 Summit系统创造性能新记录,突破了每秒100千万亿的次浮点运算!
Summit系统创造性能新记录,突破了每秒100千万亿的次浮点运算!

近日,橡树岭国家实验室的Summit系统呈献了又一场超级计算盛宴,创造了又一项性能记录,该系统首次突破了每秒100千万亿次浮点运算性能的壁垒。
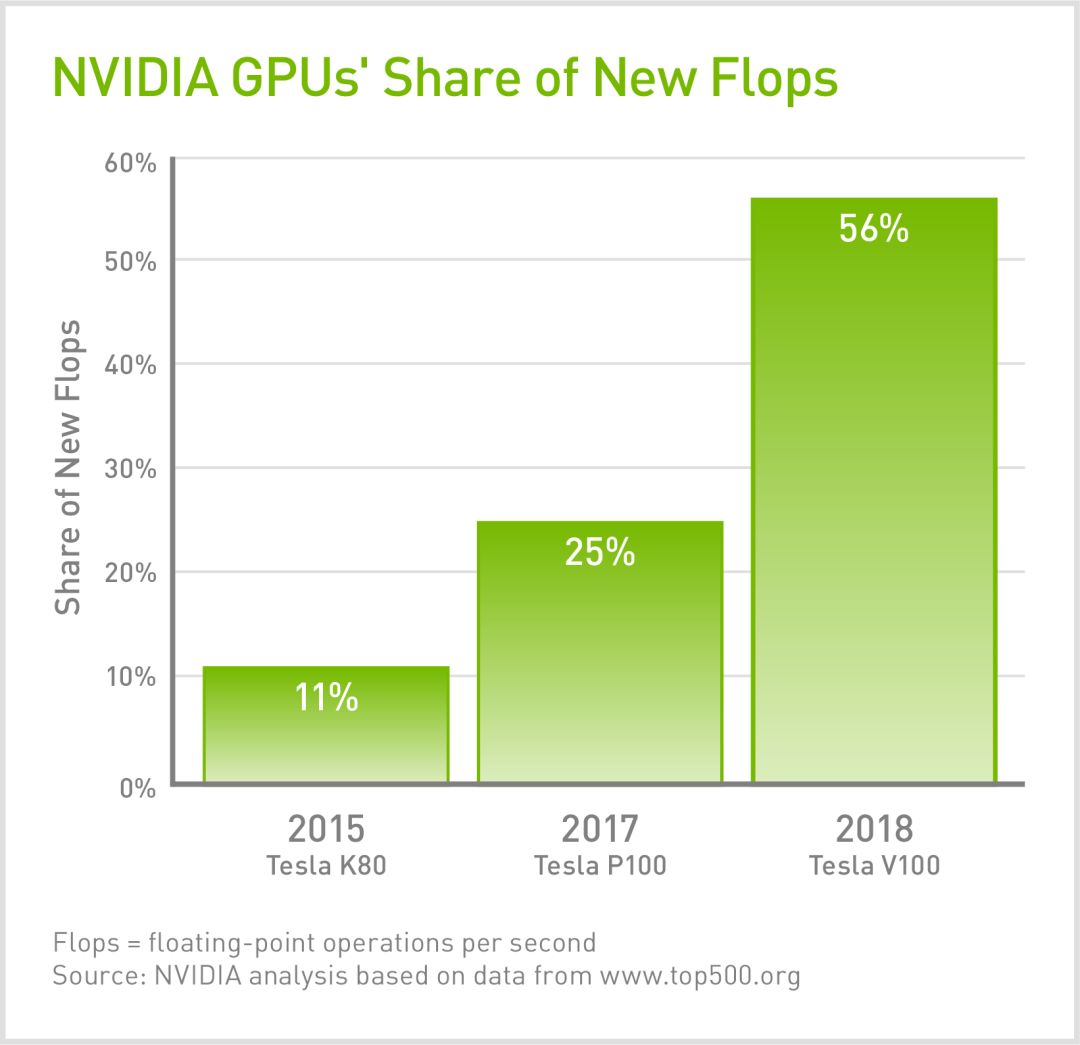
在最新发布的Top500榜单中,大部分系统的新处理能力均来自GPU。目前世界七大超级计算机中有五款都在采用GPU,包括美国、欧洲和日本的顶尖系统。
而对于Summit,GPU满足了其95%的浮点运算性能要求。随着摩尔定律的不断放缓,加速计算显然已经成为助推器,将很快推动我们进入百亿亿次级计算时代。
这样的计算性能由NVIDIA Volta Tensor Core GPU提供,其多精度计算能力将能同时应对高性能计算所需的高精度计算挑战,以及深度学习所需的高效处理的要求。
加速计算登峰造极
每年两次的超级计算展见证了加速计算近年来的飞速发展。在ISC 2018上,这一领域再次实现了突破。
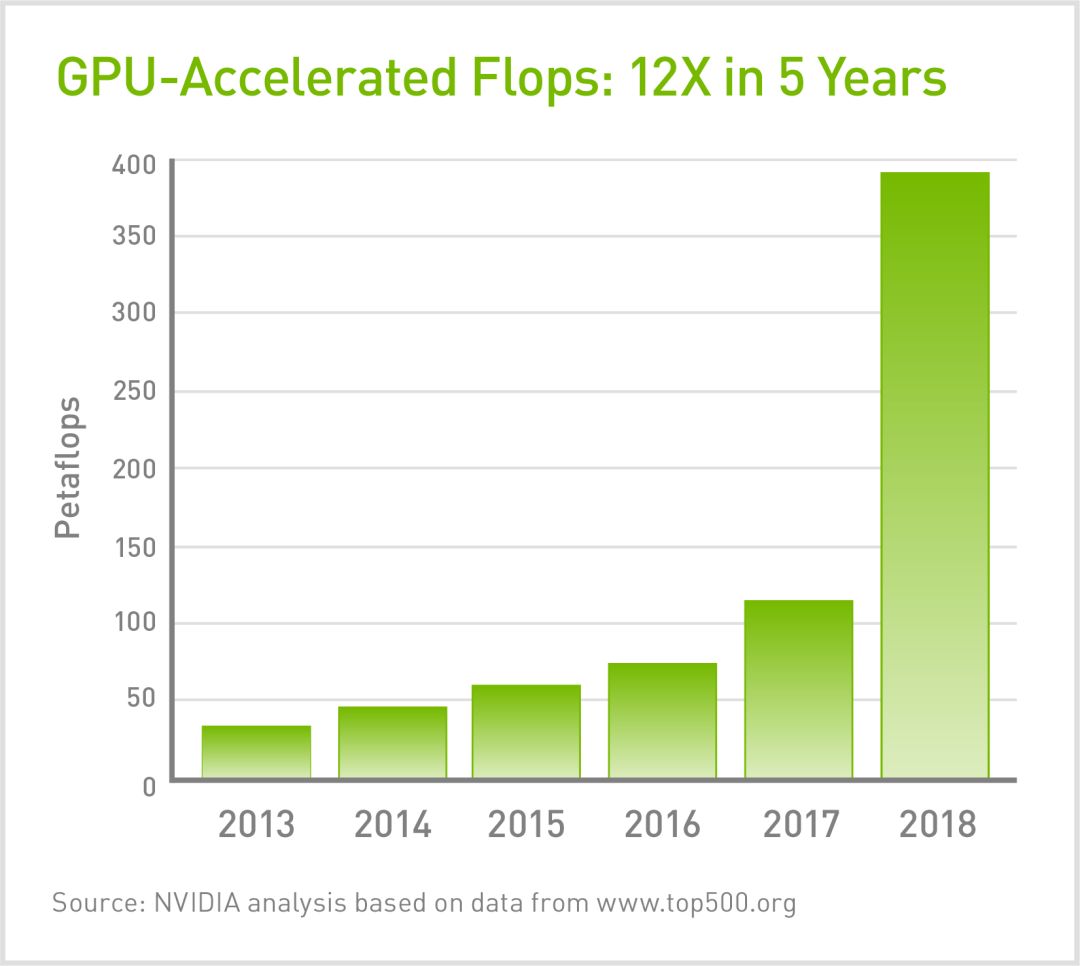
Summit显然是最有力的证据。该系统采用27648块Volta Tensor Core GPU,其测得的双精度性能达到每秒122千万亿次浮点运算。它每秒的性能相当于地球上所有人以每秒执行一次计算的速度执行一整年的任务。
其AI性能更加令人瞩目,运算速度可达到300亿亿次。这相当于整个地球上的人在15年内每秒进行一次计算。
至省与至简
多精度计算开辟了新的可能性。但是,如果GPU无法提供非凡的效率,相应的效用将受限。
在最新的Green500榜单,GPU为全球20个最具环保效益的系统中的17个提供支持。Summit不仅是世界上速度最快的系统,而且在新确立的“三级”类别(Green500 榜单中最严格的级别)中是世界上最高效的系统。
在过去10年中,GPU已经帮助美国橡树岭国家实验室将其超级计算机的能源效率提高了50倍,这些计算机包括仅支持CPU的Jaguar及由GPU加速的Titan和Summit。
而所有这些仅仅是一个开始。实现百亿亿次级计算需要在能源效率方面实现更大突破。以Green500榜单中系统的平均效率计算,为百亿亿次级计算提供动力将需要超过3亿瓦的电能,这相当于25万个美国家庭的电力需求。需要将能效提高10倍才能使百亿亿次级计算在3千万瓦条件下运行。
GPU正在帮助Summit实现这一目标。
破解难题
最新顶尖系统具备的处理能力曾经令人无法想象,但现在的研究人员将能够借助这些系统解决一些科学上最棘手的难题。
比如,遗传学。帕金森症和阿尔茨海默症等可以称得上是“毁灭性”疾病,而GPU的计算能力将可以破解这样的难题,找出人类基因组的数十亿个AGCT DNA对与诸如此类疾病之间的联系。Summit已在梳理个人基因,以实现在阿片成瘾(美国人的主要致死原因之一)研究方面的进展。
又如,材料。超导材料可用于为MRI设备、粒子加速器或磁聚变装置开发功能强大的科学磁体。然而,目前的材料十分易碎、难以制造,并且只能在非常低的温度下工作。Summit正在帮助模拟和发现具有类金属特性且可在室温下工作的新型超导材料。
再如,癌症研究。对抗癌症的关键在于开发可以自动提取、分析和分类健康数据的工具,以便揭示各种疾病因素(例如基因、生物学标记和环境)之间隐藏的关系。通过与基于文本的报告和医学影像等非结构化数据配合使用,在Summit上扩展的深度学习算法将有助于医学研究人员全面了解美国癌症患者的整体情况。
继续前进
每个国家/地区都在竞相构建百亿亿次级计算系统。2025年的Top500榜单可能会看到十多款这样的系统,而且多精度加速计算成为平台首选。相比之下,本次Top500榜单上的所有系统加在一起才勉强实现一百亿亿次级的总计算能力。这足以说明未来蕴藏着巨大机遇。
加速计算的一大吸引力在于它属于全栈创新:从架构一直到系统、加速堆栈、开发人员和半导体工艺,无一不体现着创新精神。
NVIDIA已经投入了超过10年的时间来加速整个HPC堆栈的开发。
当我们发布第一款支持CUDA的GPU时,它无法运行任何应用程序。我们需要为全新的加速环境重新设计所有的应用程序、算法、库、工具、编译器、操作系统和系统设计。打造一种能够处理数学处理器的芯片很容易,而要使全球高性能计算开发人员可以使用和编程这些处理器,则需要在整个堆栈上实现非凡的创新。
结果,550多款高性能计算和AI应用程序都由GPU加速,其中包括排名靠前的15种应用程序和所有AI框架。致力于此领域的开发人员数量在过去的五年里增加了10倍,现已接近一百万。而且,利用我们NGC容器注册上的最新高性能计算容器,高性能计算用户现在可以在他们的系统或Tensor Core GPU驱动的云上轻松点击、下载并运行最新的GPU加速应用程序。
转折与展望
在我们快速发展加速计算的同时,一些人也正在寻找量子计算的下一个转折点,量子计算使用量子位元(“qubits”)而不是1和0来处理信息。
这些理论十分具有吸引力。在未来的某个时候,可能会出现一些在量子计算机上运行的杀手级应用程序(特别是在密码学或量子化学领域),只需极小的功率即可利用超强的处理能力。
但在可预见的未来,加速计算的势头似乎不可阻挡。NVIDIA会继续致力于在高性能计算领域的创新,将实现百亿亿次级计算以及其为科学领域带来的突破。
-
NVIDIA
+关注
关注
14文章
5496浏览量
109050 -
gpu
+关注
关注
28文章
5099浏览量
134420
原文标题:加速计算成为助推器,带我们进入百亿亿次级计算时代
文章出处:【微信号:NVIDIA-Enterprise,微信公众号:NVIDIA英伟达企业解决方案】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
蜂鸟内核模块浮点指令运算数据的获取
FPNew开源浮点运算单元工程建立
(九)浮点乘法指令设计
如何获取蜂鸟内核执行模块浮点指令的运算数据
使用Simulink自动生成浮点运算HDL代码(Part 1)
risc-v中浮点运算单元的使用及其设计考虑
【中科昊芯Core_DSC280025C开发板试用体验】+1.开箱之浮点计算对比
NVIDIA驱动的现代超级计算机如何突破速度极限并推动科学发展
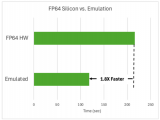
为什么GPU性能效率比峰值性能更关键

驱动 AI 边缘计算新时代!高性能 i.MX 95 应用平台引领未来






 工商网监
工商网监
评论