 AI训练势起,GPU要让位了?
AI训练势起,GPU要让位了?

电子发烧友网报道(文/周凯扬)人工智能在进化的过程中,最不可或缺的便是模型和算力。训练出来的通用大模型省去了重复的开发工作,目前不少大模型都为学术研究和AI开发提供了方便,比如华为的盘古、搜狗的BERTSG、北京智源人工智能研究院的悟道2.0等等。
那么训练出这样一个大模型需要怎样的硬件前提?如何以较低的成本完成自己模型训练工作?这些都是不少AI初创企业需要考虑的问题,那么如今市面上有哪些训练芯片是经得起考验的呢?我们先从国外的几款产品开始看起。
英伟达A100
英伟达的A100可以说是目前AI训练界的明星产品,A100刚面世之际可以说是世界上最快的深度学习GPU。尽管近来有无数的GPU或其他AI加速器试图在性能上撼动它的地位,但综合实力来看,A100依然稳坐头把交椅。

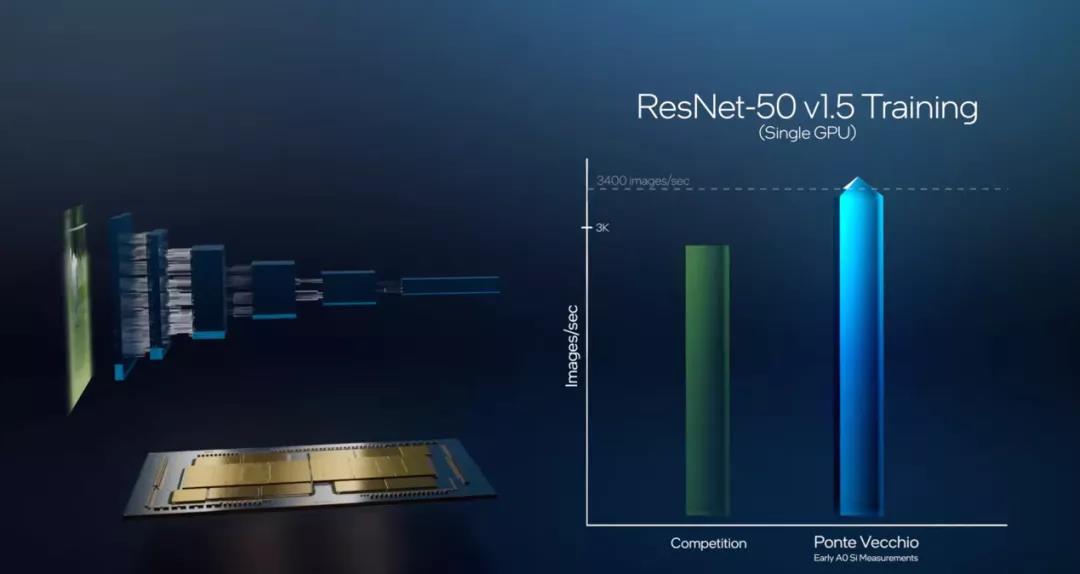
英特尔Gaudi和Ponte Vecchio
19年12月,英特尔收购了以色列的Habana Labs,将其旗下的AI加速器产品线纳入囊中。Habana Labs目前推出了用于推理的Goya处理器和用于训练的Gaudi处理器。尽管Habana Labs已经隶属英特尔,但现有的产品仍然基于台积电的16nm制程,传言称其正在开发的Gaudi2将用上台积电的7nm制程。 目前Gaudi已经用于亚马逊云服务AWS的EC2 DL1训练实例中,该实例选用了AWS定制的英特尔第二代Xeon可扩展处理器,最多可配置8个Gaudi处理器,每个处理器配有32GB的HBM内存,400Gbps的网络架构加上100Gbps的互联带宽,并支持4TB的NVMe存储。

亚马逊Trainium
最后我们以亚马逊的训练芯片收尾,亚马逊提供的服务器实例可以说是最多样化的,也包含了以上提到的A100和Gaudi。亚马逊作为云服务巨头,早已开始部署自己的服务器芯片生态,不仅在今年推出了第三代Graviton服务器处理器,也正式发布了去年公开的训练芯片Trainium,并推出了基于该芯片的Trn1实例。


小结
GPU一时半会不会跌落AI训练的神坛,但其他训练芯片的推陈出新证明了他们面对A100和Ponte Vecchio这种大规模芯片同样不惧,甚至还有自己独到的优势。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
gpu
+关注
关注
28文章
5296浏览量
136118 -
AI
+关注
关注
91文章
41479浏览量
302795
发布评论请先 登录
相关推荐
热点推荐
国产来袭!2nm AI GPU?
电子发烧友网报道(文/黄山明)在当前,GPU已经从最初的游戏图形渲染工具,逐渐演变为智能时代的核心。简单来说,如果没有GPU,今天我们所熟知的ChatGPT、自动驾驶、AI绘画等技术根本无法在合理
AI Ceph 分布式存储教程资料大模型学习资料2026
。如何构建高性能、高吞吐、高可扩展的 AI 分布式存储系统,已成为解锁大模型基建能力的核心科技命题。这不仅关乎数据存得下、读得快,更直接决定了 GPU 集群的利用率与模型训练的最终效率
发表于 05-01 17:35
HM博学谷狂野AI大模型第四期
,为开发者提供了一把打开 AI 黑盒的钥匙。从 Transformer 的矩阵运算到分布式训练的工程调度,再到推理加速的极致优化,这是一次从应用层向底层原理的深度回归。在 AI 技术竞
发表于 05-01 17:30
数据传输拖慢训练?三维一体调度让AI任务提速40%
作为AI开发者,你是否无数次陷入这样的困境:训练千亿参数大模型,数据传输占了总耗时的60%,GPU空转等待如同“带薪摸鱼”;跨地域调用算力,公网带宽瓶颈让TB级数据集传输动辄耗时数天;算力、数据
AI硬件全景解析:CPU、GPU、NPU、TPU的差异化之路,一文看懂!
CPU作为“通用基石”,支撑所有设备的基础运行;GPU凭借并行算力,成为AI训练与图形处理的“主力”;TPU在Google生态中深耕云端大模型训练;NPU则让

一文看懂AI大模型的并行训练方式(DP、PP、TP、EP)
大家都知道,AI计算(尤其是模型训练和推理),主要以并行计算为主。AI计算中涉及到的很多具体算法(例如矩阵相乘、卷积、循环层、梯度运算等),都需要基于成千上万的GPU,以并行任务的方式

NVIDIA Isaac Lab多GPU多节点训练指南
NVIDIA Isaac Lab 是一个适用于机器人学习的开源统一框架,基于 NVIDIA Isaac Sim 开发,其模块化高保真仿真适用于各种训练环境,可提供各种物理 AI 功能和由 GPU 驱动的物理仿真,缩小仿真与现实世
【「AI芯片:科技探索与AGI愿景」阅读体验】+第二章 实现深度学习AI芯片的创新方法与架构
连接定义了神经网络的拓扑结构。
不同神经网络的DNN:
一、基于大模型的AI芯片
1、Transformer 模型与引擎
1.1 Transformer 模型概述
Transformer 模型的出现
发表于 09-12 17:30
【「AI芯片:科技探索与AGI愿景」阅读体验】+AI芯片的需求和挑战
当今社会,AI已经发展很迅速了,但是你了解AI的发展历程吗?本章作者将为我们打开AI的发展历程以及需求和挑战的面纱。
从2017年开始生成式AI
发表于 09-12 16:07
AI 芯片浪潮下,职场晋升新契机?
职场、渴望在专业领域更进一步的人来说,AI 芯片与职称评审之间,实则有着千丝万缕的联系,为职业晋升开辟了新的路径。
AI 芯片领域细分与职称对应
目前,AI 芯片从技术架构上主要分为
发表于 08-19 08:58
睿海光电以高效交付与广泛兼容助力AI数据中心800G光模块升级
引领AI时代网络变革:睿海光电的核心竞争力
在AI时代,数据中心正经历从传统架构向AI工厂与AI云的转型。AI工厂依赖超大规模
发表于 08-13 19:01
在对庐山派K230的SD卡data文件夹进行删除和新件文件夹时无法操作,且训练时线程异常,怎么解决?
解决了其中训练线程报错的故障,是因为我的文件夹里只有一个分类子目录,于是在图像分类中它会报错,但是训练好后点击部署会出现部署文件生成异常的问题
查看AICube_log,日志显示如下
发表于 08-01 08:03
ai_cube训练模型最后部署失败是什么原因?
ai_cube训练模型最后部署失败是什么原因?文件保存路径里也没有中文
查看AICube/AI_Cube.log,看看报什么错?
发表于 07-30 08:15
aicube的n卡gpu索引该如何添加?
请问有人知道aicube怎样才能读取n卡的gpu索引呢,我已经安装了cuda和cudnn,在全局的py里添加了torch,能够调用gpu,当还是只能看到默认的gpu0,显示不了gpu1
发表于 07-25 08:18
并行计算的崛起:为什么GPU将在边缘AI中取代NPU
人工智能(AI)不仅是一项技术突破,它更是软件编写、理解和执行方式的一次永久性变革。传统的软件开发基于确定性逻辑和大多是顺序执行的流程,而如今这一范式正在让位于概率模型、训练行为以及数据驱动的计算



评论