 TensorFlow Lite (TFLite) 在内存使用方面的改进
TensorFlow Lite (TFLite) 在内存使用方面的改进

文 /Juhyun Lee 和 Yury Pisarchyk,软件工程师
由于资源限制严重,必须在苛刻的功耗要求下使用资源有限的硬件,因此在移动和嵌入式设备上进行推理颇有难度。在本文中,我们将展示 TensorFlow Lite (TFLite) 在内存使用方面的改进,更适合在边缘设备上运行推理。
中间张量
一般而言,神经网络可以视为一个由算子(例如 CONV_2D 或 FULLY_CONNECTED)和保存中间计算结果的张量(称为中间张量)组成的计算图。这些中间张量通常是预分配的,目的是减少推理延迟,但这样做会增加内存用量。不过,如果只是以简单的方式实现,那么在资源受限的环境下代价有可能很高,它会占用大量空间,有时甚至比模型本身高几倍。例如,MobileNet v2 中的中间张量占用了 26MB 的内存(图 1),大约是模型本身的两倍。
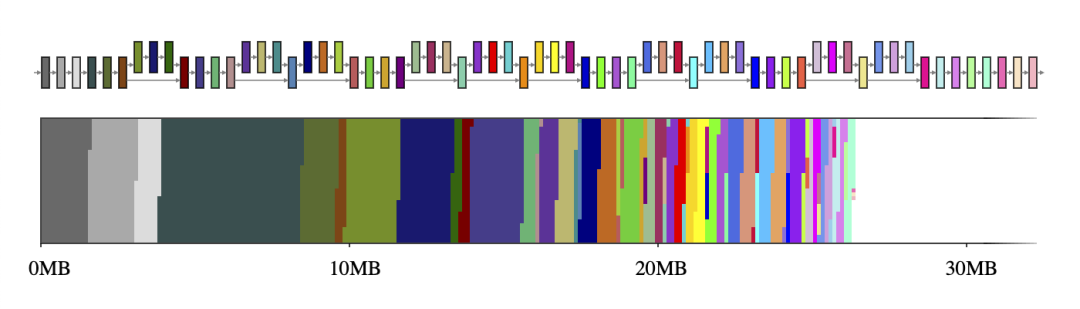
图 1. MobileNet v2 的中间张量(上图)及其到二维内存空间大小的映射(下图)。如果每个中间张量分别使用一个专用的内存缓冲区(用 65 种不同的颜色表示),它们将占用约 26MB 的运行时内存
好消息是,通过数据相关性分析,这些中间张量不必共存于内存中。如此一来,我们便可以重用中间张量的内存缓冲区,从而减少推理引擎占用的总内存。如果网络呈简单的链条形状,则两个大内存缓冲区即够用,因为它们可以在整个网络中来回互换。然而,对于形成复杂计算图的任意网络,这个NP 完备(NP-complete)资源分配问题需要一个良好的近似算法。
我们针对此问题设计了许多不同的近似算法,这些算法的表现取决于神经网络和内存缓冲区的属性,但都通过张量使用记录。中间张量的张量使用记录是一种辅助数据结构,其中包含有关张量的大小以及在给定的网络执行计划中首次最后一次使用时间的信息。借助这些记录,内存管理器能够在网络执行的任何时刻计算中间张量的使用情况,并优化其运行时内存以最大限度减少占用空间。
共享内存缓冲区对象
在 TFLite GPU OpenGL 后端中,我们为这些中间张量采用 GL 纹理。这种方式有几个有趣的限制:(a) 纹理一经创建便无法修改大小,以及 (b) 在给定时间只有一个着色器程序可以独占访问纹理对象。在这种共享内存缓冲区对象模式的目标是最小化对象池中创建的所有共享内存缓冲区对象的大小总和。这种优化与众所周知的寄存器分配问题类似,但每个对象的大小可变,因此优化起来要复杂得多。
根据前面提到的张量使用记录,我们设计了 5 种不同的算法,如表 1 所示。除了“最小成本流”以外,它们都是贪心算法,每个算法使用不同的启发式算法,但仍会达到或非常接近理论下限。根据网络拓扑,某些算法的性能要优于其他算法,但总体来说,GREEDY_BY_SIZE_IMPROVED 和 GREEDY_BY_BREADTH 产生的对象分配占用内存最小。
理论下限
https://arxiv.org/abs/2001.03288
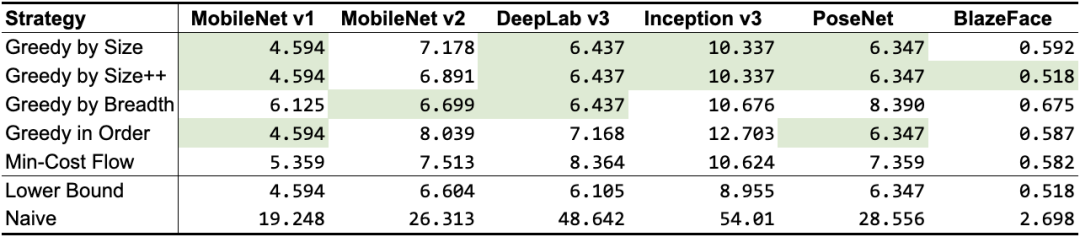
表 1. “共享对象”策略的内存占用量(以 MB 为单位;最佳结果以绿色突出显示)。前 5 行是我们的策略,后 2 行用作基准(“下限”表示最佳数的近似值,该值可能无法实现,而“朴素”表示为每个中间张量分配专属内存缓冲区的情况下可能的最差数)
回到我们的第一个示例,GREEDY_BY_BREADTH 在 MobileNet v2 上表现最佳,它利用了每个算子的宽度,即算子配置文件中所有张量的总和。图 2,尤其是与图 1 相比,突出了使用智能内存管理器的优势。
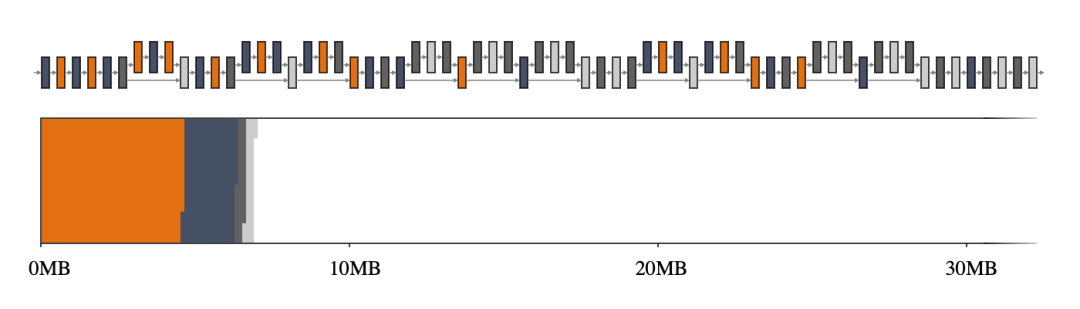
图 2. MobileNet v2 的中间张量(上图)及其大小到二维内存空间的映射(下图)。如果中间张量共享内存缓冲区(用 4 种不同的颜色表示),它们仅占用大约 7MB 的运行时内存
内存偏移量计算
对于在 CPU 上运行的 TFLite,适用于 GL 纹理的内存缓冲区属性不适用。因此,更常见的做法是提前分配一个大内存空间,并通过给定偏移量访问内存在所有不干扰其他读取和写入操作的读取器和写入器之间共享。这种内存偏移量计算法的目的是最大程度地减小内存空间的大小。
我们针对此优化问题设计了 3 种不同的算法,同时还分析了先前的研究工作(Sekiyama 等人于 2018 年提出的 Strip Packing)。与“共享对象”法类似,根据网络的不同,一些算法的性能优于其他算法,如表 2 所示。这项研究的一个收获是:“偏移量计算”法通常比“共享对象”法占用的空间更小。因此,如果适用,应该选择前者而不是后者。
Strip Packing
https://arxiv.org/abs/1804.10001

表 2. “偏移量计算”策略的内存占用量(以 MB 为单位;最佳结果以绿色突出显示)。前 3 行是我们的策略,接下来 1 行是先前的研究,后 2 行用作基准(“下限”表示最佳数的近似值,该值可能无法实现,而“朴素”表示为每个中间张量分配专属内存缓冲区的情况下可能的最差数)
这些针对 CPU 和 GPU 的内存优化默认已随过去几个稳定的 TFLite 版本一起提供,并已证明在支持更苛刻的最新模型(如 MobileBERT)方面很有优势。直接查看 GPU 实现和 CPU 实现,可以找到更多关于实现的细节。
MobileBERT
https://tfhub.dev/tensorflow/lite-model/mobilebert/1/default/1
GPU 实现
https://github.com/tensorflow/tensorflow/tree/master/tensorflow/lite/delegates/gpu/common/memory_management
CPU 实现
https://github.com/tensorflow/tensorflow/blob/master/tensorflow/lite/simple_memory_arena.h
致谢
感谢 Matthias Grundmann、Jared Duke 和 Sarah Sirajuddin,特别感谢 Andrei Kulik 参加了最开始的头脑风暴,同时感谢 Terry Heo 完成 TFLite 的最终实现。
责任编辑:xj
原文标题:优化 TensorFlow Lite 推理运行环境内存占用
文章出处:【微信公众号:TensorFlow】欢迎添加关注!文章转载请注明出处。
-
神经网络
+关注
关注
42文章
4845浏览量
108373 -
张量
+关注
关注
0文章
7浏览量
2698 -
tensorflow
+关注
关注
13文章
336浏览量
62444 -
TensorFlow Lite
+关注
关注
0文章
26浏览量
850
原文标题:优化 TensorFlow Lite 推理运行环境内存占用
文章出处:【微信号:tensorflowers,微信公众号:Tensorflowers】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
LuatOS的内存分配机制

将TensorFlowSavedModel转换为支持imx8mpNPU的tflite模型,没有成功是怎么回事?
eiQ Toolkit TFLite 转换器失败问题可能出在什么地方
在 NPU 上运行了 eIQ TensorFlow Lite 示例模型报错
基于芯科科技xG24开发套件实现语音控制灯光的简易步骤
IMX95 - NPU 不工作的原因?怎么解决?
借助谷歌LiteRT构建下一代高性能端侧AI

容易造成单片机内存溢出的几个陷阱介绍
如何在TensorFlow Lite Micro中添加自定义操作符(1)
【上海晶珩睿莓1开发板试用体验】将TensorFlow-Lite物体归类(classify)的输出图片移植到LVGL9.3界面中
【上海晶珩睿莓1开发板试用体验】TensorFlow-Lite物体归类(classify)
了解SOLIDWORKS202仿真方面的改进
澜起科技凭借在内存接口和高速互连芯片领域的突破性创新荣膺《财富》中国科技50强
如何进行tflite模型量化



评论