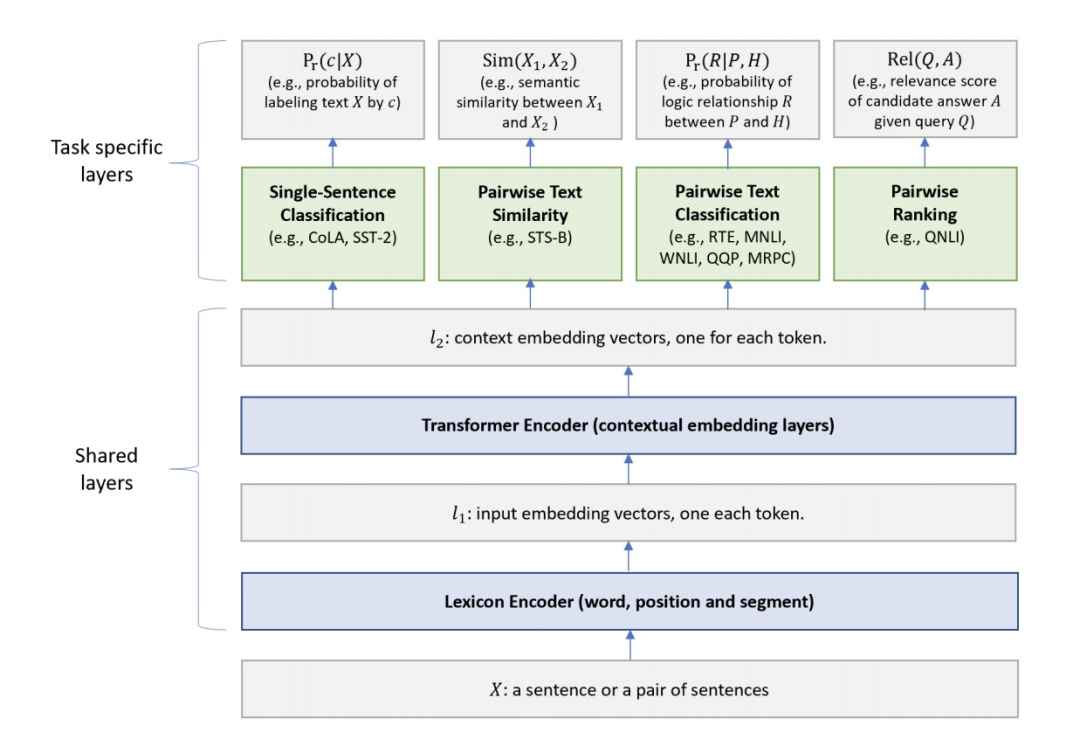
相交于 MTDNN,GPT-2 更加激进:不经微调直接用模型学习一切,只用给一个任务标识,其余的交给模型。效果出众但仍称不上成功
T5 对此做了平衡
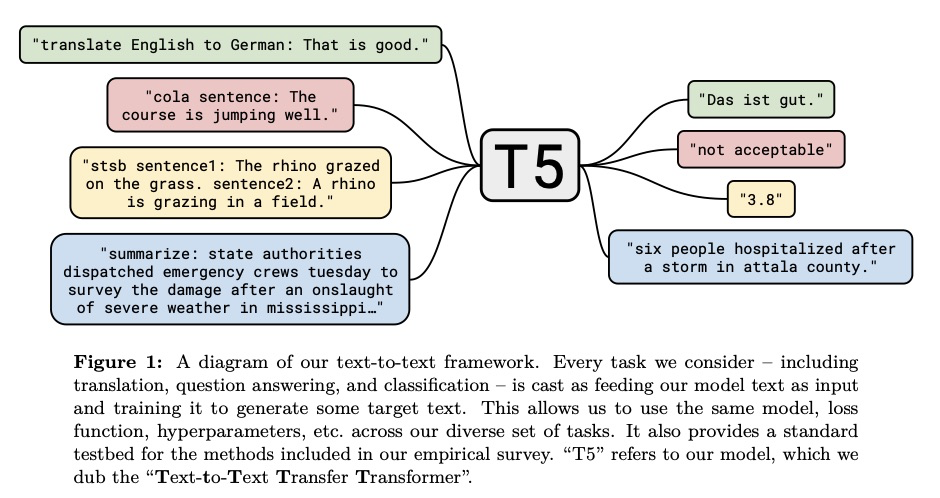
谷歌的 T5 类似于 GPT-2,训练一个生成模型来回答一切问题。同时又有点像 MTDNN,训练时模型知道它是在同时解决不同问题,它是一个训练/微调模型
同时,大体量预训练模型都面临相同的两个难题:数据不均衡和训练策略选定
不均衡数据
不同任务可供使用的数据量是不一致的,这导致数据量小的任务表现会很差。数据多的少采样,数据少的多采样是一种解决思路。BERT 对多语言训练采用的做法就是一例
为平衡这两个因素,训练数据生成(以及 WordPiece 词表生成)过程中,对数据进行指数平滑加权。换句话说,假如一门语言的概率是
,比如 意味着在混合了所有维基百科数据后, 21% 的数据是英文的。我们通过因子 S 对每个概率进行指数运算并重新归一化,之后从中采样。我们的实验中, ,所以像英语这样的富文本语言会被降采样,而冰岛语这样的贫文本语言会过采样。比如,原始分布中英语可能是冰岛语的 1000 倍,平滑处理后只有 100 倍
训练策略
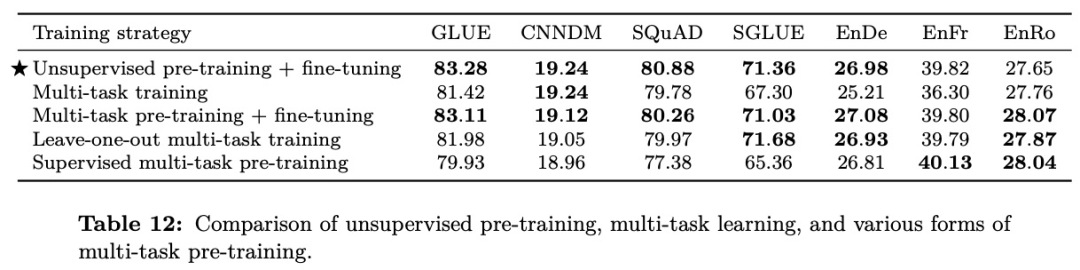
无监督预训练+微调:在 T5 预训练后对各任务进行微调
多任务训练:所有任务和 T5 预训练一同训练学习,并直接在各任务上验证结果
多任务预训练+微调:所有任务和 T5 预训练一同训练学习,然后对各任务微调训练数据,再验证结果
留一法多任务训练:T5 预训练和目标任务外的所有任务一同进行多任务学习,然后微调目标任务数据集,再验证结果
有监督多任务预训练:在全量数据上进行多任务训练,然后对各任务微调结果
可以看到先在海量数据上进行训练,然后对特定任务数据进行微调可以缓解数据不平衡问题。
审核编辑 :李倩
-
编码器
+关注
关注
45文章
4022浏览量
143730 -
模型
+关注
关注
1文章
3873浏览量
52339 -
nlp
+关注
关注
1文章
491浏览量
23367
原文标题:BERT 之后的故事
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Aigtek高压放大器在电流体动力喷印实验研究中的应用

[VirtualLab] 非球面透镜后焦点研究
第九届中国研究生创芯大赛新思科技赛题发布
一文盘点功率放大器五大热门的应用方向!

TDK SMD Transformers E13 EMHV系列:高性能贴片变压器的卓越之选
伺服系统回零运动方向与实际规划方向相反问题处理
2026年NVIDIA研究生奖学金名单公布
[企业新闻]坚定方向 持续改进
射频功率放大器赋能:双极射频溶脂实验研究的创新应用
两部门:支持人工智能、先进存储、三维异构集成芯片等前沿技术方向基础研究

基于LabVIEW的鼠标滑动方向检测教程
复合材料扭力测试力学性能研究




评论