 强化学习的经典基础性缺陷可能限制它解决很多复杂问题
强化学习的经典基础性缺陷可能限制它解决很多复杂问题
在上一篇文章里,我们提到了棋盘游戏的比喻和纯强化学习技术的缺陷(斯坦福学者冷思考:强化学习存在基础性缺陷)。在这一部分中,我们会列举一些添加先验知识的方法,同时会对深度学习进行介绍,并且展示对最近的成果进行调查。
那么,为什么不跳出纯强化学习的圈子呢?
你可能会想:
我们不能越过纯强化学习来模仿人类的学习——纯强化学习是严格制定的方法,我们用来训练AI智能体的算法是基于此的。尽管从零开始学习不如多提供些信息,但是我们没有那样做。
的确,加入先验知识或任务指导会比严格意义上的纯强化学习更复杂,但是事实上,我们有一种方法既能保证从零开始学习,又能更接近人类学习的方法。
首先,我们先明确地解释,人类学习和纯强化学习有什么区别。当开始学习一种新技能,我们主要做两件事:猜想大概的操作方法是什么,或者度说明书。一开始,我们就了解了这一技能要达到的目标和大致使用方法,并且从未从低端的奖励信号开始反向生成这些东西。
UC Berkeley的研究者最近发现,人类的学习速度比纯强化学习在某些时候更快,因为人类用了先验知识
使用先验知识和说明书
这种想法在AI研究中有类似的成果:
解决“学习如何学习”的元学习方法:让强化学习智能体更快速地学会一种新技术已经有类似的技巧了,而学习如何学习正是我们需要利用先验知识超越纯强化学习的方法。
MAML是先进的元学习算法。智能体可以在元学习少次迭代后学会向前和向后跑动
迁移学习:顾名思义,就是将在一种问题上学到的方法应用到另一种潜在问题上。关于迁移学习,DeepMind的CEO是这样说的。
我认为(迁移学习)是强人工智能的关键,而人类可以熟练地使用这种技能。例如,我现在已经玩过很多棋盘类游戏了,如果有人再教我另一种棋类游戏,我可能不会那么陌生,我会把在其他游戏上学到的启发性方法用到这一游戏上,但是现在机器还做不到……所以我想这是强人工智能所面临的重大挑战。
零次学习(Zero-shot learning):它的目的也是掌握新技能,但是却不用新技能进行任何尝试,智能体只需从新任务接收“指令”,即使没有执行过新的任务也能一次性表现的很好。
一次学习(one-shot learning)和少次学习(few-shot learning):这两类是研究的热门区域,他们和零次学习不同,因为它们会用到即将学习的技巧做示范,或者只需要少量迭代。
终身学习(life long learning)和自监督学习(self supervised learning):也就是长时间不在人类的指导下学习。
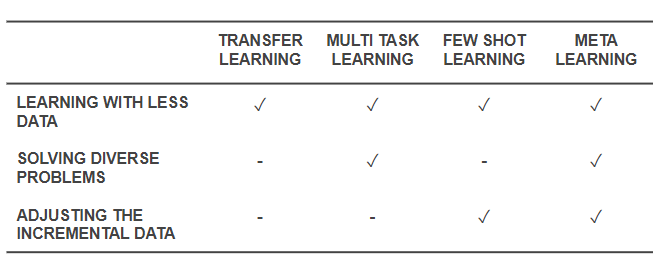
这些都是除了从零学习之外的强化学习方法。特别是元学习和零次学习体现了人在学习一种新技能时更有可能的做法,与纯强化学习有差别。一个元学习智能体会利用先验知识快速学习棋类游戏,尽管它不明白游戏规则。另一方面,一个零次学习智能体会询问游戏规则,但是不会做任何学习上的尝试。一次学习和少次学习方法相似,但是只知道如何运用技能,也就是说智能体会观察其他人如何玩游戏,但不会要求解释游戏规则。
最近一种混合了一次学习和元学习的方法。来自One-Shot Imitation from Observing Humans via Domain-Adaptive Meta-Learning
元学习和零次学习(或少次学习)的一般概念正是棋类游戏中合理的部分,然而更好的是,将零次学习(或少次学习)和元学习结合起来就更接近人类学习的方法了。它们利用先验经验、说明指导和试错形成最初对技能的假设。之后,智能体亲自尝试了这一技巧并且依靠奖励信号进行测试和微调,从而做出比最初假设更优秀的技能。
这也解释了为什么纯强化学习方法目前仍是主流,针对元学习和零次学习的研究不太受关注。有一部分原因可能是因为强化学习的基础概念并未经受过多质疑,元学习和零次学习的概念也并没有大规模应用到基础原理的实现中。在所有运用了强化学习的代替方法的研究中,也许最符合我们希望的就是DeepMind于2015年提出的Universal Value Function Approximators,其中Richard Sutton提出了“通用价值函数(general value function)”。这篇论文的摘要是这样写的:
价值函数是强化学习系统中的核心要素。主要思想就是建立一个单一函数近似器V(s;θ),通过参数θ来估计任意状态s的长期奖励。在这篇论文中,我们提出了通用价值函数近似器(UVFAs)V(s, g;θ),不仅能生成状态s的奖励值,还能生成目标g的奖励值。
将UVFA应用到实际中
这种严格的数学方法将目标看作是基础的、必须的输入。智能体被告知应该做什么,就像在零次学习和人类学习中一样。
现在距论文发表已经三年,但只有极少数人对论文的结果表示欣喜(作者统计了下只有72人)。据谷歌学术的数据,DeepMind同年发表的Human-level control through deep RL一文已经有了2906次引用;2016年发表的Mastering the game of Go with deep neural networks and tree search已经获得了2882次引用。
所以,的确有研究者朝着结合元学习和零次学习的方向努力,但是根据引用次数,这一方向仍然不清楚。关键问题是:为什么人们不把这种结合的方法看作是默认方法呢?
答案很明显,因为太难了。AI研究倾向于解决独立的、定义明确的问题,以更好地做出进步,所以除了纯强化学习以及从零学习之外,很少有研究能做到,因为它们难以定义。但是,这一答案似乎还不够令人满意:深度学习让研究人员创造了混合方法,例如包含NLP和CV两种任务的模型,或者原始AlphaGo加入了深度学习等等。事实上,DeepMind最近的论文Relational inductive biases, deep learning, and graph networks也提到了这一点:
我们认为,通向强人工智能的关键方法就是将结合生成作为第一要义,我们支持运用多种方法达到目标。生物学也并不是单纯的自然和后期培养相对立,它是将二者结合,创造了更有效的结果。我们也认为,架构和灵活性之间并非对立的,而是互补的。通过最近的一些基于结构的方法和深度学习混合的案例,我们看到了结合技术的巨大前景。
最近元学习(或零次学习)的成果
现在我们可以得出结论:
受上篇棋盘游戏比喻的激励,以及DeepMind通用价值函数的提出,我们应该重新考虑强化学习的基础,或者至少更加关注这一领域。
虽然现有成果并未流行,但我们仍能发现一些令人激动的成果:
Hindsight Experience Replay
Zero-shot Task Generalization with Multi-Task Deep Reinforcement Learning
Representation Learning for Grounded Spatial Reasoning
Deep Transfer in Reinforcement Learning by Language Grounding
Cross-Domain Perceptual Reward Functions
Learning Goal-Directed Behaviour
上述论文都是结合了各种方法、或者以目标为导向的方法。而更令人激动的是最近有一些作品研究了本能激励和好奇心驱使的学习方法:
Kickstarting Deep Reinforcement Learning
Surprise-Based Intrinsic Motivation for Deep Reinforcement Learning
Meta-Reinforcement Learning of Structured Exploration Strategies
Learning Robust Rewards with Adversarial Inverse Reinforcement Learning
Curiosity-driven Exploration by Self-supervised Prediction
Learning by Playing - Solving Sparse Reward Tasks from Scratch
Learning to Play with Intrinsically-Motivated Self-Aware Agents
Unsupervised Predictive Memory in a Goal-Directed Agent
World Models
接着,我们还可以从人类的学习中获得灵感,也就是直接学习。事实上,过去和现在的神经科学研究直接表明,人类和动物的学习可以用强化学习和元学习共同表示。
Meta-Learning in Reinforcement Learning
Prefrontal cortex as a meta-reinforcement learning system
最后一篇论文的结果和我们的结论相同,论智此前曾报道过这篇:DeepMind论文:多巴胺不只负责快乐,还能帮助强化学习。从根本上讲,人们可以认为,人类的智慧正是强化学习和元学习的结合——元强化学习的成果。如果真的是这种情况,我们是否也该对AI做同样的事呢?
结语
强化学习的经典基础性缺陷可能限制它解决很多复杂问题,像本文提到的很多论文中都提到,不采用从零学习的方法也不是必须有手工编写或者严格的规则。元强化学习让智能体通过高水平的指导、经验、案例更好地学习。
目前的时机已经成熟到可以展开上述工作,将注意力从纯强化学习的身上移开,多多关注从人类身上学到的学习方法。但是针对纯强化学习的工作不应该立即停止,而是应该作为其他工作的补充。基于元学习、零次学习、少次学习、迁移学习及它们的结合的方法应该成为默认方法,我很愿意为此贡献自己的力量。
-
智能体
+关注
关注
1文章
111浏览量
10426 -
深度学习
+关注
关注
73文章
5239浏览量
119925 -
强化学习
+关注
关注
4文章
259浏览量
11114
原文标题:面对强化学习的基础性缺陷,研究重点也许要转变
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
相关推荐
深度强化学习实战
将深度学习和强化学习相结合的深度强化学习DRL
萨顿科普了强化学习、深度强化学习,并谈到了这项技术的潜力和发展方向
如何深度强化学习 人工智能和深度学习的进阶
什么是强化学习?纯强化学习有意义吗?强化学习有什么的致命缺陷?

强化学习环境研究,智能体玩游戏为什么厉害
复杂应用中运用人工智能核心 强化学习
一文详谈机器学习的强化学习
《自动化学报》—多Agent深度强化学习综述

强化学习的基础知识和6种基本算法解释
强化学习的基础知识和6种基本算法解释

什么是强化学习






 工商网监
工商网监
评论