 AMD如何将Rome Epycs与Xeon竞争对手相抗衡
AMD如何将Rome Epycs与Xeon竞争对手相抗衡

在任何芯片设计中,天使和魔鬼都在细节之中。AMD过去对皓龙处理器(Opteron)做出的一些架构选择让它备受煎熬,关于代码如何利用硬件的假设并没有按计划实现。老款皓龙处理器(Opteron)处理器最初的设计非常出色,但公司似乎有意避免在后续产品上犯同样的错误,比如第二代霄龙(Epyc)服务器芯片。
时间和客户将会告诉我们答案,但这一衍生产品的优势在于,它采用了经过大幅改进的多芯片设计,核心采用了更先进的蚀刻工艺,似乎正以它在最需要的时候想要的东西,准确地打入服务器市场。这对霄龙(Epyc)芯片的发展来说是个好的开始,它将取代英特尔目前和未来的至强(Xeon)芯片。 我们一直渴望了解新的“罗马”霄龙(Epyc)服务器芯片的架构细节,我们在上周的发布会上介绍了基本的概况、速度、插槽、功率和定价。现在,让我们和Mike Clark一起深入了解罗马处理器的架构细节,Mike Clark是Zen核架构的研发主力,同时也是AMD的企业院士(Corporate Fellow)。从很多方面来说,拥有Zen 2核和混合处理多芯片模块设计的罗马处理器(Rome),是AMD两年前就希望能够布局的领域。相比之下,罗马处理器(Rome)现在越来越好,这一切都始于晶圆代工合作伙伴台积电在处理器核及其相关L1和L2缓存区域采用了7nm先进的的蚀刻工艺。 Clark苦笑着说:"能在工艺技术领域处于领先地位是件好事。"他补充称,英特尔和AMD将在未来几年实现跨越式发展,因此这一胜利不会是永久性的,即便这是不可否认的,也是战略性的胜利。“这个7nm工艺带来了显著的改进。有趣的是,它使我们的晶体管密度提高了2倍,但是关于主频,实际上与台积电TSMC和及工具人员做了大量工作。通常,当你使用一项新技术时,主频会下降,你会失去Vmax,需要一些时间才能使主频恢复到原来的水平。但是我们能够和他们一起创造一个非常好的7nm的主频并且保持同样的功率。当然,如果你从另一个角度来看晶体管,你可以在同样的性能水平上获得一半的功率。” 每个时钟或IPC指令也是罗马处理器(Rome)架构的重要组成部分。从几年前最后一次Opterons芯片使用的“Excavator”核心到“Naples”霄龙(Epyc)芯片使用的Zen 1核,AMD能够在固定时钟的基础上将IPC增加50%,这是一个巨大的飞跃。类似于ARM的“Ares” Neoverse设计。ARM实际上预计IPC将增加60%,但公平地说,Excavator Opterons和Cortex-A72芯片一开始在IPC方面都不是很强大——至少与英特尔的Xeon核无法相提并论。现在,AMD和ARM正在迎头赶上,随着Zen 2内核在罗马处理器(Rome)上的使用,AMD又增加了15%的IPC。英特尔新一代IPC的改进幅度在5%到10%之间,大约是平均水平的一半。
Clark说,当IPC上升时,芯片架构师通常要付出更高的功耗的代价,但是Zen 2核设计的目标是使其与Naples的Zen 1相比保持功率持平。事实证明,罗马处理器的工程师为此施加了压力,并且能够将核的功耗降低10%,超过了通过微缩工艺从Naples的14纳米到用于Zen 2的7纳米的功耗。实现这一目标的主要方法之一是将核心中的操作缓存加倍,这有助于降低功耗并提高性能。 事实上,AMD实际上把每个Zen 2核上的L1指令缓存从64 KB缩小到了32 KB,并把晶体管的区域还给了op和分支预测单元,还用其中的一些增加了第三个地址生成单元。将L1数据与指令缓存(均为32kb)的关联度提高一倍,达到8路,AMD将浮点数据路径宽度加倍,然后将L1缓存带宽加倍,以跟上它的速度。(Clark说,一个64 KB的8路关联L1缓存将占用太多的功率,而对于64核,这将是一个大问题。)L3的缓存在每个小芯片(Chiplets)上加倍,达到16MB/ pop,并且在封装上有两倍多的chiplets,是L3缓存容量(256MB)的四倍,相当于Naples 处理器的容量。它并不是把所有的东西都翻倍,但随着核数和chiplet翻倍,试图达到更好的平衡。这包括分支预测、指令获取和指令解码单元,如下图所示:
“我们喜欢能同时提高功率和性能,”Clark解释道。“经常地走在正确的道路上是很重要的,因为最糟糕的功耗使用就是执行那些你正要扔掉的指令。”在我们动态地发现我们做错了之后,我们并没有扔掉进程。这肯定会在前端消耗更多的功耗,但在后端会带来好处。” 这就引出了Zen 2核心中的整数和浮点指令单元。
在整数方面,算术逻辑单元(ALU)计数在4处保持相同,但是Zen 2内核中的地址生成单元(AGU)计数增加了1,总数为3。ALUs和AGUs的调度程序都得到了改进,寄存器文件和重新排序缓冲区的大小也得到了提高。并且针对ALUs和AGUs,控制同时多线程(SMT)的算法的公平性也进行了调整,以处理Zen 1的设计中不平衡。
当然,英特尔四年前在“Knights Landing”Xeon Phi处理器中实现了一个非常优雅的512位宽AVX-512矢量单元,并带来了它的一个变量 - 有人会说一个不太优雅的变量,因为它更难以由于它的实施方式而保持供给 - 对于“Skylake”Xeon SP处理器而言,使用当前的“Cascade Lake”Xeon SP芯片基本保持不变,除了能够在机器学习推理工作负载中消耗一半精度的指令之外。 Clark表示AMD正在考虑在未来的霄龙(Epyc)芯片中使用512位向量,但此时并不相信只添加更宽的向量是消耗晶体管预算的最佳方法。首先,Clark补充说仍有很多浮点例程不能与512位并行 - 有时甚至不能达到256位或128位-因此,在Epyc行中,在向量引擎上移动到512位是有意义的。我们认为,AMD可能会成为一个快速的追随者,做类似于DLBoost机器学习推理指令的事情。也许该功能已经在框架中,等待在将来某个软件堆栈准备就绪时激活。 在Zen 1内核中,它有一对128位向量,执行AVX-256指令需要两个操作,但是Zen 2可以在一个时钟中运行AVX-256指令;这显然需要更少的能量。双精度乘法在Zen 1上花费了四个周期,而在Zen 2上只花费了三个周期,这提高了浮点单元的吞吐量和功率效率。(上面引用的IPC图用于整数指令,而不是浮点指令。) 至于为Zen 2内核供电的高速缓存,支持高速缓存的所有结构都更大,并提供更高的吞吐量,从而推动IPC:
下面是Zen 2的CPU复杂度和缓存层次结构:
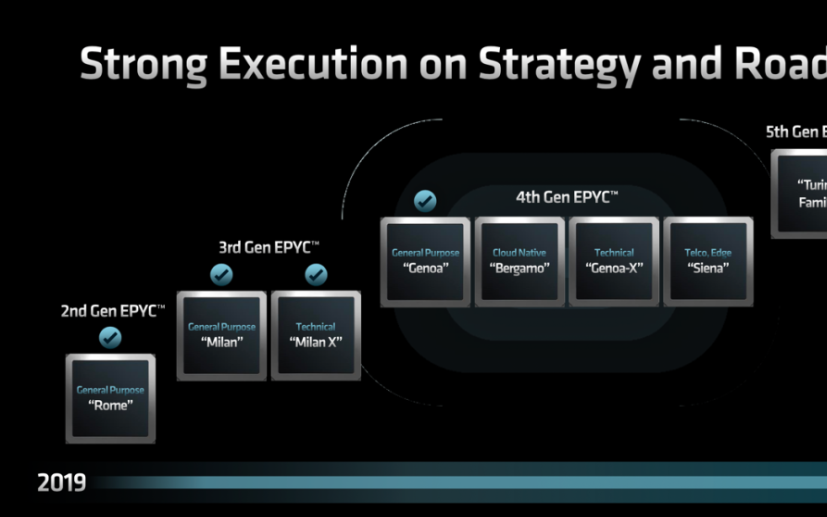
增加每个核心中的L2缓存和核心上的L3缓存是实现Zen 2核心中潜在IPC的关键,因为正如Clark正确地说的那样:“减少内存延迟的最佳方法是一开始就不去那里。“ 加上这一切,你将8个CPU复合体以及I / O和内存集线器 - 总共9个芯片 - 放到封装上,制成一个顶级的罗马Epyc。较低的仓库SKU在封装上具有较少的核心小芯片,有时在每个裸片上激活的核心较少,这就产生了罗马Epyc 7002系列芯片的广度,正如我们上周详述的那样。 这是拆除Naples和罗马的MCMs,显然它们的结构非常不同:
使用PCI-Express的第二代Infinity Fabric变体进行了一些重要更改,这些变体分别用于将Naples和罗马插座中的小芯片相互链接。Naples小芯片可以在一个时钟内对Infinity Fabric进行16字节读取和16字节写入 - 精细打印中的FCLK是结构时钟的缩写 - 而罗马芯片中的Infinity Fabric可以读取32字节和16每个结构时钟的字节写入。 虽然罗马芯片插入与Naples芯片相同的插槽,但元件在插座内部捆绑在一起的方式却截然不同。内存控制器从CPU复杂小芯片上移到中央集线器上,在14纳米工艺中蚀刻,其运行速度比在7纳米时更好,因为I / O和内存必须将信号从封装中推出并进入主板DRAM和PCI-Express外围设备插入的地方。这个集线器芯片共有8个DDR4内存控制器,总数与Naples综合体相同;每个通道都支持一个DIMM,每个控制器有两个通道,但罗马内存运行速度稍快--3.2 GHz对2.67 GHz - 因此填充所有内存插槽时,每个插槽最大可产生410 GB /秒的峰值内存带宽。这比Cascade Lake Xeon SP处理器高45%,该处理器有6个内存控制器,总运行频率为282 GB /秒,运行频率为2.93 GHz,比Naples运行2.67 GHz的340 GB /秒高出21% DRAM。(这些是双插槽服务器的评级。) 罗马Epycs的真正重大变化,以及将对许多不同工作负载的性能产生有益影响的变化,就是NUMA域在芯片中的创建方式以及NUMA跳数的减少 - 下图中的距离 - 这是从处理器复合体的一部分移动到另一部分所需的。看一看:
这基本上是一个NUMA服务器,该中心集线器是一个芯片组,使用非统一的内存访问技术将chiplets(在这个类比中是插槽)连接到一个婴儿共享内存系统中,从而将缓存和主内存捆绑在一起。 使用Naples芯片,从任何一个裸片到另一个裸片有三种不同的距离,这就是内存挂起。有一个跳到两个相邻的芯片,有时两个跳到对角线对面,三个到第二个插座中的芯片在双插槽设置中。现在,有两个NUMA域,只有两个不同的距离。它是从一个小芯片通过中央集线器到连接到任何处理器的内存的一跳,然后另一个跳过Infinity Fabric到第二个中央集线器以及挂起它的内存。为了进一步简化问题,只有两个NUMA域 - 每个罗马复合体一个。这应该使Windows Server和Linux在单插槽和双插槽系统上运行得更好,Clark 说,对于 Naples 而言,Windows Server在实施NUMA方面比Linux更麻烦。对罗马NUMA架构的这些变化的结果是,性能应该更好,更均匀,并且需要更广泛的工作负载才能启动。I / O和内存控制器集线器芯片还实现了用于将外围设备连接到系统的PCI-Express 4.0通道,在双插槽服务器的情况下,将一对罗马计算复合体相互捆绑在一起。 与Naples芯片一样,每个罗马芯片都有128个PCI-Express通道,可以通过多种不同方式进行配置,如下图所示:
与Naples一样,PCI总线的一半用于实现两个插座之间的NUMA链路,因此单插槽和双插槽罗马只有128个PCI-Express通道用于外围设备。罗马的网卡有两倍的带宽,实际上可以驱动100 Gb /秒和200 Gb /秒的适配器,而PCI-Express 3.0在使用前者方面遇到了麻烦,而在普通的x8插槽中则不能用后者。这些通道可以单独使用,通常组合成一对(x2)用于存储设备,可能为罗马系统中的56个NVM-Express驱动器和高速网络接口卡留出空间。 从技术上讲,Naples芯片有一个单独的x1通道,与Infinity Fabric控件分开。由于存在中央集线器,因此x1通道也可用于其他流量。这意味着单插槽罗马服务器技术上有129个PCI-Express 4.0通道,而双插槽罗马服务器有130个通道。英特尔至强可以缩小到x4通道; 据Clark说,他们不能做x2或x1车道。我们以前没有听过这个。 最后,Zen 2核心有一些架构扩展,这里概述了这些扩展,并没有被反馈到Naples芯片的Zen 1核心:
接下来,我们将看看AMD如何将Rome Epycs与Xeon竞争对手相抗衡,以及英特尔对Rome芯片最初和长期的反应。
-
amd
+关注
关注
25文章
5648浏览量
139041 -
晶圆代工
+关注
关注
6文章
872浏览量
49667 -
服务器芯片
+关注
关注
2文章
127浏览量
19733
原文标题:挑战Intel,AMD拥有足够的底气吗?
文章出处:【微信号:icbank,微信公众号:icbank】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
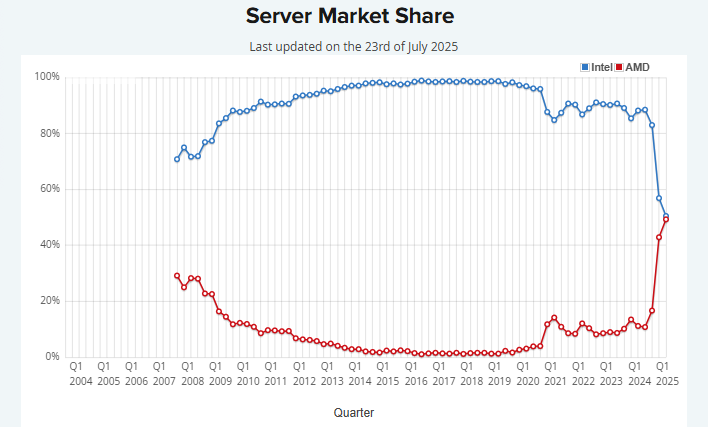
历史首次!AMD服务器CPU市占率达50%
如何将某个函数或变量放在固定的地址 ?
竞品数据对比接口技术解析

看点:AMD服务器CPU市场份额追上英特尔 华为Mate80主动散热专利曝光


如何将项目从IAR迁移到Embedded Studio
如何将RT-Thread移植到NXP MCUXPressoIDE上
如何将python文件导入到ROS系统中






 工商网监
工商网监
评论