 如何理解各层学到了怎样的信息?通过可视化工具进行探究
如何理解各层学到了怎样的信息?通过可视化工具进行探究

深度神经网络的超强有效性一直让人疑惑。
经典论文《可视化与理解CNN》(Visualizing and Understanding Convolutional Networks)解释了在图像领域中CNN从低层到高层不断学习出图像的边缘、转角、组合、局部、整体信息的过程,一定层面论证了深度学习的有效性。另一方面,传统的NLP神经网络却并不是那么深,而bert的出现直接将NLP的神经网络加到12层以上。
那么如何理解各层学到了怎样的信息?
本文作者Jesse Vig通过可视化工具对此进行了非常有意义的探究。文章分两部分,第一部分介绍bert中的6种模式,第二部分介绍其底层细节。
可视化BERT之一
在BERT错综复杂的注意力网络中,出现了一些直观的模式。
2018年是自然语言处理领域的转折之年,一系列深度学习模型在智能问答、情感分类等多种NLP任务上取得了最佳结果。特别是最近谷歌的BERT,成为了一种“以一当十的模型”,在各种任务上都取得了的极佳的表现。
BERT主要建立在两个核心思想上,这两个思想都包含了NLP最新进展:(1)Transformer的架构(2)无监督学习预训练。
Transformer 是一种序列模型,它舍弃了 RNN 的顺序结构,转而采用了一种完全基于注意力的方法。这在经典论文 《Attention Is All You Need》中有具体介绍。
BERT同时也要经过预训练。它的权重预先通过两个无监督任务学习到。这两个任务是:遮蔽语言模型(masked language model,MLM)和下句一句预测(next sentence prediction)。
因此,对于每个新任务,BERT不需要从头开始训练。相反,只要在预训练的权重上进行微调(fine-tuning)就行。有关BERT的更多详细信息,可以参考文章《图解BERT》。
BERT是一只多头怪
Bert不像传统的注意力模型那样只使用一个平坦的注意力机制。相反,BERT使用了多层次的注意力(12或24层,具体取决于模型),并在每一层中包含多个(12或16)注意力“头”。由于模型权重不在层之间共享,因此一个BERT模型就能有效地包含多达24 x 16 = 384个不同的注意力机制。
可视化BERT
由于BERT的复杂性,所以很难直观地了解其内部权重的含义。而且一般来说,深度学习模型也是饱受诟病的黑箱结构。所以大家开发了各种可视化工具来辅助理解。
可我却没有找到一个工具能够解释BERT的注意力模式,来告诉我们它到底在学什么。幸运的是,Tensor2Tensor有一个很好的工具,可用于可视化Transformer模型中的注意力模式。因此我修改了一下,直接用在BERT的一个pytorch版本上。修改后的界面如下所示。你可以直接在这个Colab notebook (https://colab.research.google.com/drive/1vlOJ1lhdujVjfH857hvYKIdKPTD9Kid8)里运行,或在Github上找到源码。(https://github.com/jessevig/bertviz)。
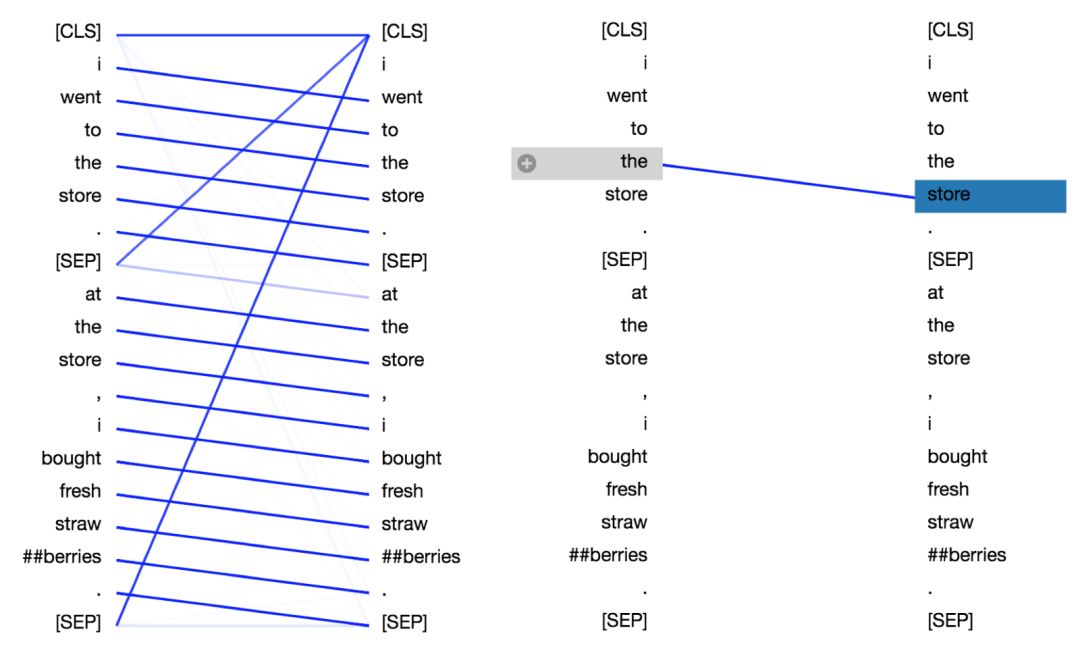
这个工具将注意力看做不同的连线,它们用来连接被更新的位置(左半边)与被注意的位置(右半边)。(译注:可以想象为神经网络是从右向左正向传播的。)不同的颜色分别代表相应的注意头,而线条颜色的深浅代表被注意的强度。在这个小工具的顶部,用户可以选择观察模型的第几层,以及第几个注意力头(通过单击顶部的色块即可,它们分别代表着12个头)。
BERT 到底学了什么?
我使用该工具探索了预训练 BERT 模型各个层和各个头的注意力模式(用全小写(uncased)版本的BERT-Base 模型)。虽然我尝试了不同的输入句子,但为了方便演示,这里只采用以下例句:
句子A:I went to the store.
句子B:At the store, I bought fresh strawberries.
BERT 用 WordPiece工具来进行分词,并插入特殊的分离符([CLS],用来分隔样本)和分隔符([SEP],用来分隔样本内的不同句子)。
因此实际输入序列为:[CLS] i went to the store . [SEP] at the store , i bought fresh straw ##berries . [SEP]
在探索中,我发现了一些特别显著的令人惊讶的注意力模式。下面是我确认的六种关键模式,将产生每一种模式的特定层和头都进行可视化展示。
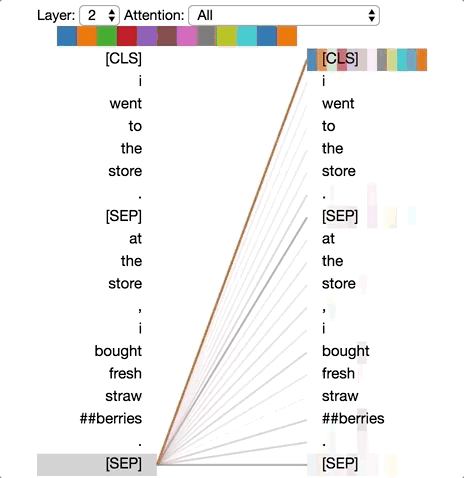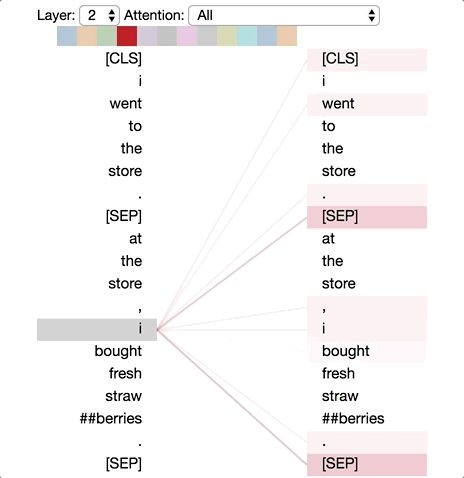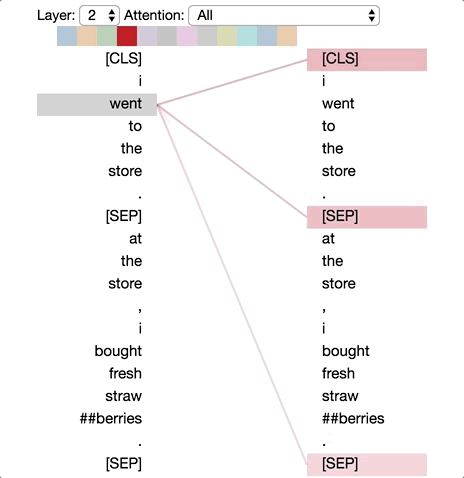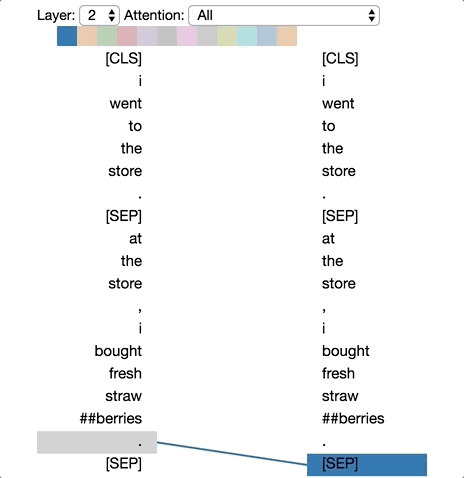
模式1:注意下一个词
在这种模式中,每个位置主要注意序列中的下一个词(token)。下面将看到第2层0号头的一个例子。(所选头部由顶部颜色条中突出的显示色块表示。)
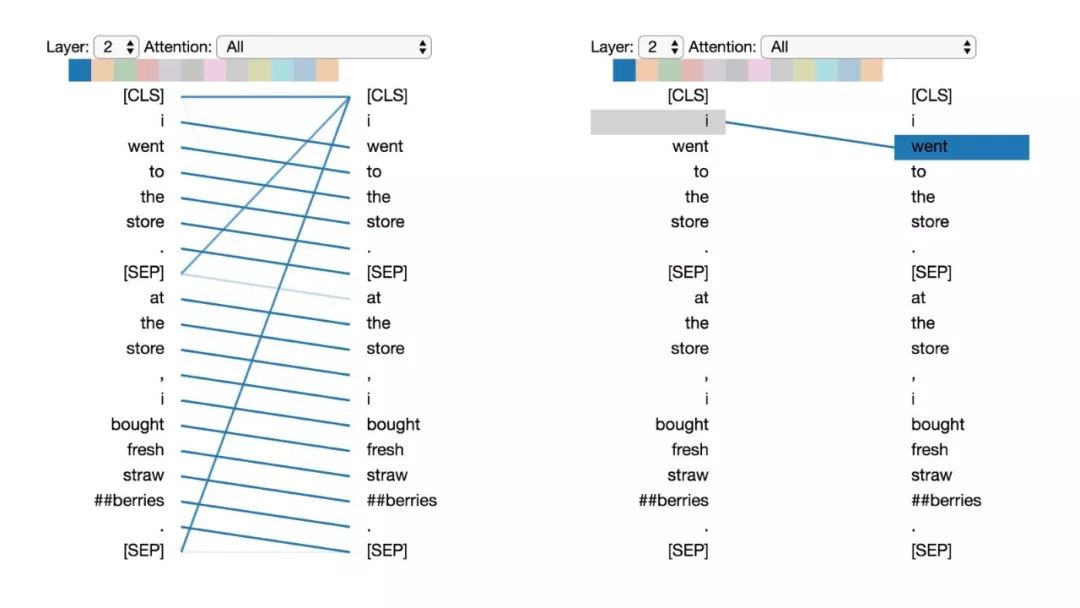
模式1:注意下一个词。
左:所有词的注意力。右:所选词的注意力权重(“i”)
左边显示了所有词的注意力,而右侧图显示一个特定词(“i”)的注意力。在这个例子中,“i”几乎所有的注意力都集中在“went”上,即序列中的下一个词。
在左侧,可以看到[SEP]符号不符合这种注意力模式,因为[SEP]的大多数注意力被引导到了[CLS]上,而不是下一个词。因此,这种模式似乎主要在每个句子内部出现。
该模式与后向RNN有关,其状态的更新是从右向左依次进行。模式1出现在模型的多个层中,在某种意义上模拟了RNN的循环更新。
模式2:注意前一个词
在这种模式中,大部分注意力都集中在句子的前一个词上。例如,下图中“went”的大部分注意力都指向前一个词“i”。
这个模式不像上一个那样显著。有一些注意力也分散到其他词上了,特别是[SEP]符号。与模式1一样,这与RNN有些类似,只是这种情况下更像前向RNN。
模式2:注意前一个词。
左:所有词的注意力。右:所选词的注意力权重(“went”)
模式3:注意相同或相关的单词
这种模式注意相同或相关的单词,包括其本身。在下面的例子中,第一次出现的“store”的大部分注意力都是针对自身和第二次出现的“store”。这种模式并不像其他一些模式那样显著,注意力会分散在许多不同的词上。
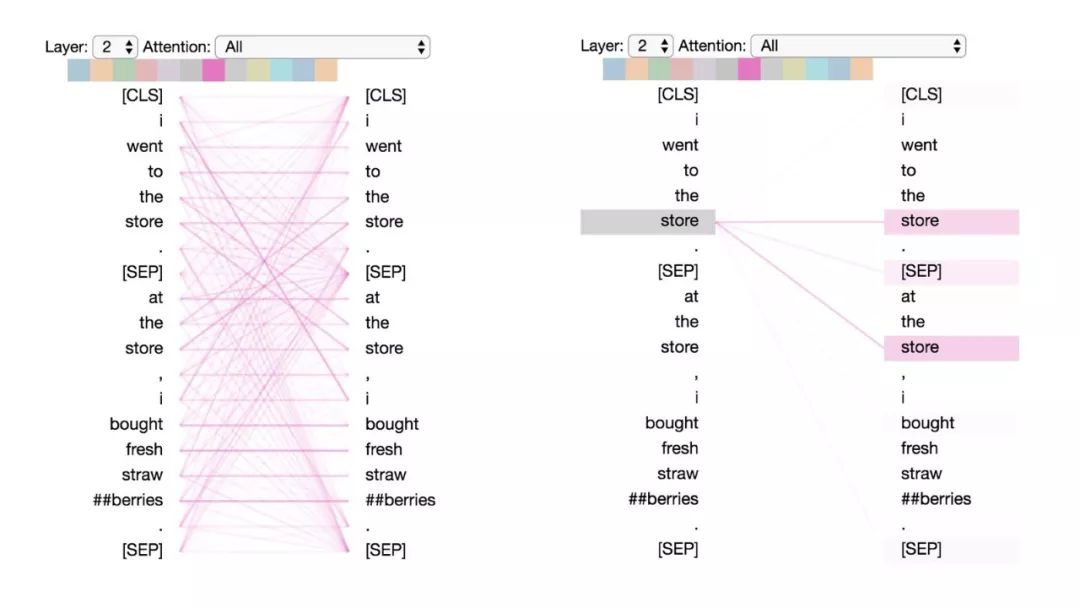
模式3:注意相同/相关的词。
左:所有词的注意力。右:所选词的注意权重(“store”)
模式4:注意“其他”句子中相同或相关词
这种模式注意另一个句子中相同或相关的单词。例如,第二句中“store”的大部分注意力都指向第一句中的“store”。可以想象这对于下句预测任务(BERT预训练任务的一部分)特别有用,因为它有助于识别句子之间的关系。
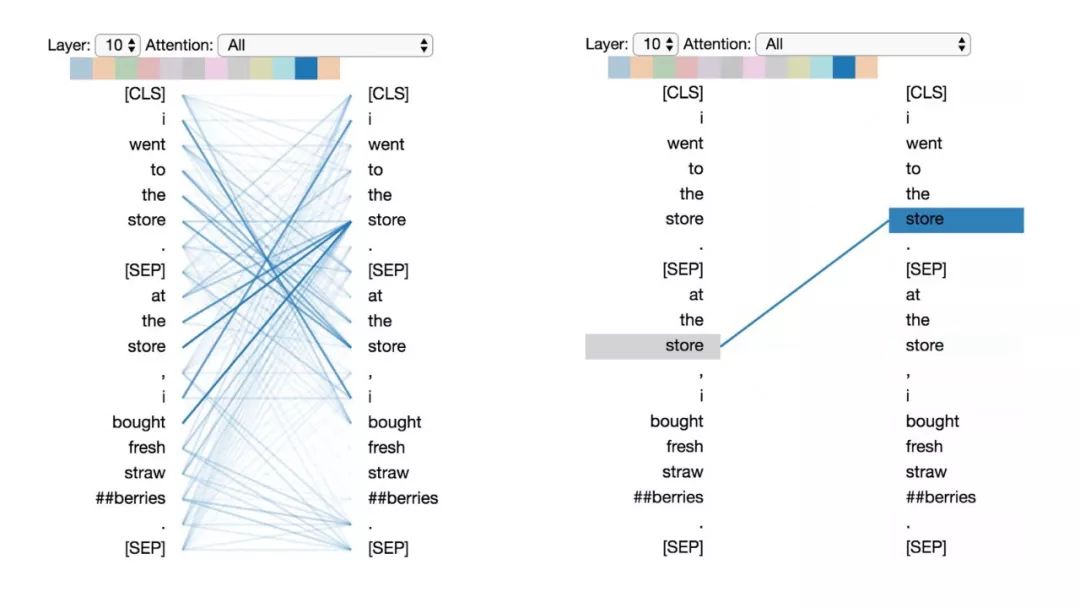
模式4:注意其他句子中相同/相关的单词。
左:所有词的注意力。右:所选词的注意权重(“store”)
模式5:注意能预测该词的其他单词
这种模式似乎是更注意能预测该词的词,而不包括该词本身。在下面的例子中,“straw”的大部分注意力都集中在“##berries”上(strawberries草莓,因为WordPiece分开了),而“##berries”的大部分注意力也都集中在“straw”上。
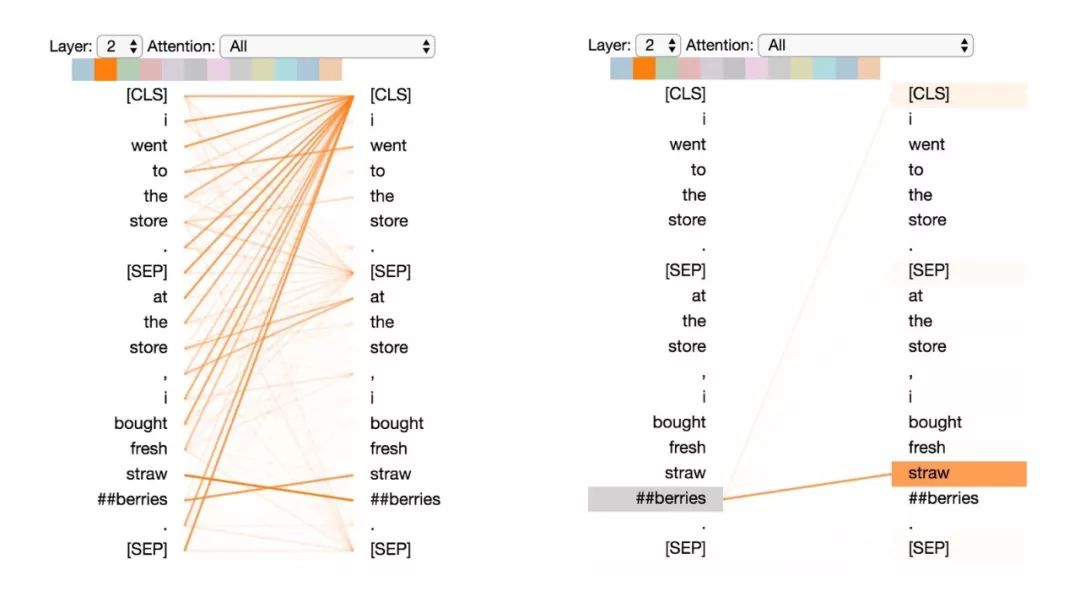
模式5:注意能预测该单词的其他单词。
左:所有词的注意力。右:所选词的注意力(“## berries”)
这个模式并不像其他模式那样显著。例如,词语的大部分注意力都集中在定界符([CLS])上,而这是下面讨论的模式6的特征。
模式6:注意分隔符
在这种模式中,词语的大部分注意力都集中在分隔符[CLS]或[SEP]上。在下面的示例中,大部分注意力都集中在两个[SEP]符号上。这可能是模型将句子级状态传播到单个词语上的一种方式。
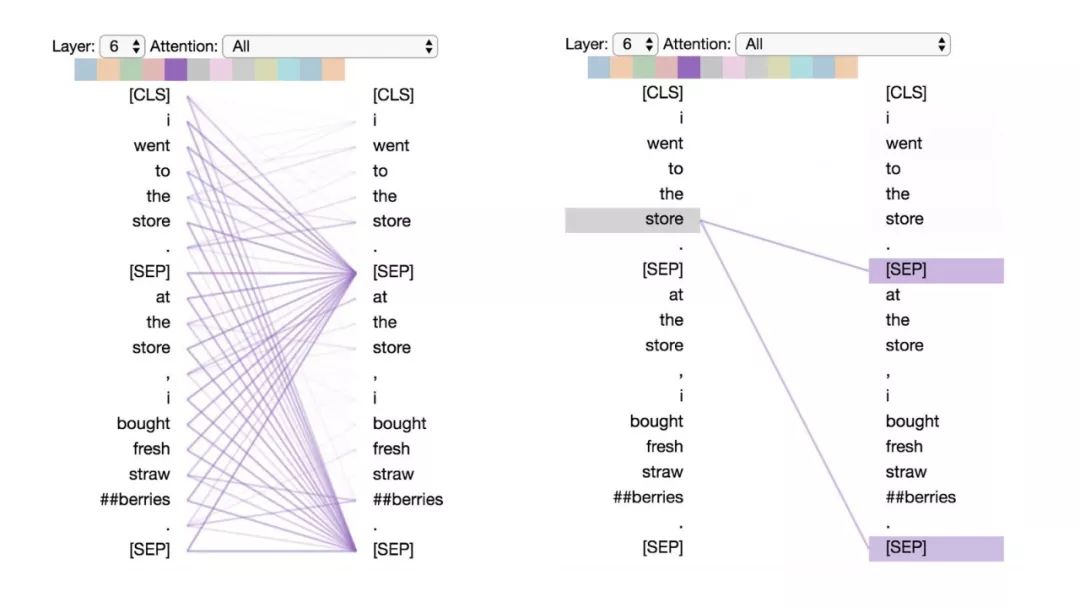
模式6:注意分隔符。左:所有词的注意力。右:所选词的注意权重(“store”)
说明
其实数据可视化有点像罗夏墨迹测验(译注:这种测验叫人解释墨水点绘的图形以判断其性格):我们的解释可能会被我们的主观信念和期望所影响。虽然上面的一些模式非常显著,但其他模式却有点主观,所以这些解释只能作为初步观察。
此外,上述6种模式只是描述了BERT的粗略注意力结构,并没有试图去描述注意力可能捕获到的语言学(linguistic)层面的模式。例如,在模式3和4中,其实可以表现为许多其他不同类型的“相关性”,例如同义关系、共同指代关系等。
而且,如果能看到注意力头是否抓取到不同类型的语义和句法关系,那将会非常有趣。
可视化BERT之二:探索注意力机制的内部细节一
在这里,一个新的可视化工具将展示BERT如何形成其独特的注意力模式。
在上文中,我讲解了BERT的注意力机制是如何呈现出多种模式的。例如,一个注意力头会主要注意序列中的下一个词;而另一个注意力头会主要注意序列中的前一个词(具体看下方图示)。在这两种情况中,BERT在本质上都是学习一种类似RNN的序列更新的模式。之后,我们也将展示BERT是如何建模词袋模型(Bag-of-Words)的。
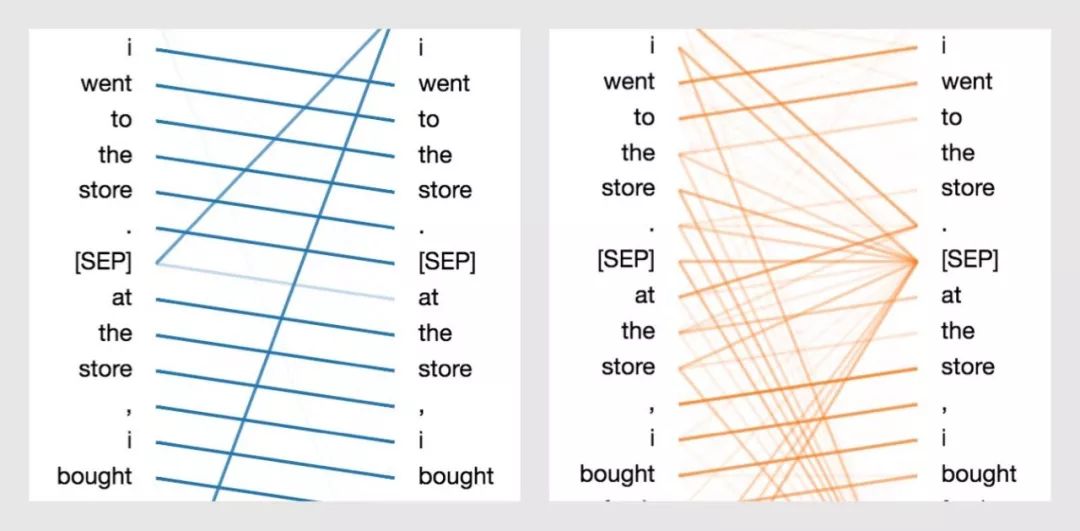
通过BERT学习下一个单词和上一个单词的注意力模式
那么BERT是如何学到这些极好的特性呢?为了解决这个问题,我从第一部分扩展了可视化工具来更深入地探索BERT——揭示提供BERT强大建模能力的神经元。你可以在这个Colab notebook或者Github上找到这个可视化工具。
最初的可视化工具(基于由Llion Jones出色完成的Tensor2Tensor)尝试来解释什么是注意力:也就是说,BERT到底在学习什么样的注意力结构?那么它是怎样学到的呢?为了解决这个问题,我添加了一个注意力细节视图,来可视化注意力的计算过程。详细视图通过点击⊕图标按钮来查看。你可以看到以下的一个demo示例,或直接跳到屏幕截图。
可视化工具概览
BERT有点像鲁布·戈德堡机(译注:是一种被设计得过度复杂的机械组合,以迂回曲折的方法去完成一些其实是非常简单的工作,例如倒一杯茶,或打一只蛋。),尽管每个组件都非常直观,但是系统整体很难把握。现在我将通过可视化工具介绍BERT注意力架构的各个部分。(想了解有关BERT的全部教程,推荐《图解transformer》和《图解BERT》这两篇文章。)
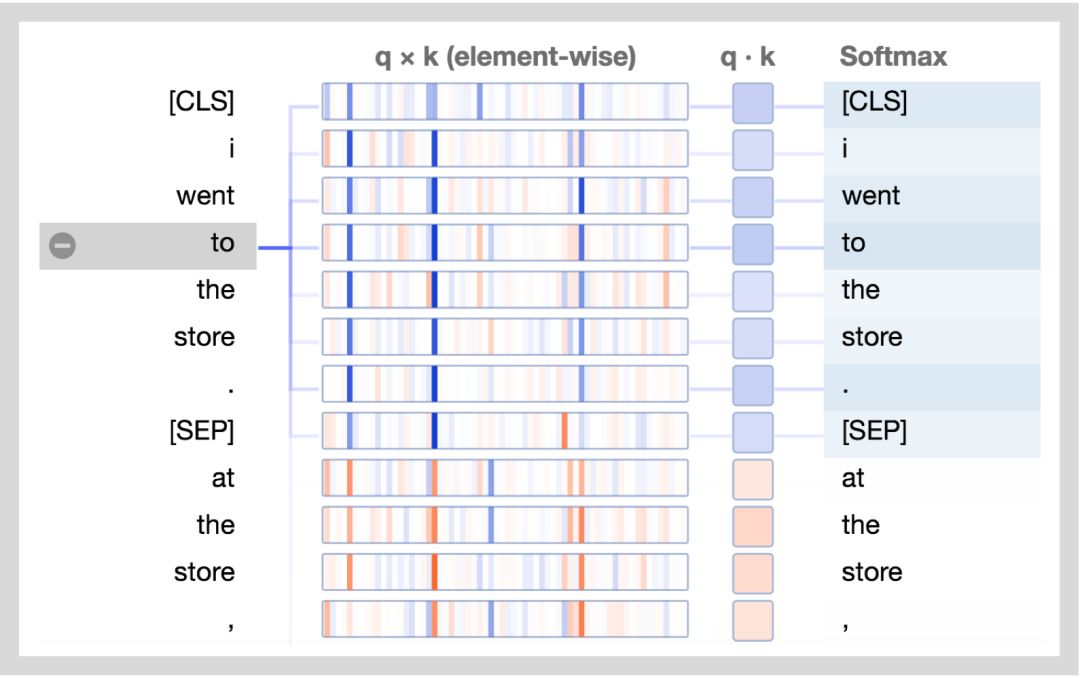
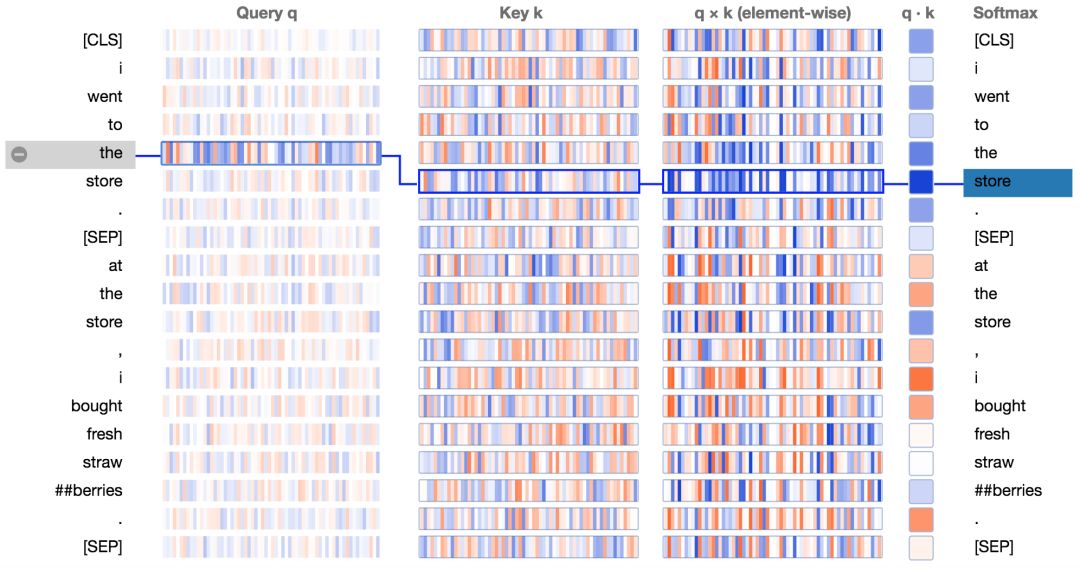
下方展示了新的注意力细节视图。图中正值是蓝色的,负值是橙色的,颜色的深浅反映了取值的大小。所有的向量都是64维的,并且作用于某个特定的注意力头上。和最初的可视化工具类似,连接线颜色的深浅代表了单词之间的注意力强度。
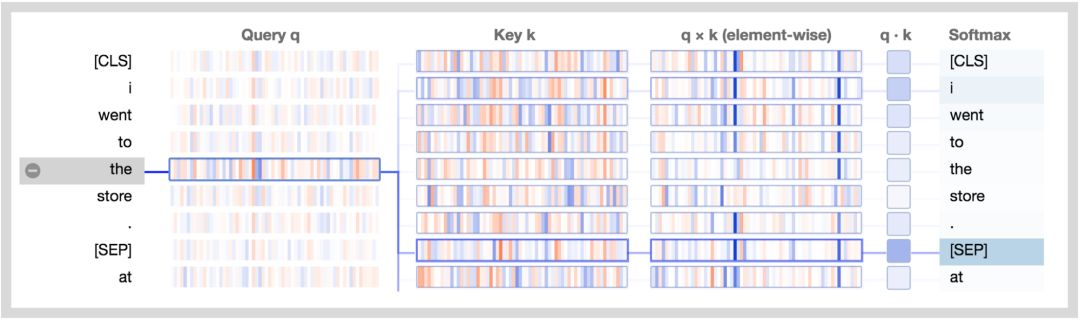
让我们结合图分析一下:
查询向量q :查询向量q是左边正在进行注意力过程的单词/位置的编码,也就是说由它来“查询”其他的单词/位置。在上述的例子中,“the”(选中的单词)的查询向量标注出来了。
键向量k:键向量k是右边正在“被注意”的单词的编码。如下所述,键向量和查询向量决定了单词被注意程度的得分。
q×k(element-wise):查询向量和键向量的逐元素积(译注:element-wise product, 也叫哈达玛积/Hadamard product)。这个逐元素积是通过选定的查询向量和每个键向量计算得到的。这是点积(逐元素乘积的和)的前导。由于它展示了查询向量中的单个元素和键向量对点积的贡献,因此将其可视化。选定的查询向量和每个键向量的点积。得到的是非归一化的注意力得分。
Softmax:所有目标单词的q·k/ 8的softmax值。这一步实现了注意力得分的归一化,保证了值为正的且和为1。常量8是向量长度(64)的开方。论文(https://arxiv.org/pdf/1706.03762.pdf)描述了这样做的原因。
解析BERT的注意力模式
在第一部分文章中,我在BERT的注意力头的结构中发现了一些模式。来看看我们是否能使用新的可视化工具来理解BERT是如何形成这些模式的。
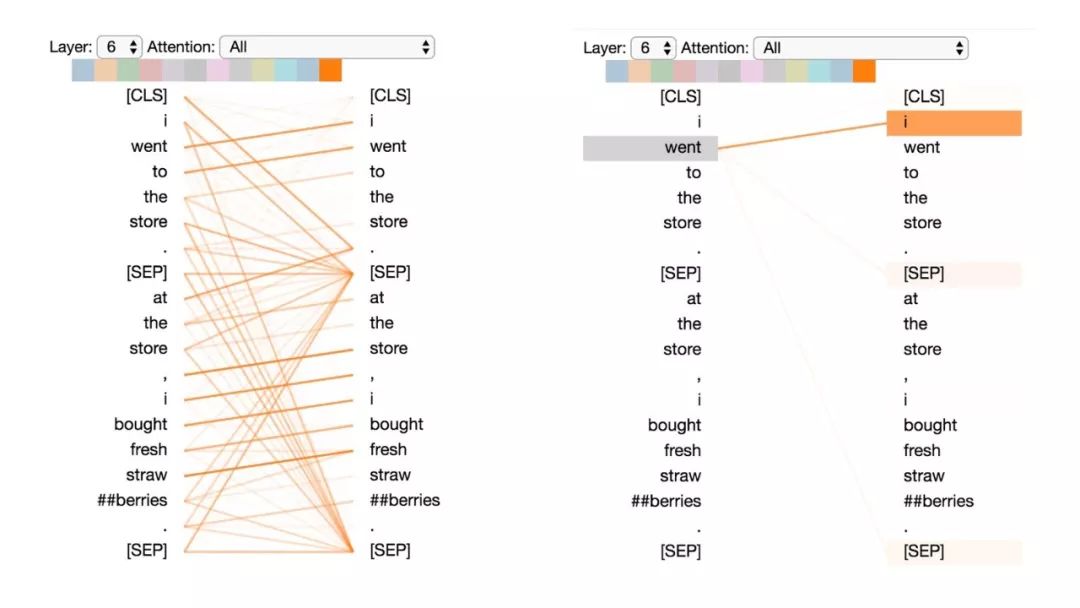
注意分隔符
让我们以一个简单的例子起手,这个例子中大多数注意力是聚焦于分隔符[SEP]的(第一部分文章中的模式6)。如第一部分文章中所描述的,这个模式可能是BERT用来将句子级的状态传播到单词级状态的一种方式。

基于BERT预训练模型的第7层3号头,聚焦分隔符注意力模式。
所以,BERT是如何直接聚焦于[SEP]符号的呢?来看看可视化工具。下面是上述例子的注意力细节视图。
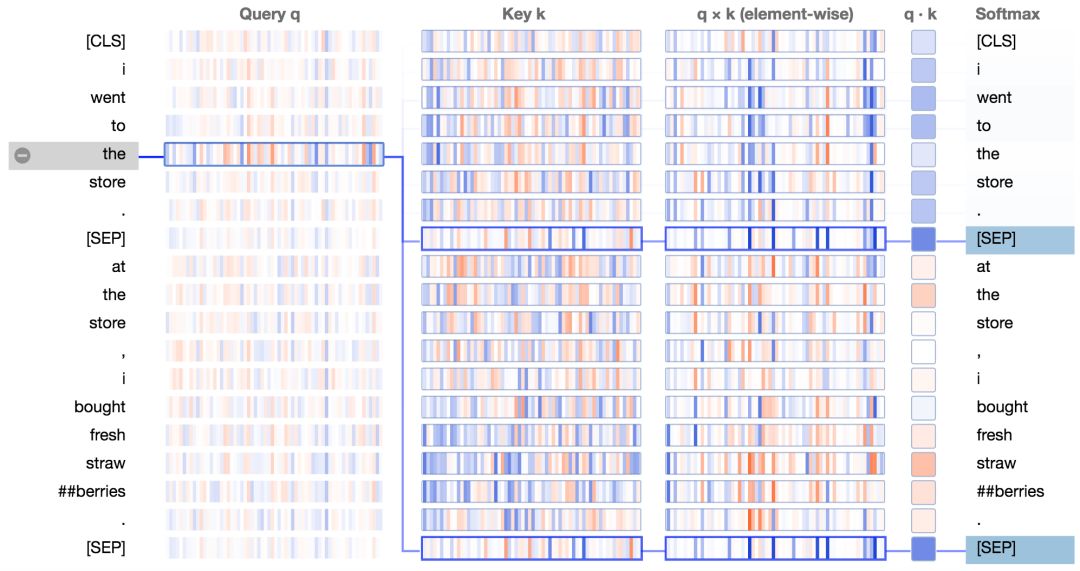
在键向量列,两个出现[SEP]处的键向量有显著的特点:它们都有少量的高正值(蓝色)和低负值(橘色)的激活神经元,以及非常多的接近0的(浅蓝,浅橘或白色)的神经元。

第一个分隔符[SEP]的键向量。
查询向量q会通过那些激活神经元来匹配[SEP]键向量,会使元素內积q×k产生较高的值,如下例子所示:
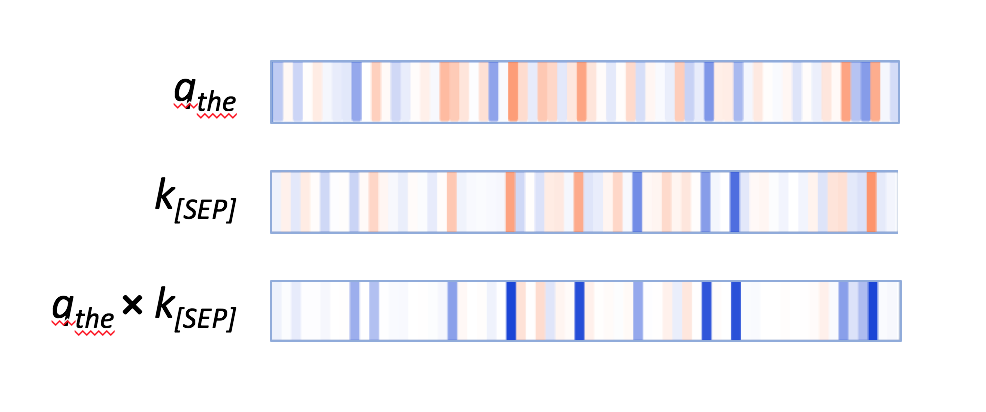
第一个“the”的查询向量;第一个[SEP]的键向量;两个向量的逐元素积。
其他单词的查询向量也遵循相似的模式;它们通过同一组神经元来匹配[SEP]键向量。因此,BERT似乎指定了一小部分神经元作为“[SEP]-匹配神经元”,而查询向量也通过这些相同位置的值来匹配[SEP]键向量。这就是注意分隔符[SEP]的注意力模式。
注意句子:词袋模型(Bag of Words)
这是一个不太常见的模式,在第一部分文章中没有具体讨论。在这种模式中,注意力被平均的分配到句子中的每个单词上。

基于BERT预训练模型的第0层0号头,专注句子的注意力模式
这个模式的作用是将句子级的状态分配到单词级上。BERT在这里本质上是通过对所有词嵌入进行几乎相等权重的加权平均操作来计算一个词袋模型。词嵌入就是我们之前提到的值向量。
那么BERT是怎样处理查询向量和键向量来形成这种注意力模式的呢?让我们再来看看注意力细节视图;
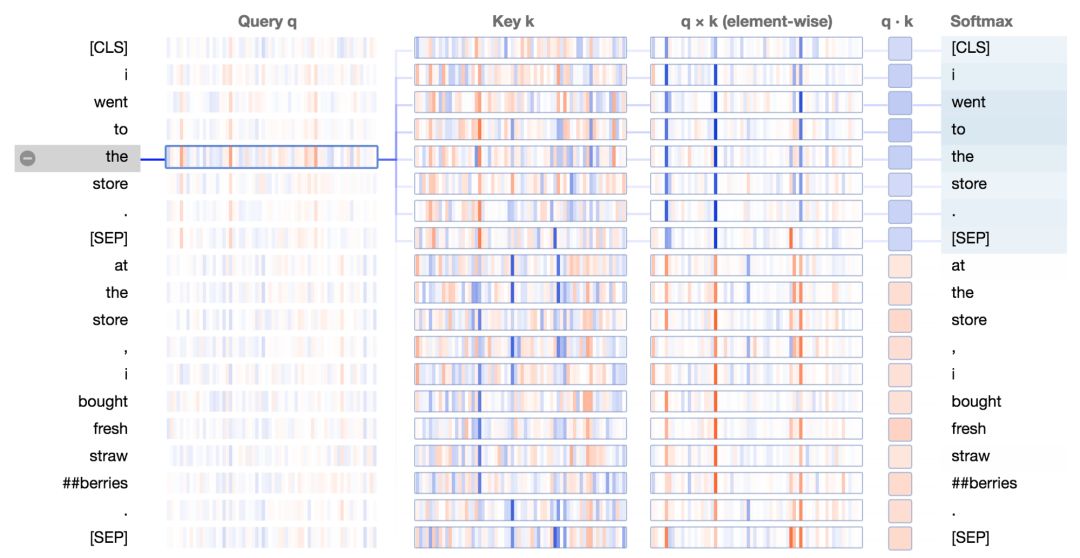
基于BERT预训练模型的第0层0号头,专注句子的注意力模式细节视图。
在q×k这列,我们能看到一个清晰的模式:少量神经元(2-4个)控制着注意力得分的计算。当查询向量和键向量在同个句子中时(上例中第一个句子),这些神经元的乘积显示出较高的值(蓝色)。当查询向量和键向量在不同句子中时,在这些相同的位置上,乘积是负的(橘色),如下例子所示:
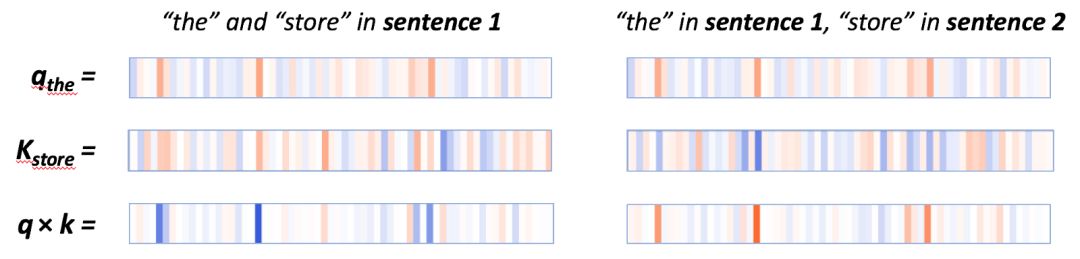
在同个句子中(左边)q*k的逐元素积很高,在不同句子中(右边)q*k的逐元素积很低。
当查询向量和键向量都来自第一个句子中时,它们在激活神经元上往往有相同的符号,因此会产生一个正积。当查询向量来自第一个句子中时,键向量来自第二个句子时,相同地方的神经元会有相反的符号,因此会产生一个负值。
但是BERT是怎么知道“句子”这个概念的?尤其是在神经网络第一层中,更高的抽象信息还没有形成的时候。这个答案就是添加到输入层(见下图)的句子级嵌入(sentence-level embeddings)。这些句子嵌入的编码信息传递到下层的变量中,即查询向量和键向量,并且使它们能够获取到特定句子的值。
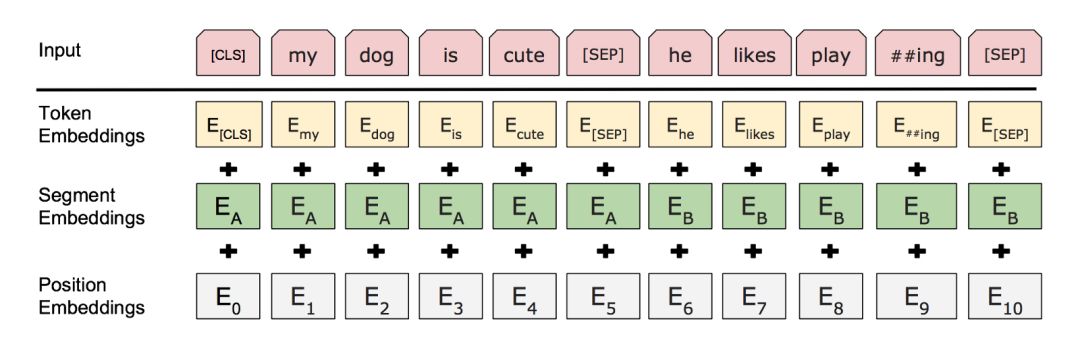
句子A和B的部分嵌入以及位置嵌入被添加到词嵌入中
(来自BERT论文(https://arxiv.org/pdf/1810.04805.pdf))
注意下一个词
在这种注意力模式中,除了分隔符,其他所有的注意力都集中在输入序列的下个单词上。
基于BERT预训练模型的第2层0号头,注意下一个词的注意力模式。
这个模式能够使BERT捕获序列关系,如二元语法(bigrams)。我们来查看它的注意力细节视图;
我们看到查询向量“the”和键向量“store”(下个单词)的乘积在大多数神经元中是很高的正值。对于下一个单词之外的其他单词,q*k乘积包含着一些正值和负值。最终的结果是“the”和“store”之间的注意力得分很高。
对于这种注意力模式,大量的神经元参与到注意力得分中。而且这些神经元根据词位置的不同而不同,如下所示:
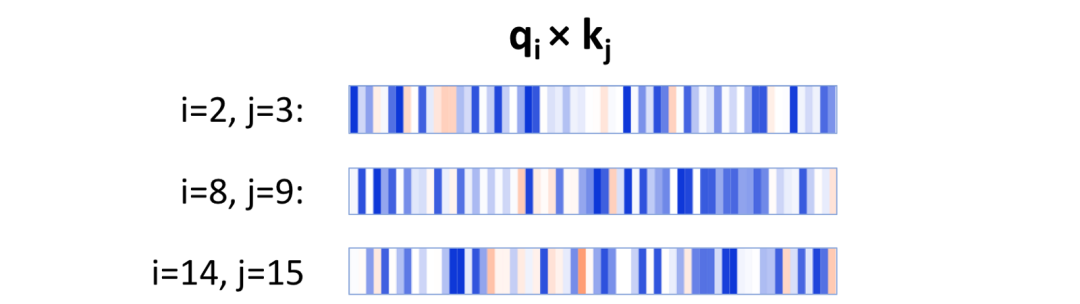
当i取2,4,8的时候,在位置i处的查询向量和在j = i+1处的键向量的逐元素积。注意激活神经元在每一个例子中都不同。
这种方式不同于注意分隔符以及注意句子的注意力模式,它们是由少量固定的神经元来决定注意力得分的。对于这两种模式,只有少量的神经元是必须的,因此这两种模式都很简单,并且在被注意的单词上都没多少变化。与它们相反,注意下个单词的注意力模式需要追踪512个单词(译注:在BERT中每个样本最多512个单词。)中到底是哪个是被一个给定的位置注意的,即哪个是下一个单词。为了实现这个功能,需要产生一系列查询向量和键向量,其中每个查询向量会有从512个键向量有唯一一个匹配。因此使用少量神经元很难完成这个任务。
那么BERT是如何能够生成这些查询向量和键向量呢?答案就在BERT的位置嵌入(position embeddings),它在输入层(见图1)中被添加到词嵌入(word embeddings)中。BERT在输入序列中学习512个独特的位置嵌入,这些指定位置的信息能通过模型流入到键向量和查询向量中。
-
神经网络
+关注
关注
42文章
4842浏览量
108178 -
图像
+关注
关注
2文章
1096浏览量
42438 -
可视化
+关注
关注
1文章
1363浏览量
22902
原文标题:用可视化解构BERT,我们从上亿参数中提取出了6种直观模式
文章出处:【微信号:BigDataDigest,微信公众号:大数据文摘】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
七款经久不衰的数据可视化工具!
从使用效果来看,数据可视化工具离不开数据中台吗?
能做数据治理的数据可视化工具,又快又灵活
现在做企业级数据分析,离不开秒分析的数据可视化工具
这样选数据可视化工具,更能选到适用的
SpeedBI数据可视化工具:浏览器上做分析
紧跟老板思维,这款数据可视化工具神了
mongodb可视化工具如何使用_介绍一款好用 mongodb 可视化工具
建议收藏的20款实用的数据可视化工具
数据可视化工具的图表主要分为哪些
怎么挑选合适企业需求的数据可视化工具
几款好用的可视化工具推荐

一键生成可视化图表/大屏 这13款数据可视化工具很强大



评论