 Xbox Series X GPU相比RX 5700 XT性能要快12%
Xbox Series X GPU相比RX 5700 XT性能要快12%

(文章来源:忘川沙华)
微软已经解除了Xbox Series X规格的限制,这对我们PC游戏玩家来说是大开眼界。Xbox的宣布使AMD负责芯片设计,并带来了RDNA2,Xbox的发布使我们可以快速了解PC游戏以及Radeon团队的游戏PC的存储内容。您可能已经听说过这个消息:AMD随Xbox Series X一起提供了具有12个TFLOP的GPU。从理论上讲,这在原始计算中相当于Nvidia的RTX 2080 Ti,但让我们解释一下这对AMD,RDNA 2的真正含义。
尽管在原始计算性能方面为12个TFLOP,但它不能代表游戏性能。在计算能力和更高的游戏帧数之间存在大量的架构优化。以AMD的RX Vega 64为例。该Vega GPU的额定值为12.66 TFLOP(单精度),与Series X GPU相当。按照该指标,而Nvidia的RTX 2080 Ti则要超过12-14个TFLOP。
这是因为Vega架构基于GCN,并且最适合于以计算为中心的任务。在游戏任务中,它需要进行优化以适应最新发展,很少有开发人员认为适合引入。因此,为什么要创建RDNA–是一种从GCN派生出来并从头开始构建用于游戏的架构。
但是这里存在问题。我们不能肯定地说RDNA 2将比Vega有多大改进,也不能肯定其优化与TSMC的7nm +工艺节点一起在性能上可与Nvidia Turing相提并论。相反,我们至少可以推测出与现有高端RDNA图形卡RX 5700 XT相比的游戏性能。
RX 5700 XT的峰值约为9.8 TFLOP,并根据所使用的游戏和API在RTX 2060 Super和RTX 2070 Super之间提供性能。在我们的基准测试套件中,它也比RX 5700快了12%,而RX 5700的计算性能为7.9 TFLOP。
按照这种逻辑,具有12个TFLOP的RDNA GPU将能够管理性能,使其能够打入Nvidia最昂贵的RTX 20系列图形卡的高端,并且比RX 5700 XT至少快12%。这可能需要将GPU与48个或56个CU配合使用。最终时钟速度取决于内核总数– 56 CU GPU达到12个TFLOP大约需要1.6 GHz,而48 CU GPU大约需要2 GHz以下。
但是我们也知道,AMD将为RDNA 2选择TSMC的7nm +工艺节点(N7 +),这有望对AMD现有Ryzen和Navi系列产品中采用的现有7nm节点(N7)进行适度改进。随着Radeon和Zen团队之间协同增效带来的效率提升,我们怀疑真正的交易比最低的12%博恩快了一定程度。
也有需要考虑的记忆。Xbox Series X将配备GDDR6,我们怀疑它会足够满足最新的Triple-A游戏的需求。可以说,AMD正在开发一种至少将在高端领域挑战Nvidia的GPU,而Radeon近年来却做不到。但是从Xbox的公告中也进一步证实了可变速率阴影(VRS)和硬件加速的光线追踪。
总而言之,在Xbox Series X,PlayStation 5以及他们在Microsoft和Sony梦寐以求的使用AMD技术,只会对AMD的Zen 2和RDNA生态系统带来好处。看来AMD最终将拥有一款能够与Nvidia的顶级显卡竞争的显卡。无论如何,感谢这些技术将我们的游戏体验变得更好。
(责任编辑:fqj)
-
显卡
+关注
关注
16文章
2517浏览量
71063 -
Xbox
+关注
关注
0文章
187浏览量
17776
发布评论请先 登录
NVIDIA RTX PRO 2000 Blackwell GPU性能测试

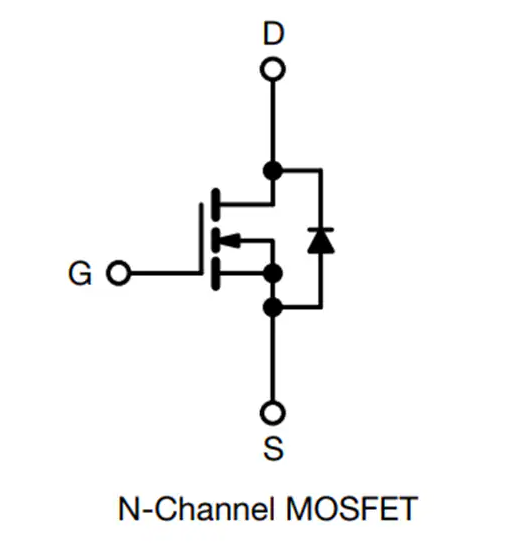
Vishay SiRS5700DP N沟道MOSFET技术深度解析:性能优势与应用实践
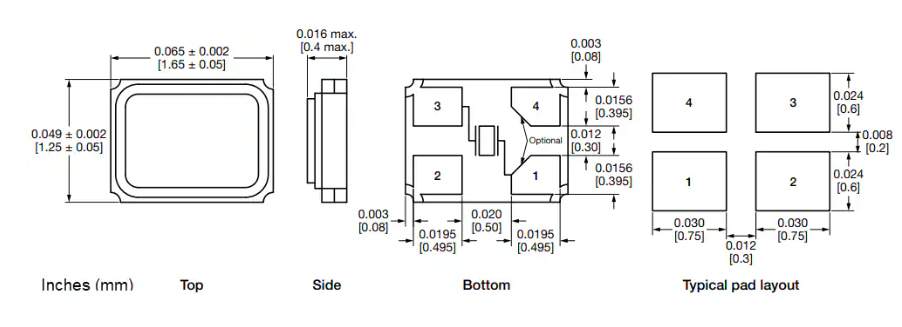
Vishay XT11系列微型晶体技术深度解析与应用指南
用于 LTE / EUTRAN 频段 IV / X (Tx 1710-1770 MHz)、(Rx 2110-2170 MHz) 的前端模块 skyworksinc

【「算力芯片 | 高性能 CPU/GPU/NPU 微架构分析」阅读体验】+NVlink技术从应用到原理
Imagination 宣布推出 E-Series GPU:开启Edge AI 与图形处理新时代
Imagination 宣布推出 E-Series GPU:开启Edge AI 与图形处理新时代

可以手动构建imx-gpu-viv吗?
为什么GPU性能效率比峰值性能更关键
GSDRO1500-8XT介质谐振器振荡器Synergy
应用资料#QFN12x12封装600V GaN功率级热性能总结
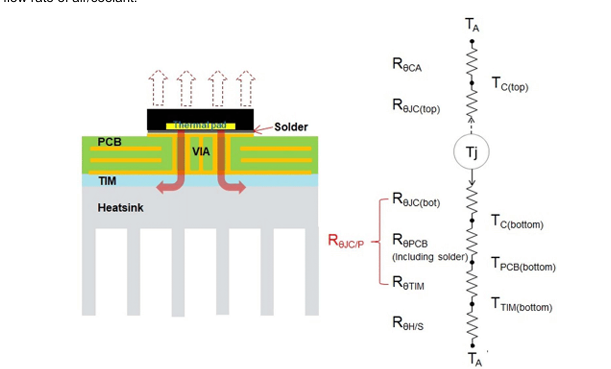
GPU 性能原理拆解






 工商网监
工商网监
评论