 决定神经网络学习处理速度的因素
决定神经网络学习处理速度的因素

今天的文章会重点关注决定神经网络学习处理速度的因素,以及获得预测的精确度,即优化策略的选择。我们会讲解多种主流的优化策略,研究它们的工作原理,并进行相互比较。
优化是寻找可以让函数最小化或最大化的参数的过程。当我们训练机器学习模型时,我们通常会使用间接优化,选择一种特定的衡量尺度,例如精确度或查全率等可以表现模型解决方法表现的指标。但是我们现在进行优化的是另一种不同的价值函数J(θ),希望通过将它的值最小化后,提高目标指标的表现。当然,价值函数的选择通常和正在解决的问题有关,更重要的是,它通常表示我们距离理想解决方案的距离。可以想象,这一话题非常复杂。
优化算法的可视化
陷阱无处不在
通常,找到非凸价值函数的最小值并不容易,我们必须用高级的优化策略定位它们。如果你学过微积分,你会了解“局部最小值”的定义——这可能是优化器最容易陷入的陷阱。此类情景的例子可以从上图左边看到,可以清楚地发现,优化器定位的点并不是最优解。
想克服所谓的“鞍点”问题会更困难。在水平处,价值函数的值几乎是常数,上图右侧体现了这一问题,在这些点上,梯度在各个方向上几乎为零,所以很难逃脱。
有时,尤其是在多层网络中,我们要处理的价值函数可能很陡。在这种区域,梯度的值可能会急剧增加,即形成梯度爆炸,导致巨大的步长。但是这一问题可以通过梯度裁剪(gradient clipping)避免。
梯度下降
在了解高级算法之前,先让我们看看基础算法。也许最直接的方法之一就是向梯度的相反方向发展。这一策略可以用以下公式表示:
其中α是一个称为学习速率的超参数,是每次迭代中采取的步长长度。在某种程度上,它的选择表示了在学习速度和精确度之间的权衡。选择的步长太小就会导致繁琐的计算,不可避免地会进行多次迭代。但是,选择的值过大,又无法找到最小值。如下图所示,我们可以看到在相邻的两次迭代上是如何变化的,而不是趋于稳定。同时,如果模型确定了合适的步长,可能会立刻找到一个最小值。
低学习率和高学习率下梯度下降
除此之外,算法还对“鞍点”问题很脆弱,因为在连续迭代中的修正尺寸对计算梯度是成比例的,这样的话,就无法从平坦处逃脱。
最后,重点是这种算法并不高效,它在每次迭代中都需要用全部的训练集。这意味着,在每个epoch中我们都要查看所有样本,从而在下次进行优化。如果只有几千个样本还好,但如果有上百万个样本呢?在这种情况下,很难想象每次迭代需要花费多少时间
mini-batch梯度下降
梯度下降和mini-batch梯度下降对比
在这一部分,我们要重点解决梯度下降不高效的问题。虽然向量化处理加速了计算,当数据集有百万个样本时,可以一次性处理多个训练样本。这里我们可以试试另一种方法,将整个数据集分成多个更小的批次(batch),用它们进行连续迭代。如上面动图所示,由于每次处理的数据量更少了,新算法做决策的速度更快了。另外注意观察模型之间动作的对比。梯度下降算法每一步都很长,且噪声较小,而mini-batch梯度下降的步长更小,噪声更大。甚至在mini-batch中,一次迭代可能会向相反方向发展。但是平均来说,都能达到最小值。
那么怎样选择batch size呢?在深度学习中,这类答案是不固定的,取决于要解决的案例。如果batch size等于整个数据集,那么处理起来就是普通的梯度下降。如果size为1,那么每次迭代禁止数据集的一个样本。这种方法通常比较公平,常见的就是随机梯度下降,它是通过选择一个随机数据集记录,用它们当做训练集进行连续迭代。但是,如果我们决定使用mini-batch,通常会选择一个中间值,通常是从64到512之间的样本中选择。
指数加权平均
这一概念在统计学或经济学中都有出现。很多高级神经网络优化算法都用到了这一方法,因为它能在梯度为零的情况下依旧进行优化。我们接下来以去年至今某大型科技公司的股票走势为例进行讲解。
不同β值下指数加权平均可视化
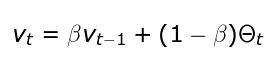
EWA主要是对之前的值进行平均,以便独立考虑局部波动,并专注于整体趋势。它的值使用上面的递归公式计算的,其中β适用于控制要平均的值的范围参数。对于较大的β值,我们得到的图形更平滑,因为记录更多。
带有动量的梯度下降
这一策略用指数加权平均避免了某一点处价值函数接近于0的可能。简单来说,我们让算法具有一定动量,所以即使局部梯度为0,我们仍然可以更具此前计算的值向前。所以这与纯梯度下降相比是更好的方法。
通常,我们用反向传播计算网络中每一层dW和db的值。但是这一次,我们不直接用计算梯度更新神经网络参数的值,而是先计算VdW和Vdb的中间值。之后我们在梯度下降中用刀VdW和Vdb,过程如下公式所示:
如上文中股票的例子,指数加权平均可以让我们专注于领先趋势而不是噪声。指示最小值的分量被放大,并且缓慢消除负责震荡的分量。更重要的是,如果我们在后续更新中获得指向类似方向的梯度,则学习率将增加。然而,这种方法有一个缺点:当你接近最小值时,动量值会增加,并且可能会变得很大,以至于算法无法再正确位置停止。
RMSProp
另一种提高梯度下降性能的方法就是使用RMSProp策略,这也是最常用的优化算法之一。这也是另一种使用甲醛梯度下降的算法,并且它是可自适应的,可以对模型每个参数调整学习率。后续参数的值取决于此前特殊参数上梯度的值。
但是,这种方法也有缺点,如上等式中的分母在每次迭代中增加,我们的学习率就会越来越小,结果可能导致模型完全停止。
优化对比
Adam
最后的最后,我们来到了自适应动量估计。这也是使用广泛的算法,它吸取了RMSProp最大的优点,将动量优化的概念相结合,使得策略可以做出快速高效的优化。
但是,尽管方法高效,计算的复杂程度也相应上升。如上所示,我写了十个矩阵等式,表示优化过程中的单次迭代。可能很多人看起来都非常陌生。不要担心!这些等式和此前的动量和RMSProp优化算法相似。
结语
这篇文章对几种优化算法做了大致总结,了解这些算法有助于在不同情况下正确使用。
-
神经网络
+关注
关注
42文章
4830浏览量
106907 -
机器学习
+关注
关注
66文章
8542浏览量
136297 -
数据集
+关注
关注
4文章
1232浏览量
26069
原文标题:快速训练神经网络的优化算法一览
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
详解深度学习、神经网络与卷积神经网络的应用






 工商网监
工商网监
评论