 街机游戏《街头霸王 3》中进行模拟来训练改进强化学习算法的工具包
街机游戏《街头霸王 3》中进行模拟来训练改进强化学习算法的工具包

从世界瞩目的围棋游戏 AlphaGo,近年来,强化学习在游戏领域里不断取得十分引人注目的成绩。自此之后,***、射击游戏、电子竞技游戏,如 Atari、超级马里奥、星际争霸到 DOTA 都不断取得了突破和进展,成为热门的研究领域。
突然袭来的回忆杀~
今天为大家介绍一个在街机游戏《街头霸王 3》中进行模拟来训练改进强化学习算法的工具包。不仅在 MAME 游戏模拟器中可以使用,这个 Python库可以在绝大多数的街机游戏中都可以训练你的算法。
下面营长就从安装、设置到测试分步为大家介绍一下。
目前这个工具包支持在Linux系统,作为MAME的包装器来使用。通过这个工具包,你可以定制算法逐步完成游戏过程,同时接收每一帧的数据和内部存储器的地址值来跟踪游戏状态,以及发送与游戏交互的动作。
首先你需要准备的是:
操作系统:Linux
Python 版本:3.6+
▌安装
你可以使用 pip来安装该库,运行下面的代码:
▌《街头霸王3》示例
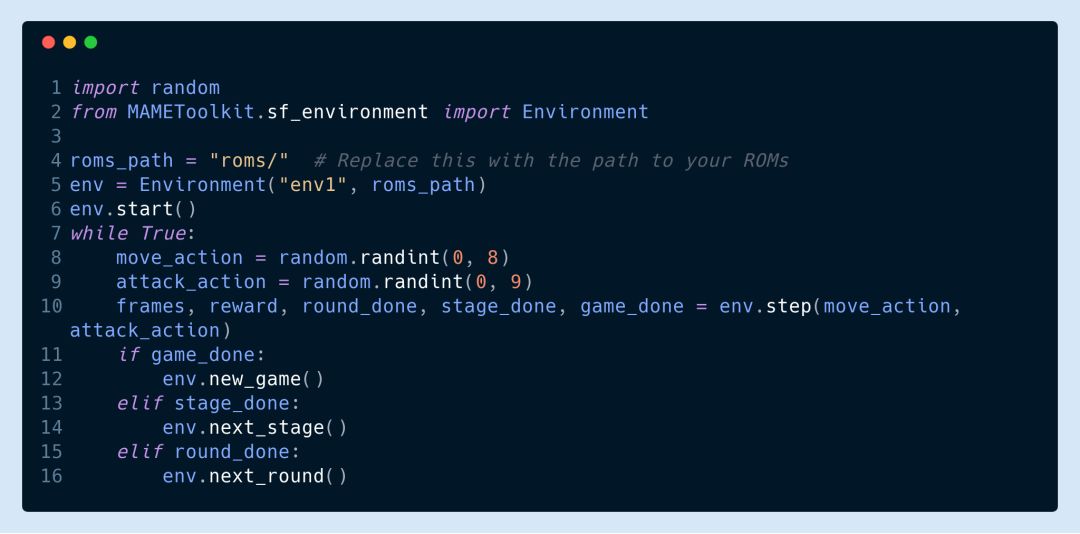
这个工具包目前已用于游戏《街头霸王 3》(Street Fighter III Third Strike: Fight for the Future), 还可以用于MAME上的任何游戏。下面的代码演示了如何在街头霸王的环境下编写一个随机智能体。
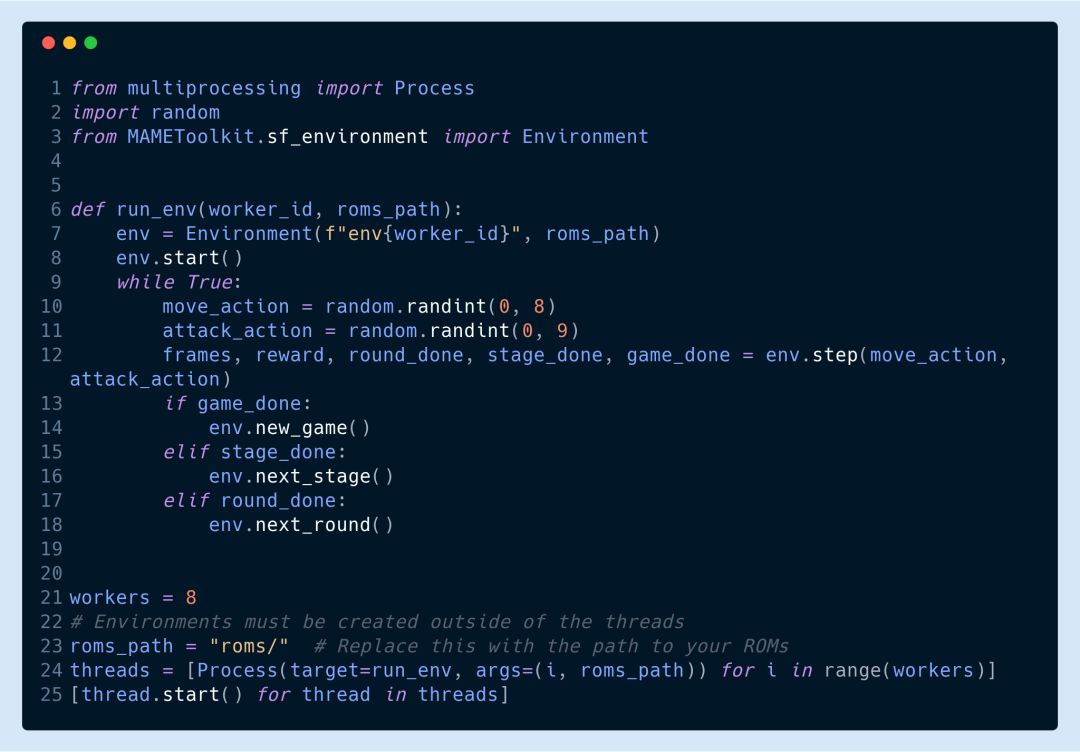
此外,这个工具包还支持hogwild训练:
▌游戏环境设置
游戏 ID
在创建一个模拟环境之前,大家需要先加载游戏的 ROM,并获取 MAME所使用的游戏 ID。比如,这个版本街头霸王的游戏 ID是“sfiii3n”,你可以通过运行以下代码来查看游戏ID:
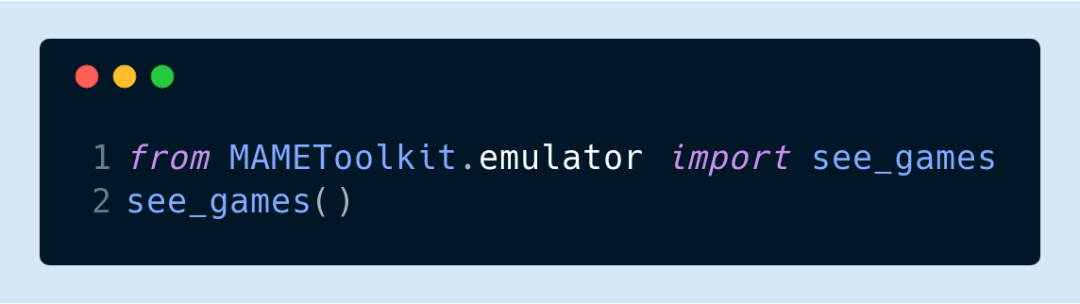
该命令会打开 MAME模拟器,你可以从游戏列表中选择你所要的那款游戏。游戏的 ID通常位于标题后面的括号中。
内存地址
实际上该工具包与模拟器本身不需要太多的交互,只需要查找和内部状态相关联的内存地址,同时用所选取的环境对状态进行跟踪。你可以使用 MAME Cheat Debugger 来观察随着时间的变化,内存地址值发生了怎样的改变。
可以使用以下命令运行Debugger:

更多关于该调试工具的使用说明请参考此教程:
***:***
当你确定了所要跟踪的内存地址后可以执行以下命令进行模拟:
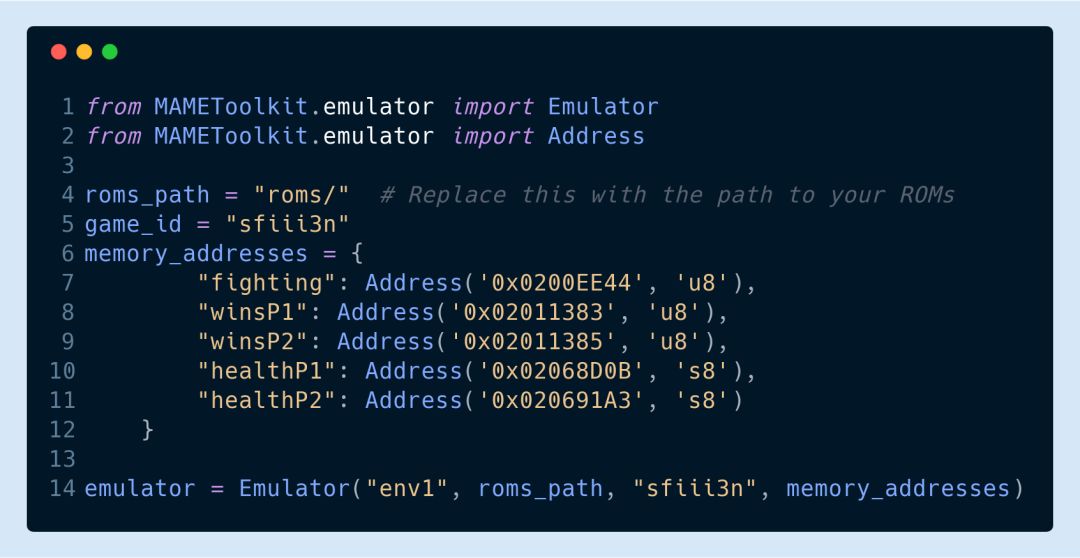
该命令会启动模拟器,并在工具包导入到模拟器进程时暂停。
分步模拟
在工具包导入完成后,你可以使用 step 函数分步进行模拟:
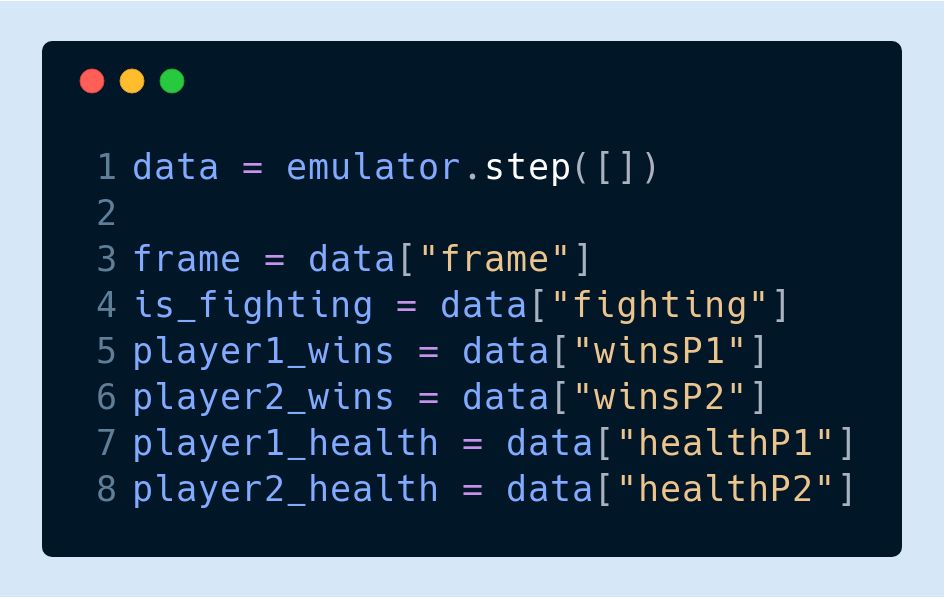
step 函数将以 Numpy 矩阵的形式返回 frame 和 data 的值,同时也会返回总时间步长的所有内存地址整数值。
发送输入
如果要向仿真器输入动作,你还需要确定游戏支持的输入端口和字段。例如,在街头霸王游戏中需要执行以下代码进行投币:

可以使用 list actions命令查看所支持的输入端口,代码如下:
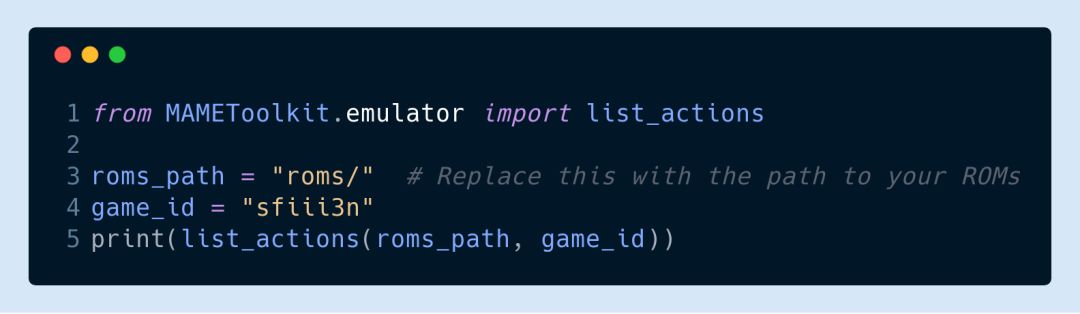
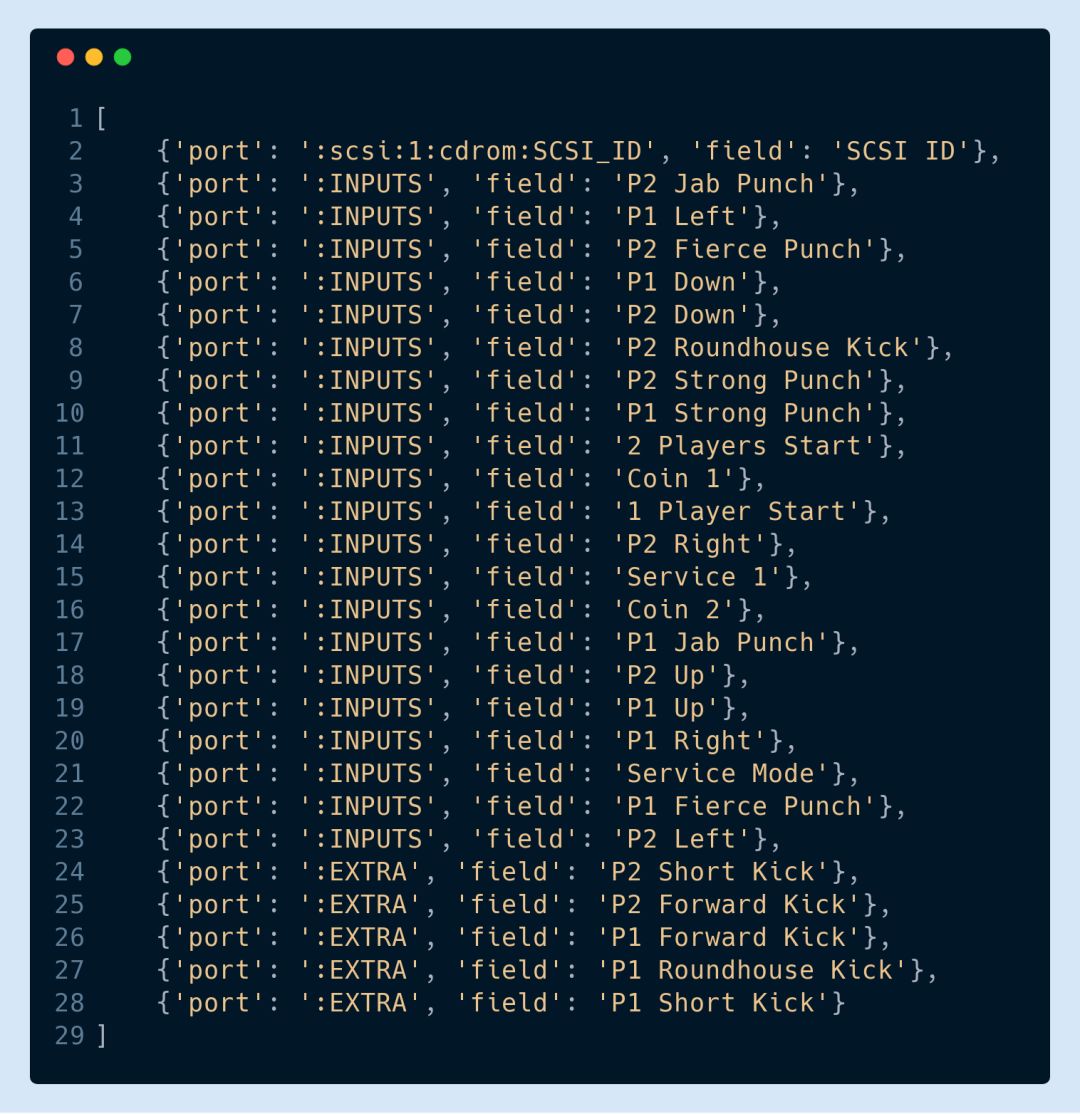
以下返回的列表就包含了街头霸王游戏环境中可用于向 step 函数发送动作的所有端口和字段:
模拟器还有一个 frame_ratio参数,可以用来调整你的算法帧率。在默认设置下,NAME每秒能生成 60帧。当然,如果你觉得这样太多了,你也能通过以下代码将其改为每秒 20帧:

▌性能基准测试
目前该工具包的开发和测试已经在8核AMD FX-8300 3.3GHz CPU以及3GB GeForce GTX 1060 GPU上完成。在使用单个随机智能体的情况下,街头霸王游戏环境可以以正常游戏速度的600%+运行。而如果用8个随机智能体进行hogwild训练的话,街头霸王游戏环境能以正常游戏速度的300%+运行。
▌简单的 ConvNet 智能体
为了确保该工具包能够训练算法,我们还设置了一个包含 5 层 ConvNet 的架构,只需进行微调,你就能用它来进行测试。在街头霸王的实验中,这个算法能够成功学习到游戏中的一些简单技巧如:连招 (combo) 和 格挡 (blocking)。街头霸王的游戏机制是由易到难设置了 10 个关卡,玩家在每个关卡都要与不同的对手对战。刚开始时,智能体平均只能打到第二关,而当经过了 2200 次训练后,它平均能打到第 5 关。学习率的设置是通过每一局中智能体所造成的净伤害和所承受的伤害来计算的。
-
存储器
+关注
关注
39文章
7771浏览量
172493 -
python
+关注
关注
59文章
4892浏览量
90464 -
强化学习
+关注
关注
4文章
275浏览量
12018
原文标题:用这个Python库,训练你的模型成为下一个街头霸王!
文章出处:【微信号:rgznai100,微信公众号:rgznai100】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Facebook推出ReAgent AI强化学习工具包
树莓派街机
深度强化学习实战
什么是强化学习?纯强化学习有意义吗?强化学习有什么的致命缺陷?

NVIDIA迁移学习工具包 :用于特定领域深度学习模型快速训练的高级SDK
谷歌AI发布足球游戏强化学习训练环境“足球引擎”
基于PPO强化学习算法的AI应用案例
机器学习中的无模型强化学习算法及研究综述

7个流行的强化学习算法及代码实现
7个流行的强化学习算法及代码实现

模拟矩阵在深度强化学习智能控制系统中的应用




评论