 剖析正交匹配追踪算法的优化设计与FPGA实现
剖析正交匹配追踪算法的优化设计与FPGA实现

0 引言
2006年,CANDES D E等人提出了压缩感知(Compressed Sensing,CS)理论[1],CS理论利用与表达基不相干的观测矩阵,以低于奈奎斯特的采样速率非自适应地采样可稀疏表示的信号,得到低维的离散信息矢量,该信息矢量包含了原始信号的全部信息,然后通过非线性重建算法完美地重建信号。
压缩感知理论主要包含了三大核心部分:信号的稀疏表示、测量矩阵的构造和信号重构算法的设计。在压缩感知理论的三个核心问题中,如何设计并用硬件实现根据离散信息样点准确重构原始信号的行之有效的算法是该理论中较为重要的一环。目前,压缩感知信号重构算法主要分为两类:基于凸松弛的优化算法,如基追踪(Basis Pursuit,BP)算法;
基于贪婪迭代的匹配追踪算法,如OMP算法[2]。这两类算法各有优缺点:凸松弛算法具有很好的鲁棒性,然而由于需要将求解问题转化为线性规划问题,计算量大,信号重构效率低;贪婪算法虽然不具有强保证性,但实现简单,重构效率高,在工程应用中得到广泛使用[3]。
首次对压缩感知恢复算法进行VLSI设计是在参考文献[4]中,而之后,有文献进行优化设计。参考文献[5]根据OMP算法必须按照特定顺序执行这一特征,采用资源复用技术,提高了资源利用率。参考文献[6]设计了一个快速求逆平方根算法,在矩阵分解部分采用QR算法。参考文献[7]对OMP算法进行优化,减少了计算延时。参考文献[8]同时进行了OMP算法和AMP算法的VLSI设计。本文先对OMP算法进行理论分析,然后对OMP算法进行改进,通过增加一个阈值来减少乘法运算次数,使运算速度更快。在矩阵分解部分采用ACD方法避免开方运算,同时在硬件实现上也进行了相应的优化。仿真结果验证了设计的可行性。
1 OMP算法
1.1 基本OMP算法
在压缩感知中,原始信号x的稀疏度为k,观测矢量y是所采集的数据,y可通过测量矩阵Φ与x相乘而得。本设计的目的是在已知y和Φ的前提下恢复出x。OMP算法主要分为两部分,即寻找稀疏矢量中非零元素的位置和计算非零元素的值。
在OMP算法中残差r是一个很关键的参数,残差是通过当前选取的列向量和原始信号的线性组合不能对压缩测量值进行表示的部分。
1.2 改进OMP算法
令原始信号x的稀疏度为k,测量矩阵Φ大小为M×N,那么y为M维的离散信息矢量。本文提出一种新的方法,即加阈值法,通过添加一个阈值来减少乘法运算次数,阈值定为内积和的平均值的α倍,内积小于阈值的那些列在下一次迭代中不再求内积。每次迭代计算后都要对阈值进行更新。信号估计的均方误差随着α的增大而增大,当α为0时均方误差最小。改进的OMP算法步骤如下:


2 计算步骤
本文利用硬件实现重构长度N=256、稀疏度k=8的原始信号,观测矢量长度M=64。
改进后的OMP算法可分为4个模块。第1个模块对应重建过程的第(1)和第(2)步,也就是在剩余列的集
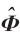
中寻找对残差贡献最大的列为最匹配原子。
第2个模块对应重建过程的第(3)步,即计算新残差,为下次迭代做准备。
第3个模块对应重建过程的第(4)和第(5)步,即计算新的阈值并除去剩余列的集
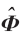
中和残差求内积小于阈值的列。求阈值前要先求内积的平均值。第t次迭代的内积平均值可用以下公式计算:

为解决对Φ的列的定位问题,用一个256位的标志位来追踪Φ的列,标志位的第i位对应Φ的第i列。在第i列和残差求内积后,下一个时钟和残差求内积的就是下一个标志位为非零所对应的列,跳过标志位为零对应的列。开始前先把标志位的每一位全部初始化成1,在每一次迭代之后对标志位进行更新。
第4个模块对应重构过程的第(7)步,求解非零元素的值,即解决最小二乘问题。对于这类运算一般用Moore-Penrose伪逆的方法求解:

求出C的逆矩阵后,就可以求得原始信号的估计:
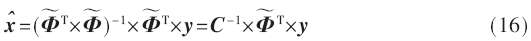
由于OMP算法的迭代性质,4个模块是不能并行执行的,只能每个模块依次执行。
3 硬件设计
硬件电路主要由以上4个模块组成,分为两个部分。整体硬件电路如图1所示。
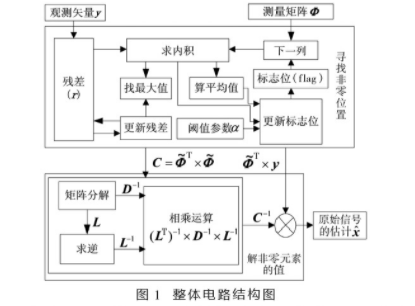
首先用观测矢量y对残差r进行初始化。y用寄存器组存储,而观测矩阵Φ用多个RAM存储,这样就能在一个时钟内读出y的所有值和Φ的一列值。数据用24位定点数表示,10位整数,14位小数。设计64个24位乘法器并行工作来求内积,然后找到内积最大值来更新
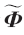
。矩阵
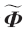
的大小变化从N×1~N×8。
每次迭代后会把Φ中和残差内积小于阈值的列过滤掉,根据式(9)、(10)和(11),剩余列的集中的每一列和残差的内积都送到累加器进行求和,然后通过求内积平均值求得阈值。阈值参数α设置为一个常数。
256位标志位作为Φ的地址寻址,标志位每一位对应Φ每一列,初始化为所有位为1。每次迭代后对标志位进行更新,把Φ中和残差内积小于阈值的列所对应的标志位赋为零,否则保持为1。然后在下一次迭代时跳过标志位为零所对应的Φ的列,也就是直接用下一个非零标志位所对应的列与残差进行求内积。通过把标志位的前32位送到一个32位前导零计算器可以找出下一个非零位。
在寻找非零元素位置的部分迭代8次后,就开始计算非零元素的值。首先要计算矩阵
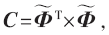
可通过以下等式计算:
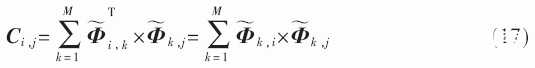
此处复用之前的64个乘法器。C是一个对称矩阵,所以只需要计算C的对角线上8个元素和对角线下半部(或上半部)的28个元素。
然后要对C进行交替的柯列斯基分解,矩阵分解要求出下三角矩阵L和对角矩阵D。从式(13)和(14)可以看出,L和D是相互依存的,必须以特定的顺序计算。本设计中稀疏度k=8,L和D可以按照图2箭头所指顺序计算。设计7个乘法器并行计算D中的元素,那么每计算一个元素需要一个时钟周期。计算D-1时采用参考文献[9]的方法进行除法运算。由于L的同一列的各个元素并不是相互依存的,所以求L的每一列值都设计为并行计算各个元素,那么每一列的计算只需要一个时钟周期。

矩阵L的求逆需要迭代进行,如式(18):
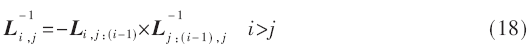
由于L的逆矩阵的各列的各个元素是相互依存的,所以列和列可以并行运算,每一列要按照特定的顺序运算,那么计算L-1需要7个时钟周期。
求C-1=(L-1)T×D-1×L-1时可以先求A=(L-1)T×D-1,然后再计算C-1=A×L-1。
4 仿真及结果分析
考虑到两个模块的最大运行频率不一样,本设计在寻找非零元素部分采用85 MHz的时钟,在求解非零元素值部分采用65 MHz的时钟。为了进行更好的对比,在MATLAB上用相同的算法、测量矩阵和观测矢量来重构原始估计值。当α=0.25时,软件和硬件的重构结果进行归一化后的对比如图3所示。
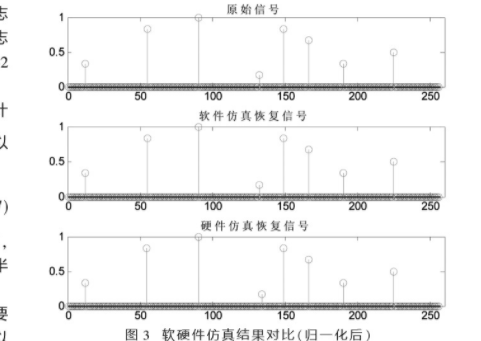
当α取值为零时,寻找非零元素部分共需要2 100个时钟周期,而仅仅是计算内积就需要256×8=2 048个时钟周期,计算非零元素部分共需要110个时钟周期,总的重构时间为26.40 μs。当α取值为0.25时,计算内积所需减少到约1 300个时钟周期,总的重构时间减少到约16.99 μs。在相同条件下,参考文献[7]重构时间为17.61 μs。而在参考文献[4]中,测量矩阵维数为32×128,观测向量维数为32×1,原始信号的稀疏度为5,总的重构时间就需要24 μs。
但是改进OMP算法归一化误差会随着α的增大而增大,当α取值为零时,归一化均方误差为0.001 5,取α=0.25时,归一化均方误差增加到0.007 1。
5 结论
本文采用一种阈值法,使得OMP恢复算法的求内积次数大大减少,从而缩短了信号重构所需要的时间,提高了恢复速率。同时,本文在硬件结构设计上也进行了一些优化,较好地平衡了占用资源和运算时间。本设计采用VHDL对改进的OMP算法进行了RTL级描述,在Quartus II上针对Altera公司的Cyclone II EP2C70F672C6进行设计和仿真,结果表明信号能够以更少的重构时间较好地恢复。
参考文献
[1] DONOHO D L.Compressed sensing[J].Information Theory,IEEE Trans. on,2006,52(4):1289-1306.
[2] TROPP J A,GILBERT A C.Signal recovery from random measurements via orthogonal matching pursuit[J].Information Theory,IEEE Trans.on,2007,53(12):4655-4666.
[3] 赵贻玖.稀疏模拟信号压缩采样与重构算法研究[D].成都:电子科技大学,2012.
[4] SEPTINUS A,STEINBERG R.Compressive sampling hardware reconstruction[C].Circuits and Systems(ISCAS),Proc.of 2010 IEEE International Symposium on.IEEE,2010:3316-3319.
[5] BLACHE P,RABAH H,AMIRA A.High level prototyping and FPGA implementation of the orthogonal matching pursuit algorithm[C].Information Science,Signal Processing and their Applications(ISSPA),2012 11th International Conference on.IEEE,2012:1336-1340.
[6] STANISLAUS J L V M,MOHSENIN T.High performance compressive sensing reconstruction hardware with QRD process[C].Circuits and Systems(ISCAS),2012 IEEE International Symposium on.IEEE,2012:29-32.
[7] STANISLAUS J,MOHSENIN T.Low-complexity fpga implementation of compressive sensing reconstruction[C].International Conference on Computing,Networking and Communications.2013.
[8] BAI L,MAECHLER P,MUEHLBERGHUBER M,et al.High-speed compressed sensing reconstruction on FPGA using OMP and AMP[C].Proc.19th Int.Conf.Electronics,Circuits and Systems(ICECS),Dec.2012:53-56.
[9] 周殿凤,王俊华.基于FPGA的32位除法器设计[J].信息化研究,2010(3):26-28.
编辑:jq
-
测量
+关注
关注
10文章
5787浏览量
117127 -
稀疏信号重构
+关注
关注
0文章
2浏览量
794
发布评论请先 登录
HMC1097LP4E宽带直接正交调制器:特性、应用与优化
ADL5385 30 MHz 至 2200 MHz 正交调制器:技术剖析与应用探索
ADL5387正交解调器:特性、应用与设计要点
LT5517:40MHz 至 900MHz 正交解调器的技术剖析
LT5516:800MHz - 1.5GHz直接转换正交解调器的技术剖析
AD8348:50 MHz至1000 MHz正交解调器的技术剖析与应用指南
AD9854:高性能CMOS 300 MSPS正交直接数字频率合成器的技术剖析
从算法到部署:Enclustra如何用DSP+FPGA/SoC专长,实现功耗与成本双优化?

室内蓝牙定位追踪技术:从典型场景到技术局限性与优化方向详解(二)
复杂的软件算法硬件IP核的实现
目标追踪的简易实现:模板匹配
信号发生器如何与波束赋形算法配合优化?
基于FPGA实现FOC算法之PWM模块设计
基于Matlab与FPGA的双边滤波算法实现

基于FPGA的压缩算法加速实现



评论