 全球最新TOP500超算榜单出炉!揭秘英伟达雄霸三分之二版图的扩张之路!
全球最新TOP500超算榜单出炉!揭秘英伟达雄霸三分之二版图的扩张之路!

6月22日,2020国际超算大会(ISC2020)期间,最新的TOP500超级计算机榜单发布。这份榜单展现了全球现代科学计算的整体情况,而引人注意的是,排名前十的超级计算机中有8台采用了NVIDIA的技术;TOP500榜单的所有系统中,有三分之二的系统(333套)由NVIDIA助力。
而不仅是当前产品和技术层面的大范围覆盖,NVIDIA正在推动数据分析、模拟、可视化、边缘串流、AI、云技术在现代科学计算中的应用,来应对当今和未来的挑战。
英伟达超算江湖地位再度刷新
Top500榜单每年更新两次,这份最新的榜单显示,全球排名前十的超级计算机中有8台采用了NVIDIA GPU、InfiniBand网络技术,或同时采用了两种技术。其中包括美国、欧洲和中国最强大的超级计算机系统。在TOP500榜单的所有系统中,有三分之二的系统(333套)采用了NVIDIA(包括收购的Mellanox)为其赋力。而在2017年6月发布的榜单上,采用两家公司的系统占比总和还不到一半(203套)。
如今,榜单上有将近四分之三(74%)的全新InfiniBand系统采用了NVIDIA Mellanox HDR 200G InfiniBand,这也展现了这一智能高速数据互连技术的迅速普及。自2019年11月以来,榜单上使用HDR InfiniBand的TOP500系统数量几乎增加了一倍。共有141台超级计算机使用了InfiniBand,自2019年6月以来增长了12%。
在TOP500超级计算机中,有305套系统使用了NVIDIA Mellanox InfiniBand和Ethernet网络(占61%),包括所有141套InfiniBand系统和164套(占63%)使用Ethernet的系统。
越来越多TOP500系统正在采用NVIDIA GPU、Mellanox网络技术,
或同时采用了这两种技术。
或同时采用了这两种技术。
TOP500榜单前25的超级计算机中有20台系统都选择采用NVIDIA GPU,为什么?能效是主要原因。如下图所示,使用NVIDIA GPU的系统,与不使用NVIDIA GPU的系统相比,能效(以gigaflops/watt为单位)平均高出2.8倍。
4周构建顶级超级计算机,每秒百亿亿次的AI算力!
TOP500和Green500榜单进行排名的主要参考依据之一就是LinPack BenchMark性能基准。在计算系统中,每瓦性能(GFloat/watts)是衡量特定计算机体系结构或计算机硬件能效的量度。从字面上来说,它衡量计算机可以为每瓦功耗消耗的计算速率。要指出的是,相比TOP500,Green500更加重视超算的能耗问题,而不仅仅追求运算速度。NVIDIA内部研究集群的新成员Selene,能够充分证明NVIDIA GPU的能效表现。在Linpack基准测试中,Selene以27.5petaflops的性能表现,在最新Green500榜单中排名第二,在整个TOP500榜单中排名第七。
Selene的功耗为20.5 gigaflops/watt,与Green500榜单上的第一名相差甚微,不过,排名第一的系统体积更小,其性能表现仅排在第394位。
这也意味着,Selene是排名前100系统中唯一突破20 gigaflops/watt能效表现大关的系统,同时也是全球性能排名第二的工业超级计算机,仅次于意大利能源巨头Eni S.p.A.的No. 6 系统(同样使用了NVIDIA GPU)。
在能效方面,相比于未使用NVIDIA GPU的其它TOP500系统的平均能效表现,Selene的能效高出了6.8倍。
据NVIDIA加速计算产品管理总监Paresh Kharya介绍,除了能效表现,Selene另一个了不起的地方在于,它是一个只用了不到4周的时间就构建完成的系统,由14套分别配置有20台DGX A100系统的模块相连接,Selene具有:280台DGX A100系统、2240颗NVIDIA A100 GPU、494台NVIDIA Mellanox Quantum 200G InfiniBand交换机、56 TB/s的网络架构、7PB的高性能全闪存。
Selene最重要的性能规格之一是可以提供超过1 exaflops的AI性能。此外,在TPCx-BB关键数据分析基准测试中,仅使用了16台DGX A100系统就创造了新纪录,性能表现高出其他系统20倍。
如今,AI和分析已成为科学计算中的新需求,因此这些结果也显得格外重要。在全球各地,研究者正在使用深度学习和数据分析预测各种最具潜力的领域,并进而开展实验。这一方法能够帮助研究者减少成本高昂且费时的实验量,从而加快取得科学成果的速度。
A100按下HPC和AI融合的快进键
在把GPU做“大”这件事上,A100就像是一个大型核反应堆。从2016年的P100,到2020年的A100,性能提升9倍之多。黄仁勋上个月从家中烤箱中端出的“世界上最大的显卡”DGX A100就是其杰作之一,而最新发布的Selene更是进一步论证了它的“恐怖”之处。根据今年GTC上黄仁勋的发布,A100 Tensor Core的一大创新之处就是引入了TensorFloat-32(TF32)来加速FP32运算,TF32结合了FP32的动态范围和FP16的精度。据称在HPC的线性动力学场景中可以获得4倍的性能提升,并在单精度训练中达到5倍的性能。总之,第三代Tensor Core核心可以为传统的64位数学模拟及精度较低的AI工作提供加速。
HPC和AI的融合,就像被NVIDIA按下快进键,AI、数据科学和科学计算交融的新时代在风驰电掣般赶来。
目前,全球顶尖供应商预计将发布超过50款内置A100的服务器,其中包括:华硕、Atos、思科、Dell Technologies、富士通、技嘉科技、HPE、浪潮、联想、One Stop Systems、Quanta/QCT和Supermicro。
这些服务器的上市时间各不相同,预计今年夏天将有30款系统上市,到年底将再有20多款系统上市。
据了解,目前并未出现在此次TOP500榜单中的6台在建系统,也都采用了A100 GPU。
软硬件结合树立大数据分析新标杆
如今领先的企业机构都在使用AI获得生产力和先进洞见。TPCx-BB是用于实际ETL(提取、转换、加载)和机器学习工作流程的企业大数据基准测试。该基准测试的30个查询项目包含多种大数据分析用例,例如库存管理、价格分析、销售分析、推荐系统、客户细分和情绪分析。
过去,这项基准测试一直只在CPU系统上运行。分布式计算系统虽然在稳步改进,但是运行如此大的数据工作负载仍会遇到瓶颈。NVIDIA通过RAPIDS软件生态系统和DGX A100系统,以19.5倍TPCx-BB性能打破纪录,树立了大数据分析的新标杆。
在这一基准测试中,采用RAPIDS开源数据科学软件库套件,并使用由16台NVIDIA DGX A100系统组成的集群,NVIDIA用时14.5分钟就完成了基准测试,而此前在CPU系统上运行的记录是4.7小时。该DGX A100集群系统共配置了128块NVIDIA A100 GPU,并配有NVIDIA Mellanox网络功能。这一软硬结合的系统可加速计算、通信、网络和存储基础设施。
30个TPCx BB基准测试查询结果
RAPIDS在16台DGX A100系统上运行,为每个10TB测试查询提供上述相对性能提升。与传统上使用CPU的方案相比,RAPIDS和DGX A100系统的成本是其1/7,功耗是其1/3。
此外,NVIDIA通过与开源社区合作,为Apache Spark 3.0带来端到端的GPU加速,能够为关键且耗时的机器学习处理流程前端提供支持。
AI模型训练将能够在相同的 Spark集群上进行处理,而不是将工作负载作为单独的流程在单独的基础架构上运行。这样就可以对整个数据科学的处理流程进行高性能数据分析,对从数据湖到模型训练所涉及的数十、乃至数千TB的数据进行加速,而且无需对已被应用于本地和云端 Spark 应用程序的现有代码进行修改。
收购Mellanox所获增益大举浮现
NVIDIA在超算这一尖端领域攻城掠地的大举扩张,也与Mellanox的贡献密不可分,这也再次验证了这笔收购的战略眼光。其产品线与NVIDIA极具互补性,通过Mellanox的InfiniBand、以太网等技术,NVIDIA拥有了更强的网络服务和云端能力,形成了更为强大的整体解决方案能力。此次TOP500的榜单显示,InfiniBand为排名前10的超级计算机中的7台提速,其中包括中国、欧洲和美国性能最强大的系统。
据了解,InfiniBand的设计基于四项基本原则:可以运行所有网络引擎的智能端点设计;为扩展设计的软件定义交换网络;可以对网络进行一站式控制和操作的集中式管理;以及确保正向和反向兼容并支持开源技术和开放API的标准技术。
正是这些基本原则帮助InfiniBand实现了高网络性能、低延迟和高速信息收发。作为目前市面上唯一的200Gb/s高速互连产品,InfiniBand通过端对端自适应路由、拥塞控制和服务质量实现高网络效率。
除了高质量、高效的网络,数据中心的停机所带来的成本损失也不容忽略。根据ITIC的研究,停机1小时所造成的成本损失通常在30万美元以上。为了尽可能避免超算数据中心停机所带来的损失,NVIDIA推出了最新的UFM Cyber-AI平台。据了解,UFM平台产品系列已管理InfiniBand系统近十年,此次扩展将使用AI通过实时和历史遥测及工作负载数据,来学习数据中心的运行节奏和网络工作负载模式。从而根据这一基准,追踪系统的运行状况和网络修改并检测性能下降、使用情况和配置文件更改。
据NVIDIA Mellanox网络事业部高级营销副总裁Gilad Shainer介绍,该平台能够确定数据中心的独特生命体征,并通过它们识别性能下降、组件故障和异常使用方式,从而使系统管理员快速检测和响应潜在的安全威胁并解决即将发生的故障。
InfiniBand已成为气候研究和天气预报应用的实际标准。全球许多气象服务机构都已选择了NVIDIA Mellanox InfiniBand网络,来加速其超级计算平台,例如西班牙气象局、中国气象局、芬兰气象局、NASA和荷兰皇家气象局。
北京市气象台选择了200 Gigabit HDR InfiniBand互连技术,来加速超级计算平台。该平台将被用于增强天气预报、改进气候和环境研究,并将被用于2022年北京冬季奥运会的天气预报。
由于气象和气候模型都是计算和数据密集型模型,预测质量通常取决于模型的复杂性和高分辨率,其中分辨率取决于超级计算机的性能,而超级计算机的性能又取决于互连技术是否能够在各计算资源之间快速、有效并且以可扩展的方式移动数据。
天气预报,正在成为被超算改变的一个新领域。而NVIDIA A100 GPU和Mellanox HDR InfiniBand网络技术所掀起的超算风暴,绝不仅止于此。
加速计算正在被重新定义
由于疫情的原因,今年的超算大会对于COVID-19相关技术和方案也给予了更多的重视。NVIDIA科学计算平台所发挥的作用,也使加速计算的未来呈现出了更多的可能性。从数据分析到模拟和可视化再到AI与边缘处理,其平台为各个领域的方法提供加速。
AI、数据分析和边缘串流正在重新定义科学计算。随着向深度学习和分析的扩展,科学家们也在运用云计算服务,甚至运用来自于网络边缘的远程仪器的流式数据,这些要素共同构成了NVIDIA所加速的科学计算支柱。
除了前文着墨较多的一些进展之外,几个前沿的案例很值得关注和思考:
模拟方面,在抗击新冠病毒的过程中,橡树岭国家实验室(Oak Ridge National Laboratory)的研究者使用Summit超级计算机的内置GPU运行AutoDock,在24小时内模拟了20亿种化合物。
科学边缘串流方面,欧洲核子研究所(CERN)最近宣布,NVIDIA GPU将使其大型强子对撞机内粒子碰撞事件产生的数据量减少500倍。
可视化方面,NVIDIA的IndeX和Magnum IO软件帮助增强火星登陆者号的可视化功能,这是全球规模最大的交互式实时立体可视化项目。
NVIDIA方面表示,最新的TOP500榜单以另一种方式说明了NVIDIA为实现AI和HPC民主化所付出的努力。而不论是研究者还是企业,都迫切需要从云到网络边缘的AI和分析加速。
为科学计算提供端对端的工作流程,采取完整的创新策略来加速所有关键应用领域,这是NVIDIA在加速计算领域的两大成功秘笈。
本文由电子发烧友网原创,未经授权禁止转载。如需转载,请添加微信号elecfans999.
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
NVIDIA
+关注
关注
14文章
5496浏览量
109076 -
gpu
+关注
关注
28文章
5099浏览量
134445 -
InfiniBand
+关注
关注
1文章
31浏览量
9534 -
Mellanox
+关注
关注
0文章
15浏览量
9617
发布评论请先 登录
相关推荐
热点推荐
英伟达5万亿市值背后,是一场赌上未来的烧钱竞赛
电子发烧友网报道(文/梁浩斌)最近,英伟达成为全球历史上首家市值突破5万亿美元的企业,如果以GDP计算,英伟达市值已经超越德国和日本,成为全球

AI驱动量子化学计算!4100万核心国产超算取得世界级突破!
电子发烧友网报道(文/梁浩斌)中国超算的高光时刻,是2016年到2017年期间,神威·太湖之光连续四次登顶全球超级计算机TOP 500
全球前四!京东云云海AI存储跻身IO500高性能存储榜单
近日,在最新公布的 IO500 排行榜中,京东云云海 AI 存储基于通用 NVMe 盘存储服务器,结合全栈自研软件体系与深度调优,成功跻身 IO500 生产榜单全球前四、国产自研第一。

聚飞光电入选2025深圳企业500强榜单
近日,深圳市企业联合会、深圳市企业家协会正式发布“2025深圳企业500强榜单”及《2025深圳500强企业发展报告》。聚飞光电连续八年登榜,位列第275位,同时入选创新能力TOP10
AI贸易激增,储能系统如何借力CM4A霍尔传感器实现智能化升级?
近日,WTO统计官员在WTO全球贸易展望报告记者会上表示,2025年上半年亚洲占据了全球人工智能贸易增长的三分之二,智能化浪潮正以前所未有的速度重塑各行各业,AI技术也会从消费端走向产业端,与能源

国家网信办约谈英伟达
近日,英伟达算力芯片被曝出存在严重安全问题。此前,美议员呼吁要求美出口的先进芯片必须配备“追踪定位”功能。美人工智能领域专家透露,英伟达
英伟达一夜大涨1.2万亿元,市值重回全球第一!
美元,市值达到3.77万亿美元,超越微软(3.66万亿美元)重回全球市值第一。这是继2024年6月和2025年1月之后,英伟达第三次登顶全球

英伟达AI人才,去了华为
都在帮华为写程序。 黄仁勋此前提到,中国是世界上最大的AI市场之一,也是通往全球成功的跳板。世界上有一半的AI研究人员在那里,赢得中国市场的平台将引领全球。据报道,中国在2019年约有全球
传音控股入选2024新经济企业TOP500
近日,第五届新经济企业高质量发展大会在上海举行,会上发布了“2024新经济企业TOP500”榜单,这是中国企业评价协会连续第五年发布该榜单。传音控股凭借卓越的技术创新实力和国际影响力再度上榜,位列
软通动力荣登“新经济企业500强”榜单
近日,第五届新经济企业高质量发展大会在上海成功召开。本次大会以“智启新经济 共享新未来”为主题,汇聚国家部委领导、专家学者、企业领袖等各界精英,共议新经济发展的前沿趋势与实践路径。软通动力凭借在智能制造、产业数字化转型等领域的卓越表现,再度入选“新经济企业TOP500”榜单
海格通信荣获2024中国新经济企业TOP500强
近日,由中国企业评价协会主办,北京大学国家发展研究院和中指研究院联合支持的第五届新经济企业高质量发展大会在上海隆重举行,海格通信(SZ 002465)受邀参会,并再次荣登“中国新经济企业TOP500”榜。
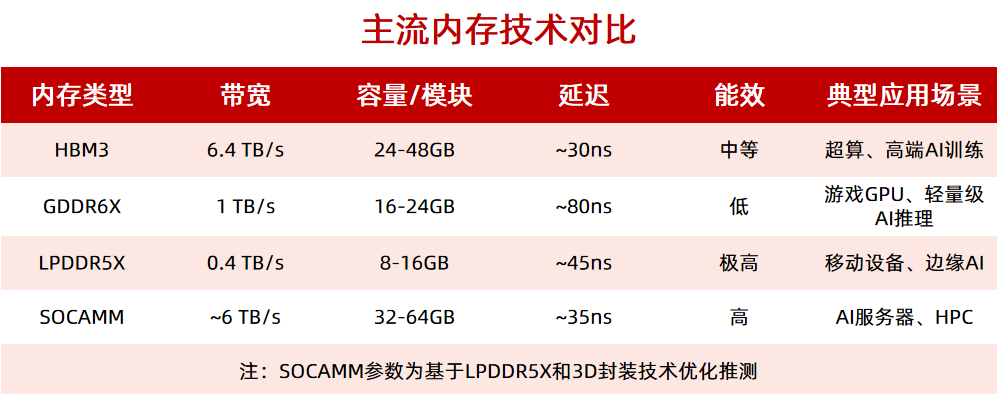
英伟达开发新型内存模组SOCAMM,或年底量产
大内存制造商深入讨论SOCAMM规范的商业化落地可能性。这意味着,SOCAMM内存模组有望最早在今年年底实现量产,为全球用户带来更加高效、稳定的内存解决方案。 值得一提的是,英伟达计划在其备受瞩目的第
英伟达力推SOCAMM内存量产:可插拔、带宽比肩HBM
模组技术,是由英伟达主导研发的面向AI计算、HPC、数据中心等领域的高密度内存解决方案,旨在通过紧凑的设计实现最大化存储容量,保持极佳的性能,并使用可拆卸的设计,便于用户可以对内存模块灵活进行升级和更换。 在CES2025上,英伟
芯盾时代荣登“人工智能应用标杆TOP100”榜单
近日,备受瞩目的第二届人工智能产业应用大会圆满落幕。会上,新智引擎与中关村人工智能研究院携手发布了备受关注的“人工智能应用标杆TOP100”榜单。这一榜单旨在表彰在人工智能领域具有卓越





 工商网监
工商网监
评论