 简单粗暴而有效的改图:自动语音识别数据扩增的“一条野路”
简单粗暴而有效的改图:自动语音识别数据扩增的“一条野路”

神经网络的调参无疑是一个巨大的工程。
如何在调参之前拥有更佳的表现?千辛万苦调好了但却过拟合,如何拥有更好的泛化能力?这无疑是人肉调参的必经之痛。一个通用的认知是,训练数据会限制模型表现的上限,能拥有更好的训练数据,无疑成功了一大截儿。
近日,Daniel S. Park 等人在自动语音识别(Automatic Speech Recognition,ASR)模型训练上,找到了一种简单却强大的数据增强方法——SpecAugment。该操作另辟蹊径,将原始语音数据生成的梅尔倒谱图直接进行图像变换,扩增训练数据,化腐朽为神奇,结果很棒。
啥是自动语音识别
自动语音识别,即依托深度神经网络模型将语音自动识别为文本输入,无论是 Siri 助手还是微软小冰,抑或占据生活一部分的微信,都有它的身影,相信这个时代的你也早已习惯用语音转输入解放双手。
传统 ASR 模型的原始输入数据一般先经过预处理,将收集的音波转化为频谱图如梅尔倒频谱,也即梅尔频率倒谱系数(Mel Frequency Cepstrum Coefficient,MFCC,一定程度上模拟了人耳对声音的处理特点)的谱图。
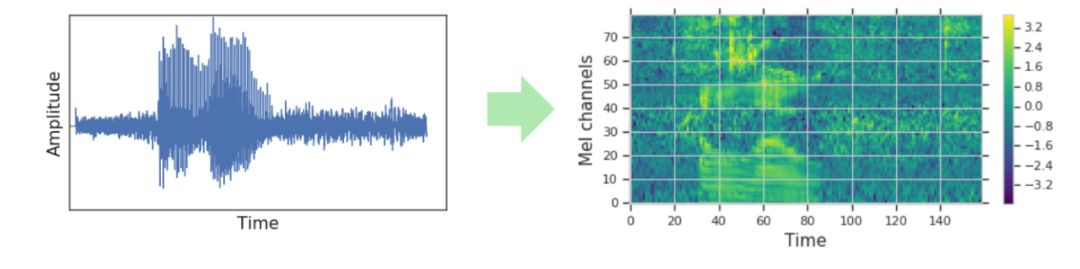
图 | 音波转化为梅尔倒频谱图结果示意图(来源:Daniel S. Park,et al./ Google Brain)
梅尔倒谱的一般流程是将声音信号进行傅立叶转换得到频谱,再进行取对数以及取逆傅立叶变换。
传统 ASR 模型扩增数据一般是将收集到的音波进行改变加速、减速、加背景噪音等变换来进行数据集的丰富,最后,这种扩增后的音频也要转化为频谱图。
然而,直接改变频谱图进行数据扩增,能否提升模型表现?毕竟,图像领域的扩增手段十分丰富,直接将频谱作为图像用一定手段进行变换结果如何?
Daniel S. Park 等人的 SpecAugment 方法证明,这是一个简单易行的好路子,可以实现在线训练,计算成本低廉无需额外数据,还能使 ASR 任务 LibriSpeech 960h(语音识别技术的最权威主流的开源数据集,包括近 1000 小时的英文发音和对应文字)和 Switchboard 300h(交换机电话语音语料库)比目前最佳模型的表现更好。
SpecAugment 的“出彩”之处
首先,在模型训练之前将输入数据——音频数据的梅尔倒谱,进行图像处理,这也是 SpecAugment 这条野路出彩的基础。即对梅尔倒频谱的横轴一段时间步长的频谱进行左或右扭转翘曲、或者掩蔽一段时长的谱图(时间屏蔽,对纵向进行掩蔽)、或是某些梅尔频率的信号(频率屏蔽,对横向进行掩蔽),得到了一系列的扩增样本。
这样的处理使得模型能够学习到时间轴上发生损失变形的音频、部分频率缺失的音频,以及丢失部分语音片段的音频的特点,增加了训练模型对这些信息的处理能力,也增强模型的泛化能力。

图 | 梅尔倒频谱的扩增变换手段:从上到下依次为没有应用增强、一定时间步长的扭曲,频率屏蔽和时间屏蔽。(来源:Daniel S. Park,et al/ Google Brain)
模型训练
输入数据处理完毕后,训练语音识别模型,这里采用 LAS(Listen Attend and Spell networks)模型。LAS 模型主要是由 Listener 和 Speller 两个子模型组成,其中 Listener 是一个声学编码器(Encoder,收集数据,相当于“听”),Speller 是一个基于注意力机制的解码器(Decoder,将收集的特征翻译成字符,相当于“说”)
训练 SpecAugment 的 Listener 子模型:输入的梅尔倒谱首先经两层卷积神经网络(CNN),经最大池化且步幅为 2,得到的结果输入到 BLSTM(双向长短期交替记忆模型)中,产生尺寸为 d x w 的基于注意力机制的特征。
训练 SpecAugment 的 Speller 子模型:将上一步骤中基于注意力机制产生的特征向量输入到一个二层 RNN(Recurrent Neural Network)模型中,训练集中的文本已用 WPM(Word Piece Model)进行了 token 处理,利用集束搜索(Beam Search),集束宽为 8,得到 token 表示的预测文本(token 处理即分词处理,之后进行词嵌入,自然语言处理利用词嵌入来将词向量化表示)。至此,实现语音转文本过程。
提升表现
比较训练集扩增前后训练出的 LAS 模型在测试集上的词错误率(Word Error Rate,WER),不改变任何超参数,测试结果错词率显著降低,可见无需调参,扩增训练集效果明显。
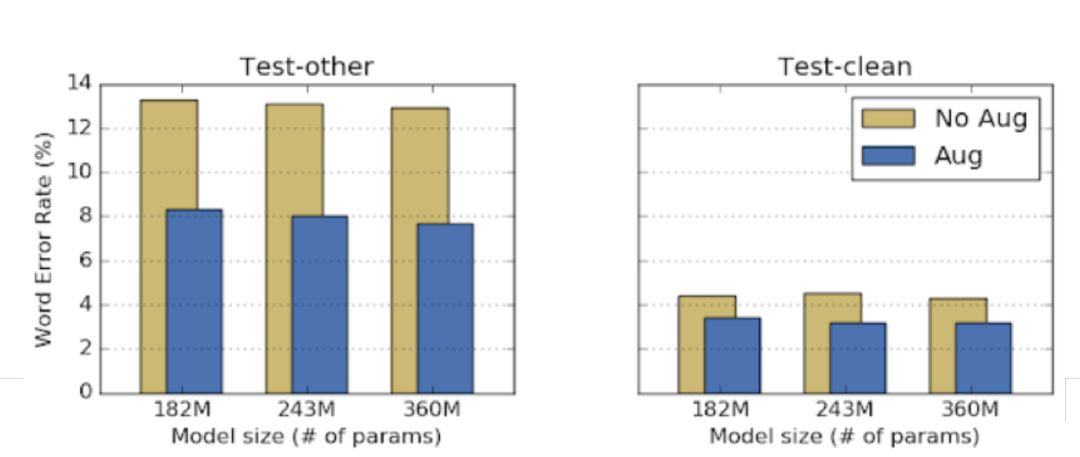
图 | 扩增训练集与否的两个模型在数据集 LibriSpeech 上有噪音测试集和无噪音测试集的表现。(来源:Daniel S. Park,et al/ Google Brain)
对于过拟合问题,虽然训练集上利用扩增的模型表现与无扩增相差并不是很多,但在开发集上,WER 有明显的降低,说明模型泛化能力提升,可以预测未训练过的数据,过拟合得到解决。
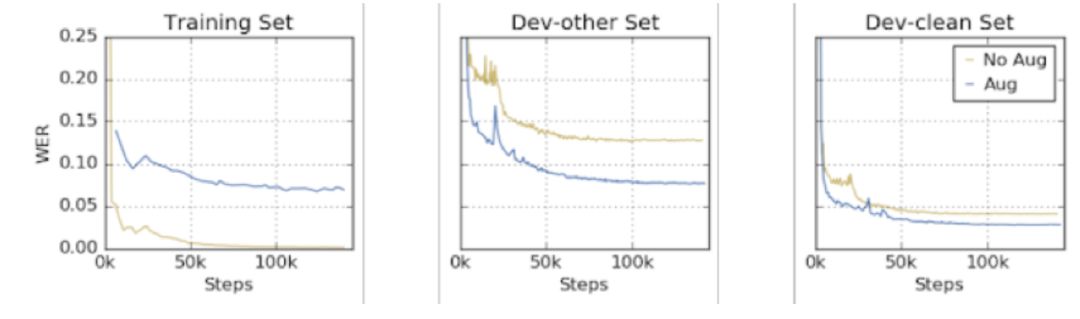
图 | 扩增训练集与否的两个模型在训练集、有噪音开发集和无噪音开发集集上的表现(来源:Daniel S. Park,et al/ Google Brain)
这个模型啥水平?
1)优于现有最佳 ASR 模型
扩增训练集后调整模型参数以及适当训练迭代,使得模型表现达到最佳,在数据集 LibriSpeech 960h 和 Switchboard 300h 有无噪音的测试集上,扩增模型表现与现有最佳模型的错词率结果对比发现,扩增方法明显取胜。无论是传统 ASR 模型(如 HMM)还是端到端的神经网络模型(如 CTC/ASG),采用 SpecAugment 方法训练后的 LAS 模型表现都明显更好。
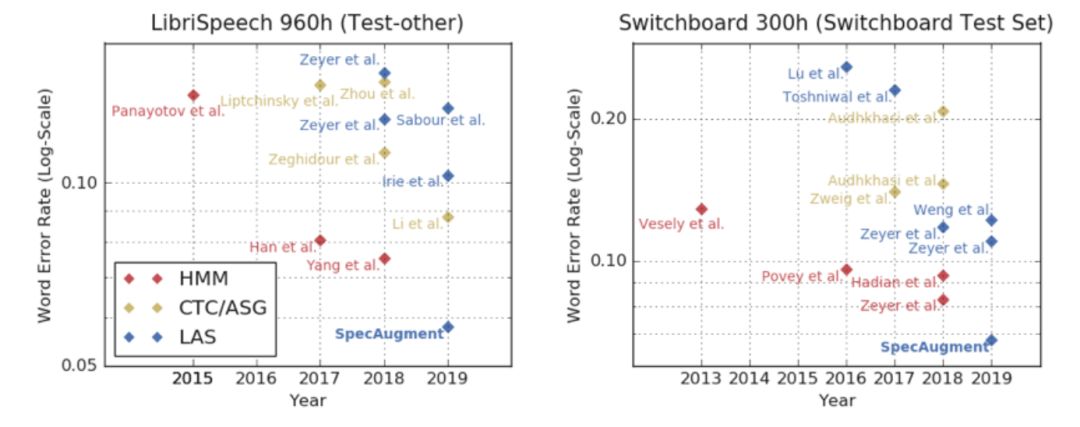
图 | LibriSpeech 960h 和 Switchboard 300h 数据集上不同模型的表现(来源:Daniel S. Park,et al/ Google Brain)
2)优于利用语言模型的 ASR 模型
引入利用大量纯文本语料库训练的语言模型(Language Models,LMs)能够使 ASR 模型效果大大提升,因为可以用语料库中的大量信息使模型功能更强,这也是 ASR 任务的一个通用做法。语言模型一般是独立训练的,使用 ASR 模型时需要占据一定内存进行存储,这使其难以在小型设备上应用。而 SpecAugment 模型的优势是,即使不利用语言模型也优于现有引入语言模型的 ASR 模型。这意味着语言模型的大内存问题,有了解决之路。
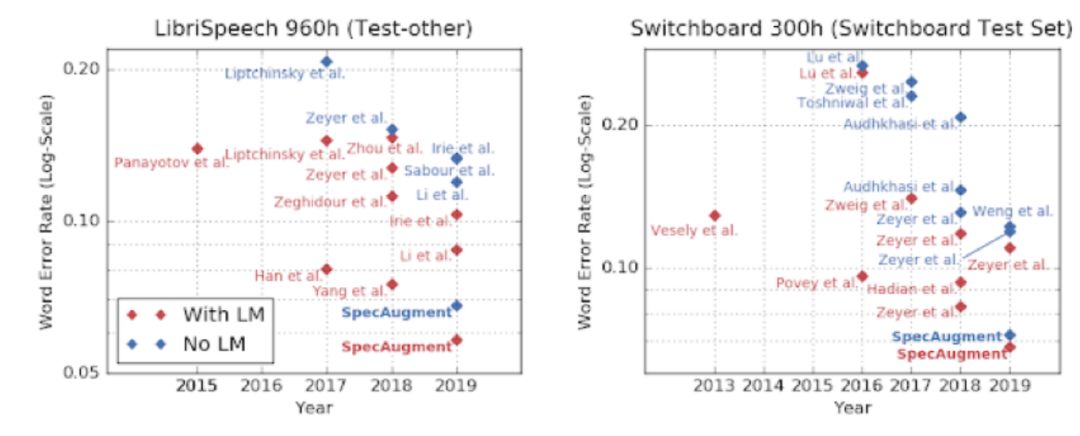
图 | LibriSpeech 960h 和 Switchboard 300h 数据集上不同 ASR 模型引入语言模型有否的表现(来源:Daniel S. Park,et al/ Google Brain)
总结,利用改变频谱图的方式扩增音频数据样本,训练出的 ASR 模型表现极佳,优于现有最好模型,甚至超过引入语言模型,很好用。
-
神经网络
+关注
关注
42文章
4827浏览量
106800 -
语音识别
+关注
关注
39文章
1803浏览量
115564 -
图像变换
+关注
关注
0文章
5浏览量
1613
原文标题:简单粗暴而有效的改图:自动语音识别数据扩增的“一条野路”
文章出处:【微信号:deeptechchina,微信公众号:deeptechchina】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
什么是离线语音识别芯片(离线语音识别芯片有哪些优点)
端到端语音交互数据 精准赋能语音大模型进阶

使用aicube进行目标检测识别数字项目的时候,在评估环节卡住了,怎么解决?
EASY EAl Orin Nano(RK3576) whisper语音识别训练部署教程

EASY EAl Orin Nano(RK3576) whisper语音识别训练部署教程
一条光纤怎么分两条
语音识别技术在通信领域中的应用实例
详解语音识别技术在通信领域中的应用


空调语音控制方案NRK3501语音识别芯片-让智能生活触手可及!






 工商网监
工商网监
评论