 深度学习制作音乐时存在某些逻辑上的问题
深度学习制作音乐时存在某些逻辑上的问题

编者按:本文来自数据科学家Haebichan Jung,他发现用深度学习制作音乐时存在某些逻辑上的问题,并用数据方法创建自己的模型解决了这一问题。本文分为四部分:
问题定位:我是如何发现在利用深度学习技术生成流行音乐时会有问题的。
解决方法:我如何创建了一个原始的音乐生成机器,只需要简单方法就能与深度学习相媲美。
结果评估:我是如何建立一套评估体系,用数学方法证明“我的音乐比深度学习生成的方法听起来更像流行音乐”的。
泛化:如何发现生成自己模型的方法,将其应用到场景而不是音乐生成上。
以下是论智带来的编译:
我创建了一个简单的概率模型,可以生成流行音乐。有了客观评判尺度之后,我认为模型生成的音乐听起来更接近流行音乐的风格。我是如何做到的呢?其中最主要的原因是我关注到了流行音乐的核心:主旋律(melody)和和声(harmony)之间的数据关系。
主旋律是人声部分,是曲调。和声是伴奏、和弦。在钢琴曲中,主旋律由右手演奏,左手负责和弦
问题所在
在研究二者的关系之前,让我们首先对这一问题下个定义。我最初开始这个项目时,只是单纯想用深度学习生成流行音乐。然后我就接触到了LSTMs,这是一种特殊的循环神经网络,是用于文本和音乐生成的流行工具。
另一位数据科学家Sigurður Skúli曾写过一篇教程,讲述了如何用LSTM神经网络和Keras生成音乐。地址:towardsdatascience.com/how-to-generate-music-using-a-lstm-neural-network-in-keras-68786834d4c5
但是我深入了解后,对使用RNN和各种变体生成流行音乐的方法背后的逻辑产生了怀疑。这种逻辑看起来是建立在多种有关流行音乐内部结构的假设上,但我并不完全认可。
其中一个具体的假设是主旋律和和声彼此独立的关系。
例如,2017年,多伦多大学的研究人员Hang Chu等人曾发表文章:Song From Pi: A Musically Plausible Network for Pop Music Generation。其中作者认为:“假设和弦是独立于给定的旋律的……”基于这一论断,作者搭建了一个复杂多层的RNN模型,主旋律在它所在的层中可以生成音符,而在和弦层中音符是自动生成的。除了彼此独立,该模型是依靠主旋律生成和弦的,这就意味着和弦的音符生成是取决于主旋律的。
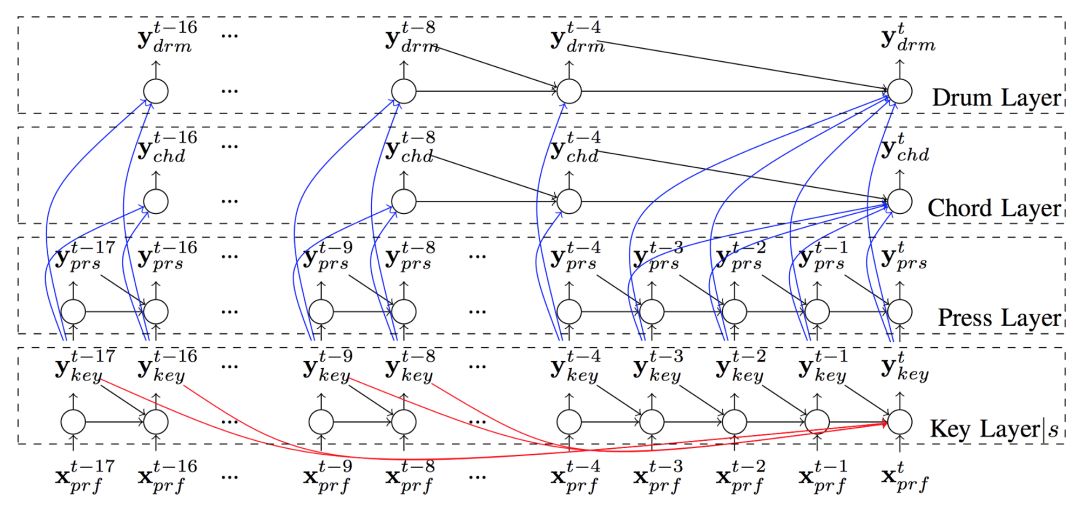
Hang Chu等人的RNN模型,每一层用于生成歌曲的不同部分
我觉得这种模型很奇怪,因为他并没有模仿人类创作歌曲的方法。我本人曾学过钢琴,就个人而言,我是不会在创作主旋律音符时不考虑和弦的。因为和弦音符既定义了旋律,也对旋律有所限制。西方流行音乐有一个很重要的特质:和弦是决定主旋律的关键。用数据科学语言表达,我们可以说某一有条件的概率控制了主旋律和和声之间的数据关系。
解决方法
首先,我研究了控制不同类型音符之间关系的预定概率。其中一个例子就是上文中提到的旋律与和声之间的“垂直”关系。
处理数据
关于数据,我将20首流行音乐转换成midi格式,完整歌单可以点击:www.popmusicmaker.com/
利用一个名为music21的Python库,主要通过马尔科夫过程处理了midi文件,提取出作为输入的不同类型的音符之间的数据关系。具体来说,我会计算我的音符之间的转移概率(transition probability)。这表示,当音符从前一个过渡到下一个时,我们可以计算其中的概率(下文会继续深入讲解)。
midi格式:一首歌的数字化版本
首先,我会提取旋律音符和和弦音符之间“垂直”的转移概率。同时我也会根据数据集计算旋律与和弦音符之间“水平”的转移概率。下表就是三种不同类型的音符所计算出的不同转移概率矩阵:
由上至下分别是三种不同的过渡概率:旋律和和弦音符之间的概率;旋律音符之间的概率;和弦音符之间的概率
模型
利用这三种概率矩阵,我的模型可以遵循以下步骤运行:
1.从数据中随机选择可用的和弦音符。
2.用上表中第一种概率矩阵,基于和弦音符选择旋律音符。
3.用上表中第二种概率矩阵,基于旋律音符选择和弦音符。
4.重复步骤3,直至结尾。
步骤1~4
5.用上表中第三种概率矩阵,基于此前的和弦音符选择新的和弦音符。
6.重复步骤1~4,直至结尾。
步骤5~6
为了详细解释这一过程,我们用具体例子代替。
1.机器随机选择了伴奏音符F。
2.音符F可以选择四个旋律音符。利用第一种转移概率矩阵,它可能会选择旋律音符C(因为有24.5%的概率可能被选到)。
3.之后,旋律音符C会进入第二种概率矩阵,选择下一个旋律音符,它可能会选A(概率有88%)。
4.第三步会继续生成新的旋律音符,直至结尾。
5.和弦音符F会转入第三个矩阵,选择下一个和弦音符。根据表中的概率,它可能会选择和弦音符F或和弦音符C。
6.重复步骤1~4。
结果评估
接着就是最难的部分了——如何对不同模型进行评估。在文章开头,我曾说这个简单的概率模型能超越神经网络,但如何将我的模型和来自神经网络的模型进行比较呢?如何用客观事实说明我生成的音乐的确更接近流行风格呢?
为了回答这个问题,我们首先要明确流行音乐的定义。我是从数据角度出发的,但是流行音乐还有另一个重要的决定因素,即要看在一首歌曲中,开头、中间和结尾部分(前奏、主歌、副歌、桥段、尾奏等各个部分)都是如何重复的。
例如迪士尼电影《冰雪奇缘》的主题曲《Let it go》中的“Let it go, let it go, can’t hold it back anymore…”就是处于整首歌的中间部分而不是开头或结尾,并且这一部分在整首歌里重复了三次。
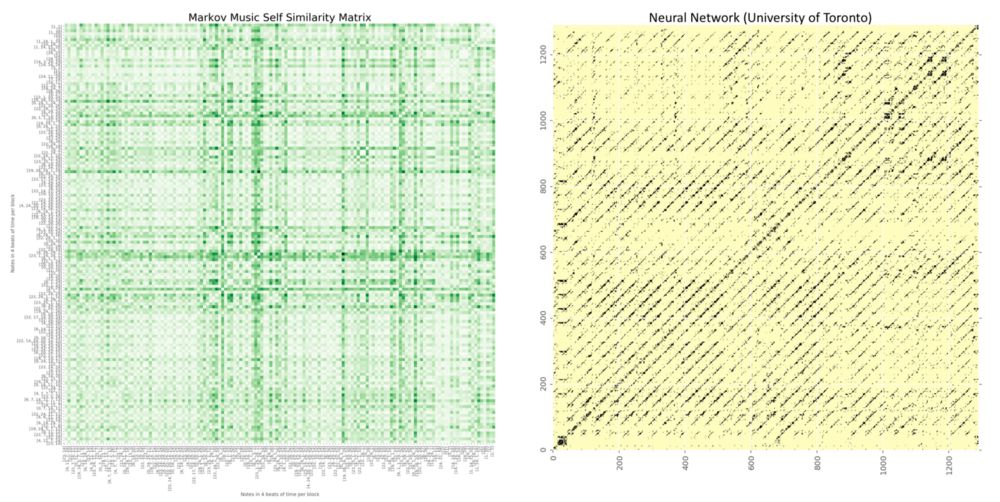
知道了这一点,我们可以使用一种名为“自相似性矩阵”的工具,它可以通过数学方法将歌曲的前奏、中间主歌和尾奏进行可视化。下方是电影《曾经(Once)》的歌曲《Falling Slowly》的自相似性矩阵。
每个小方块表示每个音符在四个节拍中演奏的可视化
在上方动图中,第一个蓝色的大方块表示歌曲的开头部分,第二个黄色方块表示歌曲的另一个片段。第一和第三个方块都是蓝色,是因为它们有相同的自相似性。第二和第四也是如此。
接着,我对数据库中的20首歌曲全部进行了可视化处理。
结果
结果非常有说服力。在引入自相似性矩阵之前,我的模型生成的乐曲没有内部的重复结构。但是将输入数据的结构进行复制,你可以看到生成的音乐出现了对应的模块。
多伦多大学提出的神经网络模型生成的音乐可视化后是这样的:

对比如下:
泛化
最后我想解决的是泛化的问题。我们如何把这个由数据驱动的模型用于除生成流行音乐以外的其他场景呢?换句话说,有没有其他的模型和我的流行音乐生成模型结构相同?
经过我的思考,我发现另一种创作确实有这种结构,即流行歌词!
以Edward McCain的《I’ll be》为例,其中一段是这样的:
I’ll be your cryin’ shoulder
I’ll be love suicide
I’ll be better when I’m older
I’ll be the greatest fan of your life
让我们把这段歌词分解,用同样的机器学习泛化语境。我们可能会将“I’ll be”作为语言模型的第一个输入,这一二元模型会生成“your”、“crying”和“shoulder”。
之后就是重要的问题:开头短语“I’ll be”是否和结尾的“shoulder”彼此独立呢?换句话说,第一句话的最后一个单词和第二句话的开头单词是否有关?
我觉得没有关系。虽然以“shoulder”结尾,但开头的“I’ll be”是基于前几句话的规律,它们形成了重复,说明这几句话之间的开头都有相似的关系。
我觉得这一发现很奇妙!流行音乐和流行歌词都有相似的结构,即内部都能用数据表示。你可以浏览我的网站:www.popmusicmaker.com试试创造自己的音乐。
-
神经网络
+关注
关注
42文章
4845浏览量
108376 -
深度学习
+关注
关注
73文章
5614浏览量
124751
原文标题:论作曲的能力,深度学习打不过简单的概率方法
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Nanopi深度学习之路(1)深度学习框架分析
深度学习模型是如何创建的?
什么是深度学习?使用FPGA进行深度学习的好处?
深度学习和机器学习深度的不同之处 浅谈深度学习的训练和调参
利用独创的深度学习模型,通过对大量音乐数据的学习及训练写出音乐作品
无线音乐门铃的电路制作
深度学习在嵌入式设备上的应用

什么是深度学习算法?深度学习算法的应用
深度学习框架是什么?深度学习框架有哪些?
计算机视觉中的九种深度学习技术




评论