 一种全新的无监督机器翻译方法,在BLUE基准测试上取得了10分以上提升
一种全新的无监督机器翻译方法,在BLUE基准测试上取得了10分以上提升

Facebook研究人员提出了一种全新的无监督机器翻译方法,在BLUE基准测试上取得了10分以上提升。研究人员表示,这种无监督方法不仅适用于机器翻译,也可以扩展到其他领域,让智能体在使用无标记数据的情况下,完成只有极少甚至没有训练数据的任务。这是机器翻译以及无监督学习的一项重大突破。而其实现方法本身也十分巧妙,相关论文已被EMNLP 2018接收。
自动语言翻译对于Facebook来说非常重要,因为Facebook用户高达数十亿,可以想见其平台每天承载和需要转换的语种数量。当然,有了神经机器翻译(NMT)技术以后,机器翻译的速度和水平都得到了大幅提升。
不过,传统的统计机器翻译也好,NMT也罢,都需要大量的训练数据,比如中英、英德、英法等大量语言对。而对于训练数据较少的语种,比如尼泊尔语,就很难应对了。这也是之前谷歌翻译出现奇怪宗教预言的原因之一,因为《圣经》是被翻译成最多语种的文本之一,专家推测谷歌应该使用《圣经》文本来训练谷歌机器翻译系统,而当出现杂乱无章的输入以后,机器拼命想要从中“找出”意义,才会出现一些来自《圣经》中的语句。
话题扯远了。回来Facebook面对的问题上来。
正如前文所说,如何解决小语种,也即没有大量可供训练的数据时,机器翻译的问题呢?
Facebook的研究人员提出了一种“不需要任何翻译资源的MT模型”,也即“无监督翻译”,他们认为这是机器翻译未来的发展方向。在即将举行的EMNLP 2018上,Facebook研究人员将展示的他们的结果。
新方法比以前最先进的无监督方法有了显著的改进,其效果相当于使用近10万个参考译文训练过的监督方法。用机器翻译常用的基准BLEU衡量,Facebook的新方法实现了超过10分的改善(BLEU上提高1分就已经是相当了不起的成果了)。
对于机器翻译而言,这是一个非常重要的发现,特别是小语种而言,有些训练数据很少,有些甚至连训练数据都没有。而Facebook提出的无监督机器翻译,能够初步解决这一问题,比如在乌尔都语(注释:巴基斯坦的国语,属于印欧语系印度-伊朗语族的印度-雅利安语支;是全球使用人数排名第20的语言)和英语之间进行自动翻译——不需要任何翻译好的语言对。
这种新方法为更快、更准确地翻译更多的语言打开了一扇门。同时,相关的技术原理或许也能用于其他机器学习和人工智能的应用。
通过旋转对齐词嵌入结构,进行词到词的翻译
Facebook无监督机器翻译的方法,首先是让系统学习双语词典,将一个词与其他语言对应的多种翻译联系起来。举个例子,就好比让系统学会“Bug”在作为名词时,既有“虫子”、“计算机漏洞”,也有“窃听器”的意思。
Facebook使用了他们在之前发表于ICLR 2018的论文《Word Translation Without Parallel Data》中介绍的方法,让系统首先为每种语言中的每个单词学习词嵌入,也即单词的向量表示。
然后,系统会训练词嵌入,根据其上下文(例如,给定单词前后的各5个单词)来预测给定单词周围的单词。尽管词嵌入是一种非常简单的表示方法,但从中可以获得很有趣的语义结构。例如,与“kitty”(小猫)这个词距离最近的是“cat”(猫),并且“kitty”这个词与“animal”(动物)之间的距离要远远小于它与“rocket”(火箭)这个词的距离。换句话说,“kitty”很少出现在有“rocket”的上下文里。
可以通过简单的旋转并对齐两种语言(X和Y)的二维词嵌入,然后通过最近邻搜索实现单词翻译。
此外,不同语言中意思相近的词汇具有相似的邻域结构,因为世界各地的人们生活在相同的物理环境中。例如,英语中“cat”和“furry”(毛茸茸)之间的关系,类似于它们在西班牙语中对应的翻译“gato”和“peludo”,因为这些单词的出现频率及其上下文是非常相似的。
鉴于这些相似之处,Facebook的研究人员提出了一种方法,让系统通过对抗训练等方法,学习将一种语言的词嵌入结构进行旋转,从而匹配另一种语言的词嵌入结构。有了这些信息以后,他们就可以推断出一个相当准确的双语词典,无需任何已经翻译好的语句,并且基本上可以做到逐字翻译。
通过旋转并对齐不同语言的词嵌入结构,得到词到词的翻译
用无监督反向翻译技术,训练句到句的机器翻译系统
当逐字翻译实现以后,接下来就是词组乃至句子的翻译了。
当然,逐字翻译的结果是无法直接用在句子翻译上的。于是,Facebook的研究人员又使用了一种方法,他们训练了一个单语种语言模型,对逐字翻译系统给出的结果打分,从而尽可能排除不符合语法规则或有语病的句子。
这个单语模型比较好获得,只要有小语种(比如乌尔都语)的大量单语数据集就可以。英语的单语模型则更好构建了。
通过使用单语模型对逐字翻译模型进行优化,就得到了一个比较原始的机器翻译系统。
虽然翻译结果不是很理想,但这个系统已经比逐字翻译的结果更好了,并且它可以将大量句子从源语言(比如乌尔都语)翻译成目标语言(比如英语)。
接下来,Facebook研究人员再将这些机器翻译所得到的句子(从乌尔都语到英语的翻译)作为ground truth,用于训练从英语到乌尔都语的机器翻译。这种技术最先由R. Sennrich等人在ACL 2015时提出,叫做“反向翻译”,当时使用的是半监督学习方法(有大量的语言对)。这还是反向翻译技术首次应用于完全无监督的系统。
不可否认,由于第一个系统(从乌尔都语到英语的原始机器翻译系统)的翻译错误,作为训练数据输入的英语句子质量并不高,因此第二个反向翻译系统输出的乌尔都语翻译效果可想而知。
不过,有了刚才训练好的那个乌尔都语单语模型,就可以用它来对第二个反向翻译系统输出的乌尔都语译文进行校正,从而不断优化、迭代,逐渐完善第二个反向翻译系统。
无监督机器翻译三原则:词到词的翻译、语言建模和反向翻译
在Facebook的这项工作中,他们确定了三个步骤——词到词的翻译(word-by-word initialization)、语言建模和反向翻译——作为无监督机器翻译的重要原则。有了这些原则后,就可以推导出各种模型。
红点代表源语言,红圈代表未观测到的目标语言翻译,红叉代表系统对目标语言的翻译;蓝点代表目标语言,蓝圈代表未观测到的源语言翻译,蓝叉代表系统对源语言的翻译。A) 构建两种语言的词嵌入模型;B) 通过旋转对齐词嵌入进行词到词的翻译;C) 通过单语种模型训练改善;D) 反向翻译。
Facebook研究人员用其构建了两种不同的模型,以解决无监督机器翻译的目标。
第一个是无监督神经模型,其结果比逐字翻译更流畅,但却没有产生研究人员想要的质量翻译。但是,这个无监督神经模型的翻译结果可以用作反向翻译的训练数据。使用这种方法得到的翻译结果,与使用100,000个语言对进行训练的监督模型效果相当。
接下来,Facebook的研究人员上述原则应用于基于经典计数统计方法的另一个机器翻译模型,叫做“基于短语的机器翻译”(phrase-based MT)。通常而言,这些模型在训练数据(也即翻译好的语言对)较少时表现更好,这也是首次将其应用于无监督的机器翻译。基于短语的机器翻译系统,能够得出正确的单词,但仍然不能形成流畅的句子。但是,这种方法取得的结果也优于以前最先进的无监督模型。
最后,他们将两种模型结合起来,得到一个既流畅又准确翻译的模型。其方法是,从一个训练好的神经模型开始,用基于短语的模型生成的反向翻译句子,对这个神经模型进行训练。
根据实证结果,研究人员发现最后一种组合方法显著提高了先前无监督机器翻译的准确性,在BLEU基准测试上,英法和英德两个语种的翻译提高了超过10分(英法和英德翻译也是使用无监督学习训练的,仅在测试时使用了翻译好的语言对进行评估)。
研究人员还测试了在语种上相隔较远的语种(英俄),训练资源较少的语种(英语—罗马尼亚语),以及语种相隔极远且训练资源极少的语种(英语—乌尔都语)的翻译。在所有情况下,新的方法比其他无监督方法都有很大的改进,有时甚至超过了使用监督学习方法进行训练的翻译系统得出的结果。
适用于任何领域的无监督学习,让智能体利用无标记数据执行罕见任务
Facebook的研究人员表示,在BLEU测试基准上提高超过10分是一个令人兴奋的开始,但对他们来说更令人兴奋的是这种方法为未来改进开启的可能性。
从短期来看,这肯定有助于我们翻译更多的语言并提高训练数据少的语言的翻译质量。但是,从这种新方法和基本原则中获得的知识,可以远远超出机器翻译的范畴。
Facebook的研究人员认为,这项研究有可能应用于任何领域的无监督学习,并可以让智能体利用没有标记的数据执行当前只有少量甚至没有专家演示的任务。这项工作表明,系统至少可以在没有监督的情况下学习,并建立一个耦合系统,其中每个组件都在一个良性循环中,随着时间的推移而不断改进。
现在,这个项目已经在Github开源,代码可以访问下面的链接获得:
https://github.com/facebookresearch/UnsupervisedMT
相关论文:https://arxiv.org/pdf/1804.07755.pdf
-
Facebook
+关注
关注
3文章
1432浏览量
58321 -
机器学习
+关注
关注
66文章
8541浏览量
136215 -
机器翻译
+关注
关注
0文章
141浏览量
15466
原文标题:Facebook全新无监督机器翻译法,BLUE测试提升超过10分!
文章出处:【微信号:AI_era,微信公众号:新智元】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
机器翻译三大核心技术原理 | AI知识科普
机器翻译三大核心技术原理 | AI知识科普 2
机器翻译不可不知的Seq2Seq模型
英汉机器翻译中基于模式的译文生成
机器翻译系统实现了自然语言处理的又一里程碑突破

从冷战到深度学习_机器翻译历史不简单

阿里巴巴机器翻译在跨境电商场景下的应用和实践
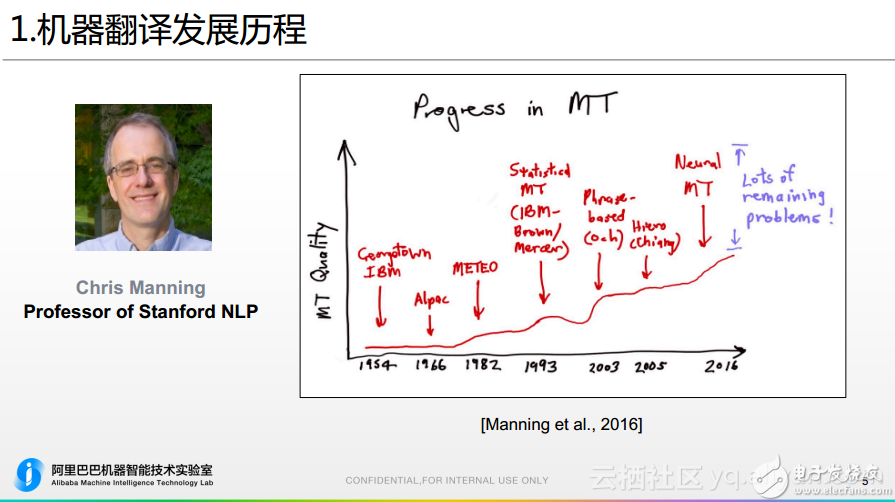
从冷战到深度学习,机器翻译历史不简单!
换个角度来聊机器翻译

人工智能翻译mRASP:可翻译32种语言
未来机器翻译会取代人工翻译吗
多语言翻译新范式的工作:机器翻译界的BERT





 工商网监
工商网监
评论