 详解一种简单而有效的Transformer提升技术
详解一种简单而有效的Transformer提升技术

01研究背景及动机
近些年,Transformer[1]逐渐成为了自然语言处理中的主流结构。为了进一步提升Transformer的性能,一些工作通过引入额外的结构或知识来提升Transformer在特定任务上的表现。尽管如此,过参数化(over-parameterization)和过拟合(overfitting)一直是Transformer中的一个显著问题。作为一种正则化技术,Dropout常被用来缓解模型的过拟合问题[2]。和引入额外结构或知识的工作相比,dropout的一个优势是不需要额外的计算开销和外部资源。因此,本文的出发点在于,能否通过融合不同的dropout技术来进一步提升Transformer的性能甚至达到state-of-the-art效果?
为此,我们提出UniDrop技术,从细粒度到粗粒度将三种不同层次的dropout整合到Transformer结构中,它们分别为feature dropout、structure dropout和data dropout 。Feature dropout (FD),即传统的dropout技术[2],通常应用在网络的隐层神经元上。Structure dropout (SD)是一种较粗粒度的dropout,旨在随机drop模型中的某些子结构或组件。Data dropout (DD)作为一种数据增强方法,通常用来随机删除输入sequence的某些tokens。在UniDrop中,我们从理论上分析了这三层dropout技术在Transformer正则化过程中起到了不同的作用,并在8个机器翻译任务上和8个文本分类任务上验证了UniDrop的有效性。
02UniDrop
2.1Transformer结构
UniDrop旨在提升Transformer的性能。在UniDrop中,feature dropout和structure dropout的使用与网络结构密切相关。因此,我们简单回顾Transformer的网络结构。
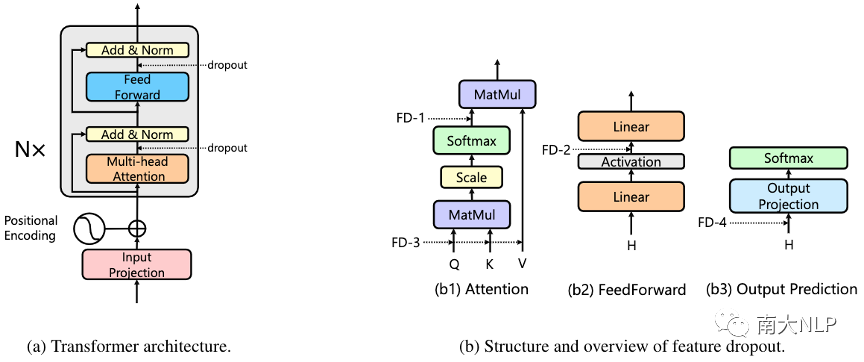
图1:标准Transformer结构和Feature Dropout
如图1(a)所示,Transformer由多个相同的block堆叠而成,每个block包含两个sub-layer,分别为multi-head self-attention layer和position-wise fully connected feed-forward layer,每个sub-layer后都使用了残差连接和层正则(Add&Norm)。
Multi-head Attention:Multi-head attention sub-layer包含多个并行的attention head,每个head通过带缩放的点乘attention将query Q和键值对K、V映射乘输出,如下式所示:
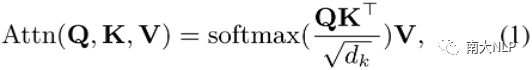
多个head的输出最终被拼接在一起并做线性映射作为最终的multi-head attention输出。
Position-wise Feed-Forward:这一层主要包含两个线性映射和一个ReLU激活函数:
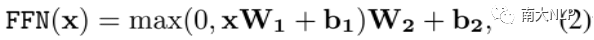
2.2Feature Dropout
如前所述,Feature Dropout (FD)即传统的dropout技术[2],可以以一定的概率随机抑制网络中的某些神经元。实际上,在标准的Transformer实现中,每个sub-layer后都默认配置了dropout。除此之外,Transformer也在multi-head attention和feed-forward network的激活函数层添加了dropout,本文将探索它们对Transformer性能的影响:
FD-1 (attention dropout):根据公式(1),在multi-head attention中,我们可以获得attention权重A=QKT,feature dropout FD-1被应用在attention权重A上。
FD-2 (activation dropout):FD-2被应用在feed-forward network sub-layer两层线性变换间的激活函数上。
除了上面已有的feature dropout,我们在预实验中发现Transformer仍有过拟合的风险。因此,我们额外提出两种feature dropout添加到Transformer结构中:
FD-3 (query, key, value dropout):FD-1直接应用在attention权重A上,表示token i和token j之间的connection有可能被drop,一个更大的FD-1值意味着更大的概率失去sequence中一些关键的connection。为了缓解这种风险,我们在attention之前的query Q、key K和value V上分别添加了dropout。
FD-4 (output dropout):我们在softmax分类的线性映射前也添加了dropout。具体而言,对sequence2sequence任务,我们将FD-4添加到Transformer decoder中,对于文本分类任务我们将FD-4添加到Transformer encoder中。
2.3Structure Dropout
为了提升Transformer的泛化性,之前的工作已经提出了两种Structure Dropout (SD),分别是LayerDrop[3]和DropHead[4]。DropHead通过随机舍弃一些attention head,从而防止multi-head attention机制被某些head主导,最终提升multi-head attention的泛化性。相比之下,LayerDrop是一种更高级别的结构dropout,它能随机舍弃Transformer的某些层,从而直接降低Transformer中的模型大小。通过预实验分析,我们将LayerDrop添加到我们的UniDrop中。
2.4Data Dropout
Data Dropout (DD)以一定的概率p随机删除输入序列中tokens。然而,直接应用data dropout很难保留原始高质量的样本,对于一个长度为n的sequence,我们保留住原始sequence的概率为(1-p)n,当n较大时,这个概率将会非常低。失去原始高质量样本对很多任务都是不利的。为了保留原始高质量的样本,同时又能利用data dropout进行数据增强,我们在UniDrop中提出了一个2-stage data dropout方案。对于给定的sequence,我们以一定的概率 pk保留原始的样本,当data dropout被应用时(概率为1- pk),我们以预定的概率p来随机删除序列中的tokens。
2.5UniDrop整合
最终,我们将上面三种不同粒度的dropout技术集成到我们的UniDrop中,并从理论上分析了feature dropout、structure dropout、data dropout能够正则Transformer的不同项并且不能相互取代,具体分析可参考论文。Figure 2是UniDrop的简单示例。
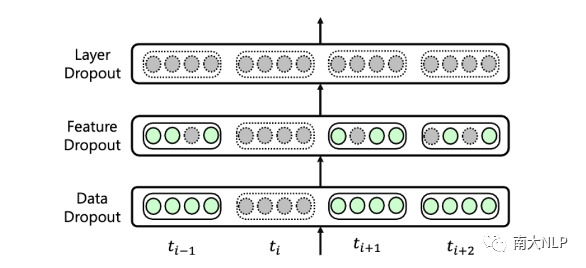
图2:UniDrop示例
03实验与分析
我们在序列生成(机器翻译)和文本分类两个任务上来验证UniDrop的性能。
3.1神经机器翻译
我们在IWSLT14数据集上进行了机器翻译实验,共4个语言对,8个翻译任务,baseline为标准的Transformer结构,实验结果如表1所示:
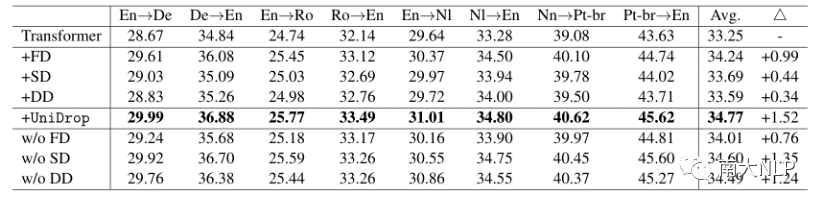
表1:不同模型在IWSLT14翻译任务上的结果
可以看到,相比于标准的Transformer,我们的UniDrop在所有任务翻译任务上都取得了一致且显著的提升。为了验证UniDrop中每种dropout的作用,我们进行了ablation study实验,也在标准Transformer添加单一的dropout去验证它们的性能。从结果看,FD、SD和DD都能在一定程度上提升Transformer的性能,并能够协同工作,最终进一步提升Transformer的泛化性。
为了进一步验证UniDrop的优越性,我们也在广泛被认可的benchmarkIWSLT14 De→En翻译任务上和其他系统进行了对比。这些系统从不同的方面提升机器翻译,如训练算法设计(Adversarial MLE)、模型结构设计(DynamicConv)、引入外部知识(BERT-fused NMT)等。可以看到,我们的Transformer+UniDrop仍然显著超过了其他系统。
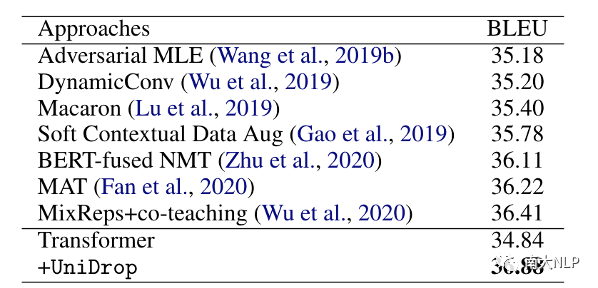
表2:不同系统在IWSLT14 De→En翻译任务上的表现
3.2文本分类
对于文本分类任务,我们以RoBERTaBASE作为backbone,在4个GLUE数据集上和4个传统的文本分类数据集上进行了实验,结果如表3和表4所示:
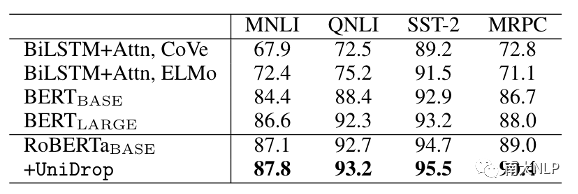
表3:不同模型在GLUE tasks (dev set)上的准确率
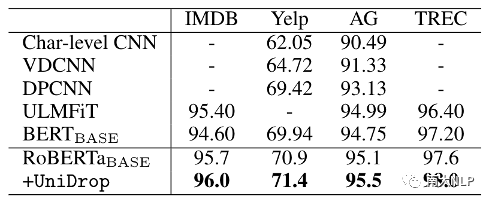
表4:不同模型在传统文本分类任务上的准确率
可以看到,作为一个强大的预训练模型,RoBERTaBASE显著超过了其他方法。即使如此,UniDrop仍然能够进一步提升RoBERTaBASE的性能,这进一步验证了UniDrop对Transformer模型的有效性。
3.3分析
为了展现UniDrop能够有效防止Transformer过拟合,我们画出了不同模型在IWSLT14 De→En翻译验证集上的loss曲线,如图3所示:
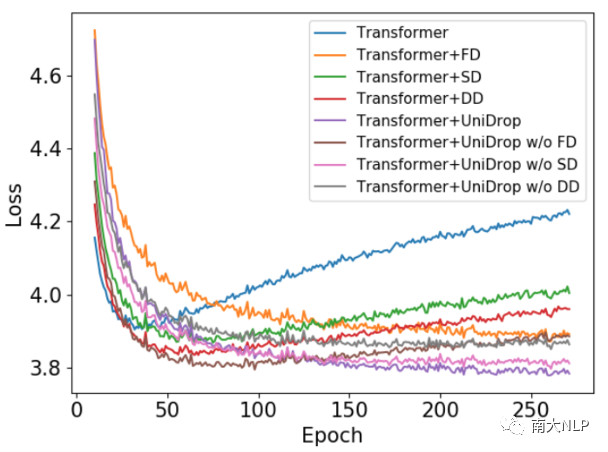
图3:不同模型在IWSLT14 De→En翻译上的dev loss
可以看到,标准的Transformer结构随着训练轮数的增加,很容易出现过拟合现象。相比之下,FD、SD、DD都在一定程度上缓解了Transformer的过拟合问题。在所有对比模型中,我们的UniDrop取得了最低的dev loss,并且dev loss能持续下降,直到训练结束。综合来看,UniDrop在预防Transformer过拟合问题上取得了最好的表现。
此外,我们也进行了细粒度的ablation study实验来探究不同的feature dropout以及我们2-stage data dropout对Transformer性能的影响,结果如表5所示:
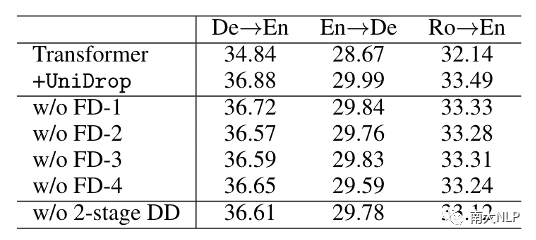
表5:Ablation Study
可以看到,FD-3比FD-1带来更多的提升,这也验证了我们之前的分析,仅使用FD-1对提升multi-head attention的泛化性来说是不够的。另外,表5表明我们提出的2-stage data dropout策略对提升性能是有帮助的,这体现了保留原始高质量样本的必要性。
04总结与展望
过拟合是Transformer结构中一个常见的问题,dropout技术常被用来防止模型过拟合。本文中,我们提出了一种集成的dropout技术UniDrop,它由细粒度到粗粒度,将三种不同类型的dropout(FD、SD、DD)融合到Transformer结构中。我们从理论上分析UniDrop中的三种dropout技术能够从不同的方面防止Transformer过拟合,在机器翻译和文本分类任务上的实验结果也体现了UniDrop的有效性和优越性,更重要的,它不需要额外的计算开销和外部资源。更多的细节、结果以及分析请参考原论文。
编辑:lyn
-
Dropout
+关注
关注
0文章
13浏览量
10788 -
Transformer
+关注
关注
0文章
156浏览量
6993 -
自然语言处理
+关注
关注
1文章
630浏览量
14769
原文标题:UniDrop:一种简单而有效的Transformer提升技术
文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Transformer 入门:从零理解 AI 大模型的核心原理
技术资讯 I 一文详解 STEP 文件

Transformer如何让自动驾驶大模型获得思考能力?
Transformer如何让自动驾驶变得更聪明?
大尺寸玻璃晶圆(12 英寸 +)TTV 厚度均匀性提升技术

代理式AI提升团队绩效的六种方式
【「AI芯片:科技探索与AGI愿景」阅读体验】+第二章 实现深度学习AI芯片的创新方法与架构
如何有效利用高光谱成像技术提升数据分析效率

自动驾驶中Transformer大模型会取代深度学习吗?

【「DeepSeek 核心技术揭秘」阅读体验】第三章:探索 DeepSeek - V3 技术架构的奥秘
一种高效智能的光伏电站管理平台
同步整流MOSFET的设计要点与效率提升技巧

一种实现开关柜局放监测的有效技术架构
一文详解外延生长技术



评论