 基于RV1126开发板的AI算法开发流程
基于RV1126开发板的AI算法开发流程

1. 概述

2. 需求分析
算法的功能常常可以用一个短词概括,如人脸识别、司机行为检测、商场顾客行为分析等系统,但是却需要依靠多个子算法的有序运作才能达成。其原因在于子算法的神经网络结构各有不同,这些结构的差异化优化了各个子算法在其功能上的实现效果。
| 模型分类名称 | 功能 |
| 目标检测模型 | 检测图像中是否存在目标物体,并给出其在图像中的具体坐标,可同时提供分类功能 |
| 关键点定位模型 | 检测图像中的特定目标,并标出关键点位,常见骨骼点位、面部器官点位等 |
| 相似度比对模型 | 比较两个不同的个体的相似度,常见人脸、猪脸识别,商品识别 |
| 分割模型 | 检测图像中存在的物体,按轮廓或其他标准分割出物体所在的不规则像素区域,可同时带分类功能 |
| OCR模型 | 识别字体 |
以下我们列出组成例子:
例子a: 人脸识别算法 = 人脸检测(检测模型)+ 矫正人脸姿态模型(关键点定位模型)+ 人脸比对模型(相似度比对模型)
例子b: 司机行为检测算法 = 人脸识别算法(具体组成如上例)+ 抽烟玩手机等危险动作识别(检测模型) + 疲劳驾驶检测(关键点定位模型)+ 车道线偏移检测(检测模型)
例子c: 商场分析 = 人脸识别算法(具体组成如首例)+ 人体跟踪算法(检测模型 + 相似度比对模型)
只有在确定了具体需求所需要的步骤后,我们才能有的放矢的采集数据,优化模型,训练出合乎我们需求的模型。
3. 准备数据
即使准备数据在大多数人看来是繁琐重复的工作,这期间仍有许多细节需要注意的。
数据样本需要良好的多样性。样本多样性是保证算法泛化能力的基础,例如想要识别农产品的功能中,假如我们只是搜集红苹果的数据,那么训练出来的网络就很难将绿色的苹果准确识别出。同时还需要加入充足的负样本,例如我们只是单纯地把农产品的图片数据喂给神经网络,那么我们就很难期望训练出来的神经网络可以有效区分真苹果还有塑料苹果。为了增强算法的可靠性,我们就需要充分的考虑到实际应用场景中会出现什么特殊情况,并将该种情况的数据添加进我们的训练数据里面。
数据样本是否可被压缩。单个样本数据的大小往往决定了网络模型的运行效率,在保证效果的情况下,应当尽量压缩图片的大小来提高运行效率,如112x112的图片,在相同环境下的处理速度将比224x224图片的快4倍左右。但是有些场景却是需要完整的图片来保证图片信息不会丢失,如山火检测一般需要很高的查全率,过度的压缩都会导致查全率下降导致算法效果不佳。
数据需要合适正确的标注与预处理。数据标注在一定程度上决定了训练效果能达到的高度,过多的错误标记将带来一个无效的训练结果。而数据的预处理,是指先对数据做出一定的操作,使其更容易被机器读懂,例如农产品在画面中的位置,如果是以像素点为单位,如农产品的中心点在左起第200个像素点,这种处理方式虽然直观准确,但是会因为不同像素点之间的差距过大,导致训练困难,这个时候就需要将距离归一化,如中心点在图中左起40%宽的位置上。而音频的预处理更为多样,不同的分词方式、傅里叶变换都会影响训练结果。
数据的准备不一定得在一开始就做到毫无遗漏。模型训练完成后,如果有一定的效果但还存在部分缺陷,就可以考虑添加或优化训练样本数据,对已有模型进行复训练修正。即使是后期的优化,增添合适的照片往往是最有效的效果。所以对数据的考量优化应该贯穿整个流程,不能在只是在开头阶段才关注数据样本的问题。
4. 选取模型
通常来讲,对于同一个功能,存在着不同的模型,它们在精度、计算速率上各有长处。模型来发现主要来源于学术研究、公司之间的公开比赛等,所以在研发过程中,就需从业人员持续地关注有关ai新模型的文章;同时对旧模型的积累分析也是十分重要的,这里我们在 下表 中列出目前在各个功能上较优的模型结构以供参考。
| 模型类型 | 模型名称 | 效果 | 速率 |
| 检测模型 | yolov5 | 精度高 | 中等 |
| 检测模型 | ssd | 精度中等,对小物体的识别一般 | 快速 |
| 关键点定位模型 | mtcnn | 精度一般,关键点较少 | 快 |
| 关键点的定位模型 | openpose | 精度高,关键点多 | 中等 |
| 相似度比对模型 | resnet18 | 精度高 | 快速 |
| 相似度比对模型 | resnet50 | 精度高,鲁棒性强,有比较强的抗干扰能力 | 中等 |
| 分割模型 | mask-rcnn | 精度中,分割出画面中的不规则物体 | 慢 |
5. 训练模型
对于有AI开发经验的研发人员,可以用自己熟悉的常见框架训练即可,如tensorflow、pytorch、caffe等主流框架,我们的开发套件可以将其转为EASY EAI Nano的专用模型。
6. 模型转换
研发tensorflow、pytorch、caffe等自主的模型后,需先将模型转换为rknn模型。同时一般需要对模型进行量化与预编译,以达到运行效率的提升。
6.1 模型转换环境搭建
6.1.1 概述
模型转换环境搭建流程如下所示:

6.1.2 下载模型转换工具
为了保证模型转换工具顺利运行,请下载网盘里“AI算法开发/RKNN-Toolkit模型转换工具/rknn-toolkit-v1.7.1/docker/rknn-toolkit-1.7.1-docker.tar.gz”。
网盘下载链接:https://pan.baidu.com/s/1LUtU_-on7UB3kvloJlAMkA 提取码:teuc
6.1.3 把工具移到ubuntu18.04
把下载完成的docker镜像移到我司的虚拟机ubuntu18.04的rknn-toolkit目录,如下图所示:
6.1.4 运行模型转换工具环境
(1)打开终端
在该目录打开终端:
(2)加载docker镜像
执行以下指令加载模型转换工具docker镜像:
docker load --input /home/developer/rknn-toolkit/rknn-toolkit-1.7.1-docker.tar.gz
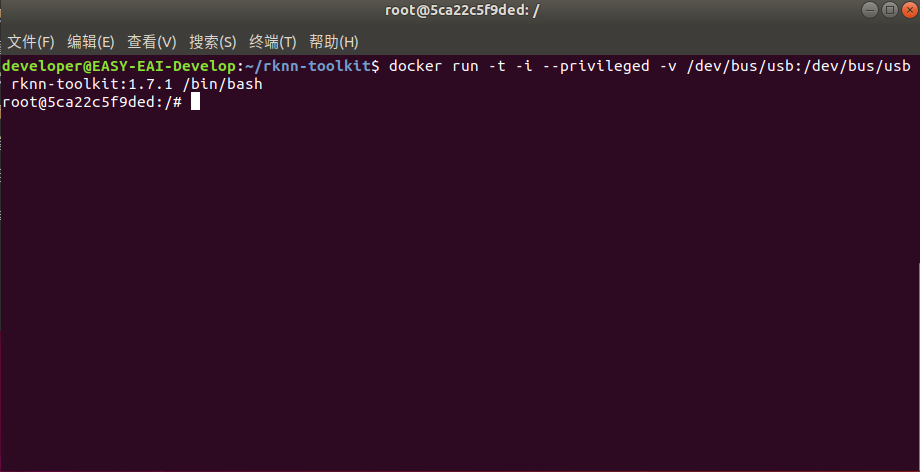
(3)进入镜像bash环境
执行以下指令进入镜像bash环境:
docker run -t -i --privileged -v /dev/bus/usb:/dev/bus/usb rknn-toolkit:1.7.1 /bin/bash
现象如下图所示:
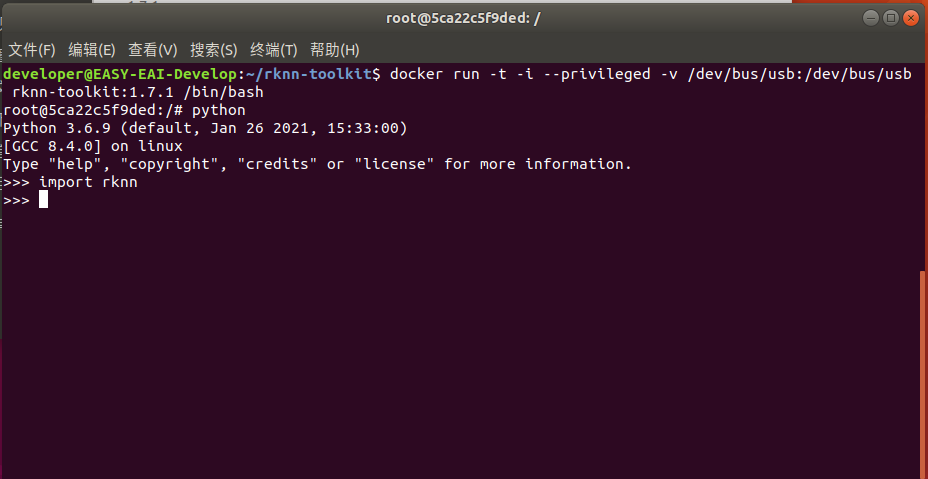
(4)测试环境
输入“python”加载python相关库,尝试加载rknn库,如下图环境测试成功:
至此,模型转换工具环境搭建完成。
6.2 模型转换示例
6.2.1 模型转换流程介绍
EASY EAI Nano支持.rknn后缀的模型的评估及运行,对于常见的tensorflow、tensroflow lite、caffe、darknet、onnx和Pytorch模型都可以通过我们提供的 toolkit 工具将其转换至 rknn 模型,而对于其他框架训练出来的模型,也可以先将其转至 onnx 模型再转换为 rknn 模型。
模型转换操作流程入下图所示:

6.2.2 模型转换Demo下载
下载百度网“AI算法开发/模型转换Demo/model_convert.tar.bz2”。把model_convert.tar.bz2解压到虚拟机,如下图所示:
下载链接:https://pan.baidu.com/s/1OjDXM8kGXDbn5BqIeErpmw 提取码:drv0
6.2.3 进入模型转换工具docker环境
执行以下指令把工作区域映射进docker镜像,其中/home/developer/rknn-toolkit/model_convert为工作区域,/test为映射到docker镜像,/dev/bus/usb:/dev/bus/usb为映射usb到docker镜像:
docker run -t -i --privileged -v /dev/bus/usb:/dev/bus/usb -v /home/developer/rknn-toolkit/model_convert:/test rknn-toolkit:1.7.1 /bin/bash
执行成功如下图所示:
6.2.4 模型转换操作说明
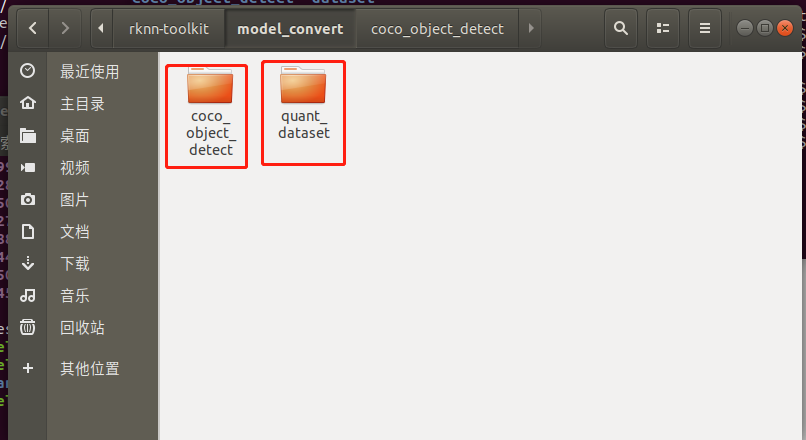
(1)模型转换Demo目录结构
模型转换测试Demo由coco_object_detect和quant_dataset组成。coco_object_detect存放软件脚本,quant_dataset存放量化模型所需的数据。如下图所示:
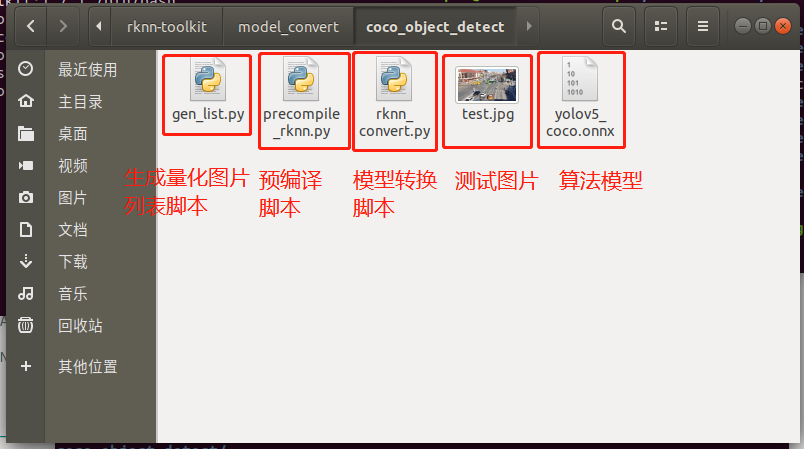
coco_object_detect文件夹存放以下内容,如下图所示:
(2)生成量化图片列表
在docker环境切换到模型转换工作目录:
cd /test/coco_object_detect/
如下图所示:
执行gen_list.py生成量化图片列表:
python gen_list.py
命令行现象如下图所示:
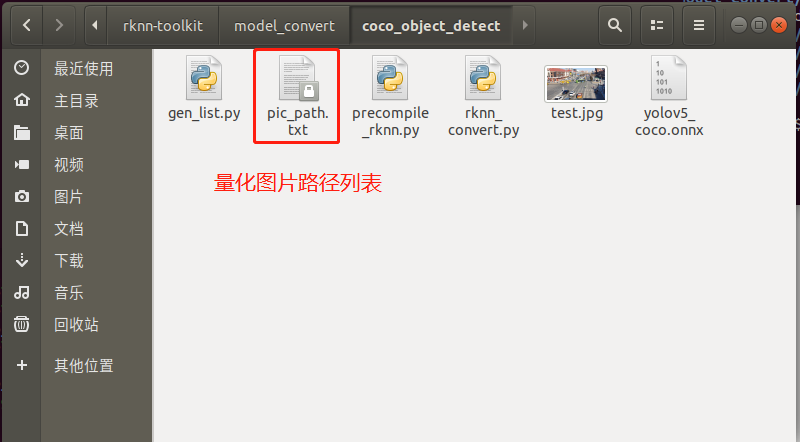
生成“量化图片列表”如下文件夹所示:
(3)onnx模型转换为rknn模型
rknn_convert.py脚本默认进行int8量化操作,脚本代码清单如下所示:
import os import urllib import traceback import time import sys import numpy as np import cv2 from rknn.api import RKNN ONNX_MODEL = 'yolov5_coco.onnx' RKNN_MODEL = './yolov5_coco_rv1126.rknn' DATASET = './pic_path.txt' QUANTIZE_ON = True if __name__ == '__main__': # Create RKNN object rknn = RKNN(verbose=True) if not os.path.exists(ONNX_MODEL): print('model not exist') exit(-1) # pre-process config print('--> Config model') rknn.config(reorder_channel='0 1 2', mean_values=[[0, 0, 0]], std_values=[[255, 255, 255]], optimization_level=3, target_platform = 'rv1126', output_optimize=1, quantize_input_node=QUANTIZE_ON) print('done') # Load ONNX model print('--> Loading model') ret = rknn.load_onnx(model=ONNX_MODEL) if ret != 0: print('Load yolov5 failed!') exit(ret) print('done') # Build model print('--> Building model') ret = rknn.build(do_quantization=QUANTIZE_ON, dataset=DATASET) if ret != 0: print('Build yolov5 failed!') exit(ret) print('done') # Export RKNN model print('--> Export RKNN model') ret = rknn.export_rknn(RKNN_MODEL) if ret != 0: print('Export yolov5rknn failed!') exit(ret) print('done')
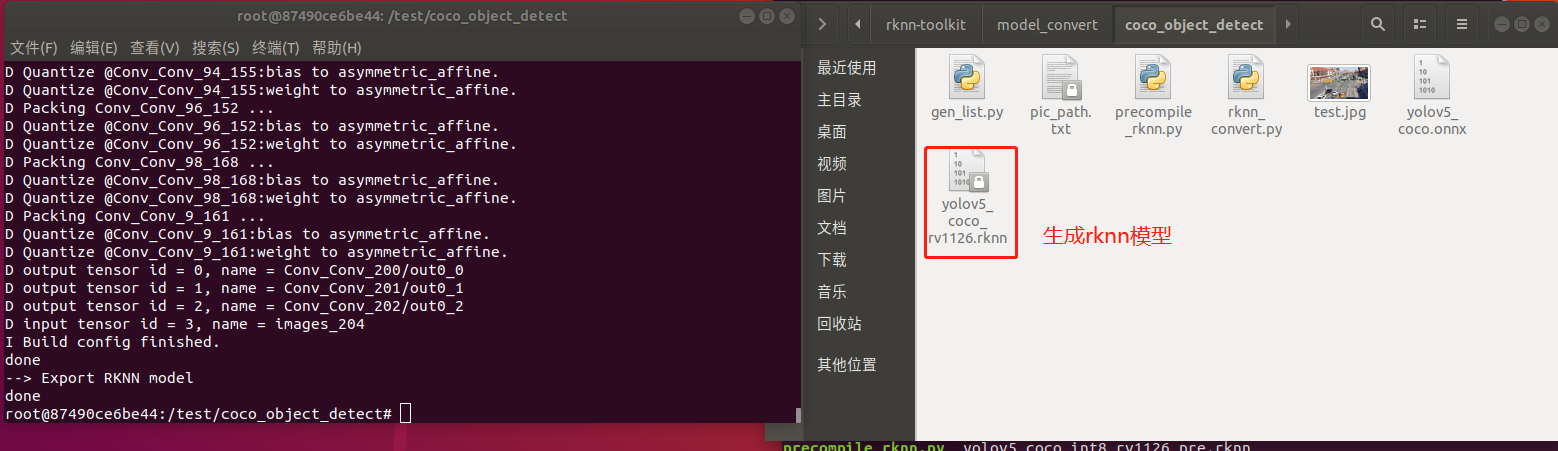
在执行rknn_convert.py脚本进行模型转换:
python rknn_convert.py
生成模型如下图所示,此模型可以在rknn环境和EASY EAI Nano环境运行:
(4)运行rknn模型
用yolov5_coco_test.py脚本在PC端的环境下可以运行rknn的模型,如下图所示:
yolov5_coco_test.py脚本程序清单如下所示:
import os import urllib import traceback import time import sys import numpy as np import cv2 import random from rknn.api import RKNN RKNN_MODEL = 'yolov5_coco_rv1126.rknn' IMG_PATH = './test.jpg' DATASET = './dataset.txt' BOX_THRESH = 0.25 NMS_THRESH = 0.6 IMG_SIZE = 640 CLASSES = ("person", "bicycle", "car","motorbike ","aeroplane ","bus ","train","truck ","boat","traffic light", "fire hydrant","stop sign ","parking meter","bench","bird","cat","dog ","horse ","sheep","cow","elephant", "bear","zebra ","giraffe","backpack","umbrella","handbag","tie","suitcase","frisbee","skis","snowboard","sports ball","kite", "baseball bat","baseball glove","skateboard","surfboard","tennis racket","bottle","wine glass","cup","fork","knife", "spoon","bowl","banana","apple","sandwich","orange","broccoli","carrot","hot dog","pizza ","donut","cake","chair","sofa", "pottedplant","bed","diningtable","toilet ","tvmonitor","laptop","mouse","remote ","keyboard ","cell phone","microwave ", "oven ","toaster","sink","refrigerator ","book","clock","vase","scissors ","teddy bear ","hair drier", "toothbrush") def sigmoid(x): return 1 / (1 + np.exp(-x)) def xywh2xyxy(x): # Convert [x, y, w, h] to [x1, y1, x2, y2] y = np.copy(x) y[:, 0] = x[:, 0] - x[:, 2] / 2 # top left x y[:, 1] = x[:, 1] - x[:, 3] / 2 # top left y y[:, 2] = x[:, 0] + x[:, 2] / 2 # bottom right x y[:, 3] = x[:, 1] + x[:, 3] / 2 # bottom right y return y def process(input, mask, anchors): anchors = [anchors[i] for i in mask] grid_h, grid_w = map(int, input.shape[0:2]) box_confidence = sigmoid(input[..., 4]) box_confidence = np.expand_dims(box_confidence, axis=-1) box_class_probs = sigmoid(input[..., 5:]) box_xy = sigmoid(input[..., :2])*2 - 0.5 col = np.tile(np.arange(0, grid_w), grid_w).reshape(-1, grid_w) row = np.tile(np.arange(0, grid_h).reshape(-1, 1), grid_h) col = col.reshape(grid_h, grid_w, 1, 1).repeat(3, axis=-2) row = row.reshape(grid_h, grid_w, 1, 1).repeat(3, axis=-2) grid = np.concatenate((col, row), axis=-1) box_xy += grid box_xy *= int(IMG_SIZE/grid_h) box_wh = pow(sigmoid(input[..., 2:4])*2, 2) box_wh = box_wh * anchors box = np.concatenate((box_xy, box_wh), axis=-1) return box, box_confidence, box_class_probs def filter_boxes(boxes, box_confidences, box_class_probs): """Filter boxes with box threshold. It's a bit different with origin yolov5 post process! # Arguments boxes: ndarray, boxes of objects. box_confidences: ndarray, confidences of objects. box_class_probs: ndarray, class_probs of objects. # Returns boxes: ndarray, filtered boxes. classes: ndarray, classes for boxes. scores: ndarray, scores for boxes. """ box_scores = box_confidences * box_class_probs box_classes = np.argmax(box_class_probs, axis=-1) box_class_scores = np.max(box_scores, axis=-1) pos = np.where(box_confidences[...,0] >= BOX_THRESH) boxes = boxes[pos] classes = box_classes[pos] scores = box_class_scores[pos] return boxes, classes, scores def nms_boxes(boxes, scores): """Suppress non-maximal boxes. # Arguments boxes: ndarray, boxes of objects. scores: ndarray, scores of objects. # Returns keep: ndarray, index of effective boxes. """ x = boxes[:, 0] y = boxes[:, 1] w = boxes[:, 2] - boxes[:, 0] h = boxes[:, 3] - boxes[:, 1] areas = w * h order = scores.argsort()[::-1] keep = [] while order.size > 0: i = order[0] keep.append(i) xx1 = np.maximum(x[i], x[order[1:]]) yy1 = np.maximum(y[i], y[order[1:]]) xx2 = np.minimum(x[i] + w[i], x[order[1:]] + w[order[1:]]) yy2 = np.minimum(y[i] + h[i], y[order[1:]] + h[order[1:]]) w1 = np.maximum(0.0, xx2 - xx1 + 0.00001) h1 = np.maximum(0.0, yy2 - yy1 + 0.00001) inter = w1 * h1 ovr = inter / (areas[i] + areas[order[1:]] - inter) inds = np.where(ovr <= NMS_THRESH)[0] order = order[inds + 1] keep = np.array(keep) return keep def yolov5_post_process(input_data): masks = [[0, 1, 2], [3, 4, 5], [6, 7, 8]] anchors = [[10, 13], [16, 30], [33, 23], [30, 61], [62, 45], [59, 119], [116, 90], [156, 198], [373, 326]] boxes, classes, scores = [], [], [] for input,mask in zip(input_data, masks): b, c, s = process(input, mask, anchors) b, c, s = filter_boxes(b, c, s) boxes.append(b) classes.append(c) scores.append(s) boxes = np.concatenate(boxes) boxes = xywh2xyxy(boxes) classes = np.concatenate(classes) scores = np.concatenate(scores) nboxes, nclasses, nscores = [], [], [] for c in set(classes): inds = np.where(classes == c) b = boxes[inds] c = classes[inds] s = scores[inds] keep = nms_boxes(b, s) nboxes.append(b[keep]) nclasses.append(c[keep]) nscores.append(s[keep]) if not nclasses and not nscores: return None, None, None boxes = np.concatenate(nboxes) classes = np.concatenate(nclasses) scores = np.concatenate(nscores) return boxes, classes, scores def scale_coords(x1, y1, x2, y2, dst_width, dst_height): dst_top, dst_left, dst_right, dst_bottom = 0, 0, 0, 0 gain = 0 if dst_width > dst_height: image_max_len = dst_width gain = IMG_SIZE / image_max_len resized_height = dst_height * gain height_pading = (IMG_SIZE - resized_height)/2 print("height_pading:", height_pading) y1 = (y1 - height_pading) y2 = (y2 - height_pading) print("gain:", gain) dst_x1 = int(x1 / gain) dst_y1 = int(y1 / gain) dst_x2 = int(x2 / gain) dst_y2 = int(y2 / gain) return dst_x1, dst_y1, dst_x2, dst_y2 def plot_one_box(x, img, color=None, label=None, line_thickness=None): tl = line_thickness or round(0.002 * (img.shape[0] + img.shape[1]) / 2) + 1 # line/font thickness color = color or [random.randint(0, 255) for _ in range(3)] c1, c2 = (int(x[0]), int(x[1])), (int(x[2]), int(x[3])) cv2.rectangle(img, c1, c2, color, thickness=tl, lineType=cv2.LINE_AA) if label: tf = max(tl - 1, 1) # font thickness t_size = cv2.getTextSize(label, 0, fontScale=tl / 3, thickness=tf)[0] c2 = c1[0] + t_size[0], c1[1] - t_size[1] - 3 cv2.rectangle(img, c1, c2, color, -1, cv2.LINE_AA) # filled cv2.putText(img, label, (c1[0], c1[1] - 2), 0, tl / 3, [225, 255, 255], thickness=tf, lineType=cv2.LINE_AA) def draw(image, boxes, scores, classes): """Draw the boxes on the image. # Argument: image: original image. boxes: ndarray, boxes of objects. classes: ndarray, classes of objects. scores: ndarray, scores of objects. all_classes: all classes name. """ for box, score, cl in zip(boxes, scores, classes): x1, y1, x2, y2 = box print('class: {}, score: {}'.format(CLASSES[cl], score)) print('box coordinate x1,y1,x2,y2: [{}, {}, {}, {}]'.format(x1, y1, x2, y2)) x1 = int(x1) y1 = int(y1) x2 = int(x2) y2 = int(y2) dst_x1, dst_y1, dst_x2, dst_y2 = scale_coords(x1, y1, x2, y2, image.shape[1], image.shape[0]) #print("img.cols:", image.cols) plot_one_box((dst_x1, dst_y1, dst_x2, dst_y2), image, label='{0} {1:.2f}'.format(CLASSES[cl], score)) ''' cv2.rectangle(image, (dst_x1, dst_y1), (dst_x2, dst_y2), (255, 0, 0), 2) cv2.putText(image, '{0} {1:.2f}'.format(CLASSES[cl], score), (dst_x1, dst_y1 - 6), cv2.FONT_HERSHEY_SIMPLEX, 0.6, (0, 0, 255), 2) ''' def letterbox(im, new_shape=(640, 640), color=(0, 0, 0)): # Resize and pad image while meeting stride-multiple constraints shape = im.shape[:2] # current shape [height, width] if isinstance(new_shape, int): new_shape = (new_shape, new_shape) # Scale ratio (new / old) r = min(new_shape[0] / shape[0], new_shape[1] / shape[1]) # Compute padding ratio = r, r # width, height ratios new_unpad = int(round(shape[1] * r)), int(round(shape[0] * r)) dw, dh = new_shape[1] - new_unpad[0], new_shape[0] - new_unpad[1] # wh padding dw /= 2 # divide padding into 2 sides dh /= 2 if shape[::-1] != new_unpad: # resize im = cv2.resize(im, new_unpad, interpolation=cv2.INTER_LINEAR) top, bottom = int(round(dh - 0.1)), int(round(dh + 0.1)) left, right = int(round(dw - 0.1)), int(round(dw + 0.1)) im = cv2.copyMakeBorder(im, top, bottom, left, right, cv2.BORDER_CONSTANT, value=color) # add border return im, ratio, (dw, dh) if __name__ == '__main__': # Create RKNN object rknn = RKNN(verbose=True) print('--> Loading model') ret = rknn.load_rknn(RKNN_MODEL) if ret != 0: print('load rknn model failed') exit(ret) print('done') # init runtime environment print('--> Init runtime environment') ret = rknn.init_runtime() # ret = rknn.init_runtime('rv1126', device_id='1126') if ret != 0: print('Init runtime environment failed') exit(ret) print('done') # Set inputs img = cv2.imread(IMG_PATH) letter_img, ratio, (dw, dh) = letterbox(img, new_shape=(IMG_SIZE, IMG_SIZE)) letter_img = cv2.cvtColor(letter_img, cv2.COLOR_BGR2RGB) # Inference print('--> Running model') outputs = rknn.inference(inputs=[letter_img]) print('--> inference done') # post process input0_data = outputs[0] input1_data = outputs[1] input2_data = outputs[2] input0_data = input0_data.reshape([3,-1]+list(input0_data.shape[-2:])) input1_data = input1_data.reshape([3,-1]+list(input1_data.shape[-2:])) input2_data = input2_data.reshape([3,-1]+list(input2_data.shape[-2:])) input_data = list() input_data.append(np.transpose(input0_data, (2, 3, 0, 1))) input_data.append(np.transpose(input1_data, (2, 3, 0, 1))) input_data.append(np.transpose(input2_data, (2, 3, 0, 1))) print('--> transpose done') boxes, classes, scores = yolov5_post_process(input_data) print('--> get result done') #img_1 = cv2.cvtColor(img, cv2.COLOR_RGB2BGR) if boxes is not None: draw(img, boxes, scores, classes) cv2.imwrite('./result.jpg', img) #cv2.imshow("post process result", img_1) #cv2.waitKeyEx(0) rknn.release()
执行yolov5_coco_test.py脚本测试rknn模型:
python yolov5_coco_test.py
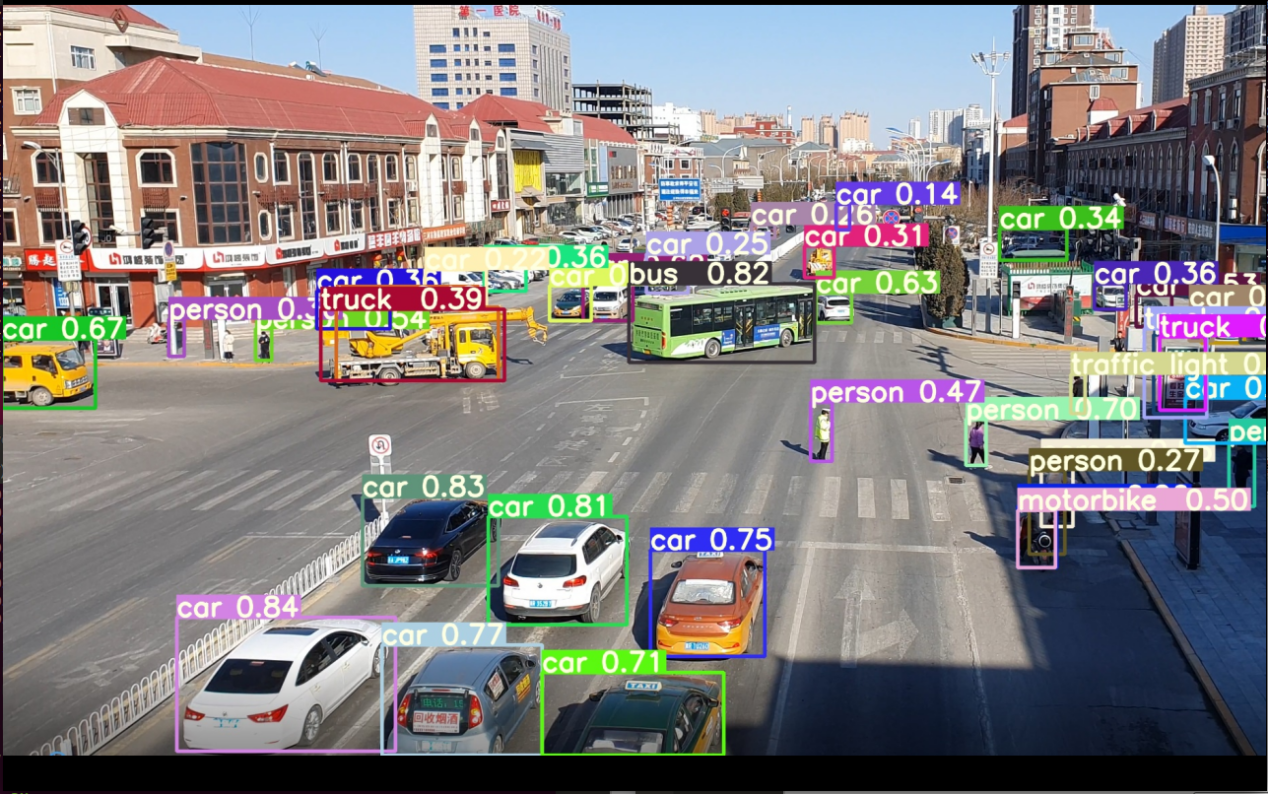
执行后得到result.jpg如下图所示:
(5)模型预编译
由于rknn模型用NPU API在EASY EAI Nano加载的时候启动速度会好慢,在评估完模型精度没问题的情况下,建议进行模型预编译。预编译的时候需要通过EASY EAI Nano主板的环境,所以请务必接上adb口与ubuntu保证稳定连接。
板子端接线如下图所示,拨码开关需要是adb:

虚拟机要保证接上adb设备:
由于在虚拟机里ubuntu环境与docker环境对adb设备资源是竞争关系,所以需要关掉ubuntu环境下的adb服务,且在docker里面通过apt-get安装adb软件包。以下指令在ubuntu环境与docker环境里各自执行:
在docker环境里执行adb devices,现象如下图所示则设备连接成功:
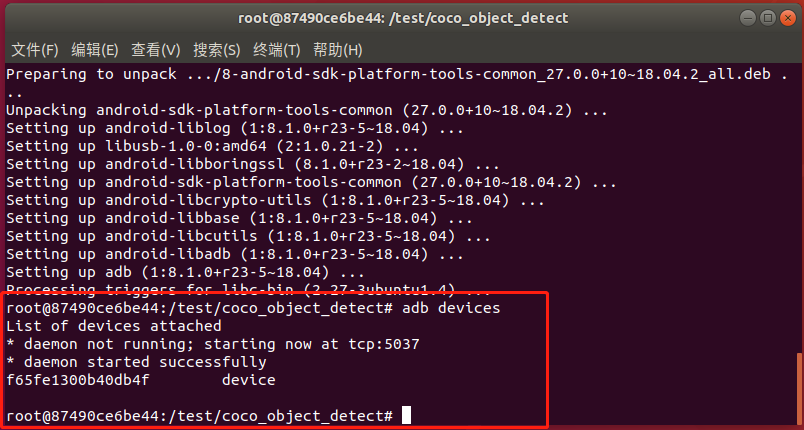
运行precompile_rknn.py脚本把模型执行预编译:
python precompile_rknn.py
执行效果如下图所示,生成预编译模型yolov5_coco_int8_rv1126_pre.rknn:
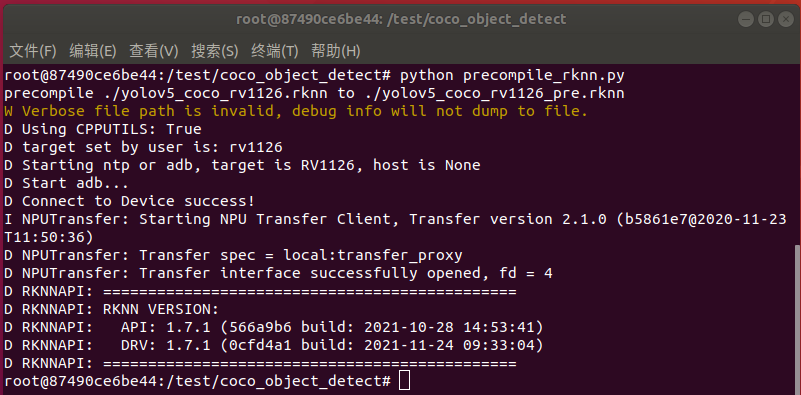
至此预编译部署完成,模型转换步骤已全部完成。生成如下预编译后的int8量化模型:
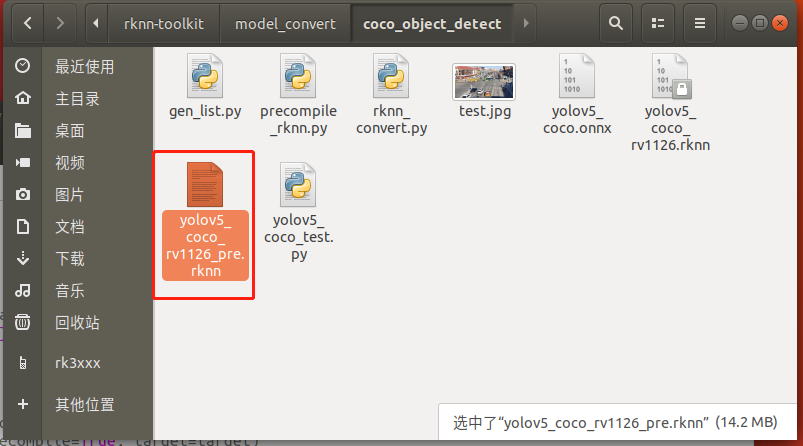
6.3 模型转换API说明
6.3.1 RKNN 初始化及对象释放
在使用 RKNN-Toolkit 的所有 API 接口时,都需要先调用 RKNN()方法初始化 RKNN 对象,并 不再使用该对象时,调用该对象的 release()方法进行释放。
初始化 RKNN 对象时,可以设置 verbose 和 verbose_file 参数,以打印详细的日志信息。其中 verbose 参数指定是否要在屏幕上打印详细日志信息;如果设置了 verbose_file 参数,且 verbose 参 数值为 True,日志信息还将写到该参数指定的文件中。如果出现 Error 级别的错误,而 verbose_file 又被设为 None,则错误日志将自动写到 log_feedback_to_the_rknn_toolkit_dev_team.log 文件中。
反馈错误信息给 Rockchip NPU 团队时,建议反馈完整的错误日志。
举例如下:
# 将详细的日志信息输出到屏幕,并写到 mobilenet_build.log 文件中 rknn = RKNN(verbose=True, verbose_file=’./mobilenet_build.log’) # 只在屏幕打印详细的日志信息 rknn = RKNN(verbose=True) … rknn.release()
6.3.2 RKNN 模型配置
在构建 RKNN 模型之前,需要先对模型进行通道均值、通道顺序、量化类型等的配置,这些 操作可以通过 config 接口进行配置。
| API | config |
| 描述 | 设置模型参数 |
| 参数 | batch_size:批处理大小,默认值为 100。量化时将根据该参数决定每一批次参与运算的数据量,以校正量化结果。如果dataset中的数据量小于batch_size,则该参数值将自动调整为dataset中的数据量。如果量化时出现内存不足的问题,建议将这个值设小一点,例如 8。 |
| mean_values:输入的均值。该参数与 channel_mean_value参数不能同时设置。参数格式是一个列表,列表中包含一个或多个均值子列表,多输入模型对应多个子列表,每个子列表的长度与该输入的通道数一致,例如[[128,128,128]],表示一个输入的三个通道的值减去128。如果 reorder_channel设置成’2 1 0‘,则优先做通道调整,再做减均值。 | |
| std_values:输入的归一化值。该参数与channel_mean_value参数不能同时设置。参数格式是一个列表,列表中包含一个或多个归一化值子列表,多输入模型对应多个子列表,每个子列表的长度与该输入的通道数一致,例如[[128,128,128]],表示设置一个输入的三个通道的值减去均值后再除以128。如果 reorder_channel设置成’2 1 0‘,则优先做通道调整,再减均值和除以归一化值。 | |
| epochs:量化时的迭代次数,每迭代一次,就选择 batch_size 指定数量的图片进行量化校正。默认值为-1,此时 RKNN-Toolkit 会根据dataset中的图片数量自动计算迭代次数以最大化利用数据集中的数据。 | |
| reorder_channel:表示是否需要对图像通道顺序进行调整,只对三通道输入有效。’0 1 2’表示按照输入的通道顺序来推理,比如图片输入时是 RGB,那推理的时候就根据 RGB顺序传给输入层;’2 1 0’表示会对输入做通道转换,比如输入时通道顺序是RGB,推理时会将其转成 BGR,再传给输入层,同样的,输入时通道的顺序为 BGR 的话,会被转成 RGB 后再传给输入层。如果有多个输入,每个输入的参数以“#”进行分 隔,如 ’0 1 2#0 1 2’。该参数的默认值是 None,对于 Caffe 框架的三通道输入模型,表示需要做通道顺序的调整,其他框架的三通道输入模型,默认不做通道顺序调整。 | |
| need_horizontal_merge:是否需要进行水平合并,默认值为 False。如果模型是 inception v1/v3/v4,建议开启该选项,可以提高推理时的性能。 | |
| quantized_dtype:量化类型,目前支持的量化类型有 asymmetric_quantized-u8、dynamic_fixed_point-i8、dynamic_fixed_point-i16,默认值为 asymmetric_quantized-u8。 | |
| quantized_algorithm: 量化参数优化算法。当前版本支持的算法有:normal,mmse和kl_divergence,默认值为normal。其中normal 算法的特点是速度较快。而mmse算 法,因为需要对量化参数进行多次调整,其速度会慢很多,但通常能得到比normal算法更高的精度;kl_divergence所用时间会比 normal多一些,但比 mmse 会少很多,在某些场景下可以得到较好的改善效果。 | |
| mmse_epoch:mmse量化算法的迭代次数,默认值为 3。通常情况下,迭代次数越多,精度往往越高。 | |
| optimization_level:模型优化等级。通过修改模型优化等级,可以关掉部分或全部模型转换过程中使用到的优化规则。该参数的默认值为 3,打开所有优化选项。值为2或1时关闭一部分可能会对部分模型精度产生影响的优化选项,值为0时关闭所有 优化选项。 | |
| target_platform:指定RKNN模型目标运行平台。目前支持RK1806、RK1808、RK3399Pro、RV1109和RV1126。其中基于RK1806、RK1808 或 RK3399Pro生成的RKNN模型可以在这三个平台上通用,基于 RV1109或RV1126生成的RKNN模型可以在这两个平台通用。如果模型要在RK1806、RK1808或RK3399Pro上运行,该参数的值可以是 [“rk1806”], [“rk1808”], [“rk3399pro”]或 [“rk1806”, “rk1808”, “rk3399pro”]等;如果模型要在RV1109 或 RV1126 上运行,该参数的值可以是 [“rv1126”], [“rv1109”]或[“rv1109”, “rv1126”]等。这个参数的值不可以是类似[“rk1808”, “rv1126”]这样的组合,因为这两款芯片互不兼容。如果不填该参数,则默认是 [“rk1808”],生成的RKNN 模型可以在 RK1806、RK1808和RK3399Pro 平台上运行。 该参数的值大小写不敏感。 | |
| quantize_input_node: 开启后无论模型是否量化,均强制对模型的输入节点进行量化。 输入节点被量化的模型,在部署时会有性能优势,rknn_input_set接口的耗时更少。当 RKNN-Toolkit 量化没有按理想情况对输入节点进行量化(仅支持输入为图片的模型)、或用户选择加载深度学习框架已生成的量化模型时可以启用(这种情况下,第一层的quantize_layer会被合并到输入节点)。默认值为 False。 | |
| merge_dequant_layer_and_output_node: 将模型输出节点与上一层的dequantize_layer,合并成一个被量化的输出节点,允许模型在部署时返回 uint8或 float类型的推理结果。此配置仅对加载深度学习框架已生成的量化模型有效。默认为 False。 | |
| 返回值 | 无 |
举例如下:
# model config rknn.config(mean_values=[[103.94, 116.78, 123.68]], std_values=[[58.82, 58.82, 58.82]], reorder_channel=’0 1 2’, need_horizontal_merge=True, target_platform=[‘rk1808’, ‘rk3399pro’]
6.3.3 模型加载
RKNN-Toolkit 目前支持Caffe, Darknet, Keras, MXNet, ONNX, PyTorch, TensorFlow,和TensorFlow Lite等模型的加载转换,这些模型在加载时需调用对应的接口,以下为这些接口的详细 说明。
(1)Caffe 模型加载接口
| API | load_caffe |
| 描述 | 加载 caffe 模型 |
| 参数 | model:caffe 模型文件(.prototxt 后缀文件)所在路径。 |
| proto:caffe模型的格式(可选值为’caffe’或’lstm_caffe’)。为了支持RNN 模型,增加了相关网络层的支持,此时需要设置 caffe 格式为’lstm_caffe’。 | |
| blobs:caffe模型的二进制数据文件(.caffemodel 后缀文件)所在路径。该参数值可以为 None,RKNN-Toolkit将随机生成权重等参数。 | |
| 返回值 | 0:导入成功 |
| -1:导入失败 |
举例如下:
#从当前路径加载 mobilenet_v2 模型 ret = rknn.load_caffe(model=’./mobilenet_v2.prototxt’, proto=’caffe’, blobs=’./mobilenet_v2.caffemodel’)
(2)Darknet 模型加载接口
| API | load_darknet |
| 描述 | 加载 Darknet模型 |
| 参数 | model:Darknet模型文件(.cfg 后缀)所在路径。 |
| weight:权重文件(.weights 后缀)所在路径 | |
| 返回值 | 0:导入成功 |
| -1:导入失败 |
举例如下:
# 从当前目录加载yolov3-tiny模型 ret= rknn.load_darknet(model=‘./yolov3-tiny.cfg’, weight=’./yolov3.weights’)
(3)Keras 模型加载接口
| API | load_keras |
| 描述 | 加载 Keras模型 |
| 参数 | model:Keras模型文件(后缀为.h5)。必填参数。 |
| convert_engine:转换引擎,可以是’Keras’或’tflite’。默认转换引擎为 Keras。可选参数。 | |
| 返回值 | 0:导入成功 |
| -1:导入失败 |
举例如下:
# 从当前目录加载 xception 模型 ret = rknn.load_keras(model=’./xception_v3.h5’)
(4)MXNet 模型加载接口
| API | load_mxnet |
| 描述 | 加载 MXNet模型 |
| 参数 | symbol:MXNet模型的网络结构文件,后缀是json。必填参数。 |
| params:MXnet模型的参数文件,后缀是 params。必填参数。 | |
| input_size_list :每个输入节点对应的图片的尺寸和通道数。例如 [[1,224,224],[ 3,224,224]]表示有两个输入,其中一个输入的 shape是[1,224,224],另外一个输入的 shape 是[3,224,224]。必填参数。 | |
| 返回值 | 0:导入成功 -1:导入失败 |
举例如下:
# 从当前目录加载 resnext50 模型 ret = rknn.load_mxnet(symbol=’resnext50_32x4d-symbol.json’, params=’resnext50_32x4d-4ecf62e2.params’, input_size_list=[[3,224,224]] )
(5)ONNX 模型加载
| API | load_onnx |
| 描述 | 加载ONNX模型 |
| 参数 | model:ONNX模型文件(.onnx 后缀)所在路径。 |
| inputs:指定模型的输入节点,数据类型为列表。例如示例中的 resnet50v2模型,其输入节点是['data']。默认值是 None,此时工具自动从模型中查找输入节点。可选参数。 | |
| input_size_list:每个输入节点对应的数据形状。例如示例中的 resnet50v2模型,其输入节点对应的输入尺寸是[[3, 224, 224]]。可选参数。 注: 1. 填写输入数据形状时不要填 batch 维。如果要批量推理,请使用 build 接口的 rknn_batch_size 参数。 2. 如果指定了 inputs 节点,则该参数必须填写。 | |
| outputs:指定模型的输出节点,数据类型为列表。例如示例中的 resnet50v2模型,其 输出节点是['resnetv24_dense0_fwd']。默认值是 None,此时工具将自动从模型中搜索输出节点。可选参数。 | |
| 返回值 | 0:导入成功 -1:导入失败 |
举例如下:
# 从当前目录加载 resnet50v2 模型 ret = rknn.load_onnx(model = './resnet50v2.onnx', inputs = ['data'], input_size_list = [[3, 224, 224]], outputs=['resnetv24_dense0_fwd'])
(6)PyTorch 模型加载接口
| API | load_pytorch |
| 描述 | 加载 PyTorch模型 |
| 参数 | model:PyTorch模型文件(.pt后缀)所在路径,而且需要是 torchscript格式的模型。 必填参数。 |
| input_size_list :每个输入节点对应的图片的尺寸和通道数。例如 [[1,224,224],[ 3,224,224]]表示有两个输入,其中一个输入的 shape 是[1,224,224],另外一个输入的 shape是[3,224,224]。必填参数。 | |
| 返回值 | 0:导入成功 -1:导入失败 |
举例如下:
# 从当前目录加载 resnet18 模型 ret = rknn. Load_pytorch(model = ‘./resnet18.pt’, input_size_list=[[3,224,224]])
(7)TensorFlow 模型加载接口
| API | load_tensorflow |
| 描述 | 加载TensorFlow模型 |
| 参数 | tf_pb:TensorFlow模型文件(.pb 后缀)所在路径。 |
| inputs:模型输入节点,支持多个输入节点。所有输入节点名放在一个列表中。 | |
| input_size_list:每个输入节点对应的数据形状。如示例中的 mobilenet-v1模型,其输入节点对应的输入尺寸是[[224, 224, 3]]。 | |
| outputs:模型的输出节点,支持多个输出节点。所有输出节点名放在一个列表中。 | |
| predef_file:为了支持一些控制逻辑,需要提供一个npz格式的预定义文件。可以通过以下方法生成预定义文件:np.savez(‘prd.npz’,placeholder_name=prd_value)。如果 “placeholder_name”中包含’/’,请用’#’替换。 | |
| 返回值 | 0:导入成功 |
| -1:导入失败 |
举例如下:
# 从当前目录加载 ssd_mobilenet_v1_coco_2017_11_17 模型 ret = rknn.load_tensorflow( tf_pb=’./ssd_mobilenet_v1_coco_2017_11_17.pb’, inputs=[‘FeatureExtractor/MobilenetV1/MobilenetV1/Conv2d_0 /BatchNorm/batchnorm/mul_1’], outputs=[‘concat’, ‘concat_1’], input_size_list=[[300, 300, 3]])
(8)TensorFlow Lite 模型加载接口
| API | load_tflite |
| 描述 | 加载 TensorFlow Lite 模型。 注:因为tflite不同版本的schema之间是互不兼容的,所以构建的tflite模型使用与RKNNToolkit不同版本的schema可能导致加载失败。目前RKNN-Toolkit使用的tflite schema 是基于官网 master 分支上的提交: 0c4f5dfea4ceb3d7c0b46fc04828420a344f7598。 官网地址如下: https://github.com/tensorflow/tensorflow/commits/master/tensorflow/lite/schema/schema.f bs |
| 参数 | model:TensorFlow Lite 模型文件(.tflite 后缀)所在路径 |
| 返回值 | 0:导入成功 |
| -1:导入失败 |
举例如下:
# 从当前目录加载 mobilenet_v1 模型 ret = rknn.load_tflite(model = ‘./mobilenet_v1.tflite’)
6.3.4 构建 RKNN 模型
| API | build |
| 描述 | 依照加载的模型结构及权重数据,构建对应的 RKNN模型。 |
| 参数 | do_quantization:是否对模型进行量化,值为 True或 False。 |
| ataset:量化校正数据的数据集。目前支持文本文件格式,用户可以把用于校正的图片(jpg或 png格式)或 npy文件路径放到一个.txt 文件中。文本文件里每一行一条路径信息。如: a.jpg b.jpg 或 a.npy b.npy 如有多个输入,则每个输入对应的文件用空格隔开,如: a.jpg a2.jpg b.jpg b2.jpg 或 a.npy a2.npy b.npy b2.npy | |
| pre_compile:模型预编译开关。预编译 RKNN 模型可以减少模型初始化时间,但是无法通过模拟器进行推理或性能评估。如果 NPU 驱动有更新,预编译模型通常也需要重新构建。 注: 1. 该选项只在 Linux x86_64 平台上有效。 2. RKNN-Toolkit-V1.0.0 及以上版本生成的预编译模型不能在 NPU 驱动版本小于0.9.6 的设备上运行;RKNN-Toolkit-V1.0.0 以前版本生成的预编译模型不能在NPU 驱 动 版 本 大 于 等 于 0.9.6 的 设 备 上 运 行 。 驱 动 版 本 号 可 以 通 过get_sdk_version 接口查询。 | |
| rknn_batch_size:模型的输入 Batch 参数调整,默认值为 1。如果大于 1,则可以在一次推理中同时推理多帧输入图像或输入数据,如 MobileNet 模型的原始input 维度为[1, 224, 224, 3],output 维度为[1, 1001],当 rknn_batch_size 设为 4 时,input 的维度变为[4, 224, 224, 3],output 维度变为[4, 1001]。 注: 1. rknn_batch_size 的调整并不会提高一般模型在 NPU 上的执行性能,但却会显著增加内存消耗以及增加单帧的延迟。 2. rknn_batch_size 的调整可以降低超小模型在 CPU 上的消耗,提高超小模型的平均帧率。(适用于模型太小,CPU 的开销大于 NPU 的开销)。 3. rknn_batch_size 的值建议小于 32,避免内存占用太大而导致推理失败。 4. rknn_batch_size 修改后,模型的 input/output 维度会被修改,使用 inference 推理模型时需要设置相应的 input 的大小,后处理时,也需要对返回的 outputs 进行处理。 | |
| 返回值 | 0:构建成功 -1:构建失败 |
注:如果在执行脚本前设置RKNN_DRAW_DATA_DISTRIBUTE 环境变量的值为1,则 RKNN Toolkit会将每一层的weihgt/bias(如果有)和输出数据的直方图保存在当前目录下的 dump_data_distribute文件夹中。使用该功能时推荐只在dataset.txt中存放单独一个(组)输入。
举例如下:
# 构建 RKNN 模型,并且做量化 ret = rknn.build(do_quantization=True, dataset='./dataset.txt')
6.3.5 导出 RKNN 模型
通过该接口导出 RKNN 模型文件,用于模型部署。
| API | export_rknn |
| 描述 | 将 RKNN模型保存到指定文件中(.rknn 后缀)。 |
| 参数 | export_path:导出模型文件的路径。 |
| 返回值 | 0:导入成功 ; |
| -1:导入失败 |
举例如下:
…… # 将构建好的 RKNN 模型保存到当前路径的 mobilenet_v1.rknn 文件中 ret = rknn.export_rknn(export_path = './mobilenet_v1.rknn') ……
6.3.6 加载 RKNN模型
| API | load_rknn |
| 描述 | 加载 RKNN 模型。 |
| 参数 | path:RKNN模型文件路径。 |
| load_model_in_npu:是否直接加载npu中的rknn模型。其中path为rknn 模型在npu中的路径。只有当RKNN-Toolkit运行在RK3399Pro Linux 开发板或连有 NPU 设备 的 PC 上时才可以设为 True。默认值为 False。 | |
| 返回值 | 0:导入成功 |
| -1:导入失败 |
举例如下:
# 从当前路径加载 mobilenet_v1.rknn 模型 ret = rknn.load_rknn(path='./mobilenet_v1.rknn')
6.3.7 初始化运行时环境
在模型推理或性能评估之前,必须先初始化运行时环境,明确模型在的运行平台(具体的目标硬件平台或软件模拟器)。
| API | init_runtime |
| 描述 | 初始化运行时环境。确定模型运行的设备信息(硬件平台信息、设备 ID);性能评估时是否启用debug 模式,以获取更详细的性能信息。 |
| 参数 | target:目标硬件平台,目前支持“rk3399pro”、“rk1806”、“rk1808”、“rv1109”、 “rv1126”。默认为 None,即在 PC 使用工具时,模型在模拟器上运行,在RK3399Pro Linux 开发板运行时,模型在RK3399Pro自带NPU上运行,否则在设定的target上 运行。其中“rk1808”包含了TB-RK1808 AI 计算棒。 |
| device_id:设备编号,如果PC连接多台设备时,需要指定该参数,设备编号可以通过”list_devices”接口查看。默认值为 None。 注:MAC OS X 系统当前版本还不支持多个设备。 | |
| perf_debug:进行性能评估时是否开启debug 模式。在 debug 模式下,可以获取到每一层的运行时间,否则只能获取模型运行的总时间。默认值为 False。 | |
| eval_mem: 是否进入内存评估模式。进入内存评估模式后,可以调用 eval_memory 接口获取模型运行时的内存使用情况。默认值为 False。 | |
| async_mode:是否使用异步模式。调用推理接口时,涉及设置输入图片、模型推理、获取推理结果三个阶段。如果开启了异步模式,设置当前帧的输入将与推理上一帧同时进行,所以除第一帧外,之后的每一帧都可以隐藏设置输入的时间,从而提升性能。 在异步模式下,每次返回的推理结果都是上一帧的。该参数的默认值为 False。 | |
| 返回值 | 0:构建成功 |
| -1:构建失败 |
举例如下:
# 初始化运行时环境 ret = rknn.init_runtime(target='rk1808', device_id='012345789AB') if ret != 0: print('Init runtime environment failed') exit(ret)
6.3.8 模型推理
在进行模型推理前,必须先构建或加载一个 RKNN 模型。
| API | inference |
| 描述 | 对当前模型进行推理,返回推理结果。 如果 RKNN-Toolkit运行在PC上,且初始化运行环境时设置 target 为Rockchip NPU设备,得到的是模型在硬件平台上的推理结果。 如果 RKNN-Toolkit 运行在PC上,且初始化运行环境时没有设置 target,得到的是模型在模拟器上的推理结果。模拟器可以模拟 RK1808,也可以模拟RV1126,具体模拟哪款芯片,取决于RKNN 模型的 target_platform 参数值。 如果 RKNN-Toolkit运行在 RK3399Pro Linux开发板上,得到的是模型在实际硬件上的推理结果。 |
| 参数 | inputs:待推理的输入,如经过 cv2 处理的图片。格式是 ndarray list。 |
| data_type:输入数据的类型,可填以下值:’float32’, ‘float16’, ‘int8’, ‘uint8’, ‘int16’。默认值为’uint8’。 | |
| data_format:数据模式,可以填以下值: “nchw”, “nhwc”。默认值为’nhwc’。这两个的 不同之处在于 channel 放置的位置。 | |
| inputs_pass_through:将输入透传给NPU 驱动。非透传模式下,在将输入传给NPU驱动之前,工具会对输入进行减均值、除方差等操作;而透传模式下,不会做这些操作。这个参数的值是一个数组,比如要透传input0,不透彻input1,则这个参数的值为[1, 0]。默认值为None,即对所有输入都不透传。 | |
| 返回值 | results:推理结果,类型是 ndarray list。 |
对于分类模型,如mobilenet_v1,模型推理代码如下(完整代码参考 example/tflite/mobilent_v1):
# 使用模型对图片进行推理,输出 TOP5 …… outputs = rknn.inference(inputs=[img]) show_outputs(outputs) ……
输出的 TOP5 结果如下:
-----TOP 5----- [156]: 0.85107421875 [155]: 0.09173583984375 [205]: 0.01358795166015625 [284]: 0.006465911865234375 [194]: 0.002239227294921875
6.3.9 模型性能评估
| API | eval_perf |
| 描述 | 评估模型性能。模型运行在PC上,初始化运行环境时不指定 target,得到的是模型在模拟器上运行的性能数据,包含逐层的运行时间及模型完整运行一次需要的时间。模拟器可以模拟 RK1808,也可以模拟 RV1126,具体模拟哪款芯片,取决于RKNN模型的target_platform参数值。 模型运行在与PC连接的Rockchip NPU上,且初始化运行环境时设置perf_debug为False,则获得的是模型在硬件上运行的总时间;如果设置perf_debug为 True,除了返回总时间外,还将返回每一层的耗时情况。模型运行在RK3399Pro Linux开发板上时,如果初始化运行环境时设置perf_debug为False,获得的也是模型在硬件上运行的总时间;如果设置perf_debug为 True,返回总时间及每一层的耗时情况。 |
| 参数 | loop_cnt::指定RKNN模型推理次数,用于计算平均推理时间。该参数只在init_runtime中的 target为非模拟器,且perf_debug设成 False时生效。该参数数据类型为整型,默认值为 1。 |
| 返回值 | perf_result:性能评估结果,详细说明请参考 5.3 章节。 |
举例如下:
# 对模型性能进行评估 …… rknn.eval_perf(inputs=[image], is_print=True) ……
6.3.10 获取内存使用情况
| API | eval_memory |
| 描述 | 获取模型在硬件平台运行时的内存使用情况。 模型必须运行在与 PC 连接的 Rockchip NPU 设备上,或直接运行在 RK3399Pro Linux 开发板上。 注: 1. 使用该功能时,对应的驱动版本必须要大于等于 0.9.4。驱动版本可以通过 get_sdk_version 接口查询。 |
| 参数 | is_print: 是否以规范格式打印内存使用情况。默认值为 True。 |
| 返回值 |
|
举例如下:
# 对模型内存使用情况进行评估 …… memory_detail = rknn.eval_memory() ……
如 example/tflite 中的 mobilenet_v1,它在 RK1808 上运行时内存占用情况如下:
============================================== Memory Profile Info Dump ============================================== System memory: maximum allocation : 22.65 MiB total allocation : 72.06 MiB NPU memory: maximum allocation : 33.26 MiB total allocation : 34.57 MiB Total memory: maximum allocation : 55.92 MiB total allocation : 106.63 MiB INFO: When evaluating memory usage, we need consider the size of model, current model size is: 4.10 MiB ==============================================
6.3.11 混合量化
(1)hybrid_quantization_step1
使用混合量化功能时,第一阶段调用的主要接口是 hybrid_quantization_step1,用于生成模型结构文件( {model_name}.json )、权重文件( {model_name}.data ) 和量化配置文件({model_name}.quantization.cfg)。接口详情如下:
| API | hybrid_quantization_step1 |
| 描述 | 根据加载的原始模型,生成对应的模型结构文件、权重文件和量化配置文件。 |
| 参数 | dataset::量化校正数据的数据集。目前支持文本文件格式,用户可以把用于校正的图片(jpg或 png格式)或npy文件路径放到一个.txt 文件中。文本文件里每一行一条路径信息。 如: a.jpg b.jpg 或 a.npy b.npy |
| 返回值 | 0:成功 -1:失败 |
举例如下:
# Call hybrid_quantization_step1 to generate quantization config …… ret = rknn.hybrid_quantization_step1(dataset='./dataset.txt') ……
(2)hybrid_quantization_step2
使用混合量化功能时,生成混合量化 RKNN模型阶段调用的主要接口是 hybrid_quantization_step2。接口详情如下:
| API | hybrid_quantization_step2 |
| 描述 | 接收模型结构文件、权重文件、量化配置文件、校正数据集作为输入,生成混合量化后的 RKNN 模型。 |
| 参数 | model_input:第一步生成的模型结构文件,例如“{model_name}.json”。数据类型为字符串。必填参数。 |
| data_input:第一步生成的权重数据文件,例如“{model_name}.data”。数据类型为字符串。必填参数。 | |
| dataset:量化校正数据的数据集。目前支持文本文件格式,用户可以把用于校正的图片(jpg 或 png 格式)或 npy 文件路径放到一个.txt 文件中。文本文件里每一行一条路径信息。 如: a.jpg b.jpg 或 a.npy b.npy | |
| pre_compile:模型预编译开关。预编译 RKNN模型可以减少模型初始化时间,但是无法通过模拟器进行推理或性能评估。如果 NPU 驱动有更新,预编译模型通常也需要重新构建。 注: 1. 该选项不能在 RK3399Pro Linux 开发板/Windows PC/Mac OS X PC 上使用。 2. RKNN-Toolkit-V1.0.0及以上版本生成的预编译模型不能在 NPU 驱动版本小于0.9.6 的设备上运行;RKNN-Toolkit-V1.0.0 以前版本生成的预编译模型不能在NPU驱动版本大于等于 0.9.6 的设备上运行。驱动版本号可以通过get_sdk_version 接口查询。 | |
| 返回值 | 0:成功 |
| -1:失败 |
举例如下:
# Call hybrid_quantization_step2 to generate hybrid quantized RKNN model …… ret = rknn.hybrid_quantization_step2( model_input='./ssd_mobilenet_v2.json', data_input='./ssd_mobilenet_v2.data', model_quantization_cfg='./ssd_mobilenet_v2.quantization.cfg', dataset='./dataset.txt') ……
6.3.12 量化精度分析
| API | accuracy_analysis |
| 描述 | 逐层对比浮点模型和量化模型的输出结果,输出余弦距离和欧式距离,用于分析量化模型精度下降原因。 注: 1.该接口在build或hybrid_quantization_step1或 hybrid_quantization_step2之后调用,并且原始模型应该为浮点模型,否则会调用失败。 2. 该接口使用的量化方式与 config 中指定的一致。 |
| inputs:包含输入图像或数据的数据集文本文件(与量化校正数据集 dataset 格式相同, 但只能包含一组输入)。 | |
| output_dir:输出目录,所有快照都保存在该目录。该目录内容的详细说明见 4.3.3 章 节。 | |
| calc_qnt_error:是否计算量化误差(默认为 True)。 | |
| target:指定设备类型。如果指定 target,在逐层量化误差分析时,将连接到 NPU上获取每一层的真实结果,跟浮点模型结果相比较。这样可以更准确的反映实际运行时的误差。 | |
| device_id:如果 PC 连接了多个NPU设备,需要指定具体的设备编号。 | |
| dump_file_type:精度分析过程中会输出模型每一层的结果,这个参数指定了输出文件的类型。有效值为’tensor’和’npy’,默认值是’tensor’。如果指定数据类型为’npy’, 可以减少精度分析的耗时。 | |
| 返回值 | 0:成功 |
| -1:失败 |
注:如果在执行脚本前设置 RKNN_DRAW_DATA_DISTRIBUTE 环境变量的值为 1,则 RKNNToolkit 会将每一层的 weihgt/bias(如果有)和输出数据的直方图保存在当前目录下的 dump_data_distribute 文件夹中。
举例如下:
…… print('--> config model') rknn.config(channel_mean_value='0 0 0 1', reorder_channel='0 1 2') print('done') print('--> Loading model') ret = rknn.load_onnx(model='./mobilenetv2-1.0.onnx') if ret != 0: print('Load model failed! Ret = {}'.format(ret)) exit(ret) print('done') # Build model print('--> Building model') ret = rknn.build(do_quantization=True, dataset='./dataset.txt') if ret != 0: print('Build rknn failed!') exit(ret) print('done') print('--> Accuracy analysis') rknn.accuracy_analysis(inputs='./dataset.txt', target='rk1808') print('done') ……
6.3.13 注册自定义算子
| API | register_op |
| 描述 | 注册自定义算子。 |
| 参数 | op_path:算子编译生成的 rknnop 文件的路径 |
| 返回值 | 无 |
参考代码如下所示。注意,该接口要在模型转换前调用。自定义算子的使用和开发请参考 《Rockchip_Developer_Guide_RKNN_Toolkit_Custom_OP_CN》文档。
rknn.register_op('./resize_area/ResizeArea.rknnop') rknn.load_tensorflow(…)
6.3.14 导出预编译模型(在线预编译)
构建RKNN模型时,可以指定预编译选项以导出预编译模型,这被称为离线编译。同样,RKNN Toolkit 也提供在线编译的接口:export_rknn_precompile_model。使用该接口,可以将普通 RKNN 模型转成预编译模型。
| API | export_rknn_precompile_model |
| 描述 | 经过在线编译后导出预编译模型。 注: 1. 使用该接口前必须先调用 load_rknn 接口加载普通 rknn 模型; 2. 使用该接口前必须调用 init_runtime 接口初始化模型运行环境,target 必须是RK NPU 设备,不能是模拟器;而且要设置 rknn2precompile 参数为 True。 |
| 参数 | export_path:导出模型路径。必填参数。 |
| 返回值 | 0:成功 -1:失败 |
举例如下:
from rknn.api import RKNN if __name__ == '__main__': # Create RKNN object rknn = RKNN() # Load rknn model ret = rknn.load_rknn('./test.rknn') if ret != 0: print('Load RKNN model failed.') exit(ret) # init runtime ret = rknn.init_runtime(target='rk1808', rknn2precompile=True) if ret != 0: print('Init runtime failed.') exit(ret) # Note: the rknn2precompile must be set True when call init_runtime ret = rknn.export_rknn_precompile_model('./test_pre_compile.rknn') if ret != 0: print('export pre-compile model failed.') exit(ret) rknn.release()
6.3.15 导出分段模型
该接口的功能是将普通的 RKNN 模型转成分段模型,分段的位置由用户指定。
| API | export_rknn_sync_model |
| 描述 | 在用户指定的模型层后面插入sync层,用于将模型分段,并导出分段后的模型。 |
| 参数 | input_model: 待分段的rknn模型路径。数据类型为字符串。必填参数。 |
| sync_uids: 待插入 sync 节点层的层uid列表,RKNN-Toolkit 将在这些层后面插入sync层。 注: 1. uid 只能通过 eval_perf 接口获取,且需要在 init_runtime 时设置 perf_debug 为True,target 不能是模拟器。 2. uid 的值不可以随意填写,一定需要是在 eval_perf 获取性能详情的 uid 列表中,否则可能出现不可预知的结果。 | |
| output_model:导出模型的保存路径。数据类型:字符串。默认值为 None,如果不填该参数,导出的模型将保存在 input_model 指定的文件中。 | |
| 返回值 | 0:成功 |
| -1:失败 |
举例如下:
from rknn.api import RKNN if __name__ == '__main__': rknn = RKNN() ret = rknn.export_rknn_sync_model( input_model='./ssd_inception_v2.rknn', sync_uids=[206, 186, 152, 101, 96, 67, 18, 17], output_model='./ssd_inception_v2_sync.rknn') if ret != 0: print('export sync model failed.') exit(ret) rknn.release()
6.3.16 导出加密模型
该接口的功能是将普通的 RKNN 模型进行加密,得到加密后的模型。
| API | export_encrypted_rknn_model |
| 描述 | 根据用户指定的加密等级对普通的 RKNN 模型进行加密。 |
| 参数 | input_model:待加密的RKNN模型路径。数据类型为字符串。必填参数。 |
| output_model:模型加密后的保存路径。数据类型为字符串。选填参数,如果不填该参数,则使用{original_model_name}.crypt.rknn作为加密后的模型的名字。 | |
| crypt_level:加密等级。等级越高,安全性越高,解密越耗时;反之,安全性越低,解密越快。数据类型为整型,默认值为 1,目前安全等级有 3 个等级,1,2 和 3。 | |
| 返回值 | 0:成功 |
| -1:失败 |
举例如下:
from rknn.api import RKNN if __name__ == '__main__': rknn = RKNN() ret = rknn.export_encrypted_rknn_model('test.rknn') if ret != 0: print('Encrypt RKNN model failed.') exit(ret) rknn.release()
6.3.17 查询 SDK 版本
| API | get_sdk_version |
| 描述 | 获取 SDK API 和驱动的版本号。 注:使用该接口前必须完成模型加载和初始化运行环境。且该接口只有在target是 Rockchip NPU 或 RKNN-Toolkit 运行在 RK3399Pro Linux 开发板才可以使用。 |
| 参数 | 无 |
| 返回值 | sdk_version:API 和驱动版本信息。类型为字符串。 |
举例如下:
# 获取 SDK 版本信息 …… sdk_version = rknn.get_sdk_version() ……
返回的 SDK 信息如下:
============================================== RKNN VERSION: API: 1.7.1 (566a9b6 build: 2021-10-28 14:53:41) DRV: 1.7.1 (566a9b6 build: 2021-11-12 20:24:57) ==============================================
6.3.18 获取设备列表
| API | list_devices |
| 描述 | 列出已连接的RK3399PRO/RK1808/RV1109/RV1126或TB-RK1808 AI 计算棒。 注:目前设备连接模式有两种:ADB 和 NTB。其中RK3399PRO 目前只支持ADB 模 式,TB-RK1808 AI计算棒只支持NTB模式,RK1808/RV1109 支持 ADB/NTB 模式。多设备连接时请确保他们的模式都是一样的。 |
| 参数 | 无 |
| 返回值 | 返回adb_devices列表和ntb_devices 列表,如果设备为空,则返回空列表。例如我们的环境里插了两个 TB-RK1808 AI 计算棒,得到的结果如下: adb_devices = [] ntb_devices = ['TB-RK1808S0', '515e9b401c060c0b'] |
举例如下:
from rknn.api import RKNN if __name__ == '__main__': rknn = RKNN() rknn.list_devices() rknn.release()
返回的设备列表信息如下(这里有两个 RK1808 开发板,它们的连接模式都是 adb):
************************* all device(s) with adb mode: ['515e9b401c060c0b', 'XGOR2N4EZR'] *************************
注:使用多设备时,需要保证它们的连接模式都是一致的,否则会引起冲突,导致设备通信失败。
6.3.19 查询模型可运行平台
| API | list_support_target_platform |
| 描述 | 查询给定 RKNN 模型可运行的芯片平台。 |
| 参数 | rknn_model:RKNN模型路径。如果不指定模型路径,则按类别打印 RKNN-Toolkit 当前支持的芯片平台。 |
| 返回值 | support_target_platform: Returns runnable chip platforms, or None if the model path is empty. |
参考代码如下所示:
rknn.list_support_target_platform(rknn_model=’mobilenet_v1.rknn’)
参考结果如下:
************************************************** Target platforms filled in RKNN model: [] Target platforms supported by this RKNN model: ['RK1806', 'RK1808', 'RK3399PRO'] **************************************************
7. 模型部署
模型转换为rknn模型后,需再参考NPU API说明文档,编写应用工程。经过编译后传输至EASY EAI Nano平台上实现部署。
7.1 模型部署示例
7.1.1 模型部署示例介绍
本小节展示yolov5模型的在EASY EAI Nano的部署过程,该模型仅经过简单训练供示例使用,不保证模型精度。
7.1.2 准备工作
(1)硬件准备
EASY EAI Nano开发板,microUSB数据线,带linux操作系统的电脑。需保证EASY EAI Nano与linux系统保持adb连接。
(2)开发环境准备
如果您初次阅读此文档,请阅读《入门指南/开发环境准备/Easy-Eai编译环境准备与更新》,并按照其相关的操作,进行编译环境的部署。
在PC端Ubuntu系统中执行run脚本,进入EASY-EAI编译环境,具体如下所示。
cd ~/develop_environment ./run.sh
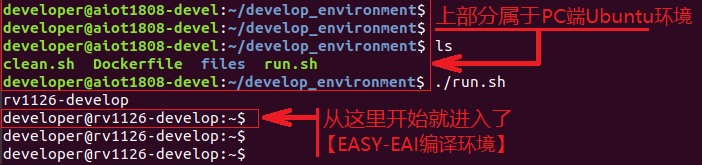
7.1.3 源码下载以及例程编译
下载yolov5 C Demo示例文件。
百度网盘链接:https://pan.baidu.com/s/1xmEgBGQCMrvHm9kfU9uBkg (提取码:lanz )。
下载解压后如下图所示:
在EASY-EAI编译环境下,切换到例程目录执行编译操作:
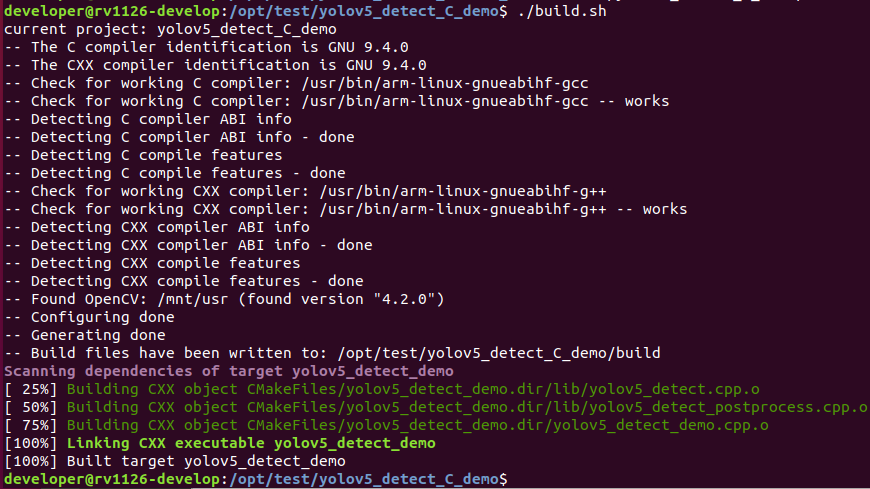
cd /opt/test/yolov5_detect_C_demo ./build.sh
注:
* 由于依赖库部署在板卡上,因此交叉编译过程中必须保持adb连接。
7.1.4 在开发板执行yolov5 demo
在EASY-EAI编译环境下,在例程目录执行以下指令把可执行程序推送到开发板端:
cp yolov5_detect_demo_release/ /mnt/userdata/ -rf
通过按键Ctrl+Shift+T创建一个新窗口,执行adb shell命令,进入板卡运行环境:
adb shell
进入板卡后,定位到例程上传的位置,如下所示:
cd /userdata/yolov5_detect_demo_release/
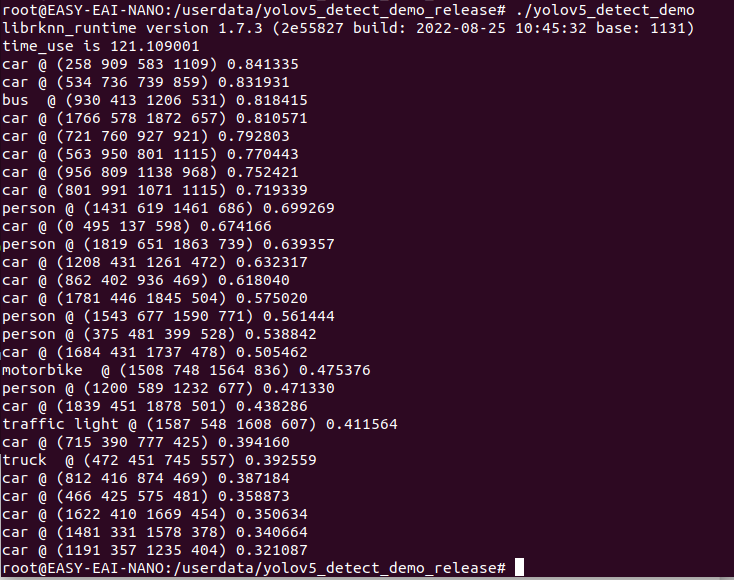
运行例程命令如下所示:
./yolov5_detect_demo
执行结果如下图所示:
退出板卡环境,取回测试图片:
exit adb pull /userdata/yolov5_detect_demo_release/result.jpg .
测试结果如下图所示:
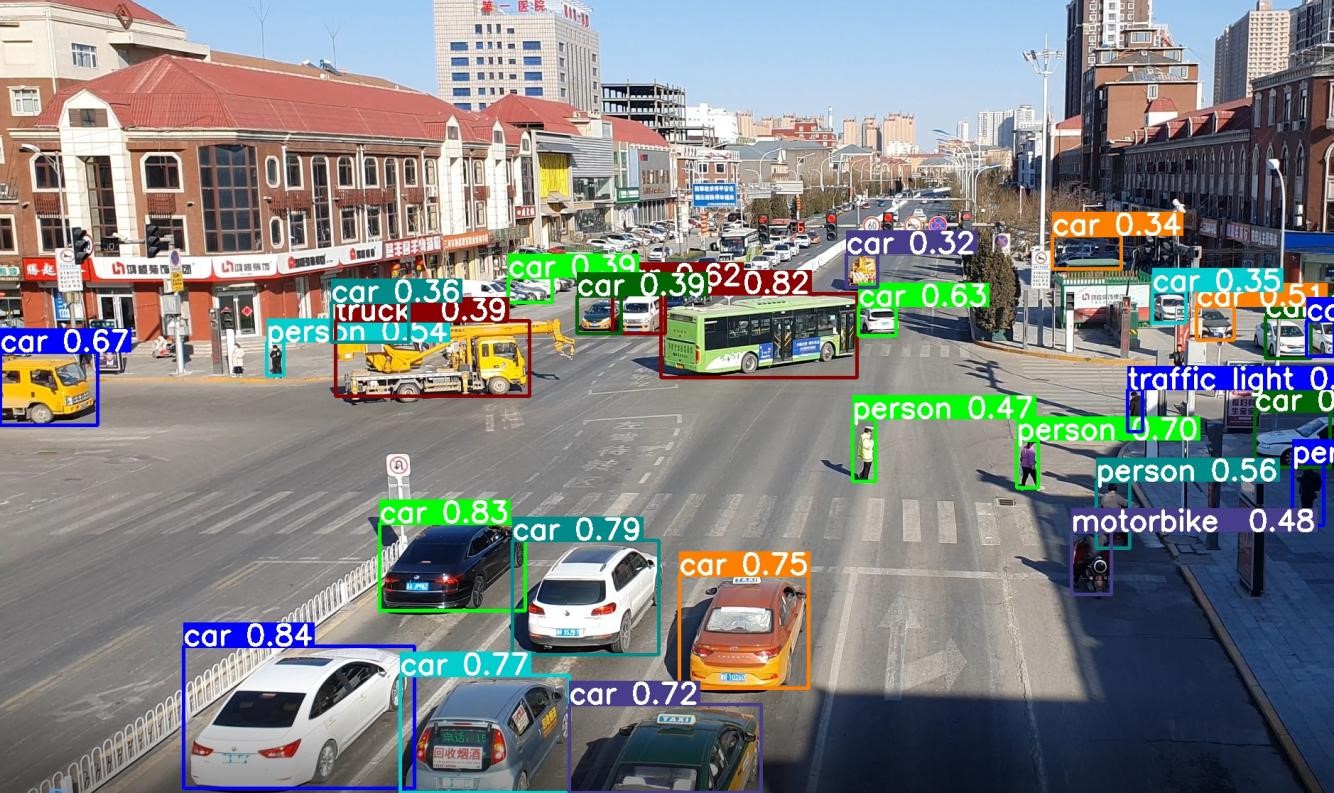
7.2 模型部署API说明
7.2.1 API流程说明
从 RKNN API V1.6.0 版本开始,新增加了一组设置输入的函数:
- rknn_inputs_map
- rknn_inputs_sync
- rknn_inputs_unmap
以及一组获取输出的函数:
- rknn_outputs_map
- rknn_outputs_sync
- rknn_outputs_unmap
在设置输入时,用户可以使用 rknn_inputs_set 或者 rknn_inputs_map 系列函数。获取推理的输出时,使用 rknn_outputs_get 或者 rknn_outputs_map 系列函数。特定场景下,使用 map 系列接口可以减少内存拷贝的次数,提高完整推理的速度。
rknn_inputs_map 系列接口和 rknn_inputs_set 接口的调用流程不同 rknn_outputs_map 系列接口和rknn_outputs_get 接口的调用流程也不同。两个系列API调用流程差异如下图所示,其中图 1.1(a)为set/get系列接口调用流程,图 1.1(b)为map系列接口调用流程。
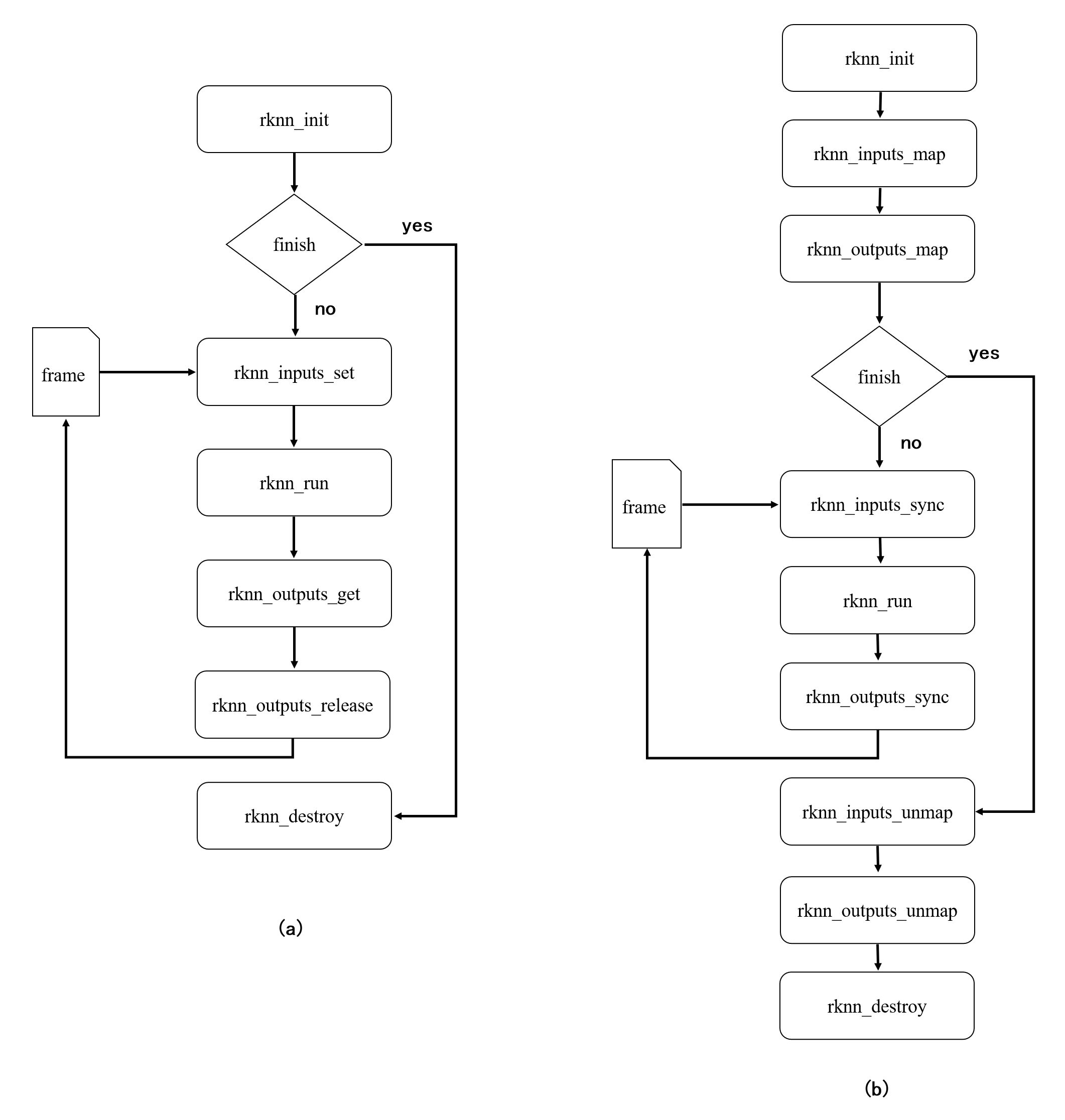
图 1.1 使用 set/get 系列(a)和 map 系列(b)接口流
设置输入和获取输出接口没有绑定关系,因此可以混合使用 set/get 系列接口和 map 系列接口。如图 1.2(a),用户可以使用 rknn_inputs_map 系列接口设置输入,再通过rknn_outputs_get 接口获取输出,或者如图 1.2(b)通过 rknn_inputs_set 系列接口设置 输入,再使用 rknn_outputs_map 接口获取输出。
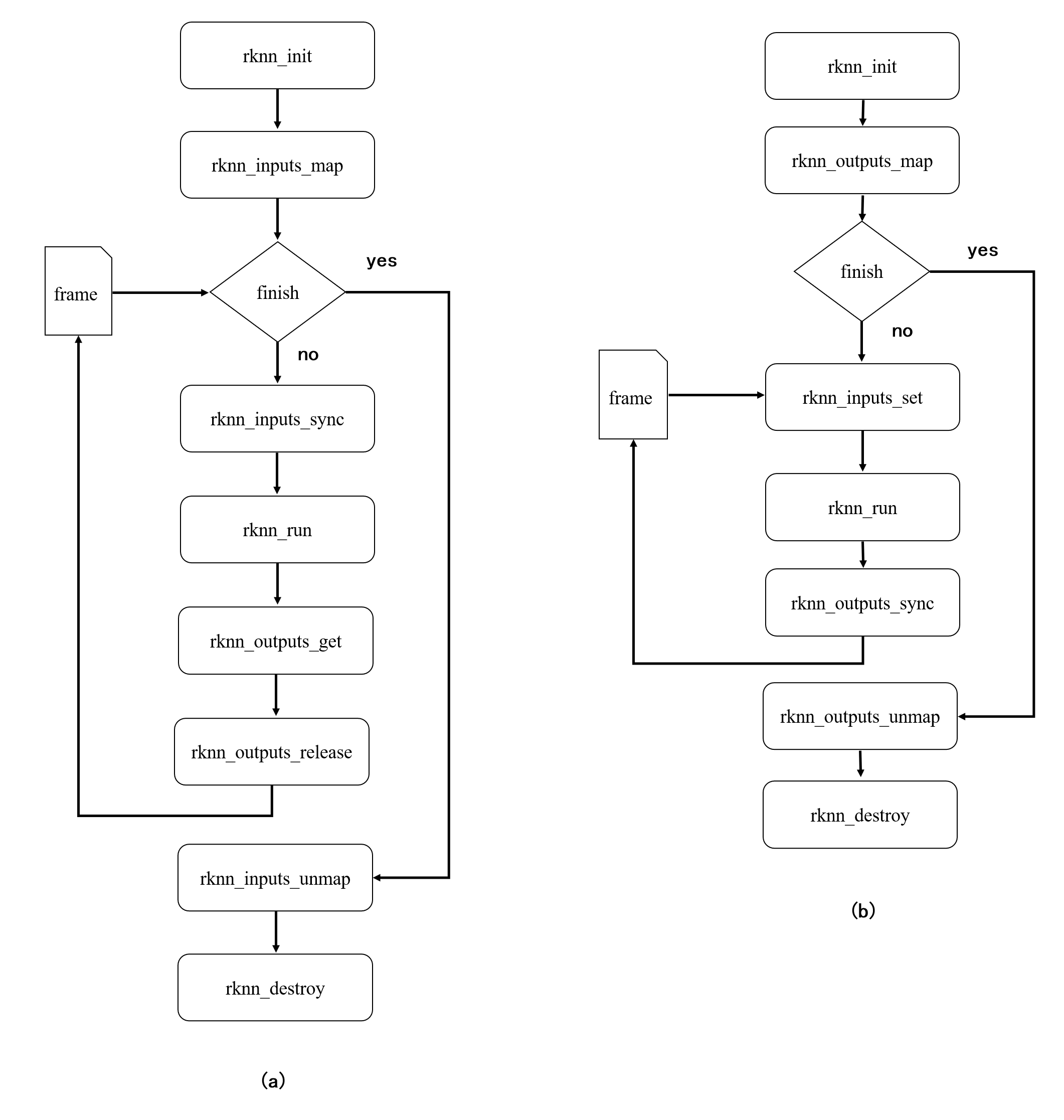
图 1.2 混合使用 set/get 系列和 map 系列接口的调用流程
(1)API内部处理流程
在推理 RKNN 模型时,原始数据要经过输入处理、NPU 运行模型、输出处理三大流程。
在典型的图片推理场景中,假设输入数据 data 是 3 通道的图片且为 NHWC 排布格式,运行时(Runtime)对数据处理的流程如图 1.3所示。在 API 层面上,rknn_inputs_set 接口(当 pass_through=0 时,详见 rknn_input 结构体)包含了颜色通道交换、归一化、量化、NHWC 转换成 NCHW 的过程,rknn_outputs_get 接口(当want_float=1时,详见 rknn_output 结构体)包含了反量化的过程。

图 1.3 完整的图片数据处理流
(2)量化和反量化
当使用rknn_inputs_set(pass_through=1)和 rknn_inputs_map 时,表明在 NPU 推理之前的流程要用户处理。rknn_outputs_map获取输出后,用户也要做反量化得到 32位浮点结果。
量化和反量化用到的量化方式、量化数据类型以及量化参数,可以通过 rknn_query 接口查询。目前,RK1808/RK3399Pro/RV1109/RV1126 (EASY EAI Nano为RV1126)的NPU有非对称量化和动态定点 量化两种量化方式,每种量化方式指定相应的量化数据类型。总共有以下四种数据类型和量化方式组合:
- uint8(非对称量化)
- int8(动态定点)
- int16(动态定点)
- float16(无)
通常,归一化后的数据用 32 位浮点数保存,32 位浮点转换成 16 位浮点数请参考 IEEE-754标准。假设归一化后的32位浮点数据是D,下面介绍量化流程:
(2.1)float32 转 uint8
假设输入tensor的非对称量化参数是
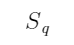
,ZP ,数据D量化过程表示为下式:
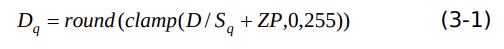
上式中,clamp表示将数值限制在某个范围。round表示做舍入处理。
(2.2)float32 转 int8
假设输入tensor的动态定点量化参数是fl,数据 D 量化过程表示为下式:
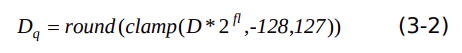
(2.3)float32 转 int16
假设输入tensor的动态定点量化参数是fl,数据D量化过程表示为下式:
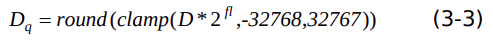
反量化流程是量化的逆过程,可以根据上述量化公式反推出反量化公式,这里不做赘述。
(3)零拷贝
在特定的条件下,可以把输入数据拷贝次数减少到零,即零拷贝。比如,当RKNN模型是非对称量化,量化数据类型是uint8,3通道的均值是相同的整数同时缩放因子相同的情况下,归一化和量化可以省略。证明如下:
假设输入图像数据是D(f),量化参数是S(q),ZP 。M(i)表示第 i 通道的均值, S(i)表示第 i 通道的归一化因子。则第i通道归一化后的数据 如下式子:
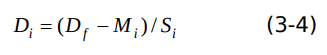
数据D(i) 量化过程表示为下式:
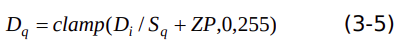
上述两个式子合并后,可以得出
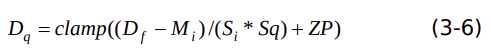
假设量化图片矫正集数据范围包含0到 255的整数值,当 M1=M2 =M3 ,S1 =S2 =S3 时, 归一化数值范围表示如下:
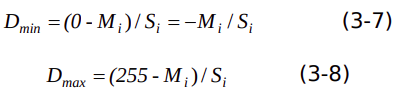
因此,量化参数计算如下:
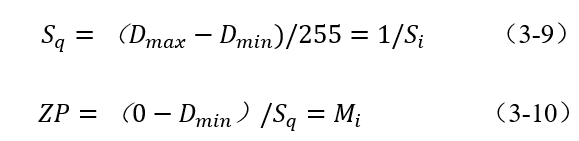
把式(3-9)和式(3-10)代入式(3-6),可以得出
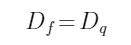
,即符合零拷贝的条件下:3 通道的均值是相同的整数同时归一化的缩放因子相同,输入uint8 数据等于量化后的uint8数据。
输入零拷贝能降低 CPU 负载,提高整体的推理速度。针对 RGB 或 BGR 输入数据,实现 输入零拷贝的步骤如下:
1)三个通道的均值是相同的整数同时归一化的缩放因子相同。
2)在 rknn-toolkit 的 config 函数中,设置 force_builtin_perm=True,导出 NHWC输入的 RKNN 模型。
3)使用 rknn_inputs_map 接口,获取输入 tensor 内存地址信息。
4)往内存地址填充输入数据,比如调用 RGA 缩放函数,目标地址使用 rknn_inputs_map获取的物理地址。
5)调用 rknn_inputs_sync 接口。
6)调用 rknn_run 接口。
7)调用获取输出接口。
7.2.2 API详细说明
(1)rknn_init
rknn_init初始化函数将创建 rknn_context 对象、加载 RKNN 模型以及根据 flag执行 特定的初始化行为。
| API | rknn_init |
| 功能 | 初始化 rknn |
| 参数 | rknn_context *context:rknn_context指针。函数调用之后,context 将会被赋值。 |
| void *model:RKNN 模型的二进制数据。 | |
| uint32_t size:模型大小。 | |
| uint32_t flag:特定的初始化标志。目前 RK1808 平台仅支持以下标志: RKNN_FLAG_COLLECT_PERF_MASK:打开性能收集调试开关,打开之后能够通过rknn_query 接口查询网络每层运行时间。需要注意,该标志被设置后rknn_run的运行时间将会变长。 | |
| 返回值 | int错误码(见rknn 返回值错误码)。 |
示例代码如下:
rknn_context ctx; int ret = rknn_init(&ctx, model_data, model_data_size, 0);
(2)rknn_destroy
rknn_destroy 函数将释放传入的 rknn_context及其相关资源。
| API | rknn_destroy |
| 功能 | 销毁 rknn_context 对象及其相关资源。 |
| 参数 | rknn_context context:要销毁的 rknn_context 对象。 |
| 返回值 | int 错误码(见 rknn 返回值错误码)。 |
示例代码如下:
int ret = rknn_destroy (ctx);
(3)rknn_query
rknn_query 函数能够查询获取到模型输入输出、运行时间以及 SDK 版本等信息。
| API | rknn_query |
| 功能 | 查询模型与 SDK 的相关信息。 |
| 参数 | rknn_context context:rknn_context 对象。 |
| rknn_query_cmd cmd:查询命令。 | |
| void* info:存放返回结果的结构体变量。 | |
| uint32_t size:info 对应的结构体变量的大小。 | |
| 返回值 | int 错误码(见 rknn 返回值错误码) |
当前 SDK 支持的查询命令如下表所示:
| 查询命令 | 返回结果结构体 | 功能 |
| RKNN_QUERY_IN_OUT_N UM | rknn_input_output_num | 查询输入输出 Tensor 个数 |
| RKNN_QUERY_INPUT_ATT R | rknn_tensor_attr | 查询输入 Tensor 属性 |
| RKNN_QUERY_OUTPUT_A TTR | rknn_tensor_attr | 查询输出 Tensor 属性 |
| RKNN_QUERY_PERF_DET AIL | rknn_perf_detail | 查询网络各层运行时间 |
| RKNN_QUERY_SDK_VERSI ON | rknn_sdk_version | 查询 SDK 版 |
接下来的将依次详解各个查询命令如何使用。
(3.1)查询输入输出 Tensor 个数
传入 RKNN_QUERY_IN_OUT_NUM 命令可以查询模型输入输出 Tensor 的个数。其中 需要先创建rknn_input_output_num 结构体对象。
示例代码如下:
rknn_input_output_num io_num; ret = rknn_query(ctx, RKNN_QUERY_IN_OUT_NUM, &io_num, sizeof(io_num)); printf("model input num: %d, output num: %d\n", io_num.n_input, io_num.n_output);
(3.2)查询输入 Tensor 属性
传入 RKNN_QUERY_INPUT_ATTR 命令可以查询模型输入 Tensor 的属性。其中需要先 创建 rknn_tensor_attr 结构体对象。
示例代码如下:
rknn_tensor_attr input_attrs[io_num.n_input]; memset(input_attrs, 0, sizeof(input_attrs)); for (int i = 0; i < io_num.n_input; i++) { input_attrs[i].index = i; ret = rknn_query(ctx, RKNN_QUERY_INPUT_ATTR, &(input_attrs[i]), sizeof(rknn_tensor_attr)); }
(3.3)查询输出 Tensor 属性
传入RKNN_QUERY_OUTPUT_ATTR命令可以查询模型输出Tensor的属性。其中需要先创建rknn_tensor_attr 结构体对象。
示例代码如下:
rknn_tensor_attr output_attrs[io_num.n_output]; memset(output_attrs, 0, sizeof(output_attrs)); for (int i = 0; i < io_num.n_output; i++) { output_attrs[i].index = i; ret = rknn_query(ctx, RKNN_QUERY_OUTPUT_ATTR, &(output_attrs[i]), sizeof(rknn_tensor_attr)); }
(3.4)查询网络各层运行时间
如果在rknn_init函数调用时有设置RKNN_FLAG_COLLECT_PERF_MASK标志,那么 在执行rknn_run完成之后,可以传入RKNN_QUERY_PERF_DETAIL命令来查询网络每层 运行时间。其中需要先创建rknn_perf_detail结构体对象。
示例代码如下:
rknn_perf_detail perf_detail; ret = rknn_query(ctx, RKNN_QUERY_PERF_DETAIL, &perf_detail, sizeof(rknn_perf_detail)); printf("%s", perf_detail.perf_data);
注意,用户不需要释放rknn_perf_detail中的perf_data,SDK会自动管理该Buffer内存。
(3.5)查询 SDK 版本
传入RKNN_QUERY_SDK_VERSION命令可以查询RKNN SDK的版本信息。其中需要先创建rknn_sdk_version结构体对象。
示例代码如下:
rknn_sdk_version version; ret = rknn_query(ctx, RKNN_QUERY_SDK_VERSION, &version, sizeof(rknn_sdk_version)); printf("sdk api version: %s\n", version.api_version); printf("driver version: %s\n", version.drv_version);
(4)rknn_inputs_set
通过 rknn_inputs_set 函数可以设置模型的输入数据。该函数能够支持多个输入,其中 每个输入是 rknn_input 结构体对象,在传入之前用户需要设置该对象。
| API | rknn_inputs_set |
| 功能 | 设置模型输入数据。 |
| 参数 | rknn_context context:rknn_contex 对象。 |
| uint32_t n_inputs:输入数据个数。 | |
| rknn_input inputs[]:输入数据数组,数组每个元素是 rknn_input 结构体对象。 | |
| 返回值 | int 错误码(见 rknn 返回值错误码)。 |
示例代码如下:
rknn_input inputs[1]; memset(inputs, 0, sizeof(inputs)); inputs[0].index = 0; inputs[0].type = RKNN_TENSOR_UINT8; inputs[0].size = img_width*img_height*img_channels; inputs[0].fmt = RKNN_TENSOR_NHWC; inputs[0].buf = in_data; ret = rknn_inputs_set(ctx, 1, inputs);
(5)rknn_inputs_map
rknn_inputs_map 函数用于获取模型输入tensor初始化后的存储状态,存储状态包括虚拟地址,物理地址fd,存储空间大小。它需要和rknn_inputs_sync接口(见rknn_inputs_sync 函数)配合使用,在模型初始化后,用户通过返回的的内存位置设置输入数据,并且在推理前调用rknn_inputs_sync函数。存储状态使用rknn_tensor_mem结构体表示。输入参数mem 是rknn_tensor_mem结构体数组。
目前,在 RK1808/RV1109/RV1126 芯片上,返回的fd是-1。当返回的物理地址值是 0xffffffffffffffff(2的64次幂-1),表示无法获取正确的物理地址,而虚拟地址仍然有效。如果有多个模型输入tensor的存储空间较大,用户可以在挂载驱动时,适当增加模型输入和 输出存储空间或者扩增固件中的CMA内存空间。以RV1109_RV1126为例,配置驱动存储 空间,可以参考如下修改:
把/etc/init.d/S60NPU_init文件这一行:
insmod /lib/modules/galcore.ko contiguousSize=0x400000 gpuProfiler=1
改成
insmod /lib/modules/galcore.ko contiguousSize=0x600000 gpuProfiler=1
然后重启生效。此配置应该大于用户模型输入和输出总大小,但不超过固件中可用的CMA空间大小。
| API | rknn_inputs_map |
| 功能 | 读取输入存储状态信息。 |
| 参数 | rknn_context context:rknn_contex 对象。 |
| uint32_t n_inputs:输入数据个数。 | |
| rknn_input inputs[]:输入数据数组,数组每个元素是 rknn_input 结构体对象。 | |
| 返回值 | int 错误码(见rknn 返回值错误码)。 |
示例代码如下:
rknn_tensor_mem mem[1]; ret = rknn_inputs_map(ctx, 1, mem);
(6)rknn_inputs_sync
rknn_inputs_sync 函数将 CPU 缓存写回内存,让设备能获取正确的数据。
| API | rknn_inputs_sync |
| 功能 | 同步输入数据。 |
| 参数 | rknn_context context:rknn_contex 对象。 |
| uint32_t n_inputs:输入数据个数。 | |
| rknn_tensor_mem mem[]:存储状态信息数组,数组每个元素是 rknn_tensor_mem结构体对象。 | |
| 返回值 | int 错误码(见 rknn 返回值错误码) |
示例代码如下:
rknn_tensor_mem mem[1]; ret = rknn_inputs_map(ctx, 1, mem); ret = rknn_inputs_sync(ctx, 1, mem);
(7)rknn_inputs_unmap
rknn_inputs_unmap 函数将清除 rknn_inputs_map函数获取的输入tensor的存储位 置信息和标志。
| API | rknn_inputs_unmap |
| 功能 | 清除rknn_inputs_map函数获取的输入tensor的存储位置信息和标志。 |
| 参数 | rknn_context context:rknn_contex对象。 |
| uint32_t n_inputs:输入数据个数。 | |
| rknn_tensor_mem mem[] : 存 储 状 态 信 息 数 组 , 数 组 每 个 元 素 是 rknn_tensor_mem 结构体对象。 | |
| 返回值 | int 错误码(见 rknn 返回值错误码) |
示例代码如下:
rknn_tensor_mem mem[1]; ret = rknn_inputs_map(ctx, 1, mem); ret = rknn_inputs_sync(ctx, 1, mem); ret = rknn_run(ctx, NULL); ret = rknn_inputs_unmap(ctx, 1, mem);
(8)rknn_run
rknn_run函数将执行一次模型推理,调用之前需要先通过rknn_inputs_set函数设置输入数据。
| API | rknn_run |
| 功能 | 执行一次模型推理。 |
| 参数 | rknn_context context:rknn_context 对象。 |
| rknn_run_extend* extend:保留扩展,当前没有使用,传入 NULL 即可。 | |
| 返回值 | int 错误码(见 rknn 返回值错误码) |
示例代码如下:
ret = rknn_run(ctx, NULL);
(9)rknn_outputs_get
rknn_outputs_get函数可以获取模型推理的输出数据。该函数能够一次获取多个输出数据。其中每个输出是rknn_output结构体对象,在函数调用之前需要依次创建并设置每个 rknn_output对象。
对于输出数据的buffer存放可以采用两种方式:一种是用户自行申请和释放,此时 rknn_output对象的is_prealloc需要设置为1,并且将buf指针指向用户申请的 buffer;另一种是由 rknn来进行分配,此时rknn_output对象的is_prealloc设置为0即可,函数执行之后 buf将指向输出数据。
| API | rknn_outputs_get |
| 功能 | 获取模型推理输出。 |
| 参数 | rknn_context context:rknn_context 对象。 |
| uint32_t n_outputs:输出数据个数。 | |
| rknn_output outputs[]:输出数据的数组,其中数组每个元素为 rknn_output 结构体对象,代表模型的一个输出。 | |
| rknn_output_extend* extend:保留扩展,当前没有使用,传入 NULL 即可 | |
| 返回值 | int 错误码(见 rknn 返回值错误码) |
示例代码如下:
rknn_output outputs[io_num.n_output]; memset(outputs, 0, sizeof(outputs)); for (int i = 0; i < io_num.n_output; i++) { outputs[i].want_float = 1; } ret = rknn_outputs_get(ctx, io_num.n_output, outputs, NULL)
(10)rknn_outputs_release
rknn_outputs_release函数将释放rknn_outputs_get函数得到的输出的相关资源。
| API | rknn_outputs_release |
| 功能 | 释放rknn_output对象。 |
| 参数 | rknn_context context:rknn_context对象。 |
| uint32_t n_outputs:输出数据个数。 | |
| rknn_output outputs[]:要销毁的 rknn_output 数组。 | |
| 返回值 | int 错误码(见rknn返回值错误码) |
示例代码如下
ret = rknn_outputs_release(ctx, io_num.n_output, outputs);
(11)rknn_outputs_map
rknn_outputs_map函数获取模型初始化后输出tensor 的存储状态。需要和rknn_outputs_sync函数(见 rknn_outputs_sync 函数)配合使用,在模型初始化后调用 rknn_outputs_map 接口,接着每次推理完调用 rknn_outputs_sync 接口。如果用户需要 32 位浮点类型的数据,需要根据量化方式和量化的数据类型做反量化。
| API | rknn_outputs_map |
| 功能 | 读取输出存储状态信息。 |
| 参数 | rknn_context context:rknn_context 对象。 |
| uint32_t n_outputs:输出数据个数。 | |
| rknn_tensor_mem mem[]:存储状态信息数组,数组每个元 素 是 rknn_tensor_mem结构体对象。 | |
| 返回值 | int 错误码(见 rknn 返回值错误码) |
示例代码如下:
rknn_tensor_mem mem[1]; ret = rknn_outputs_map(ctx, 1, mem);
(12)rknn_outputs_sync
当使用 rknn_outputs_map 接口映射完模型运行时模型输出 tensor 存储状态信息后, 为确保缓存一致性,使用 rknn_outputs_sync 函数让 CPU 获取推理完最新的数据。
| API | rknn_outputs_sync |
| 功能 | 推理完,同步最新的输出数据。 |
| 参数 | rknn_context context:rknn_context 对象。 |
| uint32_t n_outputs:输出数据个数。 | |
| rknn_tensor_mem mem[]:存储状态信息数组,数组每个元素是 rknn_tensor_mem 结构体对象。 | |
| 返回值 | int 错误码(见 rknn 返回值错误码) |
示例代码如下:
rknn_tensor_mem mem[1]; ret = rknn_run(ctx, NULL); ret = rknn_outputs_sync(ctx, io_num.n_output, mem)
(13)rknn_outputs_unmap
rknn_outputs_unmap函数将清除rknn_outputs_map函数获取的输出tensor的存储状态。
| API | rknn_outputs_unmap |
| 功能 | 清除 rknn_outputs_map 函数获取的输出 tensor 的存储状态。 |
| 参数 | rknn_context context:rknn_context 对象。 |
| uint32_t n_outputs:输出数据个数。 | |
| rknn_tensor_mem mem[]:存储状态信息数组,数组每个元素是 rknn_tensor_mem结构体对象。 | |
| 返回值 | int 错误码(见 rknn 返回值错误码) |
示例代码如下:
rknn_tensor_mem mem[1]; ret = rknn_outputs_unmap(ctx, io_num.n_output,mem);
7.2.3 RKNN 数据结构定义
(1)rknn_input_output_num
结构体rknn_input_output_num表示输入输出Tensor个数,其结构体成员变量如下表所示:
| 成员变量 | 数据类型 | 含义 |
| n_input | uint32_t | 输入 Tensor个数 |
| n_output | uint32_t | 输出 Tensor个数 |
(2)rknn_tensor_attr
结构体 rknn_tensor_attr 表示模型的 Tensor 的属性,结构体的定义如下表所示:
| 成员变量 | 数据类型 | 含义 |
| index | uint32_t | 表示输入输出 Tensor 的索引位置。 |
| n_dims | uint32_t | Tensor 维度个数。 |
| dims | uint32_t[] | Tensor 各维度值。 |
| name | char[] | Tensor 名称。 |
| n_elems | uint32_t | Tensor 数据元素个数。 |
| size | uint32_t | Tensor 数据所占内存大小。 |
| fmt | rknn_tensor_form at | Tensor 维度的格式,有以下格式: RKNN_TENSOR_NCHW RKNN_TENSOR_NHWC |
| type | rknn_tensor_type | Tensor 数据类型,有以下数据类型: RKNN_TENSOR_FLOAT32 RKNN_TENSOR_FLOAT16 RKNN_TENSOR_INT8 RKNN_TENSOR_UINT8 RKNN_TENSOR_INT16 |
| qnt_type | rknn_tensor_qnt_type | Tensor量化类型,有以下的量化类型: RKNN_TENSOR_QNT_NONE:未量化; RKNN_TENSOR_QNT_DFP:动态定点量 化; RKNN_TENSOR_QNT_AFFINE_ASYMM ETRIC:非对称量化。 |
| fl | int8_t | RKNN_TENSOR_QNT_DFP 量化类型的参数。 |
| zp | uint32_t | RKNN_TENSOR_QNT_AFFINE_ASYMMETRI C 量化类型的参数 |
| scale | float | RKNN_TENSOR_QNT_AFFINE_ASYMMETRI C 量化类型的参数。 |
(3)rknn_input
结构体rknn_input 表示模型的一个数据输入,用来作为参数传入给rknn_inputs_set函数。结构体的定义如下表所示:
| 成员变量 | 数据类型 | 含义 |
| index | uint32_t | 该输入的索引位置。 |
| buf | void* | 输入数据 Buffer 的指针。 |
| size | uint32_t | 输入数据 Buffer 所占内存大小。 |
| pass_through | uint8_t | 设置为 1 时会将 buf存放的输入数据直接设置给 模型的输入节点,不做任何预处理。 |
| type | rknn_tensor_type | 输入数据的类型。 |
| fmt | rknn_tensor_form at | 输入数据的格式。 |
(4)rknn_tensor_mem
结构体 rknn_tensor_mem表示 tensor 初始化后的存储状态信息,用来作为参数传入给 rknn_inputs_map系列和rknn_outputs_map系列函数。结构体的定义如下表所示:
| 成员变量 | 数据类型 | 含义 |
| logical_addr | void* | 该输入的虚拟地址。 |
| physical_addr | uint64_t | 该输入的物理地址。 |
| fd | int32_t | 该输入的 fd。 |
| size | uint32_t | 该输入 tensor 占用的内存大小。 |
| handle | uint32_t | 该输入的 handle。 |
| priv_data | void* | 保留的数据。 |
| reserved_flag | uint64_t | 保留的标志位。 |
(5)rknn_output
结构体rknn_output表示模型的一个数据输出,用来作为参数传入给rknn_outputs_get 函数,在函数执行后,结构体对象将会被赋值。结构体的定义如下表所示:
| 成员变量 | 数据类型 | 含义 |
| want_float | uint8_t | 标识是否需要将输出数据转为 float 类型输出。 |
| is_prealloc | uint8_t | 标识存放输出数据的 Buffer 是否是预分配。 |
| index | uint32_t | 该输出的索引位置。 |
| buf | void* | 输出数据 Buffer 的指针。 |
| size | uint32_t | 输出数据 Buffer 所占内存大小。 |
(6)rknn_perf_detail
结构体 rknn_perf_detail 表示模型的性能详情,结构体的定义如下表所示:
| 成员变量 | 数据类型 | 含义 |
| perf_data | char* | 性能详情包含网络每层运行时间,能够直接打印 出来查看。 |
| data_len | uint64_t | 存放性能详情的字符串数组的长度。 |
(7)rknn_sdk_version
结构体 rknn_sdk_version 用来表示 RKNN SDK 的版本信息,结构体的定义如下:
| 成员变量 | 数据类型 | 含义 |
| api_version | char[] | char[] SDK 的版本信息。 |
| drv_version | char[] | SDK所基于的驱动版本信息。 |
7.2.4 RKNN返回值错误码
RKNN API 函数的返回值错误码定义如下表所示
| 错误码 | 错误详情 |
| RKNN_SUCC(0) | 执行成功 |
| RKNN_ERR_FAIL(-1) | 执行出错 |
| RKNN_ERR_TIMEOUT(-2) | 执行超时 |
| RKNN_ERR_DEVICE_UNAVAILABLE (-3) | NPU 设备不可用 |
| RKNN_ERR_MALLOC_FAIL(-4) | 内存分配失败 |
| RKNN_ERR_PARAM_INVALID(-5) | 传入参数错误 |
| RKNN_ERR_MODEL_INVALID(-6) | 传入的 RKNN 模型无效 |
| RKNN_ERR_CTX_INVALID(-7) | 传入的 rknn_context 无效 |
| RKNN_ERR_INPUT_INVALID(-8) | 传入的 rknn_input 对象无 |
| RKNN_ERR_OUTPUT_INVALID(-9) | 传入的 rknn_output 对象无效 |
| RKNN_ERR_DEVICE_UNMATCH(-10) | 版本不匹配 |
| RKNN_ERR_INCOMPATILE_PRE_COM PILE_MODEL(-11) | RKNN模型使用pre_compile 模式,但是和当前驱动不兼容 |
| RKNN_ERR_INCOMPATILE_OPTIMIZAT ION_LEVEL_VERSION(-12) | RKNN模型设置了优化等级的选项,但是和当前驱动不兼容 |
| RKNN_ERR_TARGET_PLATFORM_UN MATCH(-13) | RKNN模型和当前平台不兼容,一般是将 RK1808的平台的RKNN模型放到了 RV1109/RV1126上。 |
| RKNN_ERR_NON_PRE_COMPILED_M ODEL_ON_MINI_DRIVER(-14) | RKNN模型不是pre_compile模式,在mini-driver上无法执行。 |
-
神经网络
+关注
关注
42文章
4842浏览量
108183 -
开发板
+关注
关注
26文章
6425浏览量
120930 -
AI算法
+关注
关注
0文章
274浏览量
13196
发布评论请先 登录


基于RV1126开发板实现人员检测方案

基于RV1126开发板实现安全帽检测方案

基于RV1126开发板实现人脸检测方案
基于RV1126开发板实现人脸识别方案
基于RV1126开发板实现自学习图像分类方案
基于RV1126开发板实现人脸检测方案
基于RV1126开发板实现二维码识别方案
基于RV1126开发板实现人脸检测方案
替代升级实锤!实测RV1126B,CPU性能吊打RV1126




评论