 如何表示一个词语的意思?神经网络词嵌入的基本思路
如何表示一个词语的意思?神经网络词嵌入的基本思路

主要内容
上一节讨论了自然语言处理,讨论了深度学习,非常宏观,也非常有趣。这一节和下一节的探讨则会直接跳到最基础的内容:词向量。同时,也会涉及到一些基本的数学推导。
如何表示一个词语的意思?计算机如何处理词语的意思离散化表示的问题从符号化表示到分布式表示基于相似度的分布式表示通过向量定义词语的含义word2vec神经网络词嵌入的基本思路word2vec主要思路Skip-gram预测word2vec细节一张图浓缩Skipgram训练模型:计算向量梯度梯度推导梯度下降随机梯度下降法关于公式排版Md2All 简介
如何表示一个词语的意思?
什么是“意思”?这是个简单的问题,想要解释清楚却并不容易。怎么办,向词典求助。韦氏词典说,“意思”是词语、短语所表达的思想;人们使用词语、符号所要表达的思想;作品、艺术所要表达的思想。这基本上与语言学家的思路是一致的。
在语言学家眼中,词语是一种语言符号。任何语言符号是由“能指”和“所指”构成的,“能指”指语言的声音形象,“所指”指语言所反映的事物的概念。比如英语的“tree”这个单词,它的发音就是它的“能指”,而“树”的概念就是“所指”。
中文中“意思”的意思更加有意思:
他说:“她这个人真有意思(funny)。”她说:“他这个人怪有意思的(funny)。”于是人们以为他们有了意思(wish),并让他向她意思意思(express)。他火了:“我根本没有那个意思(thought)!”她也生气了:“你们这么说是什么意思(intention)?”事后有人说:“真有意思(funny)。”也有人说:“真没意思(nonsense)”。(原文见《生活报》1994.11.13.第六版)[吴尉天,1999] ——《统计自然语言处理》
然而这些高大上的东西对于计算机实际处理词语的意思几乎没有任何帮助。
计算机如何处理词语的意思
过去几十年里主要使用的是分类词典。比如使用WordNet词库可以查询上义词和同义词。
panda 的上义词
fromnltk.corpusimportwordnetaswnpanda=wn.synset('panda.n.01')hyper=lambdas:s.hypernyms()list(panda.closure(hyper))[Synset('procyonid.n.01'),Synset('carnivore.n.01'),Synset('placental.n.01'),Synset('mammal.n.01'),Synset('vertebrate.n.01'),Synset('chordate.n.01'),Synset('animal.n.01'),Synset('organism.n.01'),Synset('living_thing.n.01'),Synset('whole.n.02'),Synset('object.n.01'),Synset('physical_entity.n.01'),Synset('entity.n.01')]
good 的同义词
S:(adj)full,goodS:(adj)estimable,good,honorable,respectableS:(adj)beneficial,goodS:(adj)good,just,uprightS:(adj)adept,expert,good,practiced,proficient,skillfulS:(adj)dear,good,nearS:(adj)good,right,ripe…S:(adv)well,goodS:(adv)thoroughly,soundly,goodS:(n)good,goodnessS:(n)commodity,tradegood,good
离散化表示的问题
有很大的参考价值,但无法体现细微差异,比如adept, expert, good, practiced, proficient, skillful虽然意思相近,但有很多细微差异
缺少新词,无法与时俱进
比较主观
需要手工创建和改编,甚至需要专家参与
难以精确计算词与词之间的相似度
无论是基于规则的语言处理,还是基于统计的语言处理,大都把词语当作单个符号进行处理。这种离散化、分类式的表示都普遍存在上述问题。
把这样的单个词语直接转换成向量后,就会出现一个1和大量的0:
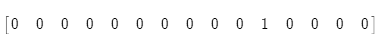 这就是所谓的one-hot 向量,也是一种localist的表示方式(只顾自己,不顾他人)这种编码方式会导致向量维度随着词表的增加而增加。2万 (speech) – 5万 (PTB) – 50万 (big vocab) – 1300万 (Google 1T),最后,这些词向量会变得非常非常长,使得计算机难以处理。
这就是所谓的one-hot 向量,也是一种localist的表示方式(只顾自己,不顾他人)这种编码方式会导致向量维度随着词表的增加而增加。2万 (speech) – 5万 (PTB) – 50万 (big vocab) – 1300万 (Google 1T),最后,这些词向量会变得非常非常长,使得计算机难以处理。
从符号化表示到分布式表示
符号化表示体现不出词语之间的内在联系,无法表示意思的相似度。任何两个独热向量都是正交的,无法通过任何运算得到相似度。

因此需要找到一种可以直接把相似度编码进向量的方法,也就是说可以直接从向量中读出词语之间的内在联系。
基于相似度的分布式表示
语言学家J. R. Firth提出,通过一个词语的上下文可以得到它的意思。“You shall know a word by the company it keeps.”一个词的意思是通过它的上下文表示的。
这个思想非常简单,却非常强大,是现代自然语言处理最成功的思想之一。
例如,如何知道banking的意思呢?方法就是找到成千上万含有banking的例句,看它周围都出现了哪些词语,然后通过处理这些词语来获得banking的含义:
government debt problems turning into banking crises as has happenedsaying that Europe needs unified banking regulation to replace the hodgepodge
banking的含义是由周围的这些词表示的。
通过向量定义词语的含义
我们先把一个词语定义成一个稠密向量,通过调整一个单词及其上下文单词的向量,使得根据两个向量可以推测两个词语的相似度;或通过一个词可以预测词语的上下文;或根据上下文可以预测这个词。这种手法也是递归的。

这个稠密的向量,就是词义的分布式表示。
word2vec
神经网络词嵌入的基本思路
借助词向量来定义一个预测中心词和语境词的概率模型(给定中心词,预测语境词的概率):
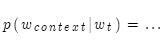
然后再定义损失函数:
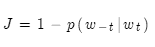
这里的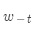 表示
表示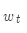 的语境词(负号表示除了某某之外)。损失函数的目的是判断预测的准确与否。如果根据中心词可以完美预测语境词,则损失函数为零。而一般情况下是做不到的这一点的。
的语境词(负号表示除了某某之外)。损失函数的目的是判断预测的准确与否。如果根据中心词可以完美预测语境词,则损失函数为零。而一般情况下是做不到的这一点的。
有了损失函数后,接下来就会在一个大型语料库的不同位置得到训练实例,调整词向量,最小化损失函数。
最后,令人惊叹的奇迹就会发生!产生的词向量非常强大,能充分地表示词语的含义。(后面会提到)
word2vec主要思路
在中心词和语境词之间相互预测!
两种算法:
Skip-grams(SG)给定目标词,预测语境词
连续词袋(CBOW)给定语境词袋,预测目标词
两个相对高效的训练方法:
层级 Softmax
负采样
Skip-gram预测
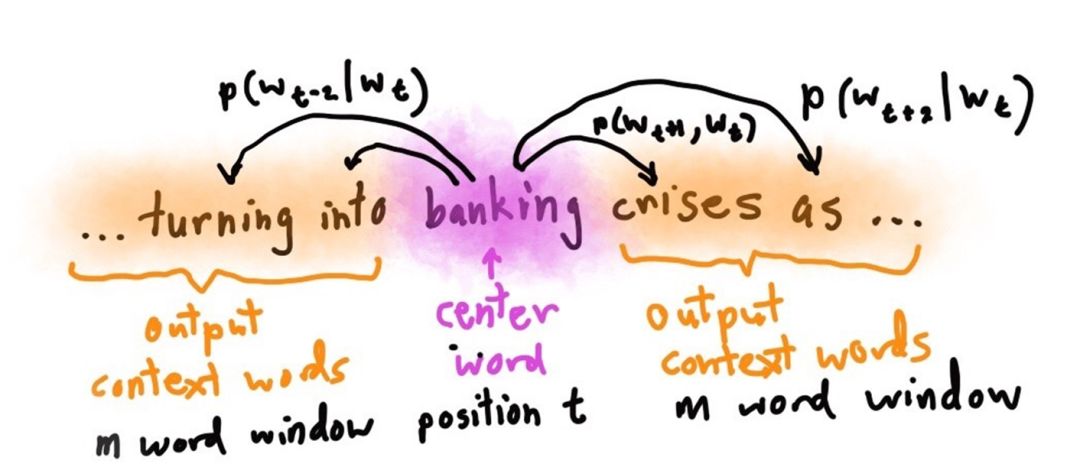
Skip-gram预测
Skip-gram的核心思想是定义一个给定中心词、预测语境词的概率分布模型。然后通过调整向量,使概率分布最大化。
注意:这里虽然有四条线,但模型中只有一个条件分布。学习就是要最大化这些概率。
word2vec细节
对于每一个中心词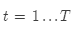 ,计算半径为
,计算半径为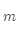 的窗口中的所有外围词的预测概率。。然后通过调整向量,使得预测概率最大。
的窗口中的所有外围词的预测概率。。然后通过调整向量,使得预测概率最大。
所以目标函数就是下面这个样子,我们要通过调整参数,使其最大化:
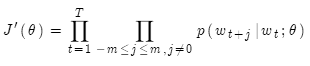
对其取负对数,得到负对数似然函数,这样就把连我乘转换为求和。我们要对其最小化。
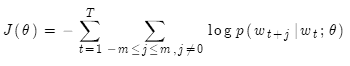
其中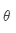 表示所有需要优化的变量。
表示所有需要优化的变量。
loss function = cost function = objective function 损失函数、代价函数、目标函数都是一样的。对于概率分布,一般使用交叉熵来计算损失。
那么概率是如何计算的?
对两个词向量 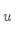
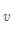 做点乘:
做点乘: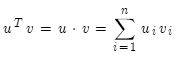
两个向量越相似,其点积越大!
重复以上,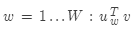 ,算出所有词与
,算出所有词与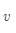 的点积,然后通过softmax获得
的点积,然后通过softmax获得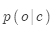 的概率分布。softmax是一种将实数值转换成概率(0-1)的标准方法。
的概率分布。softmax是一种将实数值转换成概率(0-1)的标准方法。
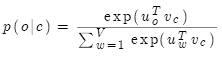
其中: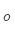 是外部词(输出词、语境词)索引,
是外部词(输出词、语境词)索引,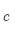 是中心词索引,
是中心词索引,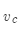 是索引为
是索引为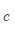 的中心词向量
的中心词向量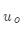 是索引为
是索引为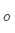 的外部词向量
的外部词向量
一张图浓缩Skipgram
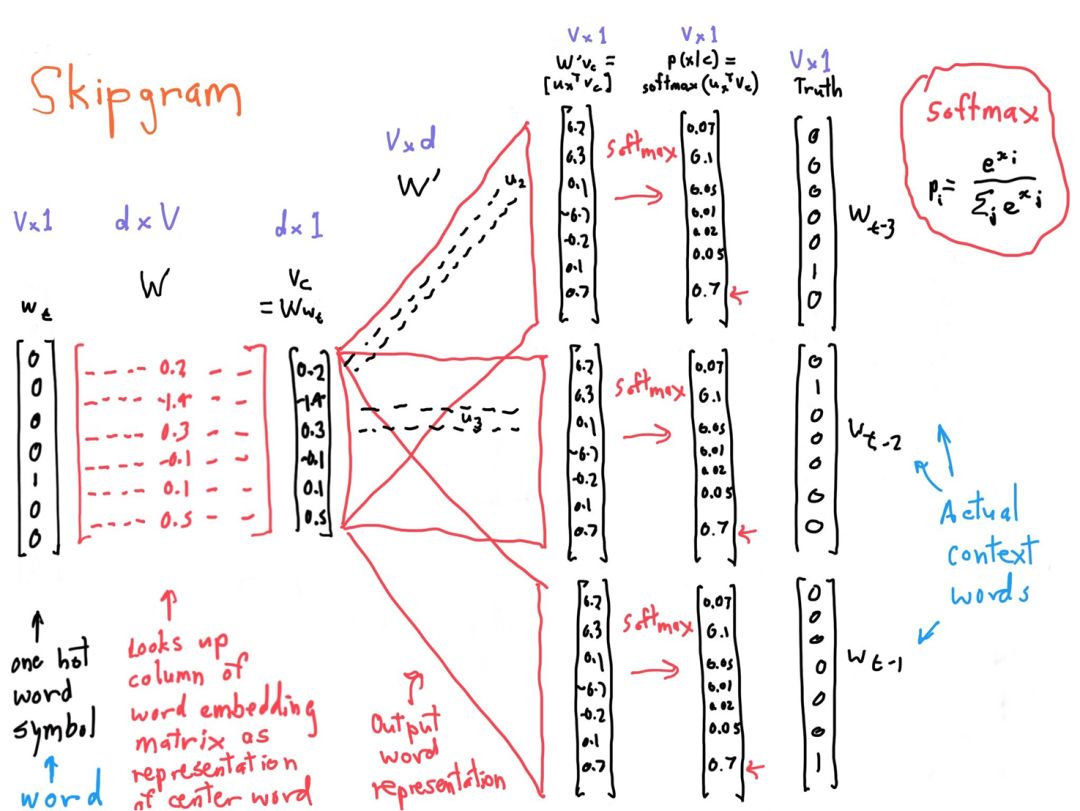
Skipgram浓缩图
从左到右是中心词独热向量,乘以中心词向量矩阵W,获得中心词语义向量,乘以另一个语境词矩阵W'得到每个词语的“相似度”,对相似度取softmax得到概率,与答案对比计算损失。
这两个矩阵都含有V个词向量,也就是说同一个词有两个词向量,哪个作为最终的、提供给其他应用使用的embeddings呢?有两种策略,要么加起来,要么拼接起来。
训练模型:计算向量梯度
通常把模型参数集定义为向量 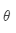 ,训练的过程就是优化这些参数,方法是梯度下降法。以之前的模型为例,有V个词,每个词有两个向量,每个向量为d维,共有2dV个参数。
,训练的过程就是优化这些参数,方法是梯度下降法。以之前的模型为例,有V个词,每个词有两个向量,每个向量为d维,共有2dV个参数。
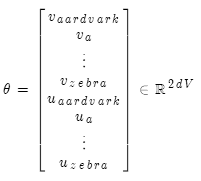
梯度推导
重要组件:
矩阵偏微分
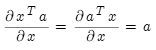
链式法则若y=f(u),u=g(x),即y=f(g(x)),则:
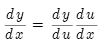
目标函数:
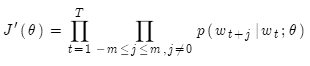
最大化它等同于最小化
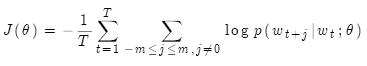
其中T是文本长度,m是窗口大小。
目标函数中的概率通过softmax计算:
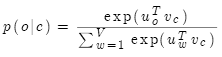
注意:每个词语分别有中心词和语境词两个向量表示。
我们先从一个中心词及其语境词开始。
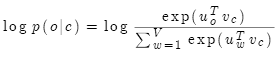
对中心词求梯度:
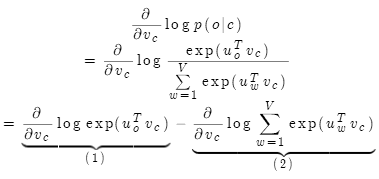
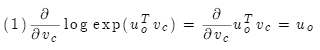

因此,

以上只是中心词向量参数梯度的推导,外部词向量参数梯度的推导过程类似。
梯度下降
有了梯度,参数减去梯度就能朝着最小值走了。这就是梯度下降法。
要在整个数据集上优化目标函数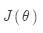 ,需要计算所有窗口的梯度。用矩阵的语言表述:
,需要计算所有窗口的梯度。用矩阵的语言表述:
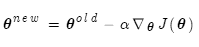
朴素梯度下降代码:
whileTrue:theta_grad=evaluate_gradient(J,corpus,theta)theta=theta-alpha*theta_grad
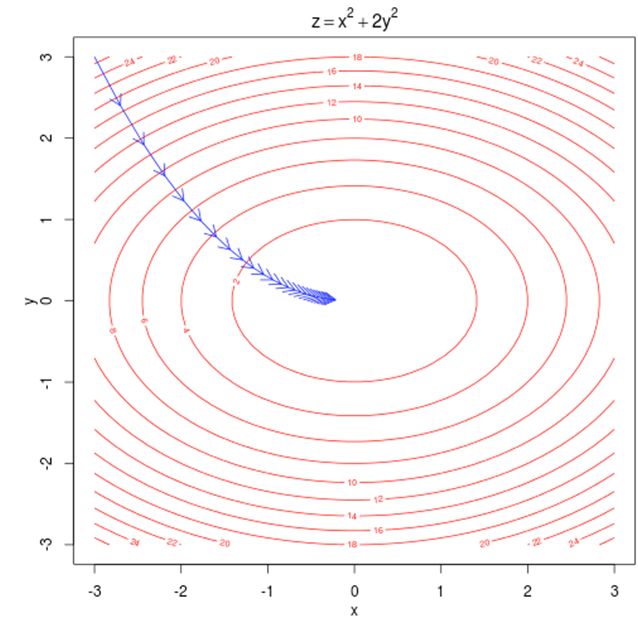
梯度下降示意图
等高线表示目标函数的数值。梯度与等高线垂直,指明了前进的方向。 是每次前进的步长。
梯度下降法是求函数最小值的最基本的方法。
随机梯度下降法
面对海量语料库和窗口数,计算所有参数的梯度,会让每次参数更新变得异常缓慢!这对所有神经网络来说,都不是个好主意。
相反,我们使用随机梯度下降法(SGD)。每次只对某个窗口更新参数。
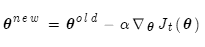
随机梯度下降代码:
whileTrue:theta_grad=evaluate_gradient(J,window,theta)theta=theta-alpha*theta_grad
虽然随机梯度下降充满噪音,但效果奇好,而且速度要快几个数量级。神经网络喜欢嘈杂的算法!
-
神经网络
+关注
关注
42文章
4844浏览量
108292 -
深度学习
+关注
关注
73文章
5613浏览量
124706 -
自然语言处理
+关注
关注
1文章
630浏览量
14749
原文标题:词语的向量化表示(CS224N-2)
文章出处:【微信号:gh_b11486d178ef,微信公众号:语言和智能】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
【案例分享】ART神经网络与SOM神经网络
如何构建神经网络?
可分离卷积神经网络在 Cortex-M 处理器上实现关键词识别
嵌入式中的人工神经网络的相关资料分享
轻量化神经网络的相关资料下载
卷积神经网络一维卷积的处理过程
搭建一个神经网络的基本思路和步骤
神经网络中词向量是怎么表示的?
用Python从头实现一个神经网络来理解神经网络的原理1

用Python从头实现一个神经网络来理解神经网络的原理2

用Python从头实现一个神经网络来理解神经网络的原理3

用Python从头实现一个神经网络来理解神经网络的原理4




评论