 一种新型分割图像中人物的方法,基于人物动作辨认
一种新型分割图像中人物的方法,基于人物动作辨认

想要进行图像分割,传统方法是先检测图中物体,在进行分离。在本文中,来自清华大学、腾讯AI研究室和英国卡迪夫大学的研究者们提出了一种新型分割图像中人物的方法,基于人物动作辨认。以下是论智对原文的编译。

图像分割的一般方法是先对物体进行检测,然后用边界框对画中物体进行分割。最近,例如Mask R-CNN的深度学习方法也被用于图像分割任务,但是大多数研究都没有注意到人类的特殊性:可以通过身体姿势进行辨认。在这篇论文中,我们提出了一种新方法,可以通过人作出的不同动作进行图像分割。
多人姿态辨认的目的是分辨图像中每个人物的动作,这些需要通过身体部位判断,比如头部、肩膀、手部、脚等等。而一般的对象分割实例旨在预测图像中每个对象的像素级标签。要想解决这两个问题,都需要检测目标物体并将它们分离,这一过程通常被称为目标检测。但是由于二维图像所含信息较少,导致想分离两个重叠的同类图像非常困难。对于目标检测,有许多强有力的基准系统,例如Fast/Faster R-CNN、YOLO,它们都遵循着一个基本规则:先生成大量proposal regions,然后用非极大抑制删除重复区域。但是,当两个相同类别的物体重叠时,NMS总是将其中一个视为重复的proposal region,然后删除它。这表明几乎所有的目标检测都不能处理大面积重合的问题。
尽管在许多多人姿态识别任务中都选用了这种框架,一些不依赖于目标检测的bottom-up方法也取得了良好性能。Bottom-up方法的主要思想是首先在所有人身体上找几个关键点。如图1所示:
图1
这种方法有几个优点,首先,运行成本不会随着图像中人数的增加而增加;其次,两个重叠在一起的人物可以在连接身体部位时分开,如图2所示,使用人体姿势可以改善目标检测中物体重叠的问题。

图2
新方法Pose2Seg
基于人体姿势识别,我们提出了一种端到端的物体分割框架,整体框架如图3所示,它将图片和姿势识别结果一同作为输入:
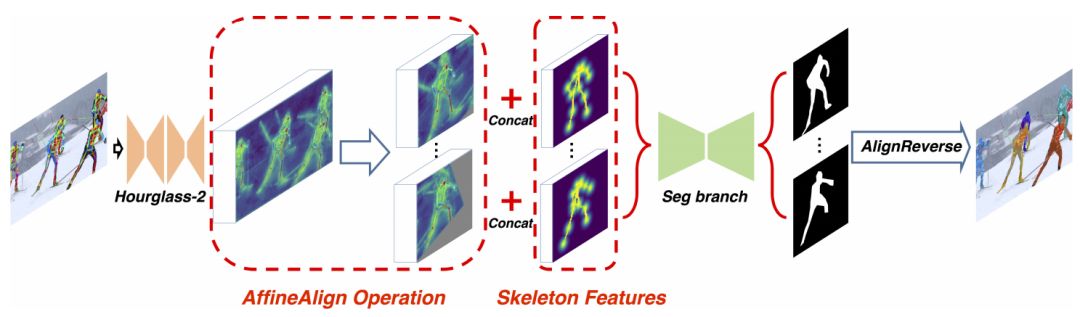
图3
然后我们使用一个对准模块,基于人体姿势检测结果(称为Affine Align),将感兴趣区域(ROI)对齐为统一大小(64×64)。同时,我们为图中的每个人物生成骨架特征,并将它们连接到ROI。最终实验表明,将骨骼信息明确地添加到网络中可以在图像分割中提供更好的信息。
AffineAlign
人类的动作种类多且复杂,想要进行图像分割是很困难的。基于Faster R-CNN和Mask R-CNN中的ROIAlign,我们提出了AffineAlign操作。但是与它们不同的是,我们是基于人物的动作对齐,而不是边界框。通过人类动作蕴涵的信息,AffineAlign操作可以把奇怪的人类动作拉直,然后将重叠的人分开,具体过程可看图4:
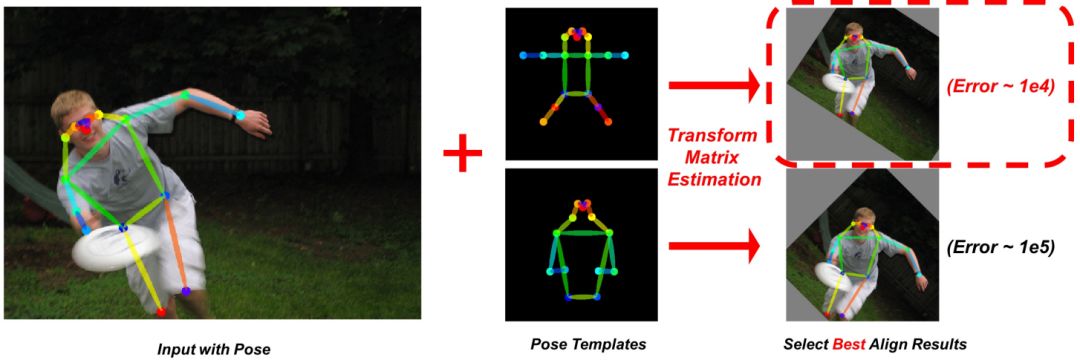
图4
同时,我们还研究了人类骨骼的特征,我们用部分亲和字段(PAF)重现某个动作的骨骼结构,PAF是一个有两通道的向量字段映射,如果COCO数据集中有11个骨骼标记,PAF就是一个有22个通道的特征映射。

实验过程
我们选用了COCO数据集,它是人类图像数量最多的公开数据及,其中我们将其分成了COCOHUMAN和COCOHUMAN-OC两个数据集,前者是有中等和大型目标物体的人类数据集,并对其中的动作进行了标注;后者是有较多重叠对象的图像,共有44张图。COCOHUMAN-OC中的一些样例如图所示:

首先是在COCOHUMAN上,本文提出的方法与Mask R-CNN进行对比:
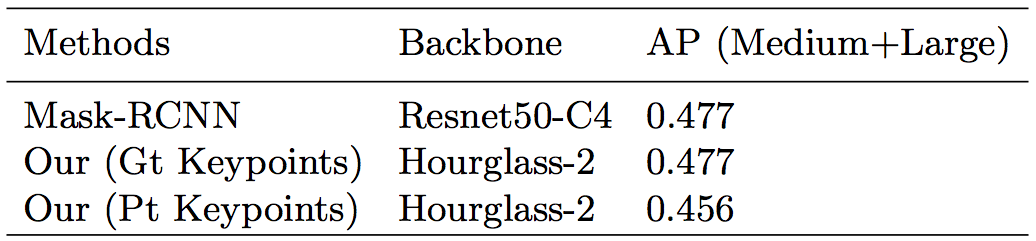
其他AffineAlign操作,a代表输入的图像,b代表在原图上锁定目标,c代表AffineAlign操作的结果,d代表分割结果
然后是在COCOHUMAN-OC上的实验对比:
我们的方法与Mask R-CNN在处理重叠图像上的表现。我们方法中的边界框使用预测掩码生成的,能更好地进行可视化和对比
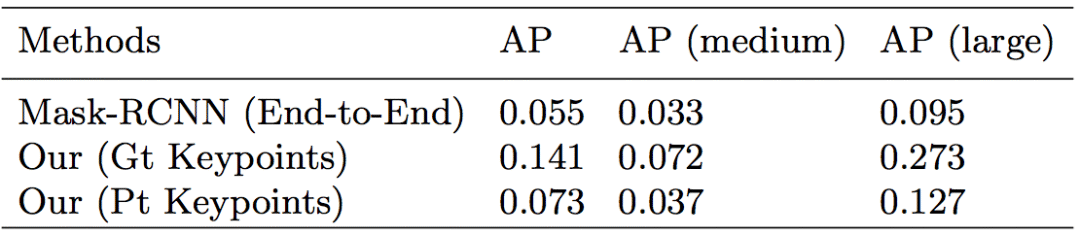
上表显示,我们提出的基于动作姿势的框架比基于图像检测的框架表现得好。由于非极大抑制,一些基于检测的框架,如Mask R-CNN无法处理大面积重叠的现象。即使目标物体能被分离,仍然有一部分无法算入其中。但是在这种新框架下,我们做到了让整个身体都被分离的结果。
-
图像分割
+关注
关注
4文章
182浏览量
18676 -
深度学习
+关注
关注
73文章
5590浏览量
123907
原文标题:清华大学与腾讯AI合作推出Pose2Seg:无需目标检测即对人像进行分割
文章出处:【微信号:jqr_AI,微信公众号:论智】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
Unity 3D和Vuforia制作AR人物互动
一种新的彩色图像分割算法

一种视频流特定人物检测方法
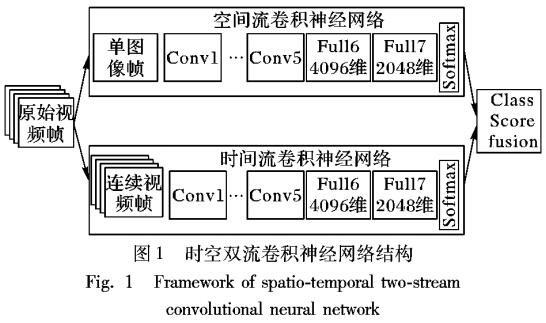
基于视频深度学习的时空双流人物动作识别模型
一种开源的机器学习模型,可在浏览器中使用TensorFlow.js对人物及身体部位进行分割
基于TensorFlow的开源JS库的网页前端人物动作捕捉的实现

一种可用于生成动漫人物头像的改进模型






 工商网监
工商网监
评论