 摄像头相关的人工智能研究成果
摄像头相关的人工智能研究成果
本文来自驭势科技人工智能组组长潘争在LiveVideoStackCon 2017大会上的分享,并由LiveVideoStack整理而成。潘争回顾了AI在图像识别领域的历史与难点,以及在安防和自动驾驶方面的实现思路。
谷歌的人工智能平台Alpha Go让AI再次进入了普通老百姓的视野,我记得2016年3月时Alpha Go第一轮测试结果就令大家十分震惊。随着技术的进步,AI的能力一定会越来越强。我们可以看到近两年AI在深度学习方面的技术进展成果显著。今天我为大家准备了一些最近与摄像头相关的人工智能研究成果。
概览:
摄像头里的数据宝藏
视觉识别的挑战与应对
AI+安防实践
AI+自动驾驶实践

今天我的分享内容主要分为以下几点:第一是我们生活中的这些摄像头所采集的数据中隐藏了哪些值得挖掘的宝藏,以及如果要去挖掘有价值的数据需要面临的一些挑战与应对的方法;第二是我在安防与自动驾驶领域应用AI的一些实践经验。
1. 摄像头里的数据宝藏
大家可以设想一下自己周围有多少观察我们的摄像头,有我们随身携带的手机、平板电脑等移动设备的前后摄像头;如果你开车,你的车至少会有一两个摄像头;当你走在大街上或商场、超市里时,随便一抬头都能看到一个监控摄像头。可以说我们的生活布满了摄像头,其中记录了我们生活一点一滴的数据便具有了非凡价值。例如商场的管理人员可通过摄像头判断此时商场里有多少顾客,大致掌握顾客的男女比例,年龄层次,从而掌握潜在消费群体的实时动向;也可以通过摄像头搜寻经常前来消费的顾客,并在正确的位置精准投放相应广告吸引其消费从而增加销售额。而在安防领域,警察可通过安装在街道上的摄像头监控预防群体事件的发生,迅速识别定位逃犯并掌握其逃跑路径从而实现快速抓捕。还有在自动驾驶领域,通过汽车上集成的多部摄像头获取的数据可以告诉自动驾驶系统周围汽车的数量、相对速度与距离等,也可识别车道线位置,推断汽车是否偏离车道,并在需要变道或刹车时及时作出反应,保障自动驾驶系统的正常运行。从摄像头中发掘有价值的数据并加以有效利用,无论对安防领域还是自动驾驶领域而言都非常重要。当然数据挖掘与处理的过程也充满挑战。
2. 视觉识别问题中的挑战与应对
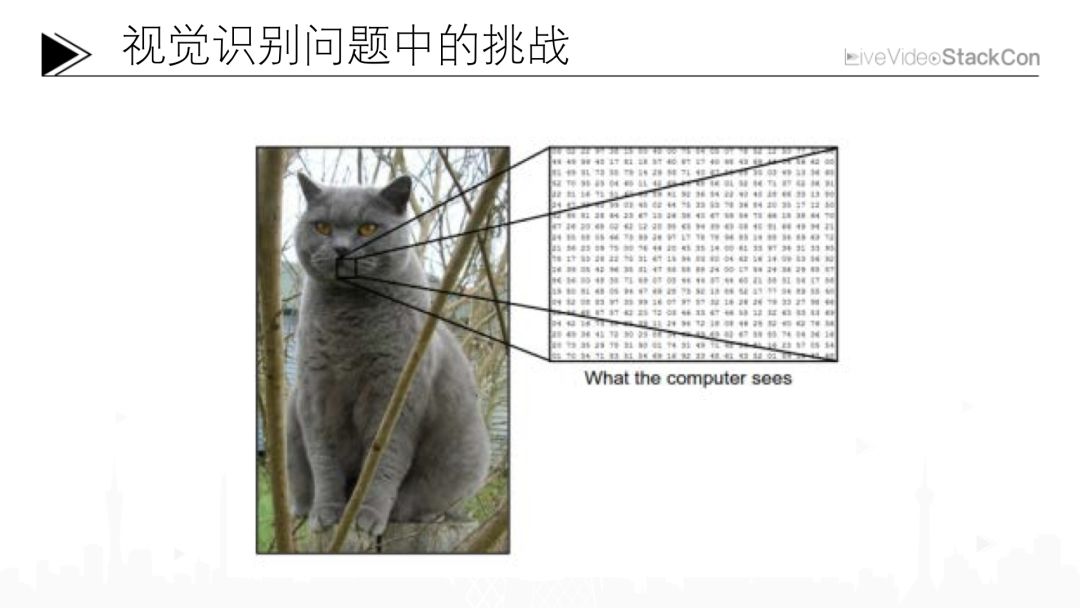
例如上面的这张图,也许一个三岁的小孩也能够识别出图片中的物体是一只猫,而对计算机来说,这张图可能只是一系列的数字。如果我们想通过这一系列的数字识别出这是一只猫则可能会遇到非常多的挑战。
挑战1:视角变化
而随着视角的变化,例如上图的同一张人脸会呈现出非常明显的差异
挑战2:光影变化
光影的变化同样至关重要,由于光源位置的不同,同样的几只企鹅,有可能是全黑的,也有可能是全白的,这对视觉识别也非常具有挑战性。
挑战3:尺度变化
姚明与小孩虽存在明显的尺度差异,但都属于人类。视觉识别系统必须能够对不同尺度的物体准确进行归类。
挑战4:形状变化
处于不同形态的同一物体同样是识别的难点,例如无论“大黄蜂”处于汽车形态还是机器人形态,视觉识别系统都应将其识别成“大黄蜂”。
挑战5:遮挡变化
更大的挑战在于很多视觉识别都需要面临的遮挡变化,我们必须保证在复杂环境的遮挡下仍能够准确识别图片中的一匹马与骑马的人。
挑战6:背景干扰
还需要解决的是背景干扰问题,我们可以轻易识别出上图中的人与金钱豹,但对计算机而言,因为目标主体的纹理与背景几乎难以分别,能够准确识别出同样结果的难度非常大。
挑战7:类内差距
最后一项挑战是类内差距,虽然都是椅子,但设计与用处的不同使其外观差距非常大,而我们希望视觉识别算法都能将其识别为一张椅子。
如何有效解决视觉识别领域上述这么多挑战?
2.1 深度学习——卷积神经网络

如果让大家完成这样一个Python函数,输入一张图片的数据,输出我们期望得到的图片类型,该如何完成?其实这个问题已经困扰了计算机视觉科学家大概半个多世纪的时间,从计算机被发明开始大家就在思考这个问题,直到最近几年才有了一个比较正式的回答,就是我们经常提到的深度学习,具体来说是一个多层卷积神经网络。上图展示了这样一个卷积神经网络的例子,在卷积神经网络的左边输入的是一张图像的数据,右边输出的是我们期待的图像所属类别。在这个网络中我们可以看到每一个蓝色的方框都代表一次卷积操作,之所以叫它多层卷积神经网络就是因为一张图片从输入原始数据到输出对应类别需要经过多次卷积操作,像这个网络需要经过22层卷积才能准确识别出图像所属的类别属性。每个卷积都会有一个卷积核,这个卷积核就是我们希望从海量数据中学习到的参数,学习不同的任务可以得出不同的参数。而这个学习训练的算法一般是根据具体任务通过使用反向传播算法进行精准识别并去学习出每一个卷积核的对应参数来。那么这样一个卷积神经网络可以达到怎样的图像识别性能呢?

这个问题也是在近几年才有了一个比较好的回答,我给大家举个例子: ImageNet比赛是一项解决通用图像识别分类问题的比赛,通过统计计算机识别并归类数据集中一千类图片的错误率来衡量其视觉识别能力的高低。人如果参加ImageNet,错误率会保持在5.1%左右。而在深度学习面世之前的2011年,ImageNet冠军的错误率可达到25.8%,但在2012深度学习面世以后,ImageNet冠军的错误率一下降到了16.4%,并且从那之后一直处于直线下降的状态,直到2015年的正确率已经下降到比人还低的3.57%。在人工智能的围棋还未超越人类的2015年,计算机在通用图像识别领域的性能已经超越了人类,能达到这样的成绩,卷积神经网络功不可没。
2.2 进一步发展的卷积神经网络
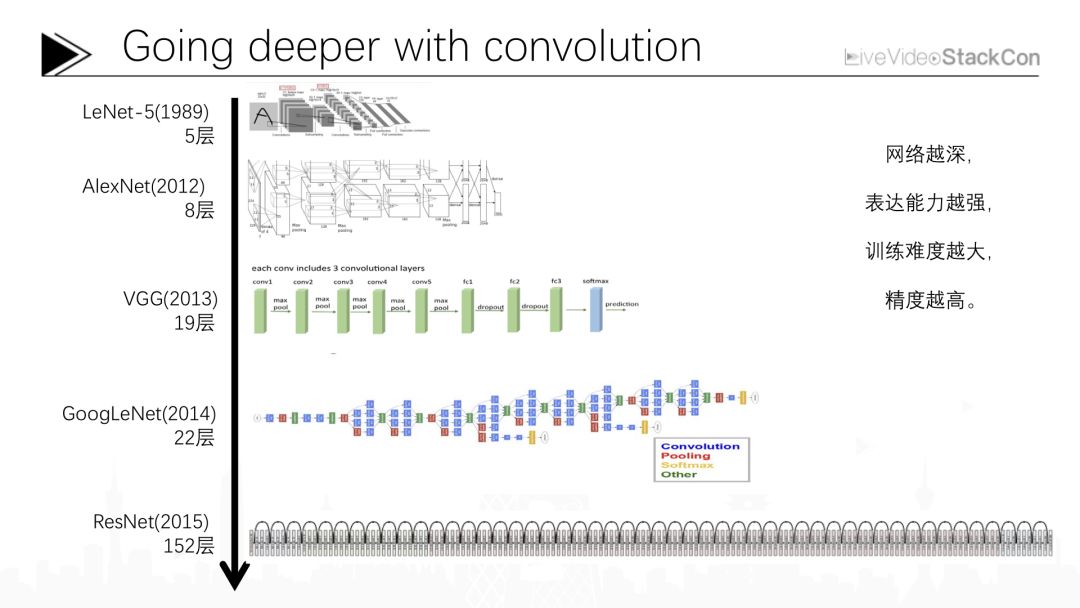
上图是近几年我们常用的深度卷积神经网络的大概结构,深度卷积神经网络最早是由Yann LeCun在1989年提出,当时是一个仅有5层的卷积神经网络,现在Yann LeCun在Facebook的人工智能研究院作为主任继续推进卷积神经网络的研究。最初卷积神经网络的层数非常的浅,仅有5层,并且那时只能完成一些手写体方面的简单识别任务。在那之后人们对卷积神经网络的研究持续了二十多年,一直到2012年,人们才提出能够胜任像ImageNet这样复杂识别任务的更先进的卷积神经网络。AlexNet在2012年借助这样一个8层的卷积神经网络网络成为当年ImageNet比赛的冠军,从那之后,又有很多不同的卷积神经网络被研发出来,总的趋势是越来越深。例如2013年达到19层的VGG、2014年Google提出的达到22层的GoogLeNet,而2015年微软亚洲研究院研制的多达152层的卷积神经网络ResNet其图像识别性能已超越人类。从卷积神经网络的发展我们不难看出,网络越深其表达能力越强,卷积神经网络所能表达的数学函数复杂程度就会越高,这就使其在处理复杂图象识别任务时能够达到更高的正确率。当然随着网络加深增多的是卷积盒的参数,对应计算量与深度学习的训练难度也会增大,接下来我将讲述近几年大家在研究深度学习时面临的三项核心问题以及提出的一些能够解决相应问题的算法思想。
2.3 视觉问题的深度学习方法

之前提到的ImageNet比赛是一个通用的模拟图像识别与分类的比赛,并不解决实际问题。与围棋类似,并不能为我们创造任何经济价值。如果想应用于实际中的视觉识别情景则还需解决以下几大类问题:语义分割、物体检测、对比验证。
2.3.1 语义分割
图像分类问题需要识别一张图片并告诉我们这张图片中物体的类别,简而言之就是输入一张图片,给出一个类别。语义分割就是希望针对一张图片中的每个像素都输出一个类别,其中有很多解决方案,例如这几年提出的FCN、Enet、PSPNet或ICnet等等。这些方法背后的基本框架都是全卷积网络。这里的全卷积网络与刚才提到的分类网络唯一不同之处在于全卷积网络并不只输出一个分类标签,而是输出多个分类结果,每个分类结果都对应了图像中的一个像素的类型值。训练时会对每个像素分类的结果进行误差计算,并用反向传播算法得出训练后的网络参数。
2.3.2 物体检测
初期的物体检测准确率很低,无法满足应用需求。近几年随着Faster RCNN、RFCN、SSD等方法的出现,物体检测的准确率已经基本达到实际应用的需求。以上这些基于深度学习的物体检测方法同样使用全卷积网络来预测出物体的每一个位置,在推断出此区域是否属于某个物体的同时对物体的类别、位置与大小进行预测。与之前的预测相比,物体检测增加了位置与大小两个预测维度。如果对这样的预测的结果还不满意的话也可像Faster RCNN这样将相应区域的图片或特性分离出并再过一次网络进行第二次的分类与回归,这种对目标的多重计算有助于提升输出结果的准确性。目前最好的物体检测方法就是类似于Faster RCNN这样分两阶段的方法,如果大家想尝试这种物体检测方面的应用也可从此方法开始。
2.3.3 对比验证
对比验证简单来说就是对两个图像进行对比并推断这两个图像是否为同一个类别,最简单的应用就是人脸识别。例如借助计算机将手机拍摄的一张人像照片与一张身份证上的照片进行对比并推断是否为同一个人。这项技术在淘宝、支付宝等平台都有应用,也可用与跟踪和ReID等方面。这里的跟踪是指用一个摄像头拍摄连续多帧照片后,识别并锁定第一帧里的某个物体,然后跟踪后续帧中这个物体的移动轨迹。
如果这些用于跟踪物体的图片来自不同的摄像头,那么这就变成了一个ReID问题。ReID在安防领域是一个非常重要的应用,例如一个小偷在A摄像头下作案时被拍摄图像后,我希望根据这张图像在其他摄像头中搜寻并锁定这个小偷,以此来推测其作案移动的路径,毫无疑问这会为警方的刑侦破案提供很大帮助。无论是人脸识别还是RelD,其技术背景都是Siamese network。
它的原理很简单,就是将两张图片经过同一个网络提取特征。在训练此网络时我们希望尽量缩小同一张人脸照片输出结果的差距,扩大不同人脸照片输出结果的差距。通过这种训练方式能够让网络学习到如何分析比对同一张人脸具有什么相似的特征,不同的人脸具有什么不同的特征。在人脸识别方面,计算机更早地超过人类。大概2013年在LFW人脸验证比赛上,人类对于脸部的识别验证准确率在97%左右,而计算机已可达到99%以上,这无疑是深度学习在人脸验证领域的突破。
之前我与大家分享的都是一些笼统的方法,接下来我会结合过去我在安防与自动驾驶领域的工作经验为大家介绍一些研究成果,
3. AI+安防
首先说一下安防,在安防领域有以下几类大家比较关心的问题。第一个问题是通过摄像头确认目标的位置也就是“人在哪里?”。知道人在哪里之后就需要明确目标属性“你是谁?”、“你从哪里来?”、“你要到哪里去?”这些看似充满哲学意味的问题同样也是安防领域最重要的三个问题。回答这三个问题之后我们还希望确认目标的行为特征“人做了什么?”这对安防领域而言同样重要。接下来让我们看一下,如何解决这几个问题。
3.1 “人在哪里?”
首先我们需要确认“人在哪里?”。安防领域中最基础的便是对物体的检测,例如上图展示了一个在安防场景里进行人物检测的实例。我们使用类似Faster RCNN技术对这样一个安防场景中人的上半身进行检测,检测上半身主要是因为人最重要的特征集中在上半身,而下半身经常会被其他物体遮挡,同理上半身的特征暴露几率更高,更容易进行特征识别。因为传统Faster RCNN方法在识别速度上处于劣势,所以我们对Faster RCNN进行了一些简化,使其在识别速度上有了比较大的提升,并且能够允许我们仅借助移动端GPU就可实现实时检测的效果。
为了验证此算法的运行极限,我们进行了一个规模更大的实验。此实验场景为北京站前广场,这里人流密集,比一般的监控场景更复杂,我们想通过此实验测试我们算法可同时检测人数的极限。经过测试我们发现即便在如此大的场景之下算法依旧能够较稳定地检测出场景中中绝大多数行人,漏检与误检几率也维持在较低水平。我们在确认目标位置之后需要进一步确认目标的移动轨迹与行为动机。
3.2 “人从哪里来,到哪里去?”
上图是一个较典型的物体跟踪实验情景,我们让这些群众演员随机游走,通过深度学习方法对每个人的运动轨迹进行跟踪。从左上角的图中我们可以看到每个人身上都会有一个圈,如果圈的颜色没有变化说明对这个人保持正常的跟踪状态。可以看到利用这种检测跟踪技术可稳定地跟踪大部分目标。借助摄像头输出的深度图,我们还可以如右下角图片展示的那样得出每个人在三维空间中的位置并变换视角进行监控,或是如在左下角图片展示的那样得到一个俯视的运行轨迹,这样就可得知每个人在监控画面当中的位置动态变化轨迹。
3.3 “这些人是谁?”
跟踪上每一个人之后,更重要的是确认跟踪目标的身份。安防领域的终极目标就是希望明确监控画面中每个人的身份信息,而能从一个人的图像中获取到的最明显的身份特征信息就是人脸。我开发了这样一项技术——远距离人脸识别。在上图展示的大场景中我们可以看到其中大部分人离摄像头的距离至少有30米~40米,在这样一个远距离监控场景下人脸采到的图像质量会出现明显的损失,例如人脸的位姿变化。我们希望借助在这样一个不佳的监控场景中获取的人脸图片与人脸特征库中的证件信息进行比对并获取目标人物的身份信息,其原理也是刚才提到的Siamese Network——通过使用几千万甚至上亿数据进行训练,得出一个较为稳定的人脸特征并在人脸库中检索出符合此特征的目标人物身份信息,从而识别目标身份。
3.4 “这些人在干什么?”
安防领域最后关心的是目标的行为特征“这个人在干什么?”其本质是明确每个人的各个关节的运动状态,我们称之为POSE识别。虽然POSE识别看上去并不属于检测、跟踪或是语义分割的范畴,但我们也可将其归结为一种物体检测,只不过我们检测的不再是人的运动轨迹,而是检测每个人的脖子、肩膀、肘关节等部分的相对位置,这与之前的物体检测相比更为复杂。近几年,借助深度学习技术,POSE识别取得了非常明显的进步。微软Xbox 360上配备的kinect便是通过可感知深度的摄像头对一两个人进行POSE识别而现在随着技术的发展,即便仅通过普通的RGB摄像头也能实现对整个广场上多个目标同时进行POSE识别,这也是近几年深度学习的一个重要突破。通过这种实时POSE识别我们不光可识别每个人在广场中的位置、运动轨迹,还可识别每个人的动作以及动作背后隐藏的人与人之间的关系,从而在监控画面中获取更多有价值的信息。
4. AI+自动驾驶

之前我们讲述了AI在安防监控领域的一些应用,接下来我会介绍一些最近正在尝试的有关自动驾驶方面的实践。其实在自动驾驶领域也需要很多摄像头数据,我们会在自动驾驶汽车中安装多个摄像头。传统汽车领域车身上的一两个摄像头主要用来拍摄汽车周围的环境图像,而在自动驾驶领域则需要更多的摄像头完成更复杂的工作。例如特斯拉已经在其还无法完全实现自动驾驶的汽车上安装了7个摄像头;如果想要实现真正的自动驾驶,为了保证画面的无死角需要安装更多摄像头,那么摄像头采集的数据能够帮助我们做什么呢?很多信息需要通过摄像头获取,例如车道线、前后左右有无行人与车辆等障碍物、红绿灯识别、可行驶区域识别等都是来源于通过摄像捕获的数据。
4.1 车道线识别
图片中展示的车道线识别,也许大家曾在一些行车记录仪或ADOS中见过。但有别于传统对单车道线的简单标记,我们现在更关注的是多车道线识别。以前的车道线识别仅是左右各一根,而我们希望能够识别一整条马路上的多根车道线。这种对于多根车道线的识别,一方面可为处于自动驾驶状态下的车辆提供变道、驶出高速等路径更改操作必要的数据,另一方面能够协助汽车进行横向定位。如果能够同时识别出所有车道,自动驾驶系统就能确认汽车当前在第几条车道上,从而计算下一步需要切换到哪一条车道,这对自动驾驶而言十分重要。检测车道线可归结为对物体的检测,大家可以将每条车道线理解为一个物体。当然在面临弯曲的车道线时还需要估计每条车道曲线的参数,需要更多的处理分析以更好地模拟车道线的变化。
4.2 行人与车辆检测
除了车道线识别,另外一个比较重要的问题是对行人与车辆的实时检测。这是安全性上十分重要的两项指标,需要知晓周围车辆的位置、距离和速度才能获取决策所需要的参数。上图是我们在北京四环这样相对简单的封闭道路环境下进行的车辆检测实验。检测车辆的算法与我们之前提到的在安防领域里检测人的算法类似,都是基于Faster RCNN架构,但自动驾驶领域对计算能力的要求更高。因为汽车的安全永远摆在第一位,并且经过每一步计算更新出的行驶策略必须符合道路交通安全法规,而我们日常生活中使用的GPU远无法达到如此严格的性能要求。因此我们需要花很多的时间将神经网络尽可能精简与压缩以实现更快的运行速度,从而能够在有限的硬件性能下满足对行人与车辆的实时监测要求。
我们还在更复杂的道路环境下测试了检测算法。上图是一个人车混行的道路环境,难点一主要在于大量汽车造成的遮挡问题,难点二主要在于身着各色服饰的群众,这种道路环境无论是对人还是对车辆的检测而言都是一个非常大的挑战。当然在如此复杂的环境下我们现有的算法仍会出现一些错误,这还需要我们积累更多的数据与改进方案以实现进一步的提升,让我们的自动驾驶系统能够通过视觉层面上的识别保证在如此复杂人车混行道路环境下驾驶过程的安全性。
4.3 红绿灯识别
视觉识别还可帮助我们识别红绿灯的状态,同样是一个比较标准的物体检测问题。但红绿灯检测与之前提到的行人与车辆检测相比,困难之处在于红绿灯在图像中是一个非常小的物体,越小的物体检测难度越大。为了解决此问题我们提高了标准检测方法输出的图像分辨率,提升最后一层深度学习网络对细小的物体的检测敏感度。
这样便可帮助我们对红绿灯等小物体实现更准确的检测。上图是我们在五道口附近一个道路环境比较复杂的路段测试红绿灯检测算法的准确性,可以看到虽然这段路上有很多红绿灯,但基本上大部分的红绿灯都可以被准确检测到。当然红绿灯不一定需要通过视觉识别进行检测,有时我们可以结合一些地图信息进一步提高红绿灯检测结果的准确性,尽可能降低依赖纯视觉图像信息进行红绿灯检测时出现错误的概率。
4.4 可行驶区域识别
对自动驾驶系统而言最后一个关键问题是明确汽车的可行驶区域。所谓可行使区域就是理论上路面没有障碍物,允许汽车安全通过的区域,那么确定汽车可行驶区域的关键点就是确定路面上的障碍物,那么如何识别道路上的障碍物呢?障碍物的种类有很多,故我们通过另一种思路来解决这个问题,也就是对可行使区域进行分割,这就使命题变为一个比较标准的图像语义分割问题。上图是我们在北京五环路上进行的测试,可以看到道路中的紫色部分为可行驶区域。
在这种封闭环路上测试此技术的效果往往是比较稳定的,但距离将其推广并应用于类似人车混行等复杂道路环境还很远,需要积累更多数据才能进一步提高精度满足道路安全驾驶的需求。同时除了识别可行使区域,大家可以看到图像中的高亮部分展示的是车道线、交通标识等必要的目标识别。这些识别在为自动驾驶安全稳定运行提供必要的驾驶辅助信息的同时也为深度学习在准确预测可行使区域和监测车辆行人等方面提供了必要的参考数据。
这便意味着这样一个多任务网络需要利用有限的计算资源更加迅速地完成多个驾驶行为监测任务,从而在出现行驶突发状况时更快作出反应与干预,保证人车安全。而在深度学习领域,同时训练两个任务相对于单独训练一个任务所达成的效果更好。
-
摄像头
+关注
关注
59文章
4614浏览量
92946 -
人工智能
+关注
关注
1777文章
43920浏览量
230781 -
自动驾驶
+关注
关注
773文章
13068浏览量
163304
原文标题:隐藏在摄像头里的AI
文章出处:【微信号:livevideostack,微信公众号:LiveVideoStack】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐





 工商网监
工商网监
评论