 基于PyTorch的深度学习入门教程之DataParallel使用多GPU
基于PyTorch的深度学习入门教程之DataParallel使用多GPU

前言
本文参考PyTorch官网的教程,分为五个基本模块来介绍PyTorch。为了避免文章过长,这五个模块分别在五篇博文中介绍。
Part1:PyTorch简单知识
Part2:PyTorch的自动梯度计算
Part3:使用PyTorch构建一个神经网络
Part4:训练一个神经网络分类器
Part5:数据并行化
本文是关于Part5的内容。
Part5:数据并行化
本文中,将会讲到DataParallel使用多GPU。
在PyTorch中使用GPU比较简单,可以这样把模型放到GPU上。
model.gpu()
还可以复制所有的tensors到GPU上。
mytensor = my_tensor.gpu()
请注意,单纯调用mytensor.gpu()不会拷贝tensor到GPU上。你需要把它分配给一个新的tensor,然后在GPU上使用这个新的tensor。
前向和反向传播可以在多个GPU上运行。但是,PyTorch默认只使用一个GPU。你可以使用DataParallel使得你的模型可以在过个GPU上并行运算。
model = nn.DataParallel(model)
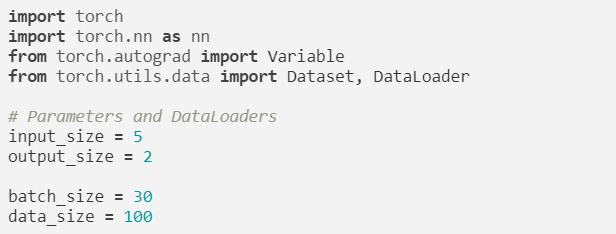
1 Package导入和参数设置
导入PyTorch的模块并且设置参数。
2 虚拟数据集
制作虚拟(随机)数据集,只需要执行getitem。
class RandomDataset(Dataset): def __init__(self, size, length): self.len = length self.data = torch.randn(length, size) def __getitem__(self, index): return self.data[index] def __len__(self): return self.len rand_loader = DataLoader(dataset=RandomDataset(input_size, 100), batch_size=batch_size, shuffle=True)
3 简单模型
作为实例,我们的模型只是获取输入,进行线性运算,给出结果。但是,你可以把DataParallel应用到任何模型(CNN,RNN,Capsule Net 等等)。
class Model(nn.Module): # Our model def __init__(self, input_size, output_size): super(Model, self).__init__() self.fc = nn.Linear(input_size, output_size) def forward(self, input): output = self.fc(input) print(" In Model: input size", input.size(), "output size", output.size()) return output
4 创建模型和数据并行
这是本篇教程的核心内容。我们需要制作一个模型实例,并检查是否有多个GPU。如果有多GPU,可以使用nn.DataParallel打包我们的model。之后,我们可以把利用model.gpu()把模型放到GPU上。
model = Model(input_size, output_size) if torch.cuda.device_count() > 1: print("Let's use", torch.cuda.device_count(), "GPUs!") # dim = 0 [30, xxx] -> [10, ...], [10, ...], [10, ...] on 3 GPUs model = nn.DataParallel(model) if torch.cuda.is_available(): model.cuda()
5 运行模型
for data in rand_loader: if torch.cuda.is_available(): input_var = Variable(data.cuda()) else: input_var = Variable(data) output = model(input_var) print("Outside: input size", input_var.size(), "output_size", output.size())
期望输出:
In Model: input size torch.Size([30, 5]) output size torch.Size([30, 2]) Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2]) In Model: input size torch.Size([30, 5]) output size torch.Size([30, 2]) Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2]) In Model: input size torch.Size([30, 5]) output size torch.Size([30, 2]) Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2]) In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2]) Outside: input size torch.Size([10, 5]) output_size torch.Size([10, 2])
6 结果
(1)如果有2 GPUs,可以看到
# on 2 GPUs Let's use 2 GPUs! In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2]) In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2]) Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2]) In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2]) In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2]) Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2]) In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2]) In Model: input size torch.Size([15, 5]) output size torch.Size([15, 2]) Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2]) In Model: input size torch.Size([5, 5]) output size torch.Size([5, 2]) In Model: input size torch.Size([5, 5]) output size torch.Size([5, 2]) Outside: input size torch.Size([10, 5]) output_size torch.Size([10, 2])
(2)如果有3 GPUs,可以看到
Let's use 3 GPUs! In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2]) In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2]) In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2]) Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2]) In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2]) In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2]) In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2]) Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2]) In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2]) In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2]) In Model: input size torch.Size([10, 5]) output size torch.Size([10, 2]) Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2]) In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2]) In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2]) In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2]) Outside: input size torch.Size([10, 5]) output_size torch.Size([10, 2])
(3)如果有8 GPUs,可以看到
Let's use 8 GPUs! In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2]) In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2]) In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2]) In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2]) In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2]) In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2]) In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2]) In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2]) Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2]) In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2]) In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2]) In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2]) In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2]) In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2]) In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2]) In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2]) In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2]) Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2]) In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2]) In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2]) In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2]) In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2]) In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2]) In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2]) In Model: input size torch.Size([4, 5]) output size torch.Size([4, 2]) In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2]) Outside: input size torch.Size([30, 5]) output_size torch.Size([30, 2]) In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2]) In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2]) In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2]) In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2]) In Model: input size torch.Size([2, 5]) output size torch.Size([2, 2]) Outside: input size torch.Size([10, 5]) output_size torch.Size([10, 2])
7 总结
DataParallel将数据自动分割送到不同的GPU上处理,在每个模块完成工作后,DataParallel再收集整合这些结果返回。
责任编辑:xj
-
gpu
+关注
关注
28文章
5099浏览量
134420 -
Data
+关注
关注
0文章
63浏览量
39031 -
深度学习
+关注
关注
73文章
5590浏览量
123890 -
pytorch
+关注
关注
2文章
813浏览量
14680
发布评论请先 登录
【团购】独家全套珍藏!龙哥LabVIEW视觉深度学习实战课(11大系列课程,共5000+分钟)
【团购】独家全套珍藏!龙哥LabVIEW视觉深度学习实战可(11大系列课程,共5000+分钟)
自动驾驶中Transformer大模型会取代深度学习吗?

跟老齐学Python:从入门到精通
GPU架构深度解析

ARM Mali GPU 深度解读
摩尔线程发布Torch-MUSA v2.0.0版本 支持原生FP8和PyTorch 2.5.0
摩尔线程与当虹科技达成深度合作
军事应用中深度学习的挑战与机遇
BP神经网络与深度学习的关系
操作指南:pytorch云服务器怎么设置?
Triton编译器在机器学习中的应用
利用Arm Kleidi技术实现PyTorch优化

深度学习工作负载中GPU与LPU的主要差异






 工商网监
工商网监
评论