 Python爬虫库中Beautiful Soup库的使用资料说明
Python爬虫库中Beautiful Soup库的使用资料说明
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
XML
+关注
关注
0文章
183浏览量
32936 -
HTML
+关注
关注
0文章
273浏览量
29270 -
python
+关注
关注
51文章
4675浏览量
83466
原文标题:Python爬虫库-BeautifulSoup的使用
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐


Python数据爬虫学习内容
流程来实现的。这个过程其实就是模拟了一个人工浏览网页的过程。Python中爬虫相关的包很多:urllib、requests、bs4、scrapy、pyspider 等,我们可以按照requests
发表于 05-09 17:25
Python爬虫与Web开发库盘点
Python爬虫和Web开发均是与网页相关的知识技能,无论是自己搭建的网站还是爬虫爬去别人的网站,都离不开相应的Python库,以下是常用的
发表于 05-10 15:21
Python爬虫初学者需要准备什么?
了一个人工浏览网页的过程。Python中爬虫相关的包很多:urllib、requests、bs4、scrapy、pyspider 等,我们可以按照requests 负责连接网站,返回网页,Xpath 用于
发表于 06-20 17:14
【NanoPi K1 Plus试用体验】python爬虫
://www.weather.com.cn/weather1d/101010100.shtml调试过程中遇到了很多问题,参考了很多大神的教程网站打开后F12就可以看到网页源码信息需要什么信息基本都是soup.find搞定
发表于 08-03 11:28
Python 爬虫:8 个常用的爬虫技巧总结!
用python也差不多一年多了,python应用最多的场景还是web快速开发、爬虫自动化运维:写过简单网站、写过自动发帖脚本、写过收发邮件脚本、写过简单验证码识别脚本。爬虫在开发过程
发表于 01-02 14:37
【建议收藏】Python库大全
` 通用urlib -网络库(stdlib)。requests -网络库。grab -网络库(基于pycurl)。pycurl -网络库(绑定libcurl)ullib3 -
发表于 09-06 15:58
0基础入门Python爬虫实战课
学习资料良莠不齐爬虫是一门实践性的技能,没有实战的课程都是骗人的!所以这节Python爬虫实战课,将帮到你!课程从0基础入门开始,受众人群广泛:如毕业大学生、转行人群、对
发表于 07-25 09:28
python网络爬虫概述
的数据,从而识别出某用户是否为水军学习爬虫前的技术准备(1). Python基础语言: 基础语法、运算符、数据类型、流程控制、函数、对象 模块、文件操作、多线程、网络编程 … 等(2). W3C标准
发表于 03-21 16:51
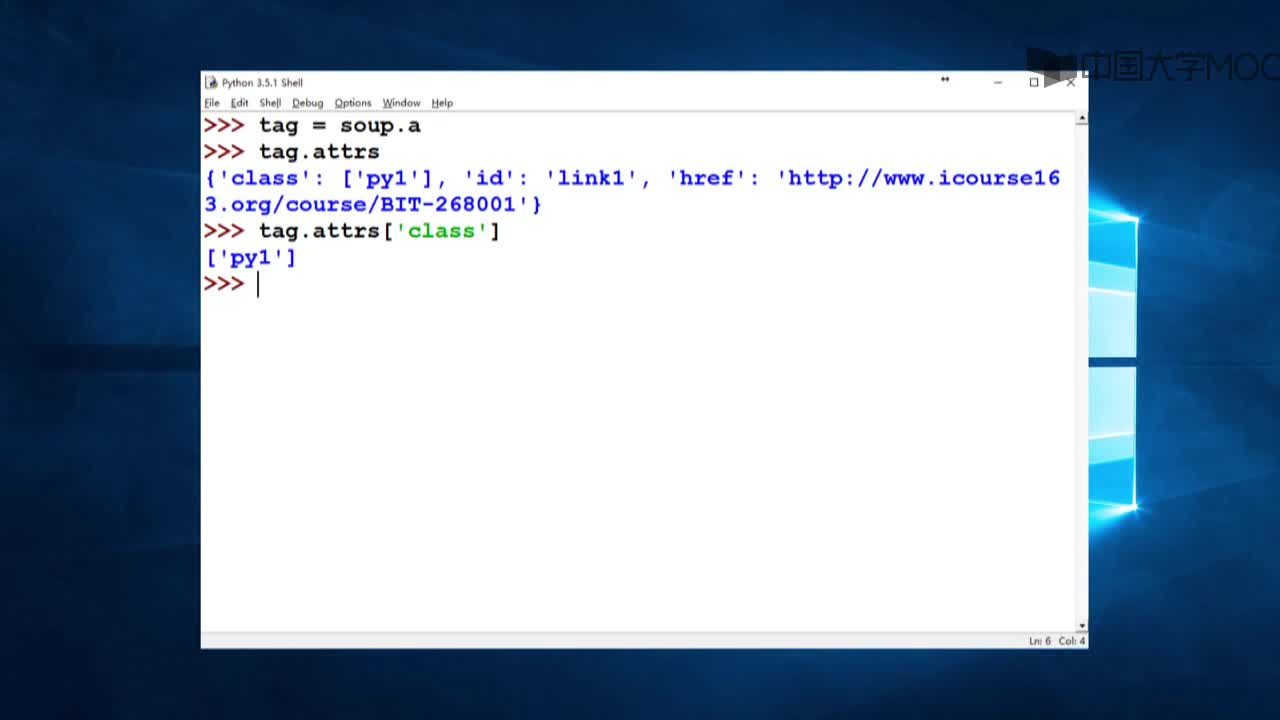
如何从HTML或XML文件中提取数据的Python爬虫库Beautiful Soup概述
Beautiful Soup是一个可以从HTML或XML文件中提取数据的Python库,简单来说,它能将HTML的标签文件解析成树形结构,然后方便地获取到指定标签的对应属性。

Python爬虫之Beautiful Soup模块
模块安装 {代码...} 模块导入 {代码...} 示例html内容获取html内容代码 {代码...} 获取的html内容 {代码...} 构建BeautifulSoup对象常用...





 工商网监
工商网监
评论