 32Tops算力!BM1684行业主机系列
32Tops算力!BM1684行业主机系列

采用BM1684/BM1684X,INT8算力高达32TOPS;支持主流编程框架,工具链完备易用度高,算法迁移代价小;适用于视觉计算、边缘计算、通用算力服务、智慧交通、智慧课堂、无人超市、监控安防等多种AI计算场景

全新一代八核AI处理器
搭载高算力处理器BM1684/BM1684X,拥有八核ARM Cortex-A53,最高主频2.3GHz,采用12nm工艺制程;最高拥有高达32Tops(INT8)算力支持主流编程框架,可广泛应用于云端及边缘应用的人工智能推理
(BM1684X算力参数)
强大的多路视频AI处理能力
最高支持32路1080P H.264/H.265的视频解码,可同时处理分析超过16路高清视频,满足视频流人脸检测、车牌识别等各类AI应用场景的需求
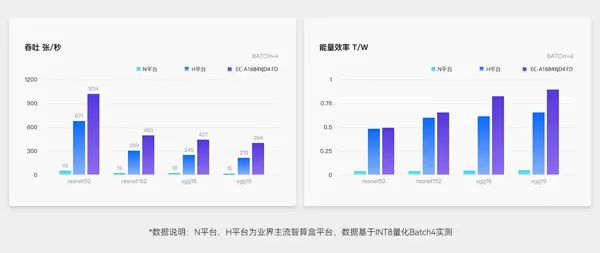
高吞吐量,高能效比
基于INT8量化Batch4实测数据,相对于业界主流智算模组平台,拥有更高的吞吐量和能效比,在性能上更具有优势
强大的网络扩展能力
支持双1000Mbps以太网、2.4GHz/5GHz 双频WiFi 、可扩展 5G/4G LTE网络,让网络通讯拥有更高的速率
一站式工具包,易用便捷
SOPHON SDK一站式深度学习开发工具包,支持主流框架 Caffe/TF/PyTorch/Mxnet/Paddle, 支持主流网络模型与自定义算子开发,支持Docker容器化,算法应用可快速进行部署
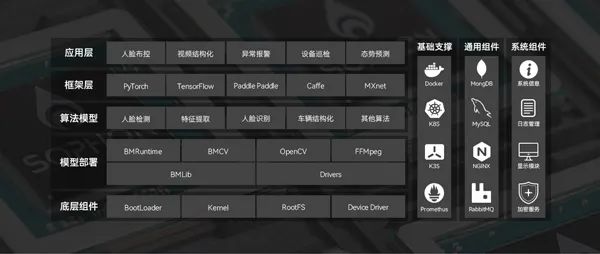
软硬件配套完善
配套完善的软硬件,可轻松实现云端及边缘应用的人工智能推理,加速人脸布控、视频结构化、异常报警、设备巡检、态势预测等边缘应用落地
丰富的扩展接口
拥有HDMI、M.2(SATA)、USB3.0、USB2.0、RS485、RS232等丰富接口,可直接应用到AI边缘计算产品中

无风扇设计,高效散热
配置工业级全金属外壳,铝合金结构导热,高效散热,无风扇设计,零噪音。运行稳定,满足各种工业级的应用需求
广泛的应用场景
高效适配市场上所有AI算法,可集成于边缘计算盒等产品中,为视觉计算、边缘计算、通用算力服务、人工智能、智慧工地、智慧交通、智慧课堂、无人超市、监控安防等行业进行AI赋能
-
处理器
+关注
关注
68文章
20408浏览量
255889 -
主机
+关注
关注
0文章
1082浏览量
36936
发布评论请先 登录
算能第三代人工智能推理芯片BM1684的核心优势
向成电子XC3588E+算力卡:3W低功耗,25 TOPS硬核算力,重塑AI视觉边缘生态

边缘AI算力临界点:深度解析176TOPS香橙派AI Station的产业价值
SAM(通用图像分割基础模型)丨基于BM1684X模型部署指南
算力高达 1570 TOPS!支持多硬盘的高算力服务器 CSB2-N10


MWC Doha 2025|美格智能全新发布60 Tops AI算力、支持Linux系统的SNM982高算力AI模组

AI算力模组TS-SG-SM7系列产品规格书
算力高达 275 TOPS!EC-AGXOrin 边缘计算主机

Qwen3-VL 4B/8B全面适配,BM1684X成边缘最佳部署平台!

腾视科技TS-SG-SM7系列AI算力模组:32TOPS算力引擎,开启边缘智能新纪元

腾视科技TS-NV-P100系列AI边缘算力盒子综合算力高达157TOPS:重新定义AI边缘算力,赋能千行百业智能化升级




评论