 会话式机器阅读理解概述
会话式机器阅读理解概述

1
会话式机器阅读理解是什么?
如何在会话式阅读理解里面能够建模它的implicative reasoning,即如何去学习会话与阅读理解篇章之间的蕴含关系。 在这篇文章中,讲者概述了两种常见阅读理解的类型: 第一种是标准的阅读理解,该模式是指,给定一篇描述型的文章和一个基于事实型的问题,通过匹配文章和问题,从文章中抽取一个span来回答这个问题; 第二种是会话式的问答,与标准的单轮问答不同,需要追问新问题,即follow up question,同时问题是以交互的形式出现。会话式问答,存在两个挑战,一个是需要能理解篇章,另一个是能够理解交互的会话本身。 基于会话式问答,讲者引入一个例子简单说明(图1)。
比如,用户简单描述了自己的情况(Scenario),但用户的问题并不能直接从文章(Rule Text)中获取,往往这个文章可能是一个比较通用的、相当于是一个法规或者法律的篇章。 比如,说明能够申请7a贷款的人,需要具备什么样的条件,但针对用户问题在文章中没有直接的答案,必须和用户进行一个交互,才能得到明确的回答。例子中,成功申请贷款的条件有三个,所以还需再问另外的条件。 比如,能不能够在别的地方获取它的资金来源,假如用户说no的话,这时候就可以给他一个答案,也就是说你可以申请。 因此,在这种情形下,就需要既能够读懂这篇文章,理解文章中的规则,也要能够主动地和用户交互,从用户那边获取一些需要知道的信息,最终再给他一个决策。
图1 定义该项任务常用的数据集是ShARC (shaping answers with rules through conversation 的简称),数据集的设定是:给定Rule Text;用户描述自己的Scenario(Background);用户提出question;已有的问答(Dialog History)。 整个过程可以概述为,由于用户给定的background往往不明确,机器需要进行几轮交互,然后从交互中获取一些跟规则有关的信息,然后告诉用户具体答案。 整个任务有两个子任务: 任务一,整合Rule Text,Scenario,Question以及通过几轮交互从用户获取的信息,作为模型输入,然后做出决策(Decision Making)。
该决策包含四种类型:一种是根据现有的信息能够作出yes or no 的决策;或者有些情况下,用户的问题可能与给定Rule Text无关,或根据Rule Text并不能解决问题,则会出现unanswerable的答案;另一种情况是Rule Text中需要满足很多条件,但有些条件机器不确定是否满足,需要作出inquire的决策,主动从用户那里获取更多信息,直至几轮交互后能够作出yes or no的决策。 任务二,如果生成的决策是inquire,则需要机器问一个follow-up question,该问题能根据Rule Text引导用户提供一些没有提供的信息,便于进一步的决策。
图2 2
会话式机器阅读理解的初探
2.1 模型介绍 负采样 针对于该任务,讲者主要介绍了两项工作,首先是发表于ACL2020的文章“Explicit Memory Tracker with Coarse-to-Fine Reasoning for Conversational Machine Reading”。 该工作的贡献有两个: a. 针对决策,提出了explicit tracker,即能够显示的追踪文章中条件是否被满足; b. 采用coarse-to-fine方法抽取Rule Text中没有被问到的规则、条件等。
图3 模型主要包括了四部分:1.Encoding→ 2.Explicit Memory Tracking→ 3.Decision Making→ 4.Question Generation,整体结构如下:
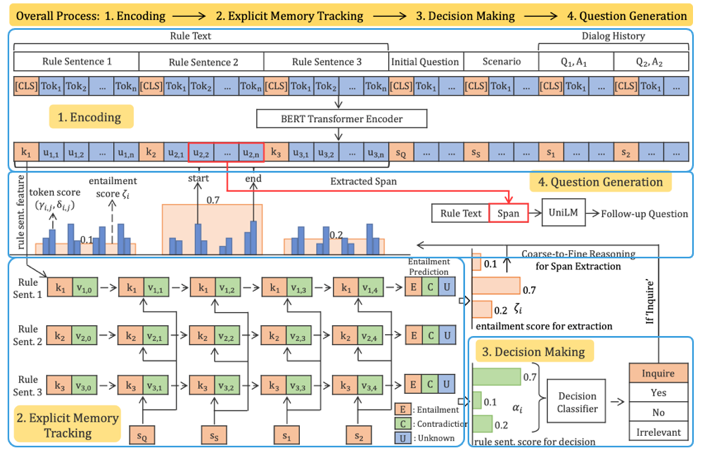
图4 (1) Encoding 将Rule Text中的句子分开,比如分为三个句子,在每个句子前加一个[CLS]表征句子特征,同时把queestion,scenario以及用户的会话历史加起来,也用[CLS]表征,拼接起全部特征后,通过BERT进行encoding。
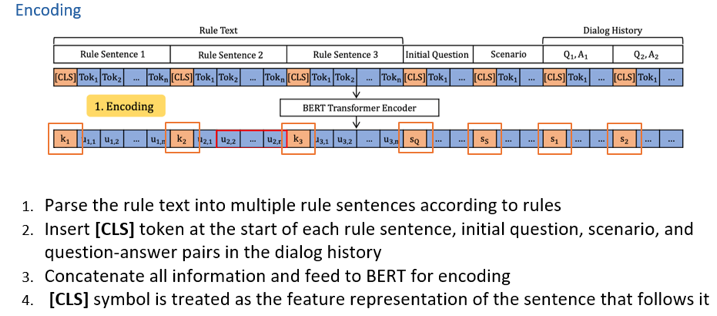
图5 (2) Explicit Memory Tracking 该部分的目的在于挖掘出存在于Relu Text的句子中与用户提供的信息(比如initial question 和dialog history)之间的implication。 针对于此,提出了explict memory tracker,类似于recurrent的思想,逐步的把用户的信息和Relu Text中的规则进行交互,从而更新每一个规则的memory里对应的value,最终得到每一个条件满足,不满足或者不知道的一个状态。 经过n次更新完后,每一个rule 都会得到key-value对。
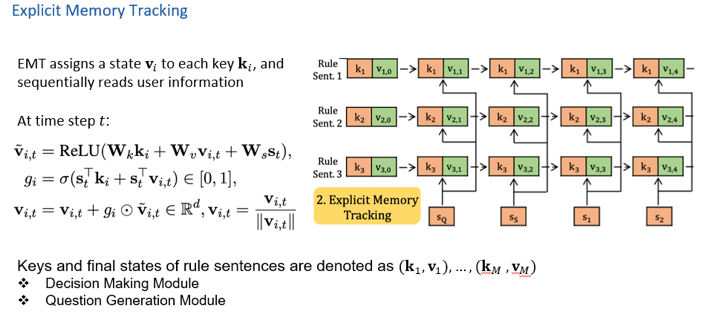
图6 (3)Decision Making 对n次更新完后的key-value做self-attention,经过一个线性层做四分类,即Yes, No, Irrelevant, Inquire。
图7 同时,还设计了一个subtask,即对最终更新完之后的key-value做一个预测,显示的预测该规则是Entailment,Prediction还是Unknown。该预测任务和Decision Making一起进行训练。
图8 (4)Question Generation 若得到的决策是Inquire,就要求继续做一个follow-up question的generation。 主要包括两个步骤: 第一步,从rule 中抽取一个span,具体是使用了一种coarse-to-fine 的做法,如下图所示。由于在Entailment prediction,句子的unknown分数越高,表示该句子越可能被问;若句子状态是Entailment或者Contradiction,说明该句子状态已知,没必要继续问下去。 因此,选择每一个句子在Entailment prediction中unknown的分数,并在每一个句子中计算抽取start和end的分数,然后将这两个分数相乘,综合判断哪一个span最有可能被问到。

图9 第二步,就是把span和rule 拼接起来,经过一个预训练模型将其rephrase一个question。
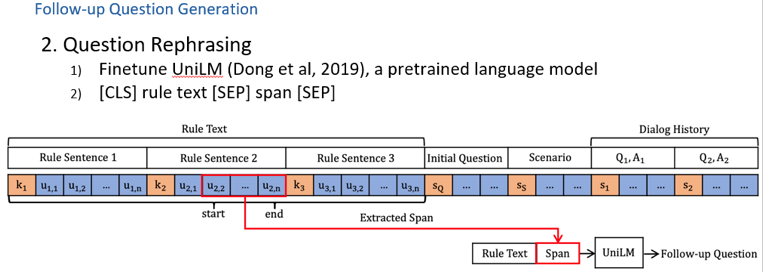
图10 2.2 实验验证 负采样 使用ShARC数据集进行实验验证,包含了两个任务的评价:分别为对于Decision Making任务采用 Marco-Accuracy 和Micro-Accuracy评价;以及对于问题生成采用BLEU Score评价。 此外,讲者考虑到在end-to-end evaluation时,存在一个缺点,也就是说,对于评价问题生成时,模型是基于决策这部分的水平去做问题生成的评价,这使得每个模型之间问题生成的表现不好比较,因此提出一个oracle question generation evaluation,即只要当Ground truth decision 是inquire,就对其问题生成的水平进行评价。 在测试集上得到的结果验证了所提出的Entailnment Memory Tracker(EMT)模型较其他模型效果有很大提升,尤其在问题生成方面效果显著。
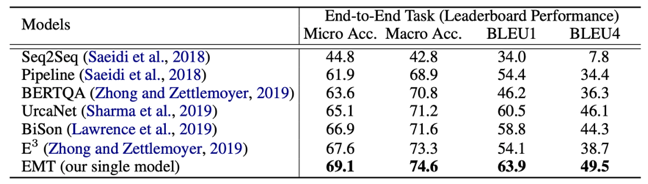
表1 具体分析每一类决策的准确率,可验证Inquire的效果要更好,主要因为模型能显式的追踪模型的一些状态,而不是简单的学习模型中一些Pattern。 此外,在oracle question generation evaluation数据集上,与之前最好的模型E3,以及加上UniLM的模型进行对比,同样也证明了采用Coarse-to-Fine的方法抽取span,在问题生成方面具有更好的效果。
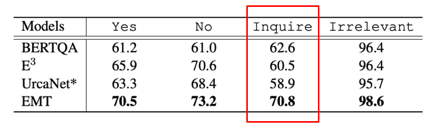
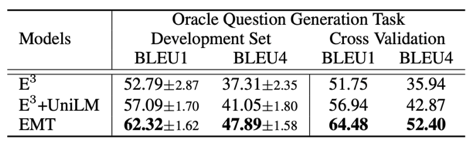
表2 同时,讲者给出了一个例子,更形象明白的说明了所提出的模型具备可解释性。
图11 3
如何更好地进行会话式机器阅读理解
3.1 问题提出负采样 进一步,讲者介绍了第二项工作,该工作与前者的侧重点有所不同,存在两个差异: 第一,document interpretation,主要由于第一项工作只是简单的对句子进行了一个切分,但实际上有些conditions(比如,上述例子中的American small business for profit business)是长句子中从句的条件,因此,第二项工作侧重如何去理解这样的条件。比如,能申请7(a)贷款,需要满足(①==True and ②==True and ③==True)的条件,这在第一项工作中是没有被建模的。

图12 第二,dialogs understanding,即对于会话并没有做特别显式的理解。比如,在会话第一轮发现rule之间是and的关系,并且在Scenairo中抽取出条件,说明第一个rule是true,但还要继续问第二个和第三个rule,所以给定Inquire的决策,直至满足所有的rule后,才能给一个“You can apply the loan”的回答。
3.2 模型介绍负采样 因此,该项工作主要基于这两点,提出先采用Discourse Segmentation的方法显式的把条件更好地抽取出来,之后做Entailment Reasoning 显式地预测每一个状态是否被满足,如果预测结果是Inquire,还需要做一个Follow-up Question Generation。
具体的,在discourse segmentation 中主要有两个目标:其一是明白Rule Text中的逻辑关系;其二是将句子中的条件更好地抽取出来。比如,对于一个rule采用Discourse Segmentation的方法将其抽取成三个elementary discourse unit (EDU),比如,下图中EDU1 ,EDU3是条件,然后EDU2是一个结果,这样的一个关系。
图15 如何实现Entailment Reasoning? 与工作一类似,在EDU抽取之后,将其与之前的用户Question,Scenairo 以及Dialog History拼接起来,经过预训练模型,得到每一个phrase的表征。然后采用多层transformer模型预测rule中每一个EDU 的状态,是Entailment、Contradiction,或者Neutral。 多层transformer模型较之前recurrent思想的模型更优秀,其不仅能在用户信息与rule之间做交互,也能更好的理解rule本身的逻辑结构(比如,conjunction,disconjunction等 )。 进一步,如何实现Decision Making? 在做决策时,根据学习到的Entailment、 Contradiction、Neutral向量,去映射前一步做Entailment Prediction的三个分数,得到每一个EDU的状态vector,同时拼接该状态vector与EDU本身的语义表示,作为Decision Classifier 输入,从而得到决策。
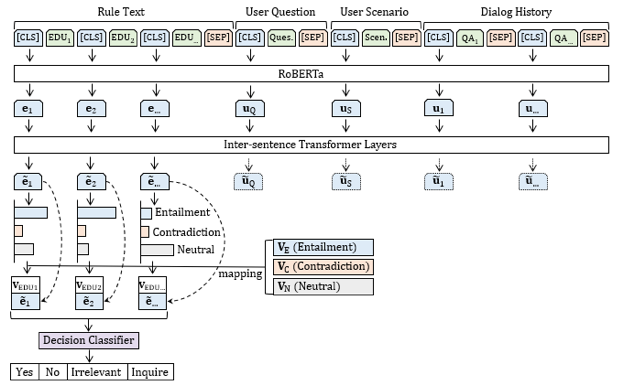
图163.3实验验证及结论负采样 同样地,实验也是在ShARC数据集上进行。实验结果表明,使用discourse segmentation加上更好的更显式的Reasoning的模式,较之前使用EMT模型具有更好的性能表现,在Micro Accuracy和Macro Accuracy上差不多高出4%。
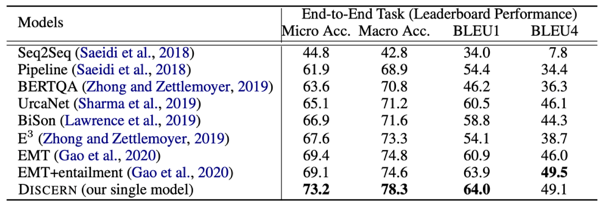
表3 在Ablation Study中,首先对比了RoBERTa和BERT之间的区别,表明了RoBERTa对于Reasoning的任务具有一定的贡献;其次,说明了采用discourse segmentation划分一个句子为多个EDU形式的效果优于仅对句子进行划分的结果;然后,证明了采用Transformer显示地对用户信息和问题之间做交互是有必要的;最后,证明了拼接Entailment vector和EDU本身的语义表示,对最终决策具有相当大的贡献。
表4 进一步,分析了不同逻辑结构下模型的结果表现。这里粗略分成4种规则的逻辑结构,即Simple、Disjunction、Conjunction以及Other。结果表示,模型在Simple形式下具有最好效果,然而在Disjunction形式下效果较差。
图17 为什么模型对于Disjunction,做出的决策效果较差? 考虑到模型涉及两部分内容,一是dialogue understanding;二是对 scenario的理解。 因此,讲者进一步做了如下实验,就是把这两块内容分开,选择一个只用到dialogue understanding 的子集,再选择一个只用到scenario Interpretation的子集,进行实验。 结果表明,只用到dialogue understanding 的子集的模型效果要优于用到整个数据集的效果,但在scenario Interpretation的子集上,实验效果差了很多。 该现象的原因在于,用户自己的background (scenario)可能用到了很多reasoning的方式,与rule 不完全一样,因此对scenario的理解是比较差的。很多时候scenario里提到了关键信息但是模型并没有抽取成功,从而继续做出inquire的决策。这也可能是导致Disjunction决策效果较差的原因。
图18 4
总结
综上,讲者团队分别提出了Explicit Memory Tracker with Coarse-to-Fine Reasoning 以及Discourse aware Entailment Reasoning的方法,并且在ShARC数据集上效果很好,同时设计实验分析了数据集本身的难点以及模型的缺陷,为后续研究指明可拓展方向。
责任编辑:xj
原文标题:香港中文大学高一帆博士:会话式机器阅读理解
-
阅读
+关注
关注
0文章
10浏览量
11693 -
机器学习
+关注
关注
67文章
8573浏览量
137548
原文标题:香港中文大学高一帆博士:会话式机器阅读理解
文章出处:【微信号:tyutcsplab,微信公众号:智能感知与物联网技术研究所】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
元太科技与联发科技深化合作 生成式AI SoC整合彩色电子纸技术升级阅读体验 锁定彩色教育与阅读市场
智能机器人从0到1系统入门课程 带源码课件 百度网盘下载
探索MAX8621Y/MAX8621Z:便携式设备的高效电源管理解决方案
【「Altium Designer 25 电路设计精进实践」阅读体验】总体感受
破解RDMA网络“黑盒”:轻量化会话追踪工具

MAX14663:便携式医疗设备的理想电源管理解决方案
【「龙芯之光 自主可控处理器设计解析」阅读体验】--全书概览与概述
【「龙芯之光 自主可控处理器设计解析」阅读体验】+可测试性设计章节阅读与自己的一些感想
《AI机器人控制进阶教程(入门版)》阅读指引

为什么选远景达嵌入式二维码阅读器?扫码识别快、准、稳,口碑之选

【「高速数字设计(基础篇)」阅读体验】+初步上手阅读
如何理解6 DOF ?

手持式身份证识别阅读器:移动的身份识别智能终端




评论