 用TensorFlow写个简单的神经网络
用TensorFlow写个简单的神经网络

这次就用TensorFlow写个神经网络,这个神经网络写的很简单,就三种层,输入层--隐藏层----输出层;
首先导入我们要使用的包
# -*- coding: utf-8 -*-import tensorflow as tfimport matplotlib.pyplot as pltimport numpy as npimport matplotlibfrom sklearn import datasetsfrom matplotlib.font_manager import FontProperties
然后在设定一下我们画图的时候要显示中文的字体,因为Python自带的不支持中文的解释
#设置中文font = FontProperties(fname=r"c:\windows\fonts\simsun.ttc", size=14)zhfont1 = matplotlib.font_manager.FontProperties(fname=r'c:\windows\fonts\simsun.ttc')
定义一个会话,因为图是必须在会话中启动的
#定义一个图会话sess=tf.Session()
这里我选用公开的数据莺尾花的数据集,这个数据集虽然都被大家 玩烂了,不过这个是一个学习代码,就不计较那么多了;
#莺尾花数据集iris=datasets.load_iris()x_vals=np.array([x[0:3] for x in iris.data])y_vals=np.array([x[3] for x in iris.data])
这里设置一个随机种子,为了可以让大家把结果复现出来
#设置一个种子求结果seed=211tf.set_random_seed(seed)8np.random.seed(seed)
开始有模有样的划分数据集了,一个是训练集,一个是测试集,训练集占80%,测试集占20%
#划分测试机和训练集train_indices=np.random.choice(len(x_vals),round(len(x_vals)*0.8),replace=True)test_indices=np.array(list(set(range(len(x_vals)))-set(train_indices)))x_vals_train=x_vals[train_indices]x_vals_test = x_vals[test_indices]y_vals_train = y_vals[train_indices]y_vals_test = y_vals[test_indices]
在这里我们在将特征进行一个归一化,也就是将数值型特征全部都转换为0-1之间的数值,用特征最大距离作为分母;还有一些其他的标准化方法,有兴趣可以了解,这个好处就是能够让迭代更加快速,还有就是消除量纲,就是单位之间影响;
使用nan_to_num这个函数主要是为了消除None值带来的计算影响
#归一化函数def normalize_cols(m): col_max = m.max(axis=0) col_min = m.min(axis=0) return (m - col_min) / (col_max - col_min)#数据归一化并转空集x_vals_train=np.nan_to_num(normalize_cols(x_vals_train))x_vals_test=np.nan_to_num(normalize_cols(x_vals_test))
好了,上面已经生成了我们想要的数据集;在这里我们在设置一次训练的数据集多大,一般是选择2^N倍数,因为是计算机是二进制存储,这样就快,这里我就随意选择了个25,因为数据集比较小,没什么影响
batch_size=25
在这里定义一下训练变量Y和X,顺便设置为浮点类型
x_data=tf.placeholder(shape=[None,3],dtype=tf.float32)y_target=tf.placeholder(shape=[None,1],dtype=tf.float32)
在这里我们设置一下隐藏层连接数
#设置隐藏层hidden_layer_nodes=5
开始定义各层的参数变量,因为输入变量是三个
#定义各层变量,初始变量为3个A1=tf.Variable(tf.random_normal(shape=[3,hidden_layer_nodes]))b1=tf.Variable(tf.random_normal(shape=[hidden_layer_nodes]))A2=tf.Variable(tf.random_normal(shape=[hidden_layer_nodes,1]))b2=tf.Variable(tf.random_normal(shape=[1]))
这里我们使用relu函数作为激活函数,以及输出结果也使用relu函数
#定义隐藏层的输出和输出层的输出hidden_output=tf.nn.relu(tf.add(tf.matmul(x_data,A1),b1))final_output = tf.nn.relu(tf.add(tf.matmul(hidden_output, A2),b2))
这里我们在定义一下损失函数,有用最大似然估计的,这里我们使用均方误差方式
loss=tf.reduce_mean(tf.square(y_target-final_output))
定义一下参数的更新方式和学习速率,这里我们使用梯度下降方法更新,下一次我们讲解用其他方式更新,和学习速率随着迭代次数减少,tfboys就是那么任性
#声明算法初始变量opt=tf.train.GradientDescentOptimizer(0.005)train_step=opt.minimize(loss)#变量进行初始化init=tf.initialize_all_variables()sess.run(init)
定义两个list,用来存放在训练中的测试集和训练集的误差
#训练过程loss_vec=[]test_loss=[]
开始迭代,这里我们设置迭代次数为5000
for i in range(5000): #选取batch_size大小的数据集 rand_index=np.random.choice(len(x_vals_train),size=batch_size) #选取出数据集 rand_x=x_vals_train[rand_index] rand_y=np.transpose([y_vals_train[rand_index]]) #开始训练步骤 sess.run(train_step,feed_dict={x_data:rand_x,y_target:rand_y}) #保存损失结果 temp_loss=sess.run(loss,feed_dict={x_data:rand_x,y_target:rand_y}) #保存损失函数 loss_vec.append(np.sqrt(temp_loss)) test_temp_loss = sess.run(loss, feed_dict={x_data: x_vals_test, y_target: np.transpose([y_vals_test])}) test_loss.append(np.sqrt(test_temp_loss)) #打印损失函数,没五十次打印一次 if (i+1)%50==0: print('Generation: ' + str(i + 1) + '. Train_Loss = ' + str(temp_loss)+ '. test_Loss = ' + str(test_temp_loss))
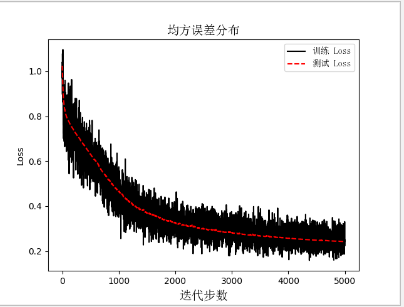
迭代最后结果为

接下来我们在看看误差随着迭代变化的趋势,下降的还不够快,这些代码其实还是很粗糙,太多地方需要优化了;下次在写个优化版本的
#画图plt.plot(loss_vec, '', label='训练 Loss')plt.plot(test_loss, 'r--', label='测试 Loss')plt.title('均方误差分布', fontproperties=font)plt.xlabel('迭代步数', fontproperties=font)plt.ylabel('Loss')plt.legend(prop=zhfont1)plt.show()
-
神经网络
+关注
关注
42文章
4845浏览量
108373 -
深度学习
+关注
关注
73文章
5614浏览量
124751 -
tensorflow
+关注
关注
13文章
336浏览量
62444
原文标题:用TensorFlow写个简单的神经网络
文章出处:【微信号:AI_shequ,微信公众号:人工智能爱好者社区】欢迎添加关注!文章转载请注明出处。
发布评论请先 登录
【案例分享】ART神经网络与SOM神经网络
【AI学习】第3篇--人工神经网络
如何构建神经网络?
如何使用TensorFlow将神经网络模型部署到移动或嵌入式设备上
使用tensorflow构建一个简单神经网络
谷歌正式发布TensorFlow 图神经网络
用Python从头实现一个神经网络来理解神经网络的原理1

用Python从头实现一个神经网络来理解神经网络的原理2

用Python从头实现一个神经网络来理解神经网络的原理3

用Python从头实现一个神经网络来理解神经网络的原理4




评论