 英伟达发布Nemotron-CC大型AI训练数据库
英伟达发布Nemotron-CC大型AI训练数据库

近日,英伟达在其官方博客上宣布了一项重大进展,推出了一款名为Nemotron-CC的大型英文AI训练数据库。这一数据库的发布,标志着英伟达在推动大语言模型训练技术方面迈出了重要一步。
据英伟达介绍,Nemotron-CC数据库总计包含了惊人的6.3万亿个Token,其中1.9万亿为精心合成的数据。这一庞大的数据量不仅为AI模型的训练提供了丰富的素材,更为学术界和企业界在探索大语言模型领域时提供了强有力的支持。
英伟达声称,Nemotron-CC数据库的设计初衷就是为了帮助学术界和企业界进一步推动大语言模型的训练过程。通过提供如此大规模、高质量的训练数据,英伟达期望能够加速AI技术的创新和应用,为各行各业带来更多的智能化解决方案。
随着人工智能技术的不断发展,大语言模型已经成为研究和实践中的热点。而英伟达此次推出的Nemotron-CC数据库,无疑将为这一领域的研究和应用注入新的活力。
声明:本文内容及配图由入驻作者撰写或者入驻合作网站授权转载。文章观点仅代表作者本人,不代表电子发烧友网立场。文章及其配图仅供工程师学习之用,如有内容侵权或者其他违规问题,请联系本站处理。
举报投诉
-
AI
+关注
关注
91文章
41967浏览量
303061 -
数据库
+关注
关注
7文章
4092浏览量
68676 -
模型
+关注
关注
1文章
3873浏览量
52337 -
英伟达
+关注
关注
23文章
4126浏览量
99774
发布评论请先 登录
相关推荐
热点推荐
数据中心缺电,英伟达又有新动作!
电子发烧友网报道(文/李弯弯)近日,英伟达宣布将举办一场私人峰会,邀请聚焦数据中心电力问题的初创公司参会,共同应对可能阻碍人工智能发展的电力难题。当下,大模型训练与推理对算力的需求呈指

从英伟达电话会看Agentic AI推理与FPGA价值
2026年2月,英伟达发布2026财年Q4财报:营收681亿美元,同比增长73%,数据中心业务增长75%——预期中的超预期。更值得关注的,是电话会中反复出现的几个关键词:Agentic


NVIDIA 推出 Nemotron 3 系列开放模型
token 数。 ● Nemotron 通过先进的强化学习技术以及大规模并行多环境后训练,实现了卓越的准确率。 ● NVIDIA 率先推出整套前沿的开放模型、训练数据集及强化学习环境

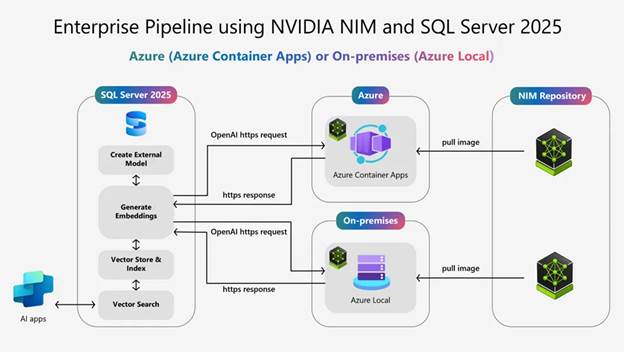
使用NVIDIA Nemotron RAG和Microsoft SQL Server 2025构建高性能AI应用
在 Microsoft Ignite 2025 大会上,随着 Microsoft SQL Server 2025 的发布,AI 就绪型企业数据库愿景成为现实,为开发者提供强大的新工具,例如内置向量
2025开放原子开发者大会AI时代数据库创新实践分论坛成功举办
11月21日,2025开放原子开发者大会——AI时代数据库创新实践分论坛成功举办。论坛以“构建AI时代智能数据底座”为核心主题,汇聚OpenTenBase、Apache Doris、K

第四次工业革命AI将实现十亿倍增长 | 中国AI芯片与英伟达的角色
内容提要:黄仁勋BG2专访:英伟达、OpenAI、算力未来与美国梦AI规模定律与推理的革命:在传统的AI规模定律(预训练、后

AI与数据库双向赋能,达梦靠自主创新把握弯道超车机遇
在AI技术迅猛发展的今天,作为数据存储与处理核心载体的数据库,正经历一场深刻的变革,传统数据库与AI技术的碰撞融合,带来了新的发展机遇,也在
数据库数据恢复—服务器异常断电导致Oracle数据库故障的数据恢复案例
Oracle数据库故障:
某公司一台服务器上部署Oracle数据库。服务器意外断电导致数据库报错,报错内容为“system01.dbf需要更多的恢复来保持一致性”。该Oracle数据库
三款主流国产数据库的技术特点
随着数字经济的快速发展和数据安全要求的提升,国产数据库正迎来前所未有的发展机遇。在信创浪潮推动下,达梦数据库、TiDB、华为高斯数据库等国产
数据库数据恢复—MongoDB数据库文件丢失的数据恢复案例
MongoDB数据库数据恢复环境:
一台操作系统为Windows Server的虚拟机上部署MongoDB数据库。
MongoDB数据库故障:
工作人员在MongoDB服务仍
数据库数据恢复—SQL Server数据库被加密如何恢复数据?
SQL Server数据库故障:
SQL Server数据库被加密,无法使用。
数据库MDF、LDF、log日志文件名字被篡改。





评论