 当前生成图像最逼真的BigGAN被谷歌超越!造假效果更为逼真
当前生成图像最逼真的BigGAN被谷歌超越!造假效果更为逼真

当前生成图像最逼真的BigGAN被超越了!
出手的,是谷歌大脑和苏黎世联邦理工学院。他们提出了新一代GAN:S³GAN。
它们生成的照片,都是真假难辨。
下面这两只蝴蝶,哪只更生动?
两张风景照片,哪张更真实?
难以抉择也正常,反正都是假的。上面的照骗,都是左边出自S³GAN,右边的出自BigGAN之手。
它们还有更多作品:
至于哪些是S³GAN,答案文末揭晓。
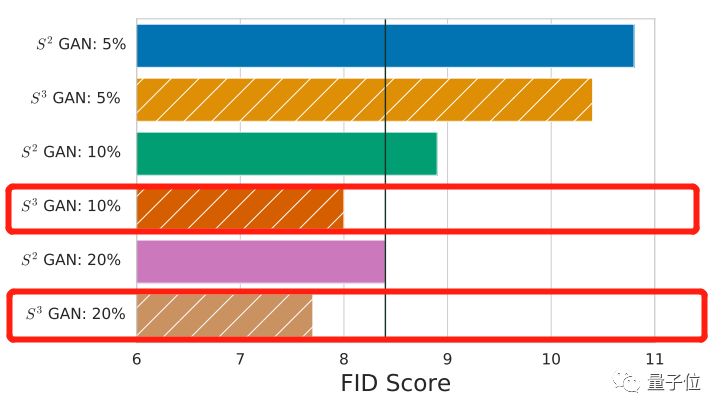
肉眼难分高下,就用数据说话。跑个FID(Frechet Inception Distance)得分,分值越低,就表示这些照骗,越接近人类认识里的真实照片——
S³GAN是8.0分,而BigGAN是8.4分。新选手略微胜出。
你可还记得BigGAN问世之初,直接将图像生成的逼真度提高了一个Level,引来Twitter上花样赞赏?
如今它不止被超越,而且是被轻松超越。
“轻松”在哪呢?
S³GAN达到这么好的效果,只用了10%的人工标注数据。而老前辈BigGAN,训练所用的数据100%是人工标注过的。
如果用上20%的标注数据,S³GAN的效果又会更上一层楼。
标注数据的缺乏,已经是帮GAN提高生成能力,拓展使用场景的一大瓶颈。如今,这个瓶颈已经几乎被打破。
现在的S³GAN,只经过了ImageNet的实验,是实现用更少标注数据训练生成高保真图像的第一步。
接下来,作者们想要把这种技术应用到“更大”和“更多样化”的数据集中。
不用标注那么多
为什么训练GAN生成图像,需要大量数据标注呢?
GAN有生成器、判别器两大组件。
其中判别器要不停地识破假图像,激励生成器拿出更逼真的图像。
而图像的标注,就是给判别器做判断依据的。比如,这是真的猫,这是真的狗,这是真的汉堡……这是假图。
可是,没有那么多标注数据怎么办?
谷歌和ETH苏黎世的研究人员,决定训练AI自己标注图像,给判别器食用。
自监督 vs 半监督
要让判别器自己标注图像,有两种方法。
一是自监督方法,就是给判别器加一个特征提取器 (Feature Extractor) ,从没有标注的真实训练数据里面,学到它们的表征 (Feature Representation) 。
对这个表征做聚类 (Clustering) ,然后把聚类的分配结果,当成标注来用。
这里的训练,用的是自监督损失函数。
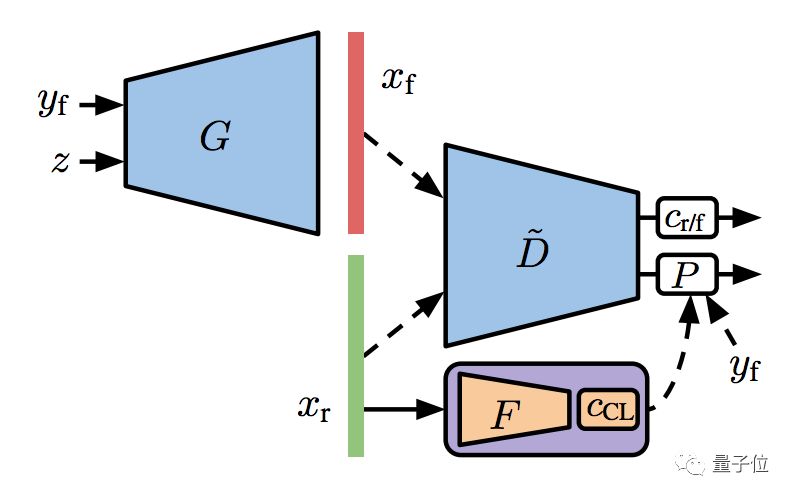
二是半监督方法,也要做特征提取器,但比上一种方法复杂一点点。
在训练集的一个子集已经标注过的情况下,根据这些已知信息来学习表征,同时训练一个线性分类器 (Linear Classifier) 。
这样,损失函数会在自监督的基础上,再加一项半监督的交叉熵损失 (Cross-Entropy Loss) 。
预训练了特征提取器,就可以拿去训练GAN了。这个用一小部分已知标注养成的GAN,叫做S²GAN。
不过,预训练也不是唯一的方法。
想要双管齐下,可以用协同训练 (Co-Training) :
直接在判别器的表征上面,训练一个半监督的线性分类器,用来预测没有标注的图像。这个过程,和GAN的训练一同进行。
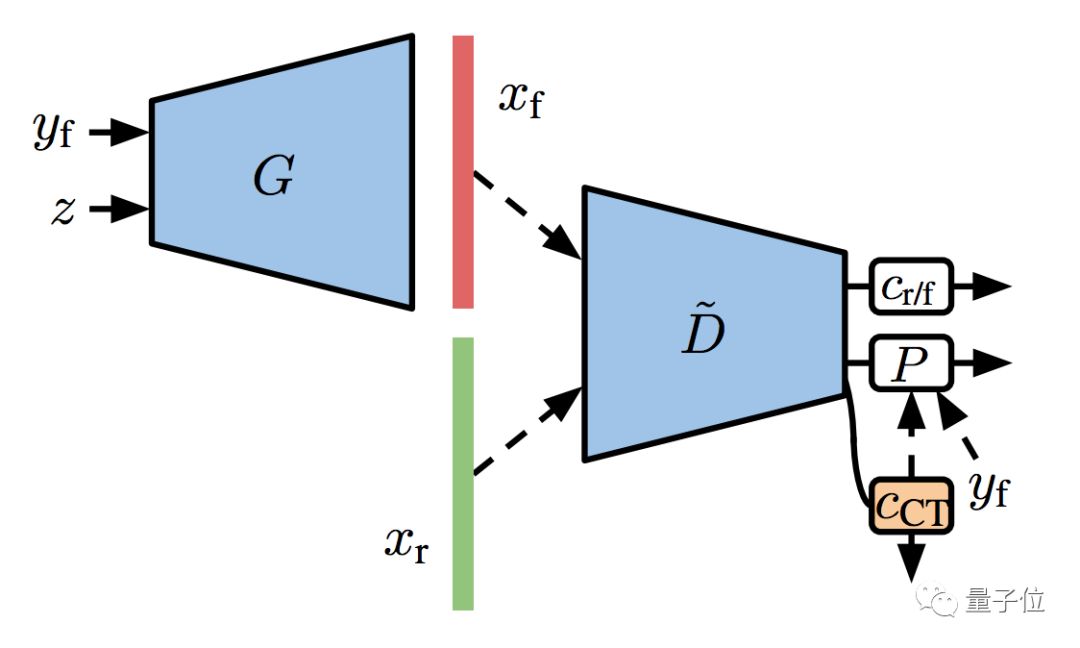
这样就有了S²GAN的协同版,叫S²GAN-CO。
升级一波
然后,团队还想让S²GAN变得更强大,就在GAN训练的稳定性上面花了心思。
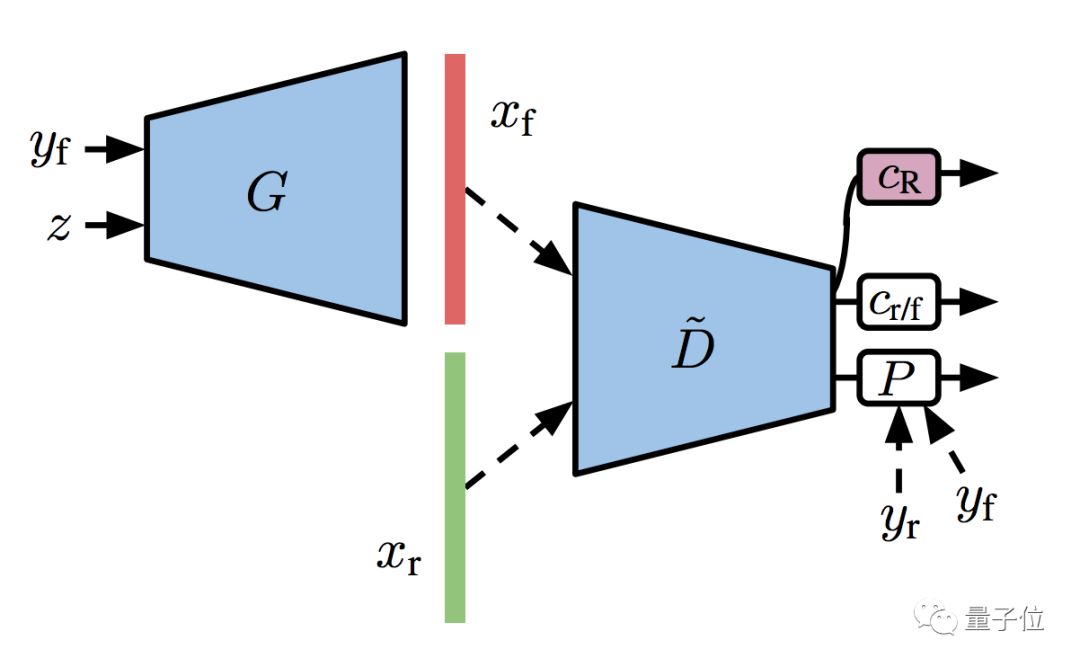
研究人员说,判别器自己就是一个分类器嘛,如果把这个分类器扩增 (Augmentation) 一下,可能疗效上佳。
于是,他们给了分类器一个额外的自监督任务,就是为旋转扩增过的训练集 (包括真图和假图) ,做个预测。
再把这个步骤,和前面的半监督模型结合起来,GAN的训练变得更加稳定,就有了升级版S³GAN:
架构脱胎于BigGAN
不管是S²GAN还是S³GAN,都借用了前辈BigGAN的网络架构,用的优化超参数也和前辈一样。
不同的是,这个研究中,没有使用正交正则化 (Orthogonal Regularization) ,也没有使用截断 (Truncation) 技巧。

△BigGAN的生成器和鉴别器架构图
训练的数据集,来自ImageNet,其中有130万训练图像和5万测试图像,图像中共有1000个类别。
图像尺寸被调整成了128×128×3,在每个类别中随机选择k%的样本,来获取半监督方法中的使用的部分标注数据集。
最后,在128核的Google TPU v3 Pod进行训练。
超越BigGAN
研究对比的基线,是DeepMind的BigGAN,当前记录的保持者,FID得分为7.4。
不过,他们在ImageNet上自己实现的BigGAN,FID为8.4,IS为75,并以此作为了标准。
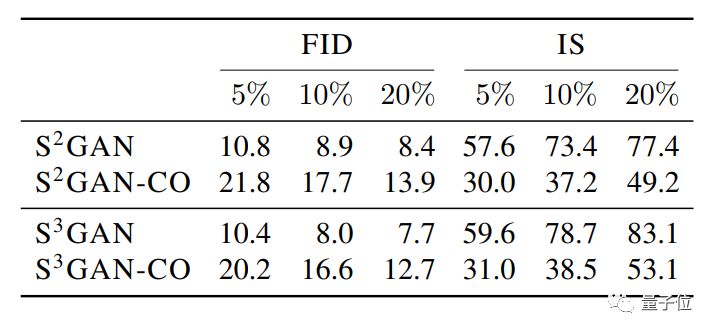
在这个图表中,S²GAN是半监督的预训练方法。S²GAN-CO是半监督的协同训练方法。
S³GAN,是S²GAN加上一个自监督的线性分类器 (把数据集旋转扩增之后再拿给它分类) 。
其中,效果最好的是S³GAN,只使用10%由人工标注的数据,FID得分达到8.0,IS得分为78.7,表现均优于BigGAN。
如果你对这项研究感兴趣,请收好传送门:
论文:

High-Fidelity Image Generation With Fewer Labels
https://arxiv.org/abs/1903.02271
文章开头的这些照骗展示,就出自论文之中:
第一行是BigGAN作品,第二行是S³GAN新品,你猜对了吗?
另外,他们还在GitHub上开源了论文中实验所用全部代码:
https://github.com/google/compare_gan
-
谷歌
+关注
关注
27文章
6259浏览量
111979 -
图像
+关注
关注
2文章
1096浏览量
42438
原文标题:史上最强GAN被谷歌超越!标注数据少用90%,造假效果却更逼真
文章出处:【微信号:WW_CGQJS,微信公众号:传感器技术】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
全面掌握ComfyUI系统教程|94节从入门到进阶实战清单
融合多场耦合效应:生成式人工智能技术演进及其在航空发动机复杂工程系统中的赋能机制研究


量子、雷达、生物医学…复杂信号如何精准生成?答案在这台“信号引擎”
借助NVIDIA Isaac Sim与World Labs Marble加速机器人仿真环境构建
使用Firebase AI Logic生成图像模型的两种新功能
看点:谷歌Veo 3.1迎来重大更新硬刚Sora 2 12英寸硅片国产龙头西安奕材今日申购
使用OpenUSD和SimReady资产构建AI工厂
HarmonyOSAI编程编辑区代码生成
AI开启更逼真的游戏时代

NVIDIA RTX PRO 4500 Blackwell产品特性
利用NVIDIA 3D引导生成式AI Blueprint控制图像生成
生成式人工智能认证:重构AI时代的人才培养与职业跃迁路径
Gemini API集成Google图像生成模型Imagen 3
技术分享 | 高逼真合成数据助力智驾“看得更准、学得更快”




评论