 深度剖析Redis的两大持久化机制
深度剖析Redis的两大持久化机制

Redis持久化深度解析:RDB与AOF的终极对决与实战优化
引言:一次生产事故引发的思考
凌晨3点,我被一通紧急电话惊醒。线上Redis集群崩溃,6GB的缓存数据全部丢失,导致MySQL瞬间承压暴增,整个交易系统陷入瘫痪。事后复盘发现,问题的根源竟是一个被忽视的持久化配置细节。
这次事故让我深刻意识到:Redis持久化不仅仅是简单的数据备份,更是保障系统高可用的关键防线。今天,我将结合5年的运维实战经验,深度剖析Redis的RDB与AOF两大持久化机制,帮你避开那些"血泪坑"。
一、为什么Redis持久化如此重要?
1.1 Redis的"阿喀琉斯之踵"
Redis以其极致的性能著称,但内存存储的特性也带来了致命弱点:
•断电即失:服务器宕机、进程崩溃都会导致数据永久丢失
•成本压力:纯内存方案成本高昂,1TB内存服务器月租可达数万元
•合规要求:金融、电商等行业对数据持久性有严格的监管要求
1.2 持久化带来的价值
通过合理的持久化策略,我们可以:
• 实现秒级RTO(恢复时间目标),将故障恢复时间从小时级降至分钟级
• 支持跨机房容灾,构建异地多活架构
• 满足数据审计需求,实现关键操作的追溯回放
二、RDB:简单粗暴的快照机制
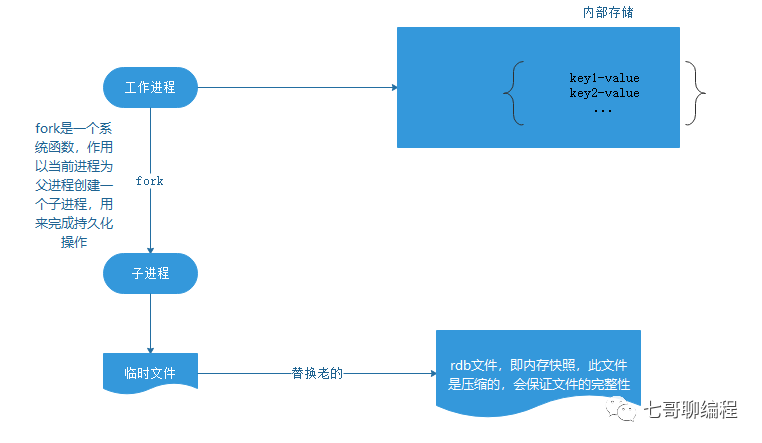
2.1 RDB的工作原理
RDB(Redis Database)采用定期快照的方式,将某一时刻的内存数据完整地持久化到磁盘。想象一下,这就像给Redis的内存状态拍了一张"全家福"。
# redis.conf 中的 RDB 配置示例 save 900 1 # 900秒内至少1个key变化则触发 save 300 10 # 300秒内至少10个key变化则触发 save 60 10000 # 60秒内至少10000个key变化则触发 dbfilename dump.rdb # RDB文件名 dir/var/lib/redis # RDB文件存储路径 rdbcompressionyes # 开启压缩(LZF算法) rdbchecksumyes # 开启CRC64校验 stop-writes-on-bgsave-erroryes# 后台保存出错时停止写入
2.2 触发机制详解
RDB持久化有多种触发方式,每种都有其适用场景:
# Python示例:监控RDB触发情况 importredis importtime r = redis.Redis(host='localhost', port=6379) # 手动触发 BGSAVE defmanual_backup(): result = r.bgsave() print(f"后台保存已触发:{result}") # 监控保存进度 whileTrue: info = r.info('persistence') ifinfo['rdb_bgsave_in_progress'] ==0: print(f"RDB保存完成,耗时:{info['rdb_last_bgsave_time_sec']}秒") break time.sleep(1) print(f"保存中...当前进度:{info['rdb_current_bgsave_time_sec']}秒") # 获取RDB统计信息 defget_rdb_stats(): info = r.info('persistence') stats = { '最后保存时间': time.strftime('%Y-%m-%d %H:%M:%S', time.localtime(info['rdb_last_save_time'])), '最后保存状态':'ok'ifinfo['rdb_last_bgsave_status'] =='ok'else'failed', '当前保存进行中': info['rdb_bgsave_in_progress'] ==1, 'fork耗时(ms)': info['latest_fork_usec'] /1000 } returnstats
2.3 RDB的优势与劣势
优势:
•恢复速度快:加载RDB文件比重放AOF日志快10倍以上
•存储效率高:二进制格式+压缩,文件体积小
•性能影响小:fork子进程异步执行,主进程无阻塞
劣势:
•数据丢失风险:最多丢失一个快照周期的数据
•fork开销大:大内存实例fork可能导致毫秒级阻塞
2.4 实战优化技巧
# 1. 避免频繁全量备份导致的IO压力 # 错误示例:生产环境不要这样配置! save 10 1 # 每10秒只要有1个key变化就备份 # 2. 合理设置备份策略 # 推荐配置:根据业务特点调整 save 3600 1 # 1小时内至少1次变更 save 300 100 # 5分钟内至少100次变更 save 60 10000 # 1分钟内至少10000次变更 # 3. 利用主从复制减少主库压力 # 在从库上执行RDB备份 redis-cli -h slave_host CONFIG SET save"900 1"
三、AOF:精确到每一条命令的日志
3.1 AOF的核心机制
AOF(Append Only File)通过记录每一条写命令来实现持久化,类似MySQL的binlog。这种方式可以最大程度地减少数据丢失。
# AOF 核心配置 appendonlyyes # 开启AOF appendfilename"appendonly.aof" # AOF文件名 appendfsync everysec # 每秒同步一次(推荐) # appendfsync always # 每次写入都同步(最安全但最慢) # appendfsync no # 由操作系统决定(最快但最不安全) no-appendfsync-on-rewrite no # 重写时是否暂停同步 auto-aof-rewrite-percentage 100 # 文件增长100%时触发重写 auto-aof-rewrite-min-size 64mb # AOF文件最小重写大小
3.2 AOF重写机制深度剖析
AOF文件会不断增长,重写机制通过生成等效的最小命令集来压缩文件:
# 模拟AOF重写过程 classAOFRewriter: def__init__(self): self.commands = [] self.data = {} defrecord_command(self, cmd): """记录原始命令""" self.commands.append(cmd) # 模拟执行命令 ifcmd.startswith("SET"): parts = cmd.split() self.data[parts[1]] = parts[2] elifcmd.startswith("INCR"): key = cmd.split()[1] self.data[key] =str(int(self.data.get(key,0)) +1) defrewrite(self): """生成优化后的命令集""" optimized = [] forkey, valueinself.data.items(): optimized.append(f"SET{key}{value}") returnoptimized # 示例:优化前后对比 rewriter = AOFRewriter() original_commands = [ "SET counter 0", "INCR counter", "INCR counter", "INCR counter", "SET name redis", "SET name Redis6.0" ] forcmdinoriginal_commands: rewriter.record_command(cmd) print(f"原始命令数:{len(original_commands)}") print(f"优化后命令数:{len(rewriter.rewrite())}") print(f"压缩率:{(1-len(rewriter.rewrite())/len(original_commands))*100:.1f}%")
3.3 AOF的三种同步策略对比
#!/bin/bash
# 性能测试脚本:对比不同fsync策略
echo"测试环境准备..."
redis-cli FLUSHDB > /dev/null
strategies=("always""everysec""no")
forstrategyin"${strategies[@]}";do
echo"测试 appendfsync =$strategy"
redis-cli CONFIG SET appendfsync$strategy> /dev/null
# 使用redis-benchmark测试
result=$(redis-benchmark -tset-n 100000 -q)
echo"$result"| grep"SET"
# 检查实际持久化情况
sync_count=$(grep -c"sync"/var/log/redis/redis.log |tail-1)
echo"同步次数:$sync_count"
echo"---"
done
3.4 AOF优化实践
-- Lua脚本:批量操作优化AOF记录
-- 将多个命令合并为一个原子操作,减少AOF条目
localprefix = KEYS[1]
localcount =tonumber(ARGV[1])
localvalue = ARGV[2]
localresults = {}
fori =1, countdo
localkey = prefix ..':'.. i
redis.call('SET', key, value)
table.insert(results, key)
end
returnresults
四、RDB vs AOF:如何选择?
4.1 核心指标对比
| 指标 | RDB | AOF |
| 数据安全性 | 较低(可能丢失分钟级数据) | 高(最多丢失1秒数据) |
| 恢复速度 | 快(直接加载二进制) | 慢(需要重放所有命令) |
| 文件体积 | 小(压缩后的二进制) | 大(文本格式命令日志) |
| 性能影响 | 周期性fork开销 | 持续的磁盘IO |
| 适用场景 | 数据分析、缓存 | 消息队列、计数器 |
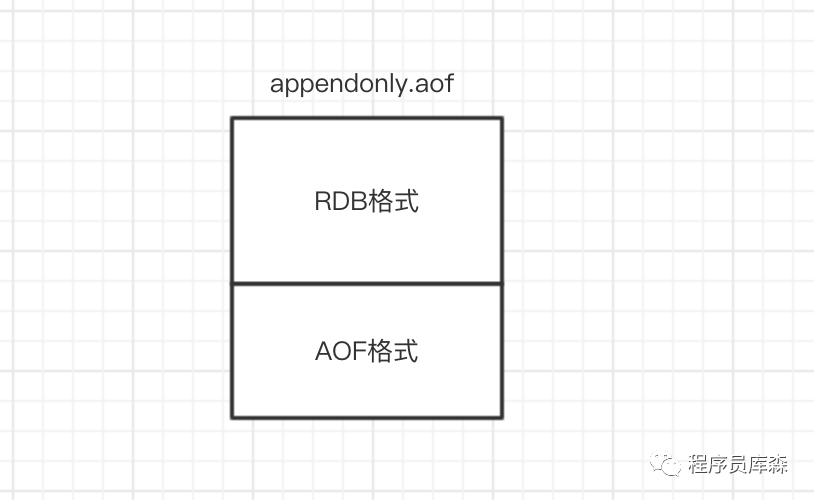
4.2 混合持久化:鱼和熊掌兼得
Redis 4.0引入的混合持久化结合了两者优势:
# 开启混合持久化 aof-use-rdb-preambleyes # 工作原理: # 1. AOF重写时,先生成RDB格式的基础数据 # 2. 后续增量命令以AOF格式追加 # 3. 恢复时先加载RDB部分,再重放AOF增量
4.3 实战选型决策树
defchoose_persistence_strategy(requirements):
"""根据业务需求推荐持久化策略"""
ifrequirements['data_loss_tolerance'] <= 1: # 秒级
if requirements['recovery_time'] <= 60: # 1分钟内恢复
return"混合持久化 (RDB+AOF)"
else:
return"AOF everysec"
elif requirements['data_loss_tolerance'] <= 300: # 5分钟
if requirements['memory_size'] >=32: # GB
return"RDB + 从库AOF"
else:
return"RDB (save 300 10)"
else: # 可容忍较大数据丢失
return"RDB (save 3600 1)"
# 示例:电商订单缓存
order_cache_req = {
'data_loss_tolerance':60, # 可容忍60秒数据丢失
'recovery_time':30, # 要求30秒内恢复
'memory_size':16 # 16GB内存
}
print(f"推荐方案:{choose_persistence_strategy(order_cache_req)}")
五、生产环境最佳实践
5.1 监控告警体系
# 持久化监控指标采集
importredis
importtime
fromdatetimeimportdatetime
classPersistenceMonitor:
def__init__(self, redis_client):
self.redis = redis_client
self.alert_thresholds = {
'rdb_last_save_delay':3600, # RDB超过1小时未保存
'aof_rewrite_delay':7200, # AOF超过2小时未重写
'aof_size_mb':1024, # AOF文件超过1GB
'fork_time_ms':1000 # fork时间超过1秒
}
defcheck_health(self):
"""健康检查并返回告警"""
alerts = []
info =self.redis.info('persistence')
# 检查RDB状态
last_save_delay = time.time() - info['rdb_last_save_time']
iflast_save_delay >self.alert_thresholds['rdb_last_save_delay']:
alerts.append({
'level':'WARNING',
'message':f'RDB已{last_save_delay/3600:.1f}小时未保存'
})
# 检查AOF大小
ifinfo.get('aof_enabled'):
aof_size_mb = info['aof_current_size'] /1024/1024
ifaof_size_mb >self.alert_thresholds['aof_size_mb']:
alerts.append({
'level':'WARNING',
'message':f'AOF文件过大:{aof_size_mb:.1f}MB'
})
returnalerts
# 使用示例
monitor = PersistenceMonitor(redis.Redis())
alerts = monitor.check_health()
foralertinalerts:
print(f"[{alert['level']}]{alert['message']}")
5.2 备份恢复演练
#!/bin/bash # 自动化备份恢复测试脚本 REDIS_HOST="localhost" REDIS_PORT="6379" BACKUP_DIR="/data/redis-backup" TEST_KEY="backup$(date +%s)" # 1. 写入测试数据 echo"写入测试数据..." redis-cli SET$TEST_KEY"test_value"EX 3600 # 2. 执行备份 echo"执行BGSAVE..." redis-cli BGSAVE sleep5 # 3. 备份文件 cp/var/lib/redis/dump.rdb$BACKUP_DIR/dump_$(date+%Y%m%d_%H%M%S).rdb # 4. 模拟数据丢失 redis-cli DEL$TEST_KEY # 5. 恢复数据 echo"停止Redis..." systemctl stop redis echo"恢复备份..." cp$BACKUP_DIR/dump_*.rdb /var/lib/redis/dump.rdb echo"启动Redis..." systemctl start redis # 6. 验证恢复 ifredis-cli GET$TEST_KEY| grep -q"test_value";then echo"✓ 备份恢复成功" else echo"✗ 备份恢复失败" exit1 fi
5.3 容量规划与优化
# 持久化容量评估工具
classPersistenceCapacityPlanner:
def__init__(self, daily_writes, avg_key_size, avg_value_size):
self.daily_writes = daily_writes
self.avg_key_size = avg_key_size
self.avg_value_size = avg_value_size
defestimate_aof_growth(self, days=30):
"""估算AOF文件增长"""
# 每条命令约占用: SET key value
cmd_size =6+self.avg_key_size +self.avg_value_size
daily_growth_mb = (self.daily_writes * cmd_size) /1024/1024
# 考虑重写压缩率约60%
after_rewrite = daily_growth_mb *0.4
return{
'daily_growth_mb': daily_growth_mb,
'monthly_size_mb': after_rewrite * days,
'recommended_rewrite_size_mb': daily_growth_mb *2
}
defestimate_rdb_size(self, total_keys):
"""估算RDB文件大小"""
# RDB压缩率通常在30-50%
raw_size = total_keys * (self.avg_key_size +self.avg_value_size)
compressed_size_mb = (raw_size *0.4) /1024/1024
return{
'estimated_size_mb': compressed_size_mb,
'backup_time_estimate_sec': compressed_size_mb /100# 假设100MB/s
}
# 使用示例
planner = PersistenceCapacityPlanner(
daily_writes=10_000_000, # 日写入1000万次
avg_key_size=20,
avg_value_size=100
)
aof_estimate = planner.estimate_aof_growth()
print(f"AOF日增长:{aof_estimate['daily_growth_mb']:.1f}MB")
print(f"建议重写阈值:{aof_estimate['recommended_rewrite_size_mb']:.1f}MB")
六、踩坑经验与故障案例
6.1 案例一:fork阻塞导致的雪崩
问题描述:32GB内存的Redis实例,执行BGSAVE时主线程阻塞3秒,导致大量请求超时。
根因分析:
• Linux的fork采用COW(写时复制)机制
• 需要复制页表,32GB约需要64MB页表
• 在内存压力大时,分配页表内存耗时增加
解决方案:
# 1. 开启大页内存,减少页表项 echonever > /sys/kernel/mm/transparent_hugepage/enabled # 2. 调整内核参数 sysctl -w vm.overcommit_memory=1 # 3. 错峰执行持久化 redis-cli CONFIG SET save""# 禁用自动RDB # 通过crontab在业务低峰期手动触发 0 3 * * * redis-cli BGSAVE
6.2 案例二:AOF重写死循环
问题描述:AOF文件达到5GB后触发重写,但重写期间新增数据量大于重写压缩量,导致重写永远无法完成。
解决方案:
-- 限流脚本:重写期间降低写入速度
localcurrent = redis.call('INFO','persistence')
ifstring.match(current,'aof_rewrite_in_progress:1')then
-- AOF重写中,限制写入
localkey = KEYS[1]
locallimit =tonumber(ARGV[1])
localcurrent_qps = redis.call('INCR','qps_counter')
ifcurrent_qps > limitthen
return{err ='系统繁忙,请稍后重试'}
end
end
-- 正常执行业务逻辑
returnredis.call('SET', KEYS[1], ARGV[2])
6.3 案例三:混合持久化的版本兼容问题
问题描述:从Redis 5.0降级到4.0时,无法识别混合格式的AOF文件。
预防措施:
# 版本兼容性检查工具
importstruct
defcheck_aof_format(filepath):
"""检查AOF文件格式"""
withopen(filepath,'rb')asf:
header = f.read(9)
ifheader.startswith(b'REDIS'):
# RDB格式头部
version = struct.unpack('bbbbbbbb', header[5:])
returnf"混合格式 (RDB v{version})"
elifheader.startswith(b'*'):
# 纯AOF格式
return"纯AOF格式"
else:
return"未知格式"
# 迁移前检查
aof_format = check_aof_format('/var/lib/redis/appendonly.aof')
print(f"当前AOF格式:{aof_format}")
if"混合"inaof_format:
print("警告: 目标版本可能不支持混合格式,建议先执行BGREWRITEAOF")
七、性能调优实战
7.1 基准测试与调优
#!/bin/bash # 持久化性能基准测试 echo"=== 持久化性能基准测试 ===" # 测试1: 无持久化 redis-cli CONFIG SET save"" redis-cli CONFIG SET appendonly no echo"场景1: 无持久化" redis-benchmark -tset,get -n 1000000 -q # 测试2: 仅RDB redis-cli CONFIG SET save"60 1000" redis-cli CONFIG SET appendonly no echo"场景2: 仅RDB" redis-benchmark -tset,get -n 1000000 -q # 测试3: 仅AOF (everysec) redis-cli CONFIG SET save"" redis-cli CONFIG SET appendonlyyes redis-cli CONFIG SET appendfsync everysec echo"场景3: AOF everysec" redis-benchmark -tset,get -n 1000000 -q # 测试4: RDB+AOF redis-cli CONFIG SET save"60 1000" redis-cli CONFIG SET appendonlyyes echo"场景4: RDB+AOF" redis-benchmark -tset,get -n 1000000 -q
7.2 持久化与内存优化
# 内存碎片与持久化关系分析
defanalyze_memory_fragmentation(redis_client):
"""分析内存碎片对持久化的影响"""
info = redis_client.info('memory')
fragmentation_ratio = info['mem_fragmentation_ratio']
used_memory_gb = info['used_memory'] /1024/1024/1024
recommendations = []
iffragmentation_ratio >1.5:
recommendations.append({
'issue':'内存碎片率过高',
'impact':f'RDB文件可能增大{(fragmentation_ratio-1)*100:.1f}%',
'solution':'考虑执行内存整理: MEMORY PURGE'
})
ifused_memory_gb >16andfragmentation_ratio >1.2:
fork_time_estimate = used_memory_gb *100# ms
recommendations.append({
'issue':'大内存+高碎片',
'impact':f'fork预计阻塞{fork_time_estimate:.0f}ms',
'solution':'建议使用主从架构,在从节点执行持久化'
})
returnrecommendations
八、未来展望与新特性
8.1 Redis 7.0的持久化改进
Redis 7.0带来了多项持久化优化:
1.增量RDB快照:只保存变更的数据页,大幅减少IO
2.AOF时间戳记录:支持按时间点恢复(PITR)
3.多线程持久化:利用多核CPU加速RDB生成
8.2 云原生时代的持久化策略
在Kubernetes环境下,持久化策略需要重新思考:
# Redis StatefulSet with 持久化配置 apiVersion:apps/v1 kind:StatefulSet metadata: name:redis-cluster spec: volumeClaimTemplates: -metadata: name:redis-data spec: accessModes:["ReadWriteOnce"] storageClassName:"fast-ssd" resources: requests: storage:100Gi template: spec: containers: -name:redis image:redis:7.0 volumeMounts: -name:redis-data mountPath:/data command: -redis-server ---save9001 ---appendonlyyes ---appendfsynceverysec
结语:持久化的平衡艺术
Redis持久化不是非黑即白的选择题,而是需要根据业务特点精心权衡的平衡艺术。记住这几个核心原则:
1.没有银弹:RDB快但可能丢数据,AOF安全但恢复慢
2.监控先行:建立完善的监控体系,及时发现问题
3.演练常态化:定期进行故障演练,验证恢复流程
4.与时俱进:关注Redis新版本特性,适时升级优化
最后,回到文章开头的生产事故,我们最终采用了混合持久化+主从架构的方案,将RTO从4小时缩短到5分钟,RPO从6小时缩短到1秒。技术选型没有对错,只有适合与否。
-
内存
+关注
关注
9文章
3234浏览量
76518 -
集群
+关注
关注
0文章
151浏览量
17687 -
Redis
+关注
关注
0文章
394浏览量
12251
原文标题:Redis持久化深度解析:RDB与AOF的终极对决与实战优化
文章出处:【微信号:magedu-Linux,微信公众号:马哥Linux运维】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Redis持久化机制的实现原理和使用技巧
redis两种持久化方式的区别
redis的持久化方式RDB和AOF的区别
redis里数据什么时候持久化
Redis使用重要的两个机制:Reids持久化和主从复制




评论