 基于序列标注的实体识别所存在的问题
基于序列标注的实体识别所存在的问题

写在前面
今天要跟大家分享的是西湖大学张岳老师2018年发表在顶会ACL上的一篇中文实体识别论文Lattice LSTM。
论文名称:《Chinese NER Using Lattice LSTM》
论文链接:https://arxiv.org/pdf/1805.02023.pdf
代码地址:https://github.com/jiesutd/LatticeLSTM
分享这个工作主要原因是:这个工作本身质量比较高,可以说是利用词汇增强中文NER的开篇之作,并且思路清晰,创新有理有据。
本篇文章主要内容将围绕下图中的两点展开:

1. 基于序列标注的实体识别所存在的问题
如下图,这部分主要包含两个内容,即:经典的LSTM-CRF实体识别模型及该类模型所存在的问题。

1.1 经典LSTM-CRF模型
实体识别通常被当作序列标注任务来做,序列标注模型需要对实体边界和实体类别进行预测,从而识别和提取出相应的命名实体。在BERT出现以前,实体识别的SOTA模型是LSTM+CRF,模型本身很简单:
首先利用嵌入方法将句子中的每个token转化为向量再输入LSTM(或BiLSTM);
然后使用LSTM对输入的信息进行编码;
最后利用CRF对LSTM的输出结果进行序列标注。
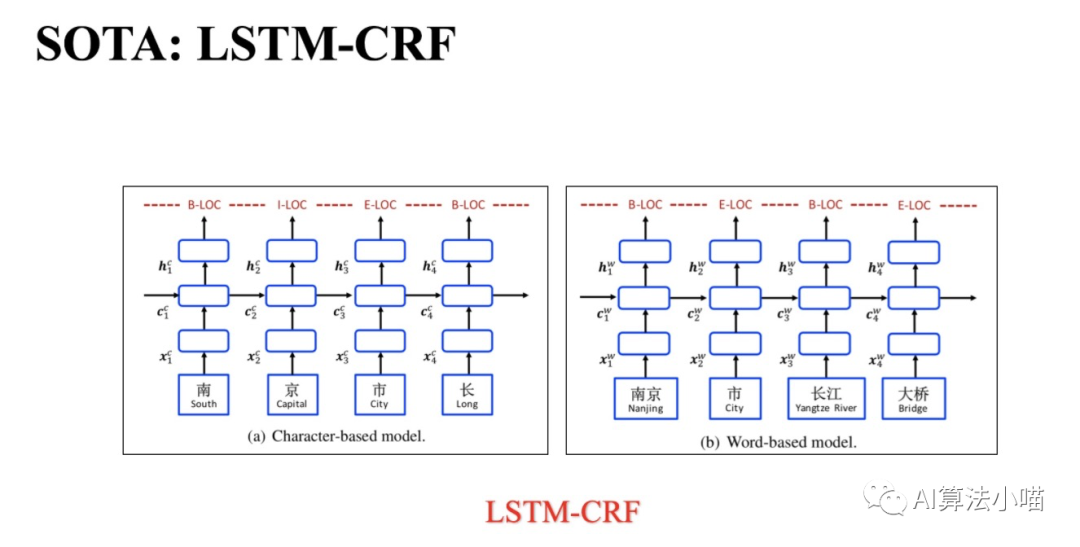
LSTM+CRF用在中文NER上,又可进一步分为两种:若token是词,那么模型就属于Word-based model;若token是字,那么模型就属于Character-based Model。
(注:BERT+LSTM+CRF主要是将嵌入方法从Word2vec换成了BERT。)
1.2 误差传播与歧义问题

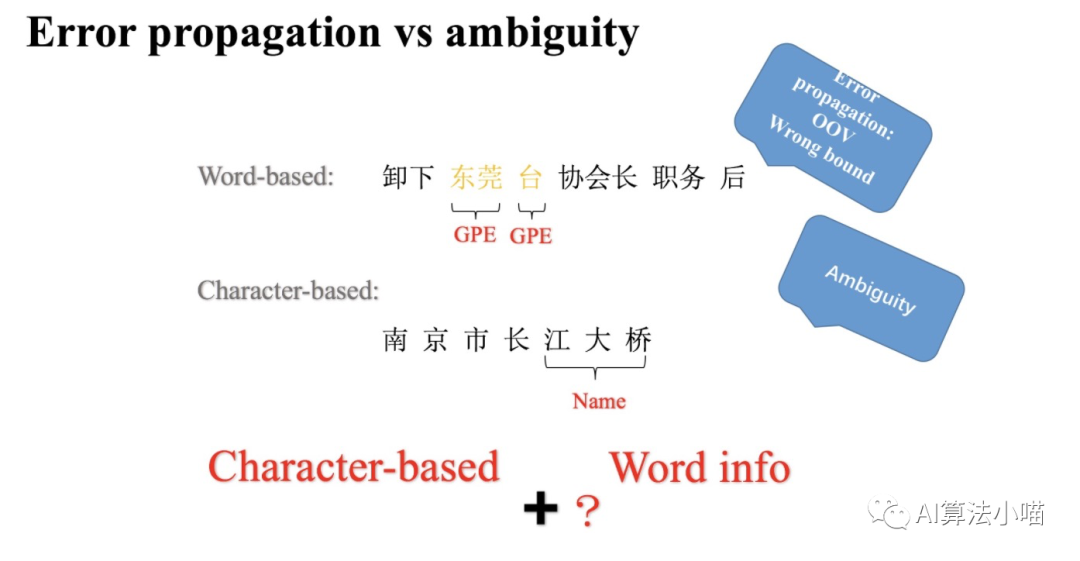
Word-based model存在误差传递问题
Word-based model做实体识别需要先分词,然后再对词序列进行实体识别即词序列标注。词汇的边界决定了实体的边界,因此一旦出现分词错误就会影响实体边界的判定。比如上图中,利用分词工具,“东莞台协” 和 ”会长“ 被拆分成了“东莞”、“台”、”协会长“,最终导致 ”东莞台“ 被识别为了GPE。换句话说,Word-based model具有和其他两阶段模型同样的误差传递问题。
Character-based model存在歧义问题
既然分词会有问题,那就不分词。Character-based model直接在字的粒度上进行实体识别即字序列标注。许多研究工作表明,在中文NER上基于字的方法优于基于词的方法。但是,相比词单字不具备完整语义。没有利用句子里的词的信息,难以应对歧义问题,识别结果可能差强人意。如上图,“会” 字本来应该和 “长” 一起组成 “会长” ,但是最终模型却将 “会” 与 “东莞台协” 视为一个语块儿,并将 “东莞台协会” 预测为ORG。
1.3 思考
既然Character-based model、Word-based model各有优缺点,那是否可以结合二者进行互补呢?换句话说,我们在Character-based model里加入词信息,这样是不是就可以既利用了词信息,又不会因为分词错误影响识别结果呢?实际上,Lattice LSTM正是这样做的。接下来我们一起跟随文章的后续内容来学习Lattice LSTM。
2. 模型细节
这一节我们首先会介绍最简单的词信息利用方方法,然后再对Lattice LSTM进行详细介绍。

2.1 简单直接的拼接法
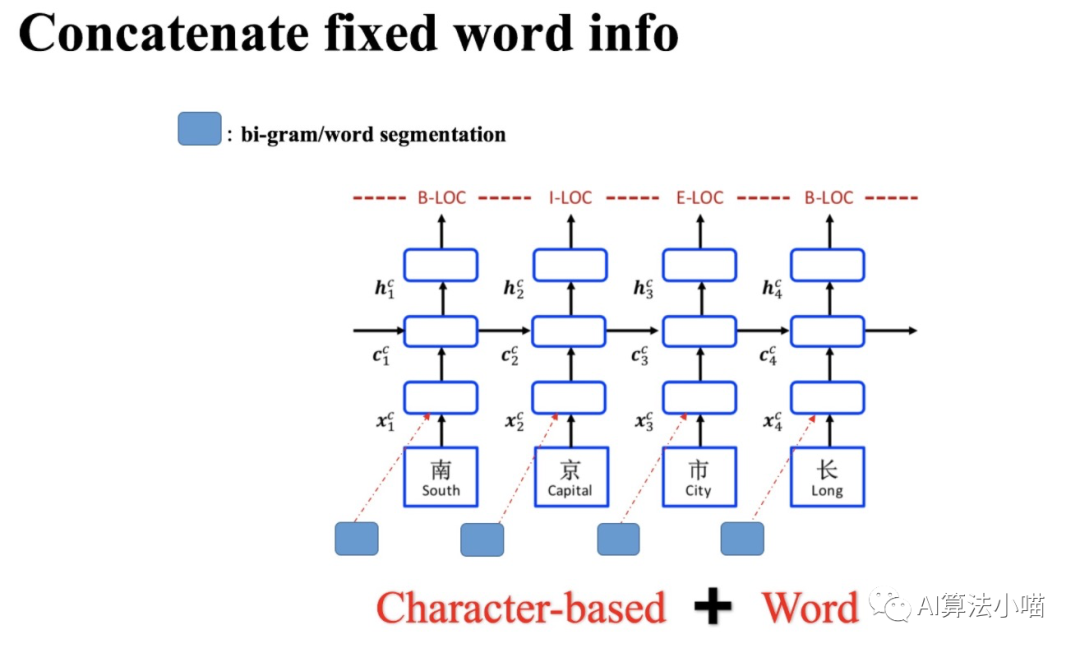
如上图所示,最容易想到同时也是最简单的词信息利用方法就是直接拼接词表征与字向量或者直接拼接词表征与LSTM的输出。16年的论文《A Convolution BiLSTM Neural Network Model for Chinese Event Extraction》[1]就采用了这样的方法构建了中文事件抽取模型,其模型结构如下图所示:
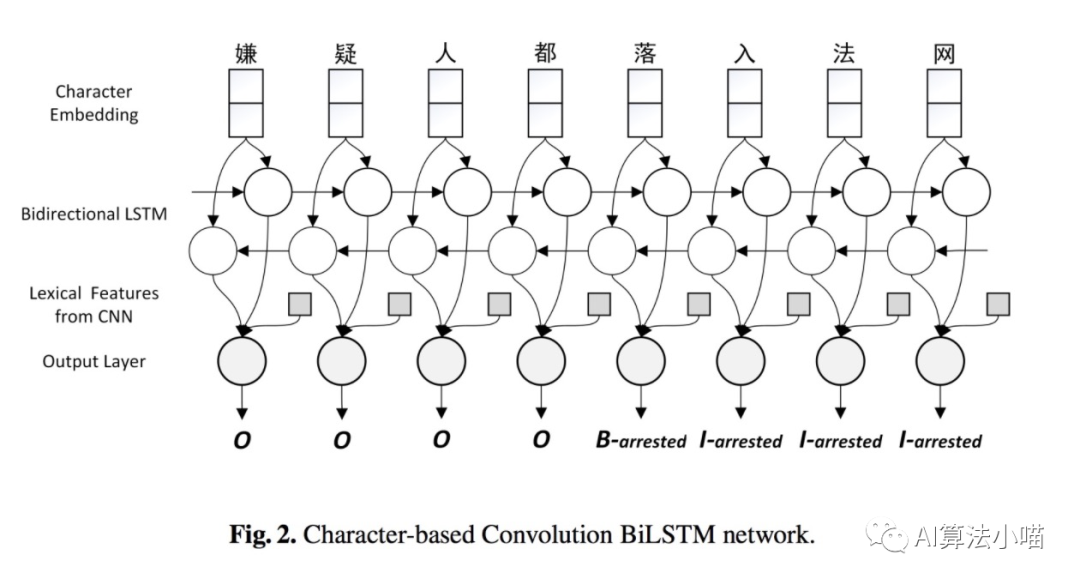
当然这里词表征可通过Word2Vec、Glove等词向量模型获得。也可以如16年的那篇事件抽取论文一样利用CNN进一步卷积获得更上层的Local Context features,再将其拼接到模型中:
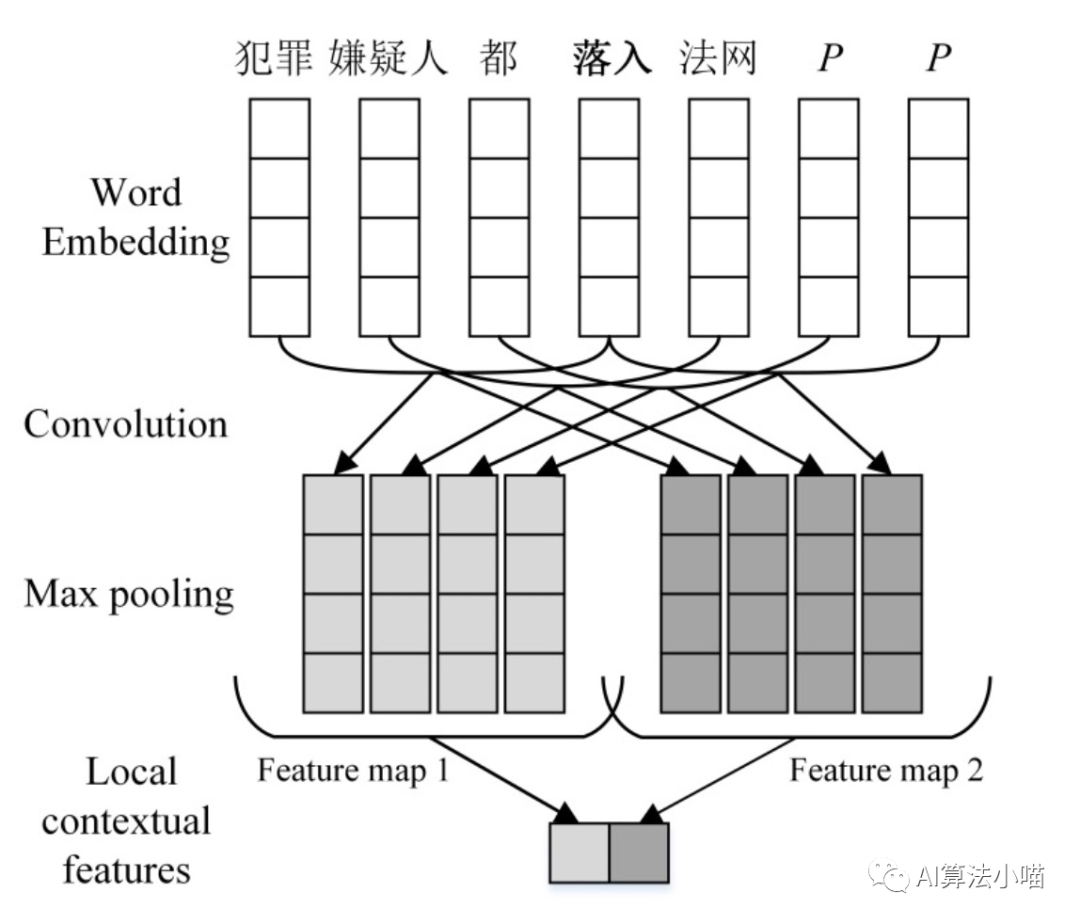
当然这不是本文的重点,我们关注的是Lattice LSTM是如何引入词信息的。
2.2 Lattice 与潜在词
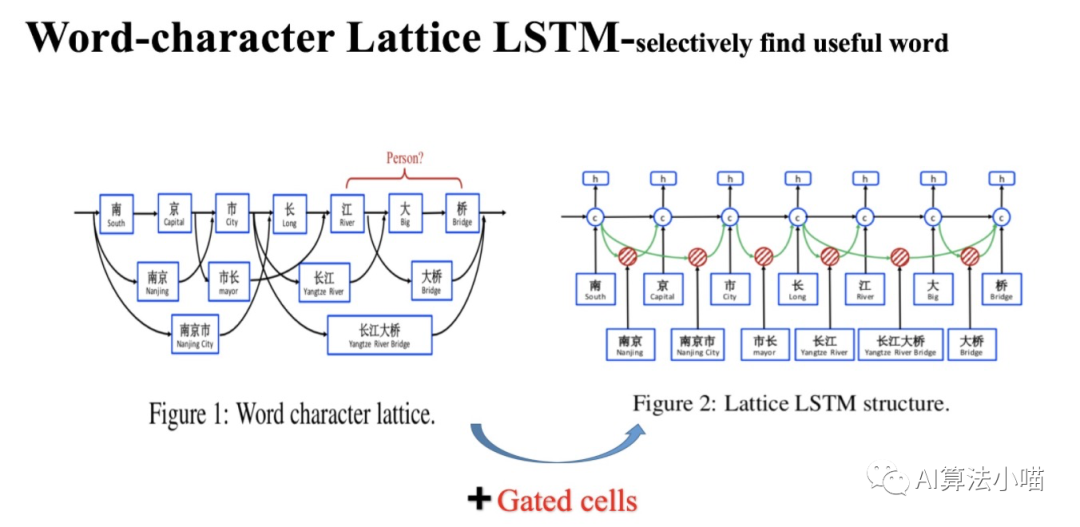
Lattice LSTM模型结构如上图右侧所示。在正式开始介绍Lattice LSTM前,我们先来看看上图左半部分。
(1)Lattice LSTM 名字来由
我们可以发现在上图左侧所示网络中,除主干部分基于字的LSTM外,还连接了许多「格子」,每个「格子」里各含有一个潜在的词,这些潜在词所含有的信息将会与主干LSTM中相应的Cell融合,看起来像一个「网格(Lattice)」。所以论文模型的名字就叫做Lattice LSTM,也就是有网格结构的LSTM模型。
(2)词典匹配获得潜在词
网格中的这些潜在词是通过匹配输入文本与词典获得的。比如通过匹配词典, “南京市长江大桥”一句中就有“南京”、“市长”,“南京市”,“长江”,“大桥“,“长江大桥”等词。
(3)潜在词的影响
首先,“南京市长江大桥” 一句的正确结果应当是 “南京市-地点”、“长江大桥-地点”。如果我们直接利用Character-based model来进行实体识别,可能获得的结果是:“南京-地点”、“市长-职务”、“江大桥-人名”。现在利用词典信息获得了文本句的潜在词:“南京”、“市长”,“南京市”,“长江”,“大桥“,“长江大桥” 等潜在词。其中,“长江”、“大桥” 与 “长江大桥” 等词信息的引入有利于模型,可以帮助模型避免犯 “江大桥-人名” 这样的错误;而 “市长” 这个词的引入却可能会带来歧义从而误导模型,导致 “南京-地点”,“市长-职务” 这样的错误。
换句话说,通过词典引入的词信息有的具有正向作用,有的则不然。当然,人为去筛除对模型不利的词是不可能的,所以我们希望把潜在词通通都丢给模型,让模型自己去选择有正向作用的词,从而避免歧义。Lattice LSTM正是这么做的:它在Character-based LSTM+CRF的基础上,将潜在词汇信息融合进去,从而使得模型在获得字信息的同时,也可以有效地利用词的先验信息。
2.3 Lattice LSTM 模型细节
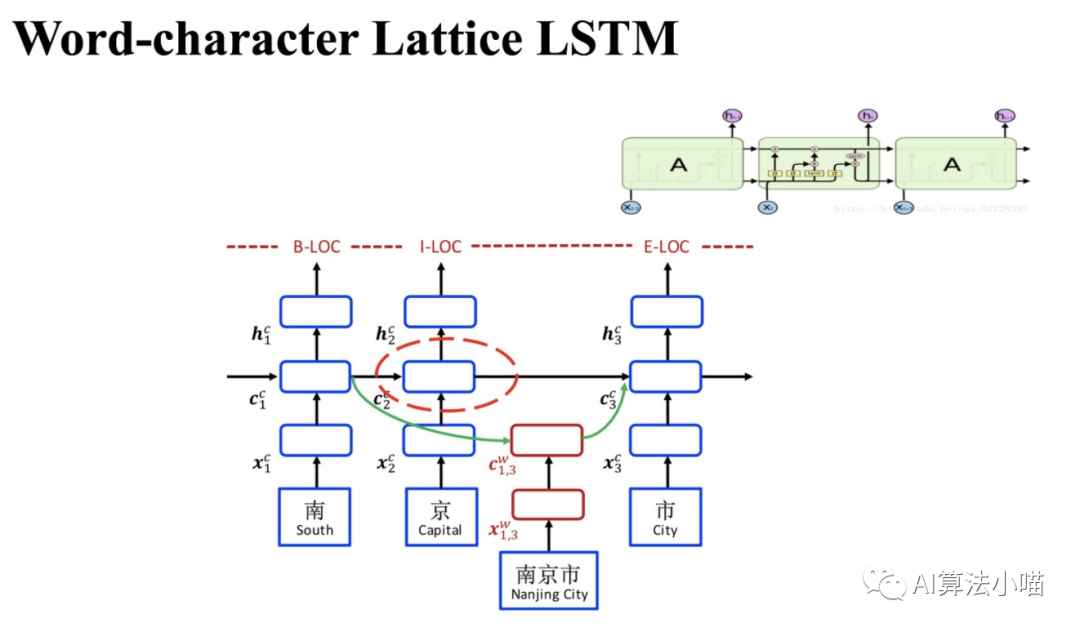
如上图所示,Lattice LSTM模型的主干部分是基于字的LSTM-CRF(Character-based LSTM+CRF):
若当前输入的字在词典中不存在任何以它结尾的词时:主干上Cell之间的传递就和正常的LSTM一样。也就是说,这个时候Lattice LSTM退化成了基本LSTM。
若当前输入的字在词典中存在以它结尾的词时:需要通过红色Cell (见2.2节图右侧)引入相关的潜在词信息,然后与主干上基于字的LSTM中相应的Cell进行融合。
接下来,我们先简单展示下LSTM的基本单元,再介绍红色Cell,最后再介绍信息融合部分。
2.3.1 LSTM 单元
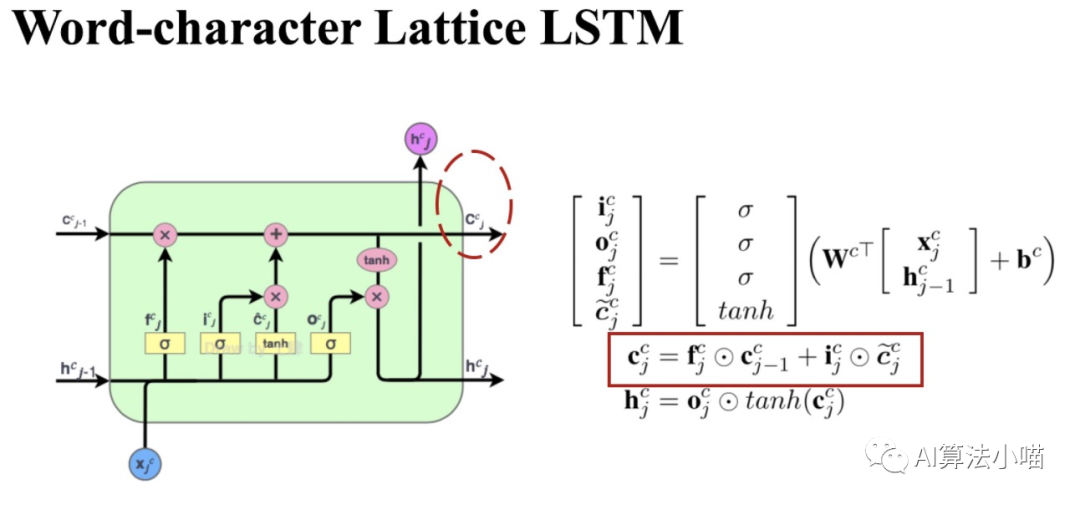
上图左侧展示了一个LSTM 单元(Cell)的内部结构,右侧展示了Cell的计算过程。在每个Cell中都有三个门控,即输入门、遗忘门和输出门。如上图右侧计算公式所示,这三个门实际上是0~1的小数,其值是根据当前时刻输入 和前一时刻Cell的输出的hidden state计算得到的:
输入门:决定当前输入有多少可以加入Cell State,即 ;
遗忘门:决定Cell State要保留多少信息,即 。
输出门:决定更新后的Cell State有多少可以被输出,即 。
纯粹的基于字的LSTM可以完全基于上述计算过程去计算,而Lattice LSTM则有所不同。
2.3.2红色Cell
前面我们提过「如果当前字在词典中存在以它结尾的词时,需要通过红色Cell引入相关潜在词信息,与主干上基于字的LSTM中相应Cell进行融合」。以下图中 "市" 字为例,句子中潜在的以它结尾的词有:"南京市"。所以,对于"市"字对应的Cell而言,还需要考虑 “南京市” 这个词的信息。
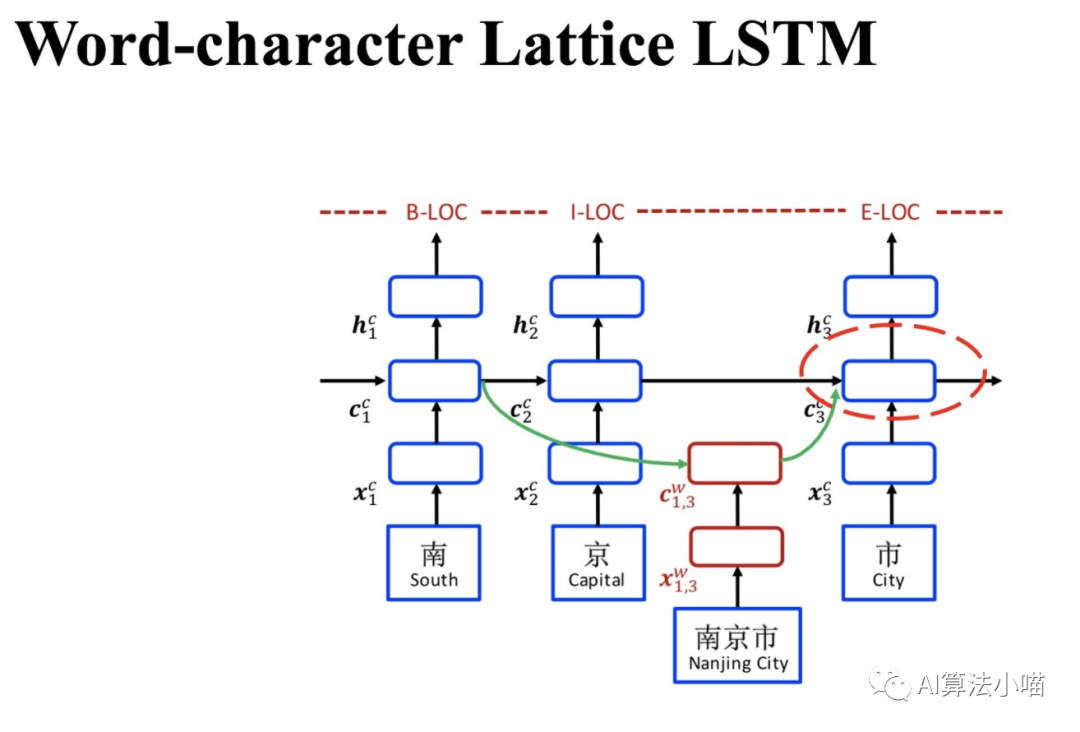
红色Cell的内部结构与主干上LSTM的Cell很类似。接下来,我们具体来看下红色Cell内部计算过程。
(1) 红色Cell 的输入
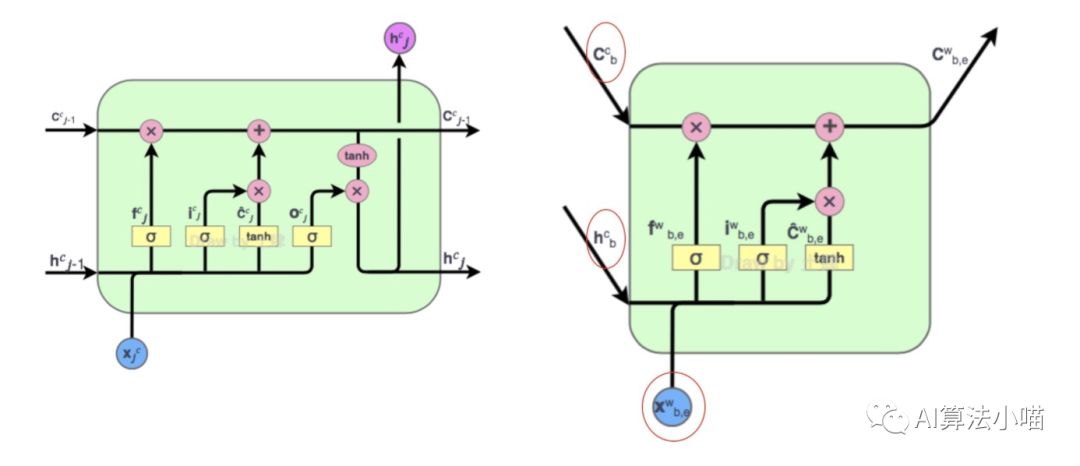
与上图左侧LSTM的Cell对比,上图右侧红色Cell有两种类型的输入:
潜在词的首字对应的LSTM单元输出的Hidden State以及Cell State
潜在词的词向量。
(2) 红色Cell 的输出
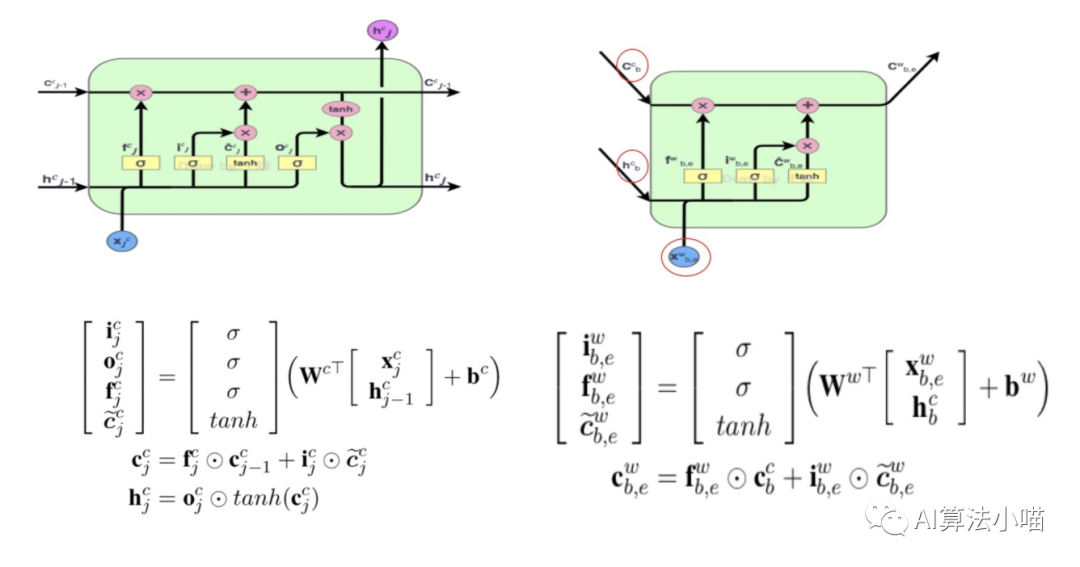
可以发现,因为序列标记是在字级别,所以与左侧LSTM的Cell相比,红色Cell没有输出门,即它不输出hidden state。
以“市”字为例,其潜在词为“南京市“,所以、 来自于"南”字, 代表“南京市”的词向量,红色Cell内部具体计算过程如下图右侧所示:
依托 “南” 字的hidden state与 “南京市” 的词向量 计算输入门 、遗忘门 以及状态更新量 :
依托 “南” 字的Cell state、与 “南京市” 相关的状态更新量 计算 “南京市“ 的Cell State:
最终红色Cell只会向 "市" 字传递Cell State。
2.3.3 信息融合
(1)潜在词的输入门
现在对于主干上的Cell来说,除状态更新量 外,还多了一个来自潜在词的Cell State。潜在词的信息不会全部融入当前字的 Cell,需要进行取舍,所以Lattice LSTM设计了额外的输入门,其计算如下:
(2) 加权融合
前面我们举的例子中都只有一个潜在词。但实际上,对部分字来说可能会在词典中匹配上很多词,例如 “桥” 这个字就可以在词典中匹配出 “大桥” 和 “长江大桥” 。为了将这些潜在词与字信息融合,Lattice LSTM做了一个类似Attention的操作:
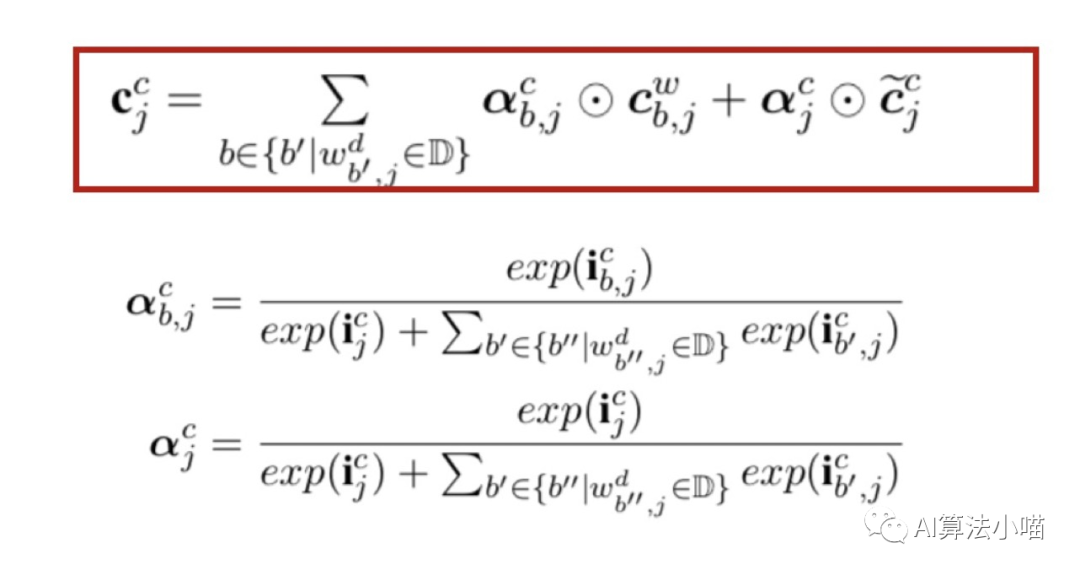
简单地说,就是当前字相应的输入门和所有以当前字为尾字的候选词的输入门做归一计算出权重,然后利用计算出的权重进行向量加权融合。
以 “桥” 字为例,它有两个潜在词,即 “长江大桥” 与 “大桥” 。那么对 “桥” 字而言,它会收到三对值,分别是:“桥” 字的输入门 与 状态 ;潜在词 "长江大桥" 相关的输入门 与Cell State;潜在词 "大桥" 相关的输入门 与Cell State,为了获得最终 “桥” 的hidden State,需要经过如下计算:
"长江大桥" 的权重:
“大桥” 的权重:
“桥“ 的权重:
加权融合获得“桥“ 的Cell state:
“桥“ 的hidden state:
3. 实验
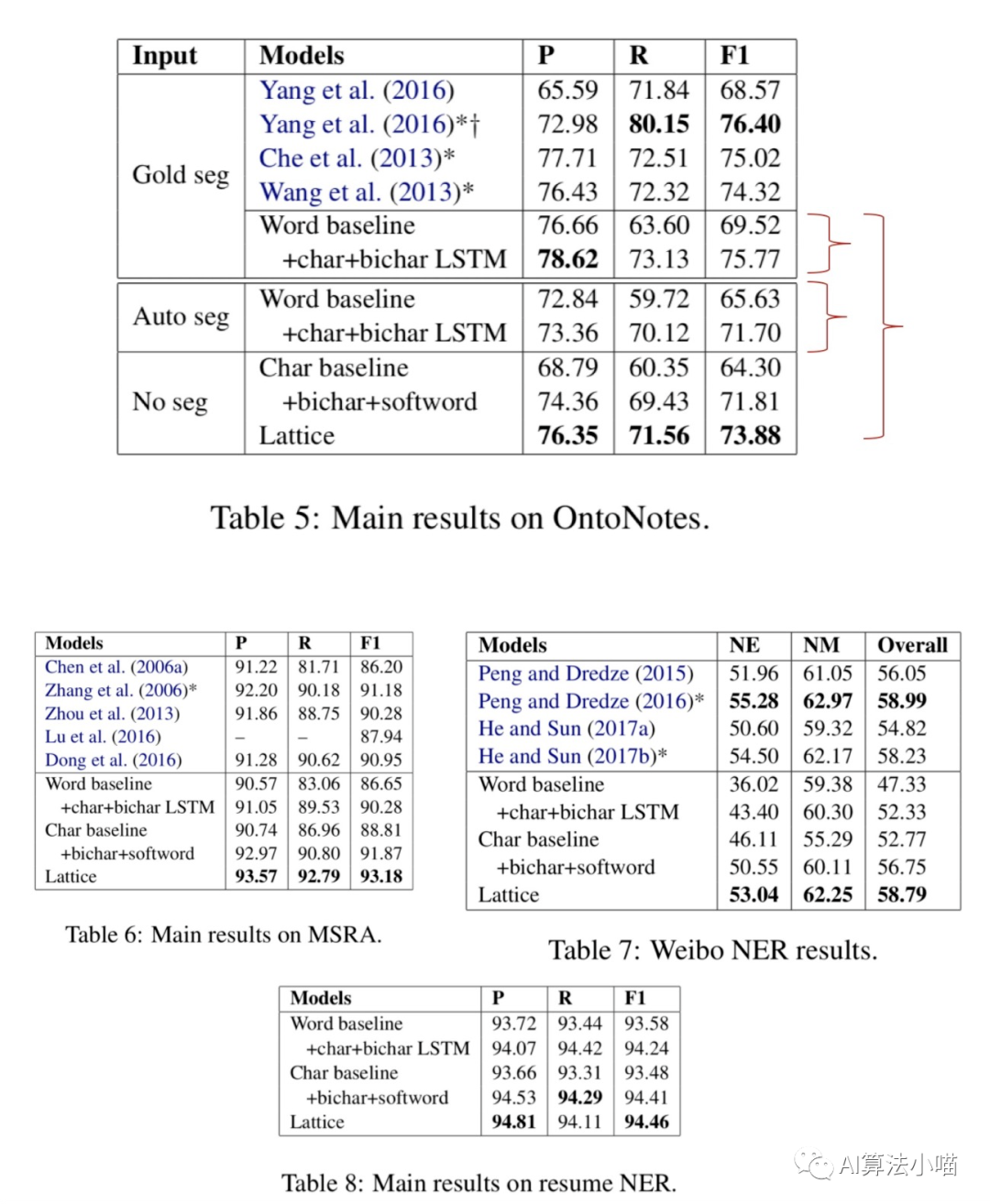
论文在Onto Notes、MSRA、微博NER、简历这4个数据集上进行了实验。从实验结果可以看出Lattice LSTM比其他对比方法有一定的提升。本文不深入探讨实验部分,感兴趣的读者可下载论文原文进行阅读。
总结
今天我们分享了中文实体识别模型Lattice LSTM,这是中文NLP领域非常重要的人物~张岳老师他们的工作。没记错的话,18年跟随导师参加NLPCC会议时,第一次见到张岳老师,深刻感觉张岳老师除了学术能力强以外,为人也非常真诚,很nice。
对NLP感兴趣的读者可以关注下张岳教授他们的其他工作。当然还有国内NLP领域的其他大师的工作,比如刘知远老师、车万翔老师、刘挺老师、孙茂松老师、邱锡鹏老师等等。想要往科研方向深入的,也可以申请去他们那里读博。当然每个老师研究方向各有侧重点,我记得当年关注到刘知远老师是因为他们的知识图谱表示学习工作(TransE等)。
关注公众号的读者里可能有些不是NLP方向的也建议可以关注关注以上老师的工作。其实当年我们参加这些会议的时候也不是做NLP方向的,但是交叉学科的工作多听听多看看总是有益处的。譬如我和我的同学们,现在多数都转到了NLP方向,在各个公司里从事NLP算法研究员、NLP算法工程师等工作。
好了,本文就到这里,今天比较啰嗦,哈哈哈。还是一样,如果本文对你有帮助的话,欢迎点赞&在看&分享,这对我继续分享&创作优质文章非常重要。感谢!
参考资料 [1]
《A Convolution BiLSTM Neural Network Model for Chinese Event Extraction》: https://eprints.lancs.ac.uk/id/eprint/83783/1/160.pdf
审核编辑 :李倩
-
模型
+关注
关注
1文章
3879浏览量
52353 -
识别
+关注
关注
3文章
175浏览量
32675 -
LSTM
+关注
关注
0文章
63浏览量
4466
原文标题:一文详解中文实体识别模型 Lattice LSTM
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
自动驾驶占用网络还需要数据标注吗?

大模型时代自动驾驶标注有什么特殊要求?

JSON:简洁代码高效搞定序列化与反序列化

极简代码,搞定JSON序列化与反序列化

一文读懂LSTM与RNN:从原理到实战,掌握序列建模核心技术

自动驾驶数据标注是所有信息都要标注吗?

算法工程师不愿做标注工作,怎么办?

复旦微电子被列入实体清单(Footnote 4)后发布公开信 已构建可持续发展格局
浅析多模态标注对大模型应用落地的重要性与标注实例
小语种OCR标注效率提升10+倍:PaddleOCR+ERNIE 4.5自动标注实战解析
瑞芯微RK3576语音识别算法

自动驾驶数据标注主要是标注什么?
什么是自动驾驶数据标注?如何好做数据标注?
数据标注与大模型的双向赋能:效率与性能的跃升



评论