 命名实体识别实践 - CRF
命名实体识别实践 - CRF

1
条件随机场-CRF
CRF,英文全称为Conditional Random Field, 中文名为条件随机场,是给定一组输入随机变量条件下另一组输出随机变量的条件概率分布模型,其特点是假设输出随机变量构成马尔可夫(Markov)随机场。
较为简单的条件随机场是定义在线性链上的条件随机场,称为线性链条件随机场(linear chain conditional random field)。
线性链条件随机场可以用于序列标注等问题,需要解决的命名实体识别(NER)任务正好可通过序列标注方法解决。
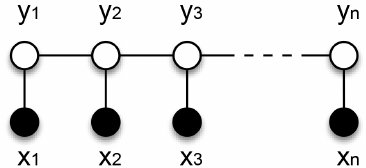
在条件概率模型P(Y|X)中,Y是输出变量,表示标记序列(或状态序列),X是输入变量,表示需要标注的观测序列。
训练时,利用训练数据集通过极大似然估计或正则化的极大似然估计得到条件概率模型p(Y|X); 预测时,对于给定的输入序列x,求出条件概率p(y|x)最大的输出序列y
利用线性链CRF来做实体识别的时候,需要假设每个标签 的预测同时依赖于先前预测的标签 和 的词语输入序列,如下图所示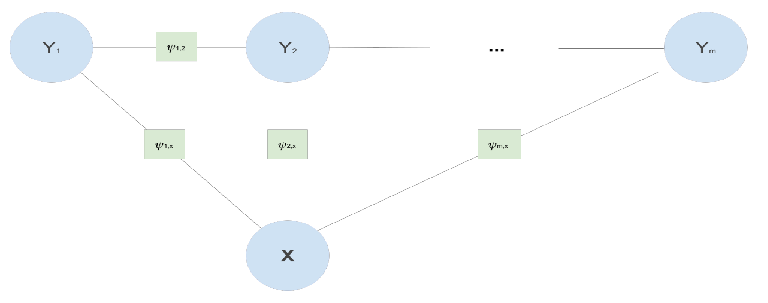 每个 NER标签仅依赖于其直接前前继和后继标签以及 x
每个 NER标签仅依赖于其直接前前继和后继标签以及 x
CRF是一种选择因子的特定方式,换句话说,就是特征函数。定义因子的 CRF 方法是采用实值特征函数 与参数 和 的线性组合的指数,下面是特征函数与权重参数在时间步上是对应的:
关于Linear-chain CRF的训练推导,可以查看文章:条件随机场CRF(一)从随机场到线性链条件随机场
2
实践1:基于CRF++实现NER
CRF++简介
CRF++是著名的条件随机场的开源工具,也是目前综合性能最佳的CRF工具,采用C++语言编写而成。其最重要的功能我认为是采用了特征模板。这样就可以自动生成一系列的特征函数,而不用我们自己生成特征函数,我们要做的就是寻找特征,比如词性等。 官网地址:http://taku910.github.io/crfpp/
官网地址:http://taku910.github.io/crfpp/
安装
CRF++的安装可分为Windows环境和Linux环境下的安装。关于Linux环境下的安装,可以参考文章:CRFPP/CRF++编译安装与部署 。在Windows中CRF++不需要安装,下载解压CRF++0.58文件即可以使用
训练语料创建
在训练之前需要将标注数据转化为CRF++训练格式文件:
分两列,第一列是字符,第二例是对应的标签,中间用 分割。
比如标注方案采用BISO,效果如下:

模板
模板是使用CRF++的关键,它能帮助我们自动生成一系列的特征函数,而不用我们自己生成特征函数,而特征函数正是CRF算法的核心概念之一。一个简单的模板文件如下: 在这里,我们需要好好理解下模板文件的规则。T**:%x[#,#]中的T表示模板类型,两个"#"分别表示相对的行偏移与列偏移。一共有两种模板:
在这里,我们需要好好理解下模板文件的规则。T**:%x[#,#]中的T表示模板类型,两个"#"分别表示相对的行偏移与列偏移。一共有两种模板:
训练
crf_learn-f3-c4.0-m100templatetrain.datacrf_model>train.rst
其中,template为模板文件,train.data为训练语料,-t表示可以得到一个model文件和一个model.txt文件,其他可选参数说明如下:
-f,–freq=INT使用属性的出现次数不少于INT(默认为1) -m,–maxiter=INT设置INT为LBFGS的最大迭代次数(默认10k) -c,–cost=FLOAT设置FLOAT为代价参数,过大会过度拟合(默认1.0) -e,–eta=FLOAT设置终止标准FLOAT(默认0.0001) -C,–convert将文本模式转为二进制模式 -t,–textmodel为调试建立文本模型文件 -a,–algorithm=(CRF|MIRA)选择训练算法,默认为CRF-L2 -p,–thread=INT线程数(默认1),利用多个CPU减少训练时间 -H,–shrinking-size=INT设置INT为最适宜的跌代变量次数(默认20) -v,–version显示版本号并退出 -h,–help显示帮助并退出
输出信息
iter:迭代次数。当迭代次数达到maxiter时,迭代终止 terr:标记错误率 serr:句子错误率 obj:当前对象的值。当这个值收敛到一个确定值的时候,训练完成 diff:与上一个对象值之间的相对差。当此值低于eta时,训练完成
预测
在训练完模型后,我们可以使用训练好的模型对新数据进行预测,预测命令格式如下:
crf_test-mcrf_modeltest.data>test.rstt
-m model表示使用我们刚刚训练好的model模型,预测的数据文件为test.data> test.rstt 表示将预测后的数据写入到test.rstt 中。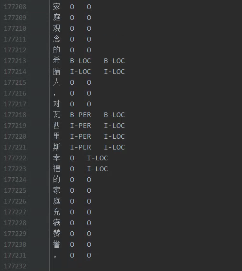
3
实践2:基于sklearn_crfsuite实现NER
sklearn_crfsuite简介
sklearn-crfsuite是基于CRFsuite库的一款轻量级的CRF库。该库兼容sklearn的算法,因此可以结合sklearn库的算法设计实体识别系统。sklearn-crfsuite不仅提供了条件随机场的训练和预测方法还提供了评测方法。
https://sklearn-crfsuite.readthedocs.io/en/latest/#
安装:pip install sklearn-crfsuite
特征与模型创建
特征构造: 模型初始化
模型初始化
crf_model=sklearn_crfsuite.CRF(algorithm='lbfgs',c1=0.25,c2=0.018,max_iterations=100, all_possible_transitions=True,verbose=True) crf_model.fit(X_train,y_train)
完整代码如下:
importre
importsklearn_crfsuite
fromsklearn_crfsuiteimportmetrics
importjoblib
importyaml
importwarnings
warnings.filterwarnings('ignore')
defload_data(data_path):
data=list()
data_sent_with_label=list()
withopen(data_path,mode='r',encoding="utf-8")asf:
forlineinf:
ifline.strip()=="":
data.append(data_sent_with_label.copy())
data_sent_with_label.clear()
else:
data_sent_with_label.append(tuple(line.strip().split("")))
returndata
defword2features(sent,i):
word=sent[i][0]
features={
'bias':1.0,
'word':word,
'word.isdigit()':word.isdigit(),
}
ifi>0:
word1=sent[i-1][0]
words=word1+word
features.update({
'-1:word':word1,
'-1:words':words,
'-1:word.isdigit()':word1.isdigit(),
})
else:
features['BOS']=True
ifi>1:
word2=sent[i-2][0]
word1=sent[i-1][0]
words=word1+word2+word
features.update({
'-2:word':word2,
'-2:words':words,
'-3:word.isdigit()':word1.isdigit(),
})
ifi>2:
word3=sent[i-3][0]
word2=sent[i-2][0]
word1=sent[i-1][0]
words=word1+word2+word3+word
features.update({
'-3:word':word3,
'-3:words':words,
'-3:word.isdigit()':word1.isdigit(),
})
ifi< len(sent)-1:
word1 = sent[i+1][0]
words = word1 + word
features.update({
'+1:word': word1,
'+1:words': words,
'+1:word.isdigit()': word1.isdigit(),
})
else:
features['EOS'] = True
if i < len(sent)-2:
word2 = sent[i + 2][0]
word1 = sent[i + 1][0]
words = word + word1 + word2
features.update({
'+2:word': word2,
'+2:words': words,
'+2:word.isdigit()': word2.isdigit(),
})
if i < len(sent)-3:
word3 = sent[i + 3][0]
word2 = sent[i + 2][0]
word1 = sent[i + 1][0]
words = word + word1 + word2 + word3
features.update({
'+3:word': word3,
'+3:words': words,
'+3:word.isdigit()': word3.isdigit(),
})
return features
def sent2features(sent):
return [word2features(sent, i) for i in range(len(sent))]
def sent2labels(sent):
return [ele[-1] for ele in sent]
train=load_data('data/train.txt')
valid=load_data('data/train.txt')
test=load_data('data/train.txt')
print(len(train),len(valid),len(test))
sample_text=''.join([c[0] for c in train[0]])
sample_tags=[c[1] for c in train[0]]
print(sample_text)
print(sample_tags)
X_train = [sent2features(s) for s in train]
y_train = [sent2labels(s) for s in train]
X_dev = [sent2features(s) for s in valid]
y_dev = [sent2labels(s) for s in valid]
# **表示该位置接受任意多个关键字(keyword)参数,在函数**位置上转化为词典 [key:value, key:value ]
crf_model = sklearn_crfsuite.CRF(algorithm='lbfgs',c1=0.25,c2=0.018,max_iterations=100,
all_possible_transitions=True,verbose=True)
crf_model.fit(X_train, y_train)
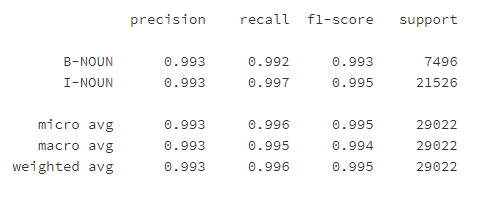
训练效果如下:
labels=list(crf_model.classes_)
labels.remove("O")
y_pred=crf_model.predict(X_dev)
metrics.flat_f1_score(y_dev,y_pred,
average='weighted',labels=labels)
sorted_labels=sorted(labels,key=lambdaname:(name[1:],name[0]))
print(metrics.flat_classification_report(
y_dev,y_pred,labels=sorted_labels,digits=3
))
完整代码 https://www.heywhale.com/home/competition/6216f74572960d0017d5e691/content/
审核编辑 :李倩
-
模型
+关注
关注
1文章
3648浏览量
51693 -
变量
+关注
关注
0文章
615浏览量
29363
原文标题:命名实体识别实践 - CRF
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
自然语言基础技术之命名实体识别相对全面的介绍
HanLP分词命名实体提取详解
Hanlp分词之CRF中文词法分析详解
基于结构化感知机的词性标注与命名实体识别框架
HanLP-命名实体识别总结
基于神经网络结构在命名实体识别中应用的分析与总结

思必驰中文命名实体识别任务助力AI落地应用
新型中文旅游文本命名实体识别设计方案

命名实体识别的迁移学习相关研究分析

基于字语言模型的中文命名实体识别系统






 工商网监
工商网监
评论