 浅谈ug1292中的降低逻辑延迟的解决方案
浅谈ug1292中的降低逻辑延迟的解决方案

在实现阶段,Vivado会把最关键的路径放在首位,这就是为什么在布局或布线之后可能出现逻辑级数低的路径时序反而未能收敛。因此,在综合或opt_design之后就要确认并优化那些逻辑级数较高的路径。这些路径可有效降低工具在布局布线阶段为达到时序收敛而迭代的次数。同时,这类路径往往逻辑延迟较大。因此,降低这类路径的逻辑延迟对于时序收敛将大有裨益。
降低逻辑延迟的流程如下图所示。不难看出,这一工作应在综合或者opte_design阶段完成。

在这个流程中,我们需要关注两类路径。一类路径是由纯粹的CLB中的资源(FF,LUT,Carry,MUXF)构成的路径;另一类则是Block(DSP,BRAM,URAM,GT)之间的路径。
无论是哪种路径,首先要通过命令report_design_analysis进行定位,具体命令格式如下图所示(也可在Vivado菜单Reports -> Report Design Analysis下执行)。
该命令可分析当前设计的逻辑级数分布情况,如下图所示,从而便于找到逻辑级数较高的路径。
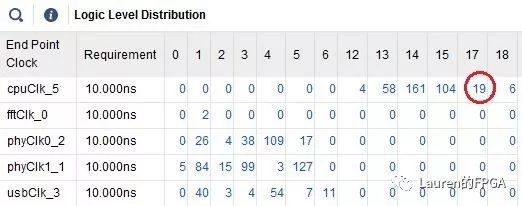
点击逻辑级数分布报告中的数字,例如图中的19,可生成相应的时序报告,从而确定属于哪类路径,并进一步观察路径特征。
对于级联的小的LUT
如果路径中包含多个级联的小的LUT,检查一下这些LUT是否是因为设计层次、综合属性(KEEP,KEEP_HIERARCHY,DONT_TOUCH,MARK_DEBUG)等导致无法合并。
对于路径中存在单个的Carry
如果路径中有单个的Carry(不是级联的),检查一下这个Carry是否限制了工具对LUT的优化,从而造成布局不是最优的。如果是,可尝试在综合时使用FewerCarryChains策略或者在opt_design阶段对这个Carry设置CARRY_REMAP属性(具体使用方法可查看ug904)。
对于终点是SRL的路径
如果路径的终点是SRL,可尝试将SRL变为FF+SRL+FF或SRL+FF。这可在综合时通过使用SRL_STYLE综合属性实现,也可在opt_design阶段通过使用SRL_STAGES_TO_INPUT或SRL_STAGES_TO_OUTPUT实现。
对于终点是触发器控制端的路径
如果路径的终点是由LUT输出连接到触发器的同步使能端或同步复位端,可尝试将这类逻辑搬移到触发器的数据端,这可在综合时通过设置EXTRACT_ENABLE或EXTRACT_RESET综合属性实现,或者在opt_design阶段通过设置CONTROL_SET_REMAP属性(具体使用方法可查看ug904)实现。
使用Retiming
此外,还可以在综合时对全局使用retiming(选中-retiming选项)或者采用模块化综合方式,对某个模块使用retiming。
对于Block到Block的路径
对于Block到Block的路径,最好将其优化为Block + FF + Block。这里的FF可以是Block内部自带的触发器(如果有的话),也可以是Slice中的触发器。
如果数据由Block RAM输出,可采用如下命令观察使能Block RAM自带的寄存器之后是否对时序有所改善。这里要注意,如下命令用于评估,因为已造成设计功能改变,所有不要在此基础上生成bit文件。
set_property –dict {DOA_REG 1 DOB_REG 1} [get_cellsxx/ramb18_inst]
该命令等效于
set_property DOA_REG 1
[get_cells xx/ramb18_inst]
set_property DOB_REG 1
[get_cells xx/ramb18_inst]
-
逻辑
+关注
关注
2文章
834浏览量
30053 -
触发器
+关注
关注
14文章
2051浏览量
63043 -
ug1292
+关注
关注
0文章
3浏览量
2408
原文标题:深度解析ug1292(5)
文章出处:【微信号:Lauren_FPGA,微信公众号:FPGA技术驿站】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
ug1292时序收敛快速参考手册

ug1292深度解析
UG1292使用之初始设计检查使用说明

深度解析ug1292:降低布线延迟
数据采集系统中降低功耗的解决方案

DC1292A DC1292A评估板
【虹科方案】西部数据超低延迟NVMe存储解决方案

UltraFast设计方法时序收敛快捷参考指南(UG1292)







 工商网监
工商网监
评论