 如何将基于Arm Cortex-M的微控制器用于本地设备端ML
如何将基于Arm Cortex-M的微控制器用于本地设备端ML

通过机器学习,开发者和工程师能够在应用中解锁新的功能。您可以为应用所需的分类任务收集大量的数据,并训练一个 ML 模型从数据中的模式里学习,而不是明确地定义计算机需要执行的指令和规则。
训练通常在计算机上的云端进行,而此类计算机会配备一个或多个 GPU。完成模型的训练之后,根据模型大小,可以将其部署在各种设备上进行推理。这些设备的范围很广,从云端拥有数千兆字节内存的大型计算机,到通常只有数千字节内存的微控制器(或 MCU),悉数在内。
微控制器是低功率、独立、经济高效的计算机系统,日常使用的设备(如微波炉、电动牙刷或智能门锁)中均有嵌入。基于微控制器的系统通常通过一个或多个传感器(例如:按钮、麦克风、运动传感器)与周围环境互动,并使用一个或多个执行器(例如:LED、电机、扬声器)来执行动作。
微控制器还具有隐私方面的优势,可以在设备上开展本地推理,而无需向云端发送任何数据。对于依靠电池运行的设备来说,微控制器还具有能耗方面的优势。
在本文中,我们将介绍如何将基于 Arm Cortex-M 的微控制器用于本地设备端 ML,以检测周围环境中的音频事件。这是一篇教程式的文章,我们将指导您训练一个基于 TensorFlow 的音频分类模型,来检测火灾警报的声音。
Arm Cortex-M
https://developer.arm.com/ip-products/processors/cortex-m
我们将介绍如何使用适用于微控制器的 TensorFlow Lite(具有 Arm CMSIS-NN 加速内核),将 ML 模型部署到基于 Arm Cortex-M0+ 的微控制器板上,来进行本地设备端 ML 推理。
适用于微控制器的 TensorFlow Lite
https://tensorflow.google.cn/lite/microcontrollers
CMSIS-NN
https://arm-software.github.io/CMSIS_5/NN/html/index.html
Arm Cortex-M0+
https://developer.arm.com/ip-products/processors/cortex-m/cortex-m0-plus
Arm 的 CMSIS-DSP 库为 Arm Cortex-M 处理器提供了优化的数字信号处理 (DSP) 功能实现,同时也将用于推理前从实时音频数据中提取特征。
CMSIS-DSP
https://arm-software.github.io/CMSIS_5/DSP/html/index.html
虽然本指南侧重于介绍火灾警报声音的检测,但也可以适用于其他声音分类任务。您可能还需要调整特征提取阶段和/或调整 ML 模型架构,以适应您的用例。
在 Google Colab 上可查看本教程的互动版本,本指南的所有技术资料都可在 GitHub 上找到。
Google Colab
https://colab.research.google.com/github/ArmDeveloperEcosystem/ml-audio-classifier-example-for-pico/blob/main/ml_audio_classifier_example_for_pico.ipynb
GitHub
https://github.com/ArmDeveloperEcosystem/ml-audio-classifier-example-for-pico
事前准备
开发环境
Google Colab
https://colab.research.google.com/notebooks/
硬件
需要下列开发板之一,这些开发板均依托于 2021 年初发布的 Raspberry Pi 的 RP2040 MCU 芯片构建而成。
Raspberry Pi 的 RP2040 MCU
“https://www.raspberrypi.org/products/rp2040/
SparkFun RP2040 MicroMod 和 MicroMod ML 载板
此开发板很适合刚接触电子行业和微控制器的人。不需要电烙铁,不需要掌握焊接技术,也不需要掌握在电路板上接线的技术。
SparkFun MicroMod RP2040 处理器。它是操作的大脑,具有 Raspberry Pi 的 RP2040 MCU 和 16MB 的闪存
SparkFun MicroMod RP2040 处理器
https://www.sparkfun.com/products/17720
SparkFun MicroMod 机器学习载板。它支持 USB 连接,并附带内置的麦克风、IMU 和摄像头连接器
SparkFun MicroMod 机器学习载板
https://www.sparkfun.com/products/16400
一条 USB-C 数据线,用于连接开发板和计算机
一把十字螺丝刀
Raspberry Pi Pico 和 PDM 麦克风板
如果您已掌握(或者想学习)焊接技术,那么这个选项非常适合您。它需要用到电烙铁,还需要了解如何用电子元件在电路板上布线。您将需要:
Raspberry Pi Pico
Raspberry Pi Pico
https://www.raspberrypi.org/products/raspberry-pi-pico/
Adafruit PDM MEMS 麦克风分接板
https://colab.research.google.com/notebooks/
半尺寸或全尺寸的电路板
跳线
一条 USB-B 微数据线,用于连接开发板和计算机
电烙铁
以上两个选项都可以帮助您使用数字麦克风收集实时的 16 kHz 音频,并利用开发板的 Arm Cortex-M0+ 处理器处理音频信号,该处理器的工作频率为 125 MHz。在 Arm Cortex-M0+ 上运行的应用将经过一个数字信号处理 (DSP) 阶段,从音频信号中提取特征。然后,将提取出的特征馈送至神经网络,以执行分类任务,确定开发板的环境中是否存在火灾警报的声音。
数据集
我们首先使用 ESC-50:环境声音分类数据集,通过 TensorFlow 来训练一个声音分类器(面向多个事件)。利用这个内容广泛的数据集进行训练后,我们将使用迁移学习,针对特定音频分类任务,对分类器进行微调。
ESC-50:环境声音分类数据集
https://github.com/karolpiczak/ESC-50
迁移学习
https://developers.google.com/machine-learning/glossary#transfer-learning
利用包含 50 种声音的 ESC-50 数据集训练这个模型。每个声音类别有 40 个音频文件,每个文件时长为 5 秒。将每个音频文件分割成 1 秒的声音片段,并舍弃任何包含纯静音的声音片段。
犬吠数据集中的样本波形
声谱图
不同于将时间序列数据直接传入 TensorFlow 模型,我们会将音频数据转换为音频声谱图表征。此举将创建音频信号频率内容随时间变化的二维表征。
所用输入音频信号的采样率将为 16 kHz,这意味着一秒钟的音频将包含 16,000 个样本。通过使用 TensorFlow 的 tf.signal.stft(。..) 函数,我们可以将 1 秒的音频信号转换为二维张量表征。我们将选择 256 的帧长和 128 的帧步长,所以此特征提取阶段的输出将为张量,其形状为 (124, 129)。
TensorFlow 的 tf.signal.stft(。..) 函数
https://tensorflow.google.cn/api_docs/python/tf/signal/stft
犬吠的声谱图表征
ML 模型
从音频信号中提取了特征之后,就可以使用 TensorFlow 的 Keras API 创建模型。上文有完整的代码链接。模型由 8 层组成:
Keras
https://tensorflow.google.cn/guide/keras/sequential_model
1. 输入层
2. 预处理层,将把输入张量从 124x129x1 调整为 32x32x1
3. 归一化层,在 -1 和 1 之间对输入值进行调整
4. 具有以下配置的二维卷积层:8 个过滤器,内核大小为 8x8,跨度为 2x2,使用 ReLU 激活函数
5. 大小为 2x2 的二维最大池化层
6. 平面化层,对二维数据进行平面化,令其变为一维
7. Dropout 层,有助于减少训练中的过度拟合
8. 密集层,有 50 个输出和一个 softmax 激活函数,用于输出声音属于某一类别的可能性(值在 0 到 1 之间)
以下为该模型的摘要:
请注意,此模型只有约 15,000 个参数(这相当小!)
微调
现在,我们将使用迁移学习,并改变模型的分类头(最后一个密集层),以训练火灾警报声的二进制分类模型。我们已从 freesound.org 和 BigSoundBank.com 收集了 10 个火灾警报片段。对于非火灾警报声,我们将使用来自 SpeechCommands 数据集的背景噪音片段。此数据集很小,但足够入门使用。数据增强技术将被用于完善我们所收集的训练数据。
freesound.org
https://freesound.org/
BigSoundBank.com
https://bigsoundbank.com/
SpeechCommands
https://tensorflow.google.cn/datasets/catalog/speech_commands
对于实际应用而言,务必要收集更大的数据集(您可以在 TensorFlow 的 Responsible AI 网站上详细了解最佳做法)。
Responsible AI 网站
https://tensorflow.google.cn/responsible_ai
数据增强
数据增强是一套用于扩大数据集规模的技术。达成此目标的方法是,稍微修改数据集中的样本或创建合成数据。在本例中使用的是音频,并将创建一些函数来增加不同的样本。我们将使用三种技术:
1. 在音频样本中添加白噪声
2. 在音频中随机添加静音
3. 将两个音频样本混合在一起
除了扩大数据集,数据增强也可以在不同的(不完美的)数据样本上训练模型,以此来减少过度拟合。例如,在微控制器上不可能有完美的高质量音频,所以此类技术(例如添加白噪声)可以帮助模型在麦克风可能经常有噪声的情况下正常运作。
GIF:数据增强如何通过增加噪声来微调声谱图
(仔细看,可能不太容易看清)
特征提取
适用于微控制器的 TensorFlow Lite (TFLu) 提供了 TensorFlow 操作的一个子集,所以无法使用我们在 MCU 上用于基线模型特征提取的 tf.signal.sft(。..) API。然而,我们可以利用 Arm 的 CMSIS-DSP 库,在 MCU 上生成声谱图。CMSIS-DSP 包含对浮点和定点 DSP 操作的支持,这些操作均针对 Arm Cortex-M 处理器进行了优化,其中便包括我们要向其部署 ML 模型的 Arm Cortex-M0+。Arm Cortex-M0+ 不包含浮点单元 (FPU),因此最好在开发板上利用基于特征提取流水线的 16 位定点 DSP。
我们可以在 Notebook 中利用 CMSIS-DSP 的 Python 封装容器,使用 16 位定点数学在我们的训练流水线上进行同样的操作。在较高级别上,我们可以通过以下基于 CMSIS-DSP 的操作来复制 TensorFlow SFT API:
CMSIS-DSP 的 Python 封装容器
https://github.com/ARM-software/CMSIS_5/tree/develop/CMSIS/DSP/PythonWrapper#readme
1. 使用汉宁窗 (Hanning Window) 公式和 CMSIS-DSP 的 arm_cos_f32 API,手动创建一个长度为 256 的汉宁窗。
arm_cos_f32
https://arm-software.github.io/CMSIS_5/DSP/html/group__cos.html#gace15287f9c64b9b4084d1c797d4c49d8
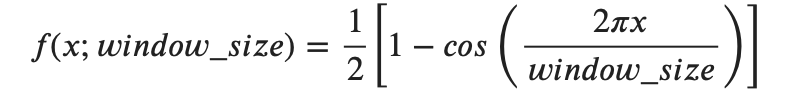
2. 创建一个 CMSIS-DSP arm_rfft_instance_q15 实例,并使用 CMSIS-DSP 的 arm_rfft_init_q15 API 对其进行初始化。
arm_rfft_init_q15
https://arm-software.github.io/CMSIS_5/DSP/html/group__RealFFT.html#ga053450cc600a55410ba5b5605e96245d
3. 循环播放音频数据,每次 256 个样本,跨度为 128(这与我们传入 TF sft API 的参数一致)
使用 CMSIS-DSP 的 arm_mult_q15 API,将 256 个样本与汉宁窗相乘
arm_mult_q15
https://arm-software.github.io/CMSIS_5/DSP/html/group__BasicMult.html#gaeeda8cdc2c7e79c8a26e905342a0bb17
使用 CMSIS-DSP 的 arm_rfft_q15 API 计算上一步输出的 FFT
arm_rfft_q15
https://arm-software.github.io/CMSIS_5/DSP/html/group__RealFFT.html#ga00e615f5db21736ad5b27fb6146f3fc5
使用 CMSIS-DSP 的 arm_cmplx_mag_q15 API 计算上一步的幅度
arm_cmplx_mag_q15
https://arm-software.github.io/CMSIS_5/DSP/html/group__cmplx__mag.html#ga0488e185f4631ac029b02f1759b287cf
4. 每个音频片段的 FFT 幅度代表声谱图的一列。
5. 由于我们的基线模型适合使用浮点输入,而不是我们使用的 16 位量化值,CMSIS-DSP arm_q15_to_float API 可以用来将声谱数据从 16 位定点值转换为用于训练的浮点值。
arm_q15_to_float
https://arm-software.github.io/CMSIS_5/DSP/html/group__q15__to__x.html#ga5a75381e7d63ea3a3a315344615281cf
这个模型的完整版 Python 代码有点长,但可以在 Google Colab notebook 的“迁移学习 -》 加载数据集”部分中加以查看。
Google Colab notebook 的“迁移学习 -》 加载数据集”部分
https://colab.research.google.com/github/ArmDeveloperEcosystem/ml-audio-classifier-example-for-pico/blob/main/ml_audio_classifier_example_for_pico.ipynb
烟雾报警器声音的波形和音频谱图
若要进一步了解如何使用 CMSIS-DSP 的定点操作创建音频声谱图,请参见 Towards Data Science 中的“数据研究员的定点 DSP (Fixed-point DSP for Data Scientists)”指南。
Towards Data Science 中的“数据研究员的定点 DSP (Fixed-point DSP for Data Scientists)”指南
https://towardsdatascience.com/fixed-point-dsp-for-data-scientists-d773a4271f7f
加载基线模型并改变分类头
我们之前利用 ESC-50 数据集训练的模型预测了 50 个声音类型的存在,这导致模型的最后密集层有 50 个输出。我们想创建的新模型是二进制分类器,需要有单一的输出值。
我们将加载基线模型,还将换掉最后的密集层,以满足我们的需要:
# We need a new head with one neuron.
model_body = tf.keras.Model(inputs=model.input, outputs=model.layers[-2].output)
classifier_head = tf.keras.layers.Dense(1, activation=“sigmoid”)(model_body.output)
fine_tune_model = tf.keras.Model(model_body.input, classifier_head)
于是就有了以下的 model.summary():
迁移学习
迁移学习是对一个任务开发的模型进行再训练,以完成类似的新任务的过程。其理念是,该模型已经学会了可迁移的“技能”,其权重和偏差可以在其他模型中作为起点。
我们人类也会使用迁移学习,例如为学习走路而培养的技能也可在以后用于学习跑步。
在神经网络中,模型的前几层会开始进行“特征提取”,如寻找形状、边缘和颜色。系统会将之后的几层用作分类器;这些层会利用提取的特征,并对特征进行分类。
正因为如此,我们可以认为前几层已经学会了相当通用的特征提取技术,并可将其应用于类似的任务,因此我们可以冻结所有这些层,在未来的新任务中加以使用。需要根据新任务对分类器层进行训练。
为了实现这个目标,我们将进程分为两步:
1. 冻结模型的“主干”,以超高的学习率训练头部。慢慢降低学习率。
2. 解冻“主干”,以低学习率微调模型每。
若要在 TensorFlow 中冻结一个层,我们可以设置 layer.trainable=False。循环操作所有层,并执行以下操作:
for layer in fine_tune_model.layers:
layer.trainable = False
然后解冻最后一层(头部):
fine_tune_model.layers[-1].trainable = True
我们现在可以使用二进制交叉熵损失函数来训练模型。还将使用 Keras 的早停回调(以避免过度拟合)和动态学习率调度器。
用冻结的层进行训练后,可以对其进行解冻:
for layer in fine_tune_model.layers:
layer.trainable = True
然后再次进行训练(最多 10 次)。您可以在 Colab notebook 的“迁移学习 -》 训练模型”部分中查看完整的代码。
Colab notebook 的“迁移学习 -》 训练模型”部分
https://colab.research.google.com/github/ArmDeveloperEcosystem/ml-audio-classifier-example-for-pico/blob/main/ml_audio_classifier_example_for_pico.ipynb#scrollTo=Replace_Baseline_Model_Classification_Head_and_Train_Model
记录您自己的训练数据
现在已得到 ML 模型,可以对出现的火灾报警声进行分类。然而,此模型的训练是根据公开的声音记录训练而成,可能与用于推理的硬件麦克风的声音特征不一致。
Raspberry Pi RP2040 MCU 带有原生的 USB 功能,可以让其像自定义 USB 设备一样运行。可以在开发板上刷写一个应用,让它能够像 USB 麦克风一样连在我们的 PC上。然后,可以用 Google Chrome 等流行的网络浏览器上的网络音频 API 来扩展 Google Colab 的功能,收集实时数据样本(所有这些都可通过 Google Colab 而得!)
网络音频 API
https://developer.mozilla.org/en-US/docs/Web/API/Web_Audio_API
硬件设置
SparkFun MicroMod RP2040
在组装时,卸下载板上的螺丝,以一定的角度将 MicroMod RP2040 处理器板滑入插座,并用螺丝将其固定。更多详情请参见 MicroMod 机器学习载板连接指南。
MicroMod 机器学习载板连接指南
https://learn.sparkfun.com/tutorials/micromod-machine-learning-carrier-board-hookup-guide?_ga=2.90268890.1509654996.1628608170-268367655.1627493370#hardware-hookup
Raspberry Pi Pico
按照“利用 Raspberry Pi Pico 创建 USB 麦克风”指南中的硬件设置部分的说明进行组装。
“利用 Raspberry Pi Pico 创建 USB 麦克风”指南中的硬件设置部分
https://www.hackster.io/sandeep-mistry/create-a-usb-microphone-with-the-raspberry-pi-pico-cc9bd5#toc-hardware-setup-5
Fritzing 布线图
组装好的电路
设置固件应用工具链
无需在个人计算机上设置 Raspberry Pi Pico 的 SDK。我们可以利用 Colab 内置的 Linux shell 命令特征,用 CMake 和 GNU Arm 嵌入工具链设置 Pico SDK 开发环境。
CMake
https://cmake.org”
GNU Arm 嵌入工具链
https://developer.arm.com/tools-and-software/open-source-software/developer-tools/gnu-toolchain/gnu-rm
还要用 git 将 pico-sdk 下载到 Colab 实例中:
pico-sdk
https://github.com/raspberrypi/pico-sdk
%%shell
git clone https://github.com/raspberrypi/pico-sdk.git
cd pico-sdk
git submodule init
git submodule update
编译并刷写 USB 麦克风应用
现在可以使用 Pico 的麦克风库中的 USB 麦克风示例。可以用 cmake 和 make 对此示例应用进行编译。然后,通过 USB 将示例应用刷写到电路板上,将电路板调至“启动 ROM 模式”,这样就可以将应用上传到电路板上。
Pico 的麦克风库
https://github.com/ArmDeveloperEcosystem/microphone-library-for-pico
SparkFun
将 USB-C 数据线插入电路板和个人计算机,为电路板供电。
按住电路板上的 BOOT 按钮,同时按 RESET 按钮。
Raspberry Pi Pico
将 Micro USB 线插入个人计算机,但不要插入 Pico 一侧。
按住白色 BOOTSEL 按钮,同时将 Micro USB 线插入 Pico。
如果您使用的是支持 WebUSB API 的浏览器,如 Google Chrome,则可以直接从 Google Colab 中把图像刷写到板上!
WebUSB API
https://wicg.github.io/webusb/
从 Google Colab 和 WebUSB 中将 USB 麦克风应用下载到板上
除此之外,您还可以手动将 .uf2 文件下载到计算机,然后把它拖到 RP2040 板的 USB 磁盘上。
收集训练数据
将 USB 麦克风应用刷写到板上之后,它将作为 USB 音频输入出现在您的个人计算机上。
我们现在可以用 Google Colab 录制火灾警报的声音,在下拉菜单中选择“MicNode”,将其作为音频输入源。然后在按下烟雾报警器的测试按钮时,点击 Google Colab 上的录音按钮,录制一个 1 秒钟的音频片段。将此过程重复几次。
同样地,我们也可以在 Google Colab 的下一个代码单元中执行相同的操作来收集背景音频样本。对于非火灾警报的声音,如无声、自己说话或任何其他正常的环境声音,将此操作重复几次。
最终模型训练
现在,我们已经用麦克风收集了更多样本,并将在推理过程中使用这些样本。我们可以用新的数据再次对模型进行微调。
将模型转换为在 MCU 上运行
需要把我们使用的 Keras 模型转换为 TensorFlow Lite 格式,以便在设备上使用它进行推理。
量化
为了优化模型以便在 Arm Cortex-M0+ 处理器上运行,我们将采用一个叫做模型量化的过程。模型量化将模型的权重和偏移从 32 位浮点值转换为 8 位值。pico-tflmicro 库(TFLu 在 RP2040 的 Pico SDK 上的一个端口)包含 Arm 的 CMSIS-NN 库,它支持在 Arm Cortex-M 处理器上对量化的 8 位权重进行优化的内核操作。
pico-tflmicro
https://github.com/raspberrypi/pico-tflmicro
我们可以使用 TensorFlow 的训练时量化 (QAT) 特征,轻松地将浮点模型转换为量化模型。
TensorFlow 的训练时量化 (QAT)
https://tensorflow.google.cn/model_optimization/guide/quantization/training
将模型转换为 TF Lite 格式
现在我们将使用 tf.lite.TFLiteConverter.from_keras_model(。..) API 将量化的 Keras 模型转换为 TF Lite 格式,然后将其以 .tflite 文件的形式保存到磁盘。
converter = tf.lite.TFLiteConverter.from_keras_model(quant_aware_model)
converter.optimizations = [tf.lite.Optimize.DEFAULT]
train_ds = train_ds.unbatch()
def representative_data_gen():
for input_value, output_value in train_ds.batch(1).take(100):
# Model has only one input so each data point has one element.
yield [input_value]
converter.representative_dataset = representative_data_gen
# Ensure that if any ops can‘t be quantized, the converter throws an error
converter.target_spec.supported_ops = [tf.lite.OpsSet.TFLITE_BUILTINS_INT8]
# Set the input and output tensors to uint8 (APIs added in r2.3)
converter.inference_input_type = tf.int8
converter.inference_output_type = tf.int8
tflite_model_quant = converter.convert()
with open(“tflite_model.tflite”, “wb”) as f:
f.write(tflite_model_quant)
由于 TensorFlow 也支持使用 tf.lite 加载 TF Lite 模型,我们也可以验证量化模型的功能,并将其准确率与 Google Colab 内部的常规未量化模型进行比较。
tf.lite
https://tensorflow.google.cn/api_docs/python/tf/lite
我们要部署的电路板上的 RP2040 MCU 没有内置的文件系统,这意味着我们不能在电路板上直接使用 .tflite 文件。然而,我们可以使用 Linux 的“xxd”命令将 .tflite 文件转换为 .h 文件,然后可以在下一步的推理应用中进行编译。
%%shell
echo “alignas(8) const unsigned char tflite_model[] = {” 》 tflite_model.h
cat tflite_model.tflite | xxd -i 》》 tflite_model.h
echo “};”
将模型部署到设备
现在模型已经准备完成,并可部署到设备上。我们已经创建了用于推理的应用模板,可以与我们为模型生成的 .h 文件一起编译。
用于推理的应用模板
https://github.com/ArmDeveloperEcosystem/ml-audio-classifier-example-for-pico/tree/main/inference-app
这个 C++ 应用依托于 pico-sdk 构建而成,同时还配备 CMSIS-DSP、pico-tflmicro,以及 Pico 库的麦克风库。它的一般结构如下:
1. 初始化
配置板内置 LED 的输出。该应用将把 LED 的亮度映射到模型的输出(0.0 表示 LED 关闭,1.0 表示 LED 亮度全开)
设置用于推理的 TF Lite 库和 TF Lite 模型
设置基于 CMSIS-DSP 的 DSP 流水线
设置并启动用于实时音频的麦克风
2. 推理循环
等待来自麦克风的 512 个新音频样本(共 4 组,每组 128 个)
将声谱图数组移动 4 列
将音频输入缓冲区移动 512 个样本(共 4 组,每组 128 个)并在新样本中复制
为更新的输入缓冲区计算 4 个新的声谱图列
对声谱图数据进行推理
将推理输出值映射到板载 LED 的亮度并将状态输出到 USB 端口
为了实时运行,推理循环的每个周期必须在 (512/16000) = 0.032 秒,即 32 毫秒以下。我们训练和转换的模型需要 24 毫秒的推理时间,因此用于循环中其他操作的时间大约为 8 毫秒。
上文中使用了 128,以匹配声谱图中的训练流水线采用的 128 的幅度。我们在声谱图中采用了 4 移位,以适应我们的实时限制。
编译固件
现在我们可以使用 CMake 来生成编译所需的构建文件,然后用 make 进行编译。
必须根据您采用的板,修改“cmake 。.”行:
SparkFun: cmake 。. -DPICO_BOARD=sparkfun_micromod
Raspberry Pi Pico: cmake 。. -DPICO_BOARD=pico
将推理应用刷写到板上
您需要再次将板调至“启动 ROM 模式”,以便将新的应用加载到板上。
SparkFun
将 USB-C 数据线插入电路板和个人计算机,为电路板供电。
按住电路板上的 BOOT 按钮,同时按 RESET 按钮。
Raspberry Pi Pico
将 Micro USB 线插入个人计算机,但不要插入 Pico 一侧。
按住白色 BOOTSEL 按钮,同时将 Micro USB 线插入 Pico。
如果您使用的是支持 WebUSB API 的浏览器,如 Google Chrome,则可以在 Google Colab 中直接将图像刷写到电路板上。除此之外,您还可以手动将 .uf2 文件下载到计算机,然后把它拖到 RP2040 板的 USB 磁盘上。
监控板上的推理
推理应用在电路板上开始运行之后,您可以通过两种方式观察它的运行情况:
通过观察板上 LED 的亮度来直观地获取信息。没有火灾警报声时,LED 应该保持关闭或变暗,若有火灾警报声,LED 就会亮起:
连接板的 USB 串行端口,查看推理应用的输出。如果您使用的是支持 Web Serial API 的浏览器,如 Google Chrome,则可以直接从 Google Colab 中完成:
Web Serial API
https://developer.mozilla.org/en-US/docs/Web/API/Web_Serial_API
改善模型
现在已将第一版模型部署在板上,该模型正在对 16,000 kHz 的实时音频数据进行推理!
测试一下各种声音,看看模型是否有预期的输出。可能会误检测出火灾警报声(误报),也有可能在有警报声时没有检测出来(漏报)。
如果出现这种情况,您可以将 USB 麦克风应用固件刷写到板上,为训练记录数据,重新训练模型并转换为 TF lite 格式,以及重新编译推理应用并刷写到板上,以便为场景记录更多新的音频数据。
监督式机器学习模型的好坏通常取决于其所使用的训练数据,所以针对这些场景的额外训练数据可能会有助于改善模型。您也可以尝试改变模型结构或特征提取过程,但请记住,模型必须足够小巧快速,才能在 RP2040 MCU 上运行。
结论
本文介绍了一个端到端的流程,即如何训练自定义的音频分类器模型,以便在使用 Arm Cortex-M0+ 处理器的开发板上运行。就模型训练而言,我们采用了 TensorFlow,使用了迁移学习技术以及较小的数据集和数据增强技术。我们还从麦克风中收集了自己的数据,并在推理时加以使用,其方法是将 USB 麦克风应用加载到开发板上,并通过网络音频 API 和 JavaScript 扩展 Colab 的特征。
项目的训练方面结合了 Google 的 Colab 服务和 Chrome 浏览器,以及开源的 TensorFlow 库。推理应用从数字麦克风采集音频数据,在特征提取阶段使用 Arm 的 CMSIS-DSP 库,然后使用适用于微控制器的 TensorFlow Lite 与 Arm CMSIS-NN 加速内核,用 8 位量化模型进行推理,在 Arm Cortex-M0+ 处理器上对实时的 16 kHz 音频输入进行分类。
利用 Google Chrome 的网络音频 API、网络 USB API 和网络串行 API 功能来扩展 Google Colab 的特征,与开发板进行互动。这样我们就能够完全通过网络浏览器对我们的应用进行实验和开发,并将其部署到一个受限的开发板上进行设备端推理。
由于 ML 处理是在开发板 RP2040 MCU 上进行的,所以在推理时,所有音频数据均会保留在设备上。
责任编辑:haq
-
音频
+关注
关注
31文章
3136浏览量
84944 -
机器学习
+关注
关注
66文章
8541浏览量
136241
原文标题:使用 Raspberry Pi RP2040 进行端到端 TinyML 音频分类
文章出处:【微信号:tensorflowers,微信公众号:Tensorflowers】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Cortex-M产品的特色
灵动微MM32F3270微控制器的音频设备参考方案
STM32C031x4/x6:面向主流应用的Arm® Cortex®-M0+ 微控制器
PY32F030系列32位ARM Cortex-M0+微控制器介绍
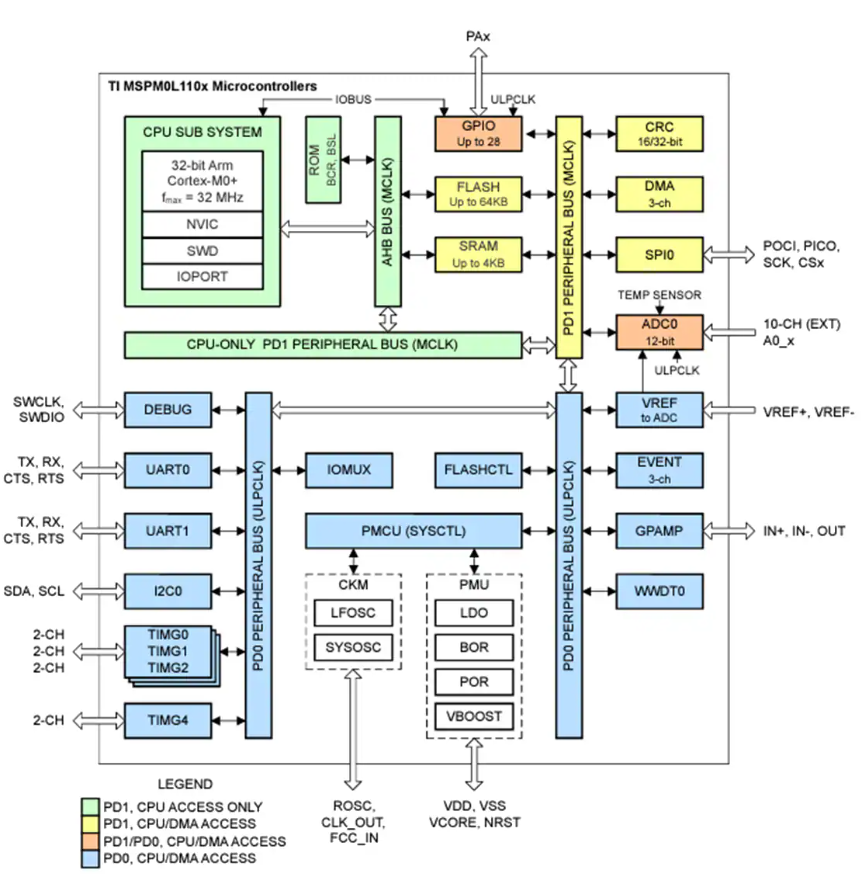
Texas Instruments MSPM0L110x Arm® Cortex®-M0微控制器深度解析
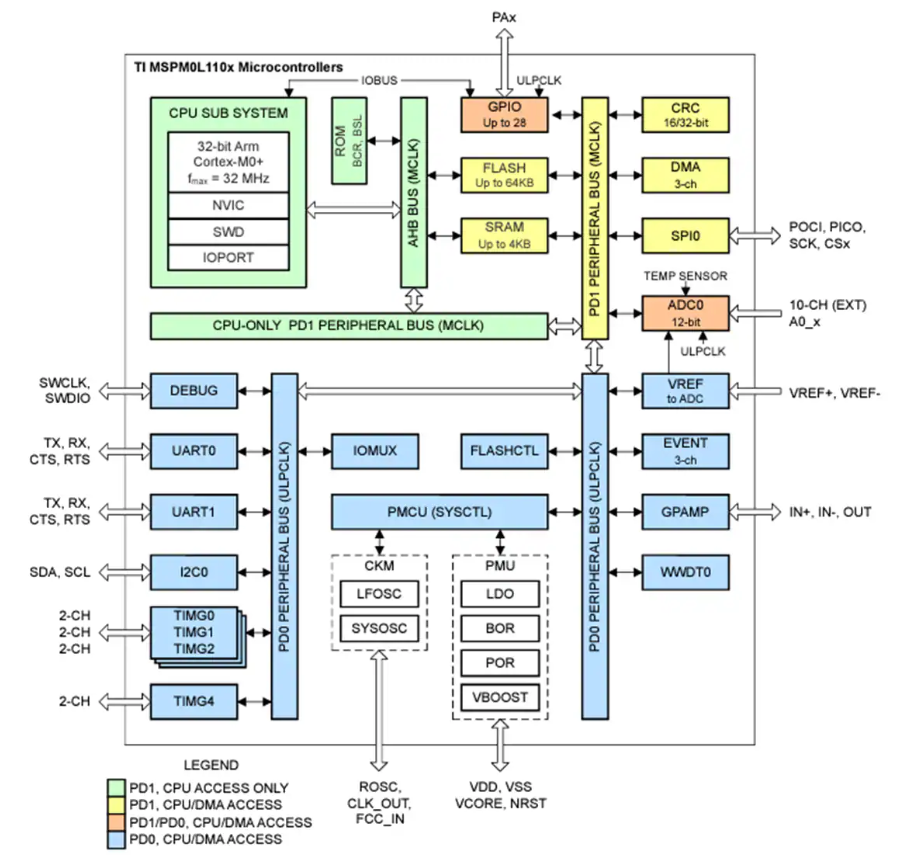
MSPM0L110x Arm Cortex-M0+微控制器技术解析
极海APM32F411微控制器硬件FPU使用指南

Analog Devices / Maxim Integrated MAX32672 ARM Cortex-M4F微控制器特性/应用/框图

雅特力AT32L021系列低功耗ARM®Cortex®-M0+微控制器
MAX32555 Cortex-M3闪存微控制器英文数据手册
XMC1402-F064X0128AA——基于 ARM® Cortex®-M 的32位工业微控制器
Toshiba推出七款Arm Cortex-M4电机控制微控制器
东芝推出七款基于Arm Cortex-M4内核的32位微控制器






 工商网监
工商网监
评论